
The language of the subject area. Not overloaded with general purpose language constructs. At the same time, it allows you to implement very complex logic with just a few lines. All of this is DSL.
However, the creation of DSL requires the developer to be qualified. Regular use of this approach turns into a routine of developing another language. The solution may be to create a universal tool - an engine that will be applicable to completely different tasks and easy to modify. In this article, we will develop in C # the simplest from the point of view of implementation, but at the same time quite powerful language engine, with which you can solve a fairly wide range of problems.
Introduction
There are two ways to develop an application project: to make it so simple that it is obvious that it has no flaws, or to make it so complex that it does not have obvious flaws. C.E. R. Hoar (CAR Hoare)In this article I want to share one of the development techniques that helps me and my team, on the one hand, deal with the complexity of projects. And on the other, it allows you to quickly develop prototype applications. At first glance, developing a programming language seems too complicated. So it is, if we are talking about a universal tool. If the goal is to cover a narrow subject area, then the development of a specific language often justifies itself.
Once I was faced with the task of developing an implementation of an industrial language (IEC 61131-3) for integration into customer software. In the course of this work, I became interested in the topic of interpreter-structure and since then I have written interpreters of esoteric and not very languages as a hobby. In the future, an understanding came of how to use self-written interpreters to simplify everyday life.

The main goal of sane programming languages is to simplify the process of programming and reading a program. Writing in asm is easier than in machine codes, writing in C is easier than in asm, in C # is even simpler and so on.
This is achieved mainly due to the most popular technique of reductionism - splitting a complex task into simple and recognizable components - standardizing their interaction and a certain syntax.
The programming language consists of a set of operators, which in essence is the basis of the language, elementary building blocks, and syntax that defines the way of writing combinations of operators, as well as the standard library. Sequences of elementary actions according to syntactic rules are grouped into functions, functions are grouped into classes (if there are OOP), classes are combined into libraries, and those, in turn, into packages. This is what a typical mainstream language looks like. In principle, these techniques are enough to solve most everyday tasks. However, this is not the limit, because you can take a step further - to a higher level of abstraction, and you will have to go beyond the limits of the language used if it does not support metaprogramming in the form of macros.
Nowadays, most of the projects boil down to a combination of ready-made components and an insignificant low-level samopisnogo part. The combination of components is usually done by means of a universal programming language - C #, Java, Python and others. Although these languages are high-level, they are also universal, and therefore necessarily contain syntactic constructions for low-level operations, creation of functions, classes, description of generalized types, asynchronous programming, and much more. Because of this, the task “Do it once, do two, do three” overgrows with a mass of syntactic constructions and can swell up to hundreds of lines of code or more.
You can simplify the reuse of components if you repeat the technique of reductionism, but to these very components. This is achieved through the development of a specialized language that has a simplified syntax and serves solely to describe the interaction of these components. This approach is called YaOP (language-oriented programming), and languages are called DSL (Domain-Specific Language - a domain-specific language).
Due to the lack of redundant constructions, only a few lines on the DSL can implement quite complex functionality, which leads to positive consequences: the development speed increases, the number of errors decreases, and system testing is simplified.
If applied successfully, this approach can significantly increase the flexibility of the product being developed due to the possibility of writing compact scripts that define and expand the behavior of the system. There can be a lot of applications for this approach, as evidenced by the prevalence of this approach, because DSL is everywhere. Common HTML is a document description language, SQL is a structured query language, JSON is a structured data description language, XAML, PostScript, Emacs Lisp, nnCron and many others.

With all the advantages, DSL also has a significant drawback - high requirements for the system developer.
Not every developer has the knowledge and experience in developing even a primitive language. Even a smaller number of specialists can develop a sufficiently flexible and productive language. There are other problems. For example, at a certain point in the development of the originally laid down functionality, it may not be enough and it will be necessary to create functions or OOP. And where there are functions, it may be necessary to optimize tail recursion to do without loops, and so on. In this case, backward compatibility must be taken into account so that previously written scripts continue to work with the new version.
Another problem is that a language designed to solve one problem is completely unsuitable for others. Therefore, you have to develop a new DSL from scratch, so developing new languages becomes a chore. This again complicates the maintenance and reduces the reuse of code that is difficult to share between different DSL implementations and projects that use them.

The way out is to create a DSL to build a DSL. Here, I do not mean RBNF, but rather a language that can be changed by built-in means to the language of the subject area. The main obstacle to creating a flexible and transformable language is the presence of a rigidly defined syntax and type system. Over the entire development period of the computer industry, several flexible languages without syntax have been proposed, but they have survived to this day and the Forth and Lisp languages continue to develop actively. The main feature of these languages is that, due to their structure and homo-iconicity, they can, due to built-in means, change the behavior of the interpreter and, if necessary, parse syntactic constructions that were not laid down originally.
