 In October, the second programming championship was held. We received 12,500 applications, more than 6,000 people tried their hand at competitions. This time, the participants could choose one of the following tracks: backend, frontend, mobile development and machine learning. Each track required to pass the qualification stage and the final.
In October, the second programming championship was held. We received 12,500 applications, more than 6,000 people tried their hand at competitions. This time, the participants could choose one of the following tracks: backend, frontend, mobile development and machine learning. Each track required to pass the qualification stage and the final.
By tradition, we will publish analysis of tracks on Habré. Let's start with the tasks of the qualification phase of machine learning. The team prepared five such tasks, of which there were two options for three tasks: in the first version there were tasks A1, B1 and C, in the second - A2, B2 and C. The options were randomly distributed between the participants. The author of task C is our developer Pavel Parkhomenko, the rest of the tasks were made by his colleague Nikita Senderovich.
For the first simple algorithmic task (A1 / A2), participants could get 50 points by correctly enumerating the answer. For the second task (B1 / B2) we gave from 10 to 100 points - depending on the effectiveness of the solution. To get 100 points, it was required to implement the dynamic programming method. The third task was devoted to constructing a click model based on the provided training data. It required the application of methods for working with categorical attributes and the use of a non-linear learning model (for example, gradient boosting). For the task it was possible to get up to 150 points - depending on the value of the loss function on the test sample.
A1. Restore the length of the carousel
Condition
| Time limit | 1 s |
| Memory limit | 256 MB |
| Enter | standard input or input.txt |
| Output | standard output or output.txt |
A carousel is a horizontal ribbon of cards, each of which offers to subscribe to a specific source or topic. The same card can occur several times in a carousel. The carousel can be scrolled from left to right, and after the last card, the user again sees the first one. For the user, the transition from the last card to the first is invisible, from his point of view the tape is endless.
At some point, a curious user Vasily noticed that the tape was actually looped, and decided to find out the true length of the carousel. To do this, he began to scroll through the tape and sequentially write out the meeting cards, for simplicity, designating each card with a lowercase Latin letter. So Vasily wrote the first n cards on a piece of paper. It is guaranteed that he looked at all the carousel cards at least once. Then Vasily went to bed, and in the morning he discovered that someone had spilled a glass of water on his notes and now some letters could not be recognized.
According to the remaining information, help Vasily determine the smallest possible number of cards in the carousel.
I / O Formats and Examples
The first line contains a single integer n (1 ≤ n ≤ 1000) - the number of characters written by Vasily.
The second line contains the sequence written by Vasily. It consists of n characters - lowercase Latin letters and the # sign, which means that the letter at this position cannot be recognized.
Print a single integer positive number - the smallest possible number of cards in the carousel.
In the first example, all the letters were recognized, the minimum carousel could consist of 3 cards - abc.
In the second example, all the letters were recognized, the minimum carousel could consist of 3 cards - abb. Please note that the second and third cards in this carousel are the same.
In the third example, the smallest possible carousel length is obtained if we assume that the symbol a was in the third position. Then the initial line is ababa, the minimum carousel consists of 2 cards - ab.
In the fourth example, the source string could be anything, for example ffffff. Then the carousel could consist of one card - f.
Input format
The first line contains a single integer n (1 ≤ n ≤ 1000) - the number of characters written by Vasily.
The second line contains the sequence written by Vasily. It consists of n characters - lowercase Latin letters and the # sign, which means that the letter at this position cannot be recognized.
Output format
Print a single integer positive number - the smallest possible number of cards in the carousel.
Example 1
| Enter | Output |
5
| 3
|
Example 2
| Enter | Output |
7
| 3
|
Example 3
| Enter | Output |
5
| 2
|
Example 4
| Enter | Output |
6
| 1
|
Notes
In the first example, all the letters were recognized, the minimum carousel could consist of 3 cards - abc.
In the second example, all the letters were recognized, the minimum carousel could consist of 3 cards - abb. Please note that the second and third cards in this carousel are the same.
In the third example, the smallest possible carousel length is obtained if we assume that the symbol a was in the third position. Then the initial line is ababa, the minimum carousel consists of 2 cards - ab.