There are solutions for Forth extending its syntax to C or to Scheme. "Fort" is often criticized for the unusual postfix sequence of arguments and operations, which is dictated by the use of the stack to pass arguments. However, “Fort” has access to a text interpreter, this allows you to hide the reverse record from the user, if necessary. And, finally, this is a matter of habit, and it is developed quite quickly.
The Lisp family of languages relies on macros that allow you to enter DSL if necessary. And access to the interpreter and reader facilitates the implementation of metacyclic interpreters with specified interpretation features. For example, the implementation of Scheme lisp Racket is positioned as an environment for developing languages and has out of the box languages for creating web servers, building GUI interfaces, inference language, and others.
Such flexibility makes these languages good candidates for the role of the universal DSL engine.
“Fort” and Lisp mainly develop as general-purpose languages, albeit niche ones, as a result - they draw upon themselves functionality that can be redundant for a DSL language. But at the same time they are simple enough to implement, which means that you can develop a limited version with the possibility of its expansion. This will allow you to reuse the core of such a language with small modifications (ideally without) for a specific task.
I also want to note that these languages are great not only for writing scripts, but also for interactive interaction with the system via REPL. Which, on the one hand, can be convenient for debugging, and on the other hand, act as a user-accessible interface with the system. It is believed that the text interface with the system in some cases can be more effective than the graphical one, since it is much simpler to implement, more flexible, allows the user to generalize typical operations into functions, and so on. A striking example of a text interface might be Bash. And if the language is homo-iconic, then its constructions can be relatively easily generated and parsed and implemented with a minimal effort on top of the interpreter graphic language - this can be useful when the target user is far from programming.
Nowadays, XML and JSON data description languages are widely used as DSL for configuration. Of course, this is a great practice, but in some cases the data alone is not enough and you need, for example, to describe operations on them.
In this post, I propose to create a simple interpreter of the Fort language and show how to adapt it to solve specific problems.
The Fort language was chosen as the easiest to implement and use, while powerful enough to use it as a DSL for a number of tasks. In fact, the heart of the language is the address interpreter, which even in assembler takes only a few lines, and the bulk of the implementation falls on the primitives, which are more, the more universal, fast and flexible the implementation should be. Another important part of the language is the text interpreter, which allows you to interact with the address interpreter.

Address interpreter
The basic element of the Fort language is a word that is separated from other words and atoms (numbers) by spaces, line ends and tabs.
A word has the same meaning and properties as a function from other languages, for example C. Words wired in the implementation, that is, implemented by the same means as the interpreter, are similar to operators from other languages. In fact, a program in any programming language is nothing more than a combination of language and data operators. Therefore, the creation of a programming language can be considered as the definition of operators and how to combine them. Moreover, languages such as C define a different way of writing operators, which determines the syntax of the language. In most languages, modifying statements is usually not possible - for example, you cannot change the syntax or behavior of an if statement.
In the Fort language, all operators and their combinations (user words) have the same writing method. Fort words are divided into primitive and custom. You can define a word that will overload the primitive, thus changing the behavior of the primitives. Although in reality the redefined word will be implemented through the initially defined primitives. In our implementation, the function in C # will be the primitive. A user-defined word consists of a list of addresses of words to be executed. Since there are two kinds of words, the interpreter must distinguish between them. Separation of primitives and user words is carried out through the same primitives, each user word begins with a DoList operation and ends with an Exit operation.
It is possible to describe for a long time how such a separation occurs, but it is easier to understand this by studying the execution order of the interpreter program. To do this, we implement a minimal interpreter, define a simple program and see how it will be performed step by step.
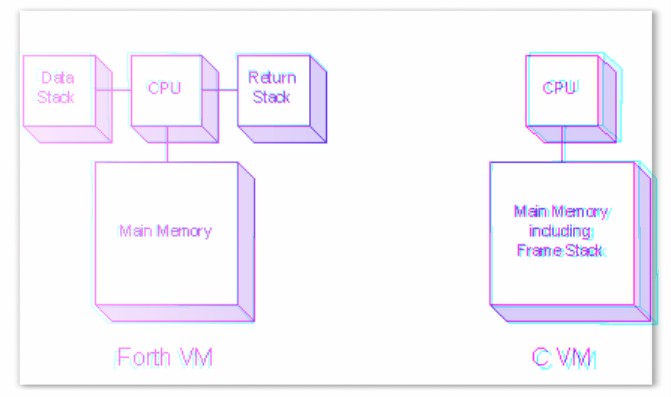
Our fort machine consists of linear memory, data stack, return stack, instruction pointer, word pointer. We will also have a separate place to store primitives.
public object[] Mem; // public Stack<int> RS; // public Stack<object> DS; // public int IP; // public int WP; // public delegate void CoreCall(); public List<CoreCall> Core; //
The essence of the interpretation is to navigate to the address in memory and to execute the instruction that is indicated there. The entire address interpreter - the heart of the language - in our case will be defined in one function Next ().