In the fourth example, the source string could be anything, for example ffffff. Then the carousel could consist of one card - f.
Rating system
Only after passing all the tests for the task can you get 50 points .
In the testing system, tests 1–4 are examples from the condition.
Decision
It was enough to sort out the possible length of the carousel from 1 to n and for each fixed length check if it could be such. It is clear that the answer always exists, since the value of n is guaranteed to be a possible answer. For a fixed carousel length p, it suffices to verify that in the transmitted line for all i from 0 to (p - 1) at all positions i, i + p, i + 2p, etc., there are the same characters or #. If at least for some i there are 2 different characters from the range from a to z, then the carousel cannot be of length p. Since in the worst case, for each p, you need to run through all the characters of the string once, the complexity of this algorithm is O (n 2 ).
def check_character(char, curchar): return curchar is None or char == "#" or curchar == char def need_to_assign_curchar(char, curchar): return curchar is None and char != "#" n = int(input()) s = input().strip() for p in range(1, n + 1): is_ok = True for i in range(0, p): curchar = None for j in range(i, n, p): if not check_character(s[j], curchar): is_ok = False break if need_to_assign_curchar(s[j], curchar): curchar = s[j] if not is_ok: break if is_ok: print(p) break
A2. Restore the length of the carousel
Condition
| Time limit | 1 s |
| Memory limit | 256 MB |
| Enter | standard input or input.txt |
| Output | standard output or output.txt |
A carousel is a horizontal ribbon of cards, each of which offers to subscribe to a specific source or topic. The same card can occur several times in a carousel. The carousel can be scrolled from left to right, and after the last card, the user again sees the first one. For the user, the transition from the last card to the first is invisible, from his point of view the tape is endless.
At some point, a curious user Vasily noticed that the tape was actually looped, and decided to find out the true length of the carousel. To do this, he began to scroll through the tape and sequentially write out the meeting cards, for simplicity, designating each card with a lowercase Latin letter. So Vasily wrote out the first n cards. It is guaranteed that he looked at all the carousel cards at least once. Since Vasily was distracted by the contents of the cards, when writing out, he could mistakenly replace one letter with another, but it is known that he made no more than k mistakes in total.
The records made by Vasily fell into your hands; you also know the value of k. Determine how few cards could be in his carousel.
I / O Formats and Examples
The first line contains two integers: n (1 ≤ n ≤ 500) - the number of characters written by Basil, and k (0 ≤ k ≤ n) - the maximum number of errors that Vasily made.
The second line contains n lowercase letters of the Latin alphabet - the sequence written by Vasily.
Print a single integer positive number - the smallest possible number of cards in the carousel.
In the first example, k = 0, and we know for sure that Vasily was not mistaken, the minimum carousel could consist of 3 cards - abc.
In the second example, the smallest possible carousel length is obtained if we assume that Vasily mistakenly replaced the third letter a with c. Then the real line is ababa, the minimum carousel consists of 2 cards - ab.
In the third example, it is known that Vasily could make one mistake. However, the size of the carousel is minimal, assuming that he did not make mistakes. The minimum carousel consists of 3 cards - abb. Please note that the second and third cards in this carousel are the same.
In the fourth example, we can say that Vasily was mistaken in entering all the letters, and the original line could actually be any, for example ffffff. Then the carousel could consist of one card - f.
Input format
The first line contains two integers: n (1 ≤ n ≤ 500) - the number of characters written by Basil, and k (0 ≤ k ≤ n) - the maximum number of errors that Vasily made.
The second line contains n lowercase letters of the Latin alphabet - the sequence written by Vasily.
Output format
Print a single integer positive number - the smallest possible number of cards in the carousel.
Example 1
| Enter | Output |
5 0
| 3
|
Example 2
| Enter | Output |
5 1
| 2
|
Example 3
| Enter | Output |
7 1
| 3
|
Example 4
| Enter | Output |
6 6
| 1
|
Notes
In the first example, k = 0, and we know for sure that Vasily was not mistaken, the minimum carousel could consist of 3 cards - abc.
In the second example, the smallest possible carousel length is obtained if we assume that Vasily mistakenly replaced the third letter a with c. Then the real line is ababa, the minimum carousel consists of 2 cards - ab.
In the third example, it is known that Vasily could make one mistake. However, the size of the carousel is minimal, assuming that he did not make mistakes. The minimum carousel consists of 3 cards - abb. Please note that the second and third cards in this carousel are the same.
In the fourth example, we can say that Vasily was mistaken in entering all the letters, and the original line could actually be any, for example ffffff. Then the carousel could consist of one card - f.
Rating system
Only after passing all the tests for the task can you get 50 points .
In the testing system, tests 1–4 are examples from the condition.
Decision
It was enough to sort out the possible length of the carousel from 1 to n and for each fixed length check if it could be such. It is clear that the answer always exists, since the value of n is guaranteed to be a possible answer, whatever the value of k. For a fixed carousel length p, it suffices to calculate, independently for all i from 0 to (p - 1), what is the minimum number of errors made at positions i, i + p, i + 2p, etc. This number of errors is minimal if taken as true the symbol is the one that occurs most often in these positions. Then the number of errors is equal to the number of positions on which another letter stands. If for some p the total number of errors does not exceed k, then the value p is a possible answer. Since for each p you need to go over all the characters of the string once, the complexity of this algorithm is O (n 2 ).
n, k = map(int, input().split()) s = input().strip() for p in range(1, n + 1): mistakes = 0 for i in range(0, p): counts = [0] * 26 for j in range(i, n, p): counts[ord(s[j]) - ord("a")] += 1 mistakes += sum(counts) - max(counts) if mistakes <= k: print(p) break
B1. Optimal recommendation tape
Condition
| All languages | Oracle Java 8 | GNU c ++ 17 7.3 | |
| Time limit | 5 s | 3 s | 1 s |
| Memory limit | 256 MB | ||
| Enter | standard input or input.txt | ||
| Output | standard output or output.txt | ||
In order for the user’s feed to be diverse, it is necessary to choose among m candidates n publications so that among them there are at least A 1 publications having the first property, at least A 2 publications having the second property, ..., A k publications having the property of number k. Find the maximum possible total relevance score for m publications that satisfy this requirement, or determine that such a set of publications does not exist.
I / O Formats and Examples
The first line contains three integers - n, m, k (1 ≤ n ≤ 50, 1 ≤ m ≤ min (n, 9), 1 ≤ k ≤ 5).
The next n lines show the characteristics of publications. For the i-th publication, an integer s i (1 ≤ s i ≤ 10 9 ) is given - an assessment of the relevance of this publication, and then, after a space, a string of k characters, each of which is 0 or 1 - the values of each attribute of this publication.
The last line contains k integers separated by spaces - the values A 1 , ..., A k (0 ≤ A i ≤ m) that define the requirements for the final set of m publications.
If there is no set of m publications satisfying the restrictions, print the number 0. Otherwise, print a single integer positive number - the maximum possible total relevance score.
In the first example, from four publications with two properties, two should be selected so that there is at least one publication that has the first property and one that has the second property. The largest amount of relevance can be obtained if we take the second and third publications, although any option with a fourth publication is also suitable for restrictions.
In the second example, it is impossible to select two publications so that both have the second property, because only the first publication has it.
Input format
The first line contains three integers - n, m, k (1 ≤ n ≤ 50, 1 ≤ m ≤ min (n, 9), 1 ≤ k ≤ 5).
The next n lines show the characteristics of publications. For the i-th publication, an integer s i (1 ≤ s i ≤ 10 9 ) is given - an assessment of the relevance of this publication, and then, after a space, a string of k characters, each of which is 0 or 1 - the values of each attribute of this publication.
The last line contains k integers separated by spaces - the values A 1 , ..., A k (0 ≤ A i ≤ m) that define the requirements for the final set of m publications.
Output format
If there is no set of m publications satisfying the restrictions, print the number 0. Otherwise, print a single integer positive number - the maximum possible total relevance score.
Example 1
| Enter | Output |
4 2 2
| 11
|
Example 2
| Enter | Output |
3 2 2
| 0
|
Notes
In the first example, from four publications with two properties, two should be selected so that there is at least one publication that has the first property and one that has the second property. The largest amount of relevance can be obtained if we take the second and third publications, although any option with a fourth publication is also suitable for restrictions.