public void Next() { while (true) { if (IP == 0) return; WP = (int)Mem[IP++]; Core[(int)Mem[WP]](); } }
Each user word begins with a DoList command, the task of which is to save the current interpretation address on the stack and set the interpretation address of the next word.
public void DoList() { RS.Push(IP); IP = WP + 1; }
To exit the word, use the Exit command, which restores the address from the return stack.
public void Exit() { IP = RS.Pop(); }
To clearly demonstrate the principle of the interpreter, we will introduce a command, it will simulate useful work. Let's call it Hello ().
public void Hello() { Console.WriteLine("Hello"); }
First you need to initialize the machine and specify the primitives for the interpreter to work correctly. You also need to specify the addresses of primitives in the program memory.
Mem = new Object[1024]; RS = new Stack<int>(); DS = new Stack<object>(); Core = new List<CoreCall>(); Core.Add(Next); Core.Add(DoList); Core.Add(Exit); Core.Add(Hello); const int opNext = 0; const int opDoList = 1; const int opExit = 2; const int opHello = 3; // core pointers Mem[opNext] = opNext; Mem[opDoList] = opDoList; Mem[opExit] = opExit; Mem[opHello] = opHello;
Now we can make a simple program, in our case, the user code will start at address 4 and consist of two subprograms. The first routine starts at address 7 and calls the second, which starts at address 4 and displays the word Hello.
// program Mem[4] = opDoList; // 3) IP = 9 , IP = WP + 1 = 5 Mem[5] = opHello; // 4) Mem[6] = opExit; // 5) , IP = 9 Mem[7] = opDoList; // 1) Mem[8] = 4; // 2) 4, WP = 4 Mem[9] = opExit; // 6) , IP = 0
To execute the program, you must first save the value 0 on the return stack, according to which the address interpreter will interrupt the interpretation cycle, and set the entry point, and then start the interpreter.
var entryPoint = 7; // IP = 0; // IP = 0, WP = entryPoint; // WP = 7 DoList(); // , IP = 0 Next(); //
As described, in this interpreter primitives will be stored in separate memory. Of course, it could have been implemented differently: for example, in the program memory, the delegate to the operator function was stored. On the one hand, such an interpreter would not have turned out easier, but on the other, it would have been clearly slower, since each step of the interpretation would require type checking, casting and execution, more operations are obtained.
Each user word of our interpreter begins with the DoList primitive, whose task is to save the current address of the interpretation and go to the next address. The exit from the subroutine is carried out by the Exit operation, which restores the address from the return stack for further interpretation. In fact, we described the entire address interpreter. To execute arbitrary programs, it is enough to expand it with primitives. But first you need to deal with a text interpreter, which provides an interface to the address interpreter.

Text interpreter
The Fort language has no syntax; programs written in it are words separated by spaces, tabs, or line ends. Therefore, the task of the text interpreter is to break the input stream into words (tokens), find an entry point for them, execute or write to memory. But not all tokens are subject to execution. If the interpreter does not find the word, he tries to interpret it as a numerical constant. In addition, the text interpreter has two modes: interpretation mode and programming mode. In programming mode, the word addresses are not executed, but are written into memory, thus new words are determined.
Canonical implementations of the “Fort” usually combine a dictionary (dictionary entry) and program memory, defining a single code file in the form of a simply connected list. In our implementation, only executable code will be in memory, and the entry points of words will be stored in a separate structure - a dictionary.
public Dictionary<string, List<WordHeader>> Entries;
In this dictionary, the word is assigned to several headings, so you can define an arbitrary number of subprograms with the same name, and then delete this definition and start using the old one. Also, the saved old address allows you to find the name of a word in the dictionary, even if it has been redefined, which is especially useful for generating a stack trace or for debugging to study memory. WordHeader is a class that stores a subroutine entry address and an immediate interpretation flag.
public class WordHeader { public int Address; public bool Immediate; }
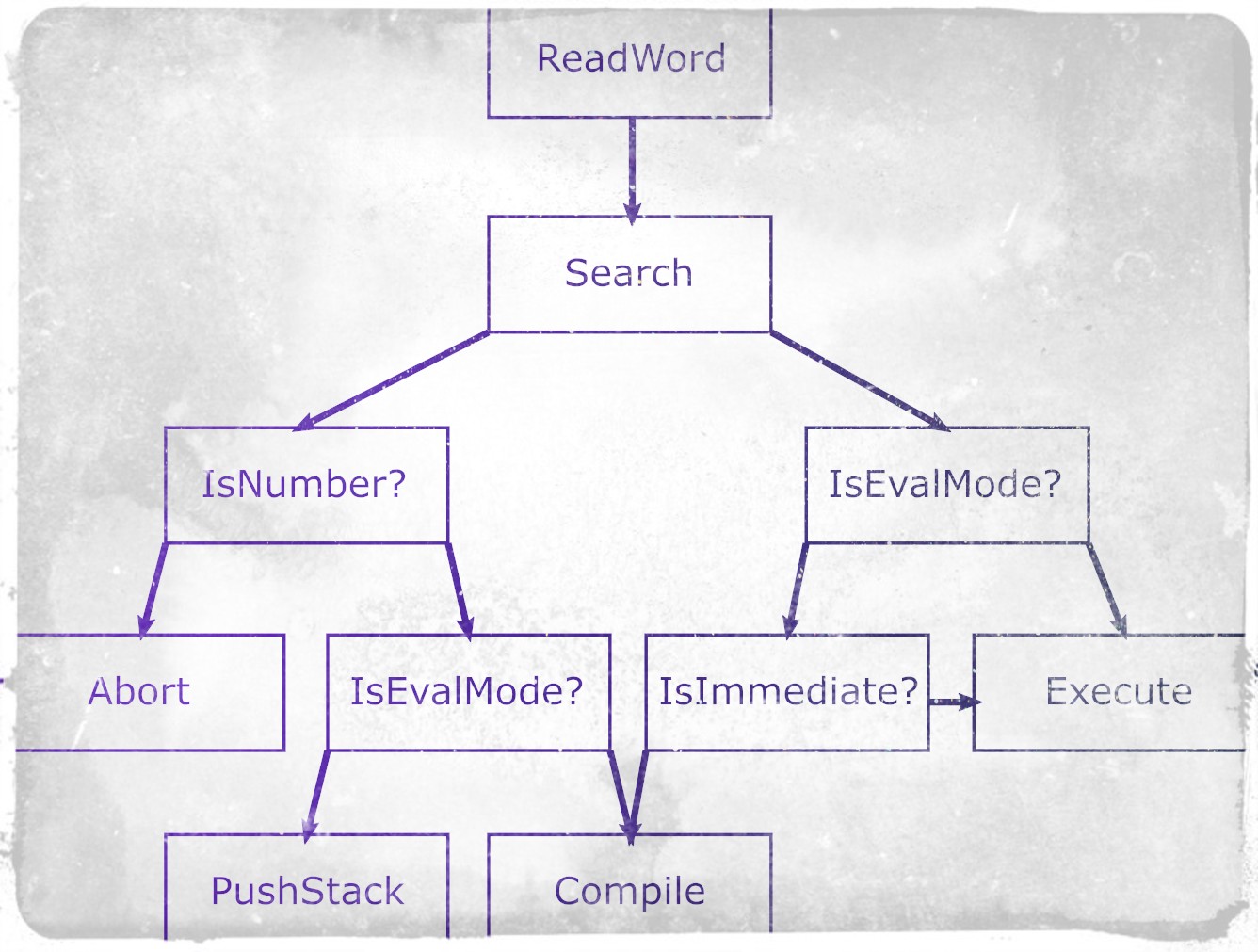
The Immediate flag instructs the interpreter that this word should be executed in programming mode, and not written to memory. Schematically, the logic of the interpreter can be represented as follows: the right hand is YES, the left is NO.
We will use TextReader to read the input stream, and TextWriter to output it.
public TextReader Input; public TextWriter Output;
The implementation of the interpreter according to the above scheme will be in one function Interpreter ().
void Interpreter() { while (true) { var word = ReadWord(Input); if (string.IsNullOrWhiteSpace(word)) return; // EOF var lookup = LookUp(word); if (IsEvalMode) { if (lookup != null) { Execute(lookup.Address); } else if (IsConstant(word)) { DS.Push(ParseNumber(word)); } else { DS.Clear(); Output.WriteLine($"The word {word} is undefined"); } } else { // program mode if (lookup != null) { if (lookup.Immediate) { Execute(lookup.Address); } else { AddOp(lookup.Address); } } else if (IsConstant(word)) { AddOp(LookUp("doLit").Address); AddOp(ParseNumber(word)); } else { IsEvalMode = true; DS.Clear(); Output.WriteLine($"The word {word} is undefined"); } } } }
Interpretation is performed in a loop, the output of which is carried out upon reaching the end of the input stream (for example, the end of the file), while the ReadWord function will return an empty string. The task of ReadWord is to return the next word with each call.
static string ReadWord(TextReader sr) { var sb = new StringBuilder(); var code = sr.Read(); while (IsWhite((char)code) && code > 0) { code = sr.Read(); } while (!IsWhite((char)code) && code > 0) { sb.Append((char)code); code = sr.Read(); } return sb.ToString(); } static bool IsWhite(char c) { return " \n\r\t".Any(ch => ch == c); }
After the word has been read, an attempt is made to find it in the dictionary. If successful, the title of the word is returned; otherwise, null.