In the second example, it is impossible to select two publications so that both have the second property, because only the first publication has it.
Rating system
Tests for this task consist of five groups. Points for each group are awarded only when passing all tests of the group and all tests of previous groups. Passing tests from the conditions is necessary to get points for groups starting from the second. In total for the task you can get 100 points .
In the testing system, tests 1-2 are examples from the condition.
1. (10 points) tests 3–10: k = 1, m ≤ 3, s i ≤ 1000, no tests are required from the condition
2. (20 points) tests 11–20: k ≤ 2, m ≤ 3
3. (20 points) tests 21–29: k ≤ 2
4. (20 points) tests 30–37: k ≤ 3
5. (30 points) tests 38–47: no additional restrictions
Decision
There are n publications, each has speed and k Boolean flags, it is necessary to select m cards such that the sum of relevances is maximum and k requirements of the form “among the selected m publications must have ≥ A i cards with the i-th flag” are fulfilled, or determine that such a set of publications does not exist.
The decision is 10 points : if there is exactly one flag, it is enough to take A 1 publications with this flag that are of the most relevance (if there are less such cards than A 1 , then the desired set does not exist), and the rest (m - A 1 ) should be collected cards with the best relevance.
The decision is 30 points : if m does not exceed 3, then you can find the answer by exhaustive search of all possible O (n 3 ) triples of cards, choose the best option in terms of total relevance that satisfies the restrictions.
The decision is 70 points (50 points is the same, it’s easier to implement): if there are no more than 3 flags, then you can divide all publications into 8 disjoint groups according to the set of flags that they have: 000, 001, 010, 011, 100, 101, 110, 111. Publications in each group must be sorted in descending order of relevance. Then, for O (m 4 ), we can sort out how many best publications we take from groups 111, 011, 110 and 101. From each we take from 0 to m publications, in total no more than m. After this, it becomes clear how many publications need to be collected from groups 100, 010 and 001 in order to satisfy the requirements. It remains to get to m with the remaining cards with the best relevance.
Complete solution : consider the dynamic programming function dp [i] [a] ... [z]. This is the maximum total relevance score that can be obtained using exactly i publications so that there are exactly a publications with flag A, ..., z publications with flag Z. Then, initially dp [0] [0] ... [0] = 0, and for all other sets of parameters we set the value equal to -1 in order to maximize this value in the future. Next, we will “enter the game” cards one at a time and with each card improve the values of this function: for each state of dynamics (i, a, b, ..., z) using the j-th publication with flags (a j , b j , ..., z j ), one can try to make a transition to the state (i + 1, a + a j , b + b j , ..., z + z j ) and check if the result improves in this state. Important: during the transition, we are not interested in states where i ≥ m, therefore, the total states of such dynamics are no more than m k + 1 , and the resulting asymptotic behavior is O (nm k + 1 ). When the states of dynamics are calculated, the answer is a state that satisfies the constraints and gives the highest total relevance score.
From the point of view of implementation, to speed up the work of the program, it is useful to store the state of dynamic programming and the flags of each publication in packed form in one whole number (see code), and not in the list or tuple. This solution uses less memory and allows you to effectively update the state of the dynamics.
Complete Solution Code:
def pack_state(num_items, counts): result = 0 for count in counts: result = (result << 8) + count return (result << 8) + num_items def get_num_items(state): return state & 255 def get_flags_counts(state, num_flags): flags_counts = [0] * num_flags state >>= 8 for i in range(num_flags): flags_counts[num_flags - i - 1] = state & 255 state >>= 8 return flags_counts n, m, k = map(int, input().split()) scores, attributes = [], [] for i in range(n): score, flags = input().split() scores.append(int(score)) attributes.append(list(map(int, flags))) limits = list(map(int, input().split())) dp = {0 : 0} for i in range(n): score = scores[i] state_delta = pack_state(1, attributes[i]) dp_temp = {} for state, value in dp.items(): if get_num_items(state) >= m: continue new_state = state + state_delta if value + score > dp.get(new_state, -1): dp_temp[new_state] = value + score dp.update(dp_temp) best_score = 0 for state, value in dp.items(): if get_num_items(state) != m: continue flags_counts = get_flags_counts(state, k) satisfied_bounds = True for i in range(k): if flags_counts[i] < limits[i]: satisfied_bounds = False break if not satisfied_bounds: continue if value > best_score: best_score = value print(best_score)
B2. Function approximation
Condition
| Time limit | 2 s |
| Memory limit | 256 MB |
| Enter | standard input or input.txt |
| Output | standard output or output.txt |
Let a discrete function f be defined at the points i = 1, 2, ..., n. It is necessary to find a piecewise constant function g consisting of no more than k sections of constancy such that the value SSE = (g (i) - f (i)) 2 is minimal.