public WordHeader LookUp(string word) { if (Entries.ContainsKey(word)) { return Entries[word].Last(); } return null; }
You can check whether the entered value is a number by the first two characters. If the first character is a number, then we assume that it is a number. If the first character is a “+” or “-” sign, and the second is a digit, most likely this is also a number.
static bool IsConstant(string word) { return IsDigit(word[0]) || (word.Length >= 2 && (word[0] == '+' || word[0] == '-') && IsDigit(word[1])); }
To convert a string to a number, you can use the standard methods Int32.TryParse and Double.TryParse. But they do not differ in speed for several reasons, so I use a custom solution.
static object ParseNumber(string str) { var factor = 1.0; var sign = 1; if (str[0] == '-') { sign = -1; str = str.Remove(0, 1); } else if (str[0] == '+') { str = str.Remove(0, 1); } for (var i = str.Length - 1; i >= 0; i--) { if (str[i] == '.') { str = str.Remove(i, 1); return IntParseFast(str) * factor * sign; } factor *= 0.1; } return IntParseFast(str) * sign; } static int IntParseFast(string value) { // An optimized int parse method. var result = 0; foreach (var c in value) { if (!(c >= '0' && c <= '9')) return result; // error result = 10 * result + (c - 48); } return result; }
The ParseNumber method can convert both integer values and floating-point numbers, for example, “1.618”.
The execution of the word occurs in the same way as we used to run the address interpreter. In the event of an exception, a stack trace of the address interpreter will be printed.
public void Execute(int address) { try { if (address < Core.Count) { // eval core Core[address](); // invoke core function } else { // eval word IP = 0; // set return address WP = address; // set eval address DoList(); // fake doList Next(); // run evaluator } } catch (Exception e) { Output.WriteLine(e.Message); var wpEntry = Entries.FirstOrDefault(d => d.Value.Any(en => en.Address == WP)); var ipEntry = Entries.FirstOrDefault(d => d.Value.Any(en => en.Address == SearchKnowAddress(IP))); Output.WriteLine($"WP = {WP:00000} - '{wpEntry.Key}', IP = {IP:00000} - '{ipEntry.Key}'"); if (RS.Any()) { Output.WriteLine("Stack trace..."); foreach (var a in RS) { var ka = SearchKnowAddress(a); var sEntry = Entries.FirstOrDefault(d => d.Value.Any(en => en.Address == ka)); Output.WriteLine($"...{a:00000} -- {sEntry.Key}"); } RS.Clear(); DS.Clear(); } else if (address < Core.Count) { var entry = Entries.FirstOrDefault(d => d.Value.Any(en => en.Address == address)); Output.WriteLine($"Core word is {entry.Key}"); } IP = WP = 0; } }
When the interpreter is in compilation mode and the word is not marked for immediate execution, its address must be recorded in memory.
public void AddOp(object op) { Mem[Here++] = op; }
The here variable stores the address of the next free cell. Since this variable should be accessible from the runtime environment as a variable of the Fort language, the value here is stored in the program memory at a given offset.
public int _hereShift; public int Here { get => (int)Mem[_hereShift]; set => Mem[_hereShift] = value; }
In order to distinguish between a numerical constant and a word address during interpretation, a compilation of the word doLit is compiled before each constant, which reads the next value in memory and places it on the data stack.
public void DoLit() { DS.Push(Mem[IP++]); }
We have described address and text interpreters, further development consists in filling the nucleus with atoms. Different versions of "Fort" have a different set of basic words, the most minimalistic implementation will be, perhaps, eForth, which contains only 31 primitives. Because the primitive runs faster than compound user words, minimal Fort implementations are usually slower than verbose implementations. A comparison of the set of words of several versions of interpreters can be found here .
In the interpreter described here, I also tried not to unnecessarily inflate the dictionary of basic words. But for ease of integration with the .net platform, I decided to implement math, Boolean operations and, of course, reflection through a set of primitives. At the same time, some of the words that are often primitive in Fort implementations are missing here, implying implementation by means of the interpreter.
At the time of writing, the basic set is 68 words.
// Core SetCoreWord("nop", Nop); SetCoreWord("next", Next); SetCoreWord("doList", DoList); SetCoreWord("exit", Exit); SetCoreWord("execute", Execute); SetCoreWord("doLit", DoLit); SetCoreWord(":", BeginDefWord); SetCoreWord(";", EndDefWord, true); SetCoreWord("branch", Branch); SetCoreWord("0branch", ZBranch); SetCoreWord("here", GetHereAddr); SetCoreWord("quit", Quit); SetCoreWord("dump", Dump); SetCoreWord("words", Words); SetCoreWord("'", Tick); SetCoreWord(",", Comma); SetCoreWord("[", Lbrac, true); SetCoreWord("]", Rbrac); SetCoreWord("immediate", Immediate, true); // Mem SetCoreWord("!", WriteMem); SetCoreWord("@", ReadMem); SetCoreWord("variable", Variable); SetCoreWord("constant", Constant); // RW SetCoreWord(".", Dot); SetCoreWord(".s", DotS); SetCoreWord("cr", Cr); SetCoreWord("bl", Bl); SetCoreWord("word", ReadWord, true); SetCoreWord("s\"", ReadString, true); SetCoreWord("key", Key); // Comment SetCoreWord("(", Comment, true); SetCoreWord("\\", CommentLine, true); // .net mem SetCoreWord("null", Null); SetCoreWord("new", New); SetCoreWord("type", GetType); SetCoreWord("m!", SetMember); SetCoreWord("m@", GetMember); SetCoreWord("ms@", GetStaticMember); SetCoreWord("ms!", SetStaticMember); SetCoreWord("load-assembly", LoadAssembly); SetCoreWord("invk", invk); // Boolean SetCoreWord("true", True); SetCoreWord("false", False); SetCoreWord("and", And); SetCoreWord("or", Or); SetCoreWord("xor", Xor); SetCoreWord("not", Not); SetCoreWord("invert", Invert); SetCoreWord("=", Eql); SetCoreWord("<>", NotEql); SetCoreWord("<", Less); SetCoreWord(">", Greater); SetCoreWord("<=", LessEql); SetCoreWord(">=", GreaterEql); // Math SetCoreWord("-", Minus); SetCoreWord("+", Plus); SetCoreWord("*", Multiply); SetCoreWord("/", Devide); SetCoreWord("mod", Mod); SetCoreWord("1+", Inc); SetCoreWord("1-", Dec); // Stack SetCoreWord("drop", Drop); SetCoreWord("swap", Swap); SetCoreWord("dup", Dup); SetCoreWord("over", Over); SetCoreWord("rot", Rot); SetCoreWord("nrot", Nrot);
To define new user words, two kernel words are used: “:” and “;”. The word “:” reads the name of a new word from the input stream, creates a header with this key, the address of the base word doList is added to the program memory, and the interpreter is put into compilation mode. All subsequent words will be compiled, with the exception of those marked as immediate.
public void BeginDefWord() { AddHeader(ReadWord(Input)); AddOp(LookUp("doList").Address); IsEvalMode = false; }
Compilation ends with the word “;”, which writes the address of the word “exit” into the program memory and puts it into interpretation mode. Now you can define custom words - for example, loops, a conditional statement, and others.
Eval(": ? @ . ;"); Eval(": allot here @ + here ! ;"); Eval(": if immediate doLit [ ' 0branch , ] , here @ 0 , ;"); Eval(": then immediate dup here @ swap - swap ! ;"); Eval(": else immediate [ ' branch , ] , here @ 0 , swap dup here @ swap - swap ! ;"); Eval(": begin immediate here @ ;"); Eval(": until immediate doLit [ ' 0branch , ] , here @ - , ;"); Eval(": again immediate doLit [ ' branch , ] , here @ - , ;"); Eval(": while immediate doLit [ ' 0branch , ] , here @ 0 , ;"); Eval(": repeat immediate doLit [ ' branch , ] , swap here @ - , dup here @ swap - swap ! ;"); Eval(": // immediate [ ' \\ , ] ;"); // C like comment
I will not describe the rest of the standard words - on the network on the corresponding thematic resources there is enough information on them. To interact with the platform, I defined 9 words:
- "Null" - pushes null onto the stack;
- “Type” - pushes the class type onto the stack of “word TrueForth.MyClass type”;
- “New” - takes the type from the stack, creates an instance of the class and places it on the stack, constructor arguments, if any, must also be on the stack “word TrueForth.MyClass type new”;
- “M!” - takes an instance of an object, field name, value from the stack, and assigns a value to the specified field;
- “M @” - picks up an instance of an object from the stack, the field name and returns the value of the field to the stack;
- “Ms!” And “ms @” - similar to the previous ones, but for static fields, instead of an instance, the stack must have a type;
- "Load-assembly" - takes from the stack, let it to the assembly and loads into memory;
- “Invk” - takes the delegate, arguments from the stack and calls it “1133 word SomeMethod word TrueForth.MyClass type new m @ invk”.
I described the main points of the implementation of the Fort language, this implementation does not seek to support ANSI standards for the language, since its task is to implement an engine for building DSL, and not to implement a general-purpose language. In most cases, the developed interpreter is enough to build a simple language of the subject area.
There are several ways to use the above interpreter. For example, you can create an instance of the interpreter, and then submit an initialization script to the input, in which the necessary words are determined. The latter through reflection interact with the system.
public static bool Init4Th() { Interpreter = new OForth(); if (File.Exists(InitFile)) { Interpreter.Eval(File.ReadAllText(InitFile)); return true; } else { Console.WriteLine($" {InitFile} !"); return false; } }
Report Distribution System Configuration Example
( ***** ***** ) word GetFReporter word ReportProvider.FlexReports.FReporterEntry type new m@ invk constant fr // : word ReportProvider.FlexReports.FDailyReport type new ; // : word AddReport fr m@ invk ; // : [ ' word , ] ; // : [ ' word , ] ; // : [ ' s" , ] ; // , " : ; // : dup [ ' word , ] swap word MailSql swap m! ; : dup [ ' word , ] swap word XlsSql swap m! ; ( ***** ***** ) cr s" " . cr cr " 08:00 mail@tinkoff.ru seizure.sql , " 08:00 mail@tinkoff.ru fixed-errors-top.sql fixed-errors.sql WO" 08:00 mail@tinkoff.ru wo-wait-complect-dates.sql " 07:30 mail@tinkoff.ru top-previous-input-errors.sql previous-input-errors.sql " 10:00 mail@tinkoff.ru collection-report.sql BPM " 08:00 mail@tinkoff.ru bpm-inbox-report.sql ScanDoc3 7 " 07:50 mail@tinkoff.ru new-sd3-complects-prevew.sql new-sd3-complects.sql ( ******************************** ) cr s" " . cr
You can do otherwise: pass ready-made objects to the input of the interpreter through the data stack and then interact with them through the interpreter. As, for example, I did to restore the device settings for receiving scans of documents, a scanner, a webcam or a virtual device (for debugging or training). In this case, the set of parameters, settings, the initialization order of different devices is very different and trivially solved through the fort-interpreter.
var interpreter = new OForth(); interpreter.DS.Push(this); // Push current instance on DataStack interpreter.Eval("constant arctium"); // Define constant with the instance if (File.Exists(ConfigName)) { interpreter.Eval(File.ReadAllText(ConfigName)); }
The configuration is generated programmatically, it turns out something like this:
s" @device:pnp:\\?\usb#vid_2b16&pid_6689&mi_00#6&1ef84f63&0&0000#{65e8773d-8f56-11d0-a3b9-00a0c9223196}\global" s" Doccamera" word Scanning.Devices.PhotoScanner.PhotoScannerDevice type new dup s" 3264x2448, FPS:20, BIT:24" swap word SetSnapshotMode swap m@ invk dup s" 1280x720, FPS:30, BIT:24" swap word SetPreviewMode swap m@ invk word SetActiveDevice arctium m@ invk
By the way, the scripts * .ps and * .pdf are generated in a similar way, because both PostScript and Pdf are essentially a subset of the “Fort”, but they are used exclusively for rendering documents on the screen or printer.
It is just as easy to implement interactive mode for console and not only applications. To do this, you must first initialize the system through the prepared script, then start the interpretation by setting the interpreter on the standard input STDIN.
var interpreter = new OForth(); const string InitFile = "Init.4th"; if (File.Exists(InitFile)) { interpreter.Eval(File.ReadAllText(InitFile)); } else { Console.WriteLine($" {InitFile} !"); } interpreter.Eval(Console.In); // Start interactive console
The initialization script may be like this:
( ***** ***** ) word ComplectBuilder.Program type constant main // : mode! [ ' word , ] word Mode main ms! ; // : init word Init main ms@ invk ; // : load [ ' word , ] word LoadFile main ms@ invk ; // : start word StartProcess main ms@ invk ; // : count word Count main ms@ invk ; // : all count ; // ( ***** ***** ) init cr cr s" , help" . cr cr ( ***** ***** ) : help s" :" . cr s" load scandoc_test.csv 0 all start" . cr bl bl s" load scandoc_test.csv -- " . cr bl bl s" 0 all start -- , 0 all " . cr cr s" DEV TEST PROD:" . cr s" mode! DEV init" . cr s" :" . cr s" word Mode main ms@ . cr" . cr ;
As input, there can be not only a console or text from a TextBox application with a UI, but also a network. In this case, you can implement simple interactive control, for example, a service, for debugging, starting, stopping components. The possibilities of such use are limited by the imagination of the developer and the task to be solved. , UI - .
. , , .
, :
public void Callback(string word, MulticastDelegate action) { if (string.IsNullOrWhiteSpace(word) || word.Any(c => " \n\r\t".Any(cw => cw == c))) { throw new Exception("invalid format of word"); } DS.Push(action); Eval($": {word} [ ' doLit , , ] invk ;"); }
DS.Push(action), . , , [ ], , . ' Tick , doLit, , . Comma «,» doLit, .
, . , :
public class WoConfItem { public string ComplectType; public string Route; public string Deal; public bool IsStampQuery; }
— , :
public class WoConfig { private OForth VM; private List<WoConfItem> _conf; public WoConfig(string confFile) { _conf = new List<WoConfItem>(); VM = new OForth(); // VM.Callback("new-conf", new Action(ClearConf)); VM.Callback("{", new Func<WoConfItem>(NewConf)); VM.Callback("}", new Action<WoConfItem>(AddConf)); VM.Callback("complect-type", new Func<WoConfItem,string,WoConfItem>(ConfComplectType)); VM.Callback("route", new Func<WoConfItem,string,WoConfItem>(ConfRoute)); VM.Callback("deal", new Func<WoConfItem,string,WoConfItem>(ConfDeal)); VM.Callback("is-stamp-query", new Func<WoConfItem,bool,WoConfItem>(ConfIsStampQuery)); // , , var initScript = new StringBuilder(); initScript.AppendLine(": complect-type [ ' word , ] swap complect-type ;"); initScript.AppendLine(": route [ ' word , ] swap route ;"); initScript.AppendLine(": deal [ ' word , ] swap deal ;"); initScript.AppendLine(": is-stamp-query ' execute swap is-stamp-query ;"); VM.Eval(initScript.ToString()); // WatchConfig(confFile); } private void ReadConfig(string path) { using (var reader = new StreamReader(File.OpenRead(path), Encoding.Default)) { VM.Eval(reader); } } readonly Func<string, bool> _any = s => s == "*"; public WoConfItem GetConf(string complectType, string routeId) { return _conf?.FirstOrDefault(cr => (cr.ComplectType == complectType || _any(cr.ComplectType)) && (cr.Route == routeId || _any(cr.Route)) ); } public bool IsAllow(string complectType, string routeId) { return GetConf(complectType, routeId) != null; } void WatchConfig(string path) { var directory = Path.GetDirectoryName(path); var fileName = Path.GetFileName(path); // , if (!File.Exists(path)) { if (!Directory.Exists(directory)) { Directory.CreateDirectory(directory); } var sb = new StringBuilder(); sb.AppendLine("\\ WO passport configuration"); sb.AppendLine("new-conf"); sb.AppendLine(""); sb.AppendLine("\\ Config rules"); sb.AppendLine("\\ { -- begin config item, } -- end config item, * -- match any values"); sb.AppendLine("\\ Example:"); sb.AppendLine("\\ { complect-type * route offer deal 100500 is-stamp-query true }"); sb.AppendLine(""); File.WriteAllText(path, sb.ToString(), Encoding.Default); } // ReadConfig(path); // var fsWatcher = new FileSystemWatcher(directory, fileName); fsWatcher.Changed += (sender, args) => { try { fsWatcher.EnableRaisingEvents = false; // , // , // Thread.Sleep(1000); ReadConfig(path); } catch (Exception e) { Console.WriteLine(e); } finally { fsWatcher.EnableRaisingEvents = true; } }; fsWatcher.EnableRaisingEvents = true; } // , void ClearConf() { _conf.Clear(); } void AddConf(WoConfItem conf) { _conf.Add(conf); } static WoConfItem NewConf() { return new WoConfItem(); } static WoConfItem ConfComplectType(WoConfItem conf, string complectType) { conf.ComplectType = complectType; return conf; } static WoConfItem ConfRoute(WoConfItem conf, string route) { conf.Route = route; return conf; } static WoConfItem ConfDeal(WoConfItem conf, string deal) { conf.Deal = deal; return conf; } static WoConfItem ConfIsStampQuery(WoConfItem conf, bool isStampQuery) { conf.IsStampQuery = isStampQuery; return conf; } }
:
\ WO passport configuration new-conf \ Config rules \ { -- begin config item, } -- end config item, * -- match any values \ Example: \ { complect-type * route offer deal 100500 is-stamp-query true } \ ***** offer ***** { complect-type offer route offer is-stamp-query false deal 5c18e87bfeed2b0b883fd4df } { complect-type KVK route offer is-stamp-query true deal 5d03a8a1edf8af0001876df0 } { complect-type offer-cred route offer is-stamp-query true deal 5d03a8a1edf8af0001876df0 } { complect-type offer-dep route offer is-stamp-query true deal 5d03a8a1edf8af0001876df0 } { complect-type quick-meeting route offer is-stamp-query true deal 5d03a8a1edf8af0001876df0 } { complect-type exica route offer is-stamp-query true deal 5d03a894e2f5850001435492 } { complect-type reissue route offer is-stamp-query true deal 5d03a894e2f5850001435492 } \ ***** offer-flow ***** { complect-type KVK route offer-flow is-stamp-query true deal 5d03a8a1edf8af0001876df0 } { complect-type offer-cred route offer-flow is-stamp-query true deal 5d03a8a1edf8af0001876df0 } { complect-type offer-dep route offer-flow is-stamp-query true deal 5d03a8a1edf8af0001876df0 } { complect-type reissue route offer-flow is-stamp-query true deal 5d03a894e2f5850001435492 }
, , DSL — .
, «». DSL.
, , — , , , , — . , .
— , . — , — !
, .
- .
Good luck