I / O Formats and Examples
The first line contains two integers n and k (1 ≤ n ≤ 300, 1 ≤ k ≤ min (n, 10)).
The second line contains n integers f (1), f (2), ..., f (n) - the values of the approximate function at points 1, 2, ..., n (–10 6 ≤ f (i) ≤ 10 6 ).
Print a single number - the minimum possible value of SSE. The answer is considered correct if the absolute or relative error does not exceed 10 –6 .
In the first example, the optimal function g is the constant g (i) = 2.
SSE = (2 - 1) 2 + (2 - 2) 2 + (2 - 3) 2 = 2.
In the second example, there are 2 options. Either g (1) = 1 and g (2) = g (3) = 2.5, or g (1) = g (2) = 1.5 and
g (3) = 3. In any case, SSE = 0.5.
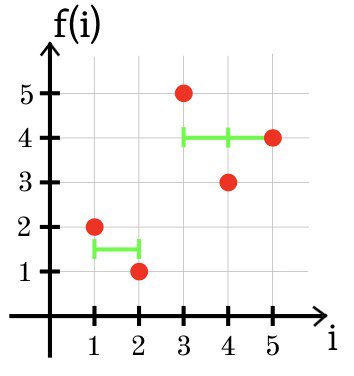
In the third example, the optimal approximation of the function f using two sections of constancy is shown below: g (1) = g (2) = 1.5 and g (3) = g (4) = g (5) = 4.
SSE = (1.5 + 2) 2 + (1.5 - 1) 2 + (4 - 5) 2 + (4 - 3) 2 + (4 - 4) 2 = 2.5.
Input format
The first line contains two integers n and k (1 ≤ n ≤ 300, 1 ≤ k ≤ min (n, 10)).
The second line contains n integers f (1), f (2), ..., f (n) - the values of the approximate function at points 1, 2, ..., n (–10 6 ≤ f (i) ≤ 10 6 ).
Output format
Print a single number - the minimum possible value of SSE. The answer is considered correct if the absolute or relative error does not exceed 10 –6 .
Example 1
| Enter | Output |
3 1
| 2.000000
|
Example 2
| Enter | Output |
3 2
| 0.500000
|
Example 3
| Enter | Output |
5 2
| 2.500000
|
Notes
In the first example, the optimal function g is the constant g (i) = 2.
SSE = (2 - 1) 2 + (2 - 2) 2 + (2 - 3) 2 = 2.
In the second example, there are 2 options. Either g (1) = 1 and g (2) = g (3) = 2.5, or g (1) = g (2) = 1.5 and
g (3) = 3. In any case, SSE = 0.5.
In the third example, the optimal approximation of the function f using two sections of constancy is shown below: g (1) = g (2) = 1.5 and g (3) = g (4) = g (5) = 4.
SSE = (1.5 + 2) 2 + (1.5 - 1) 2 + (4 - 5) 2 + (4 - 3) 2 + (4 - 4) 2 = 2.5.
Rating system
Tests for this task consist of five groups. Points for each group are awarded only when passing all tests of the group and all tests of previous groups. Passing tests from the conditions is necessary to get points for groups starting from the second. In total for the task you can get 100 points .
In the testing system, tests 1-3 are examples from the condition.
1. (10 points) tests 4–22: k = 1, no tests are required from the condition
2. (20 points) tests 23–28: k ≤ 2
3. (20 points) tests 29–34: k ≤ 3
4. (20 points) tests 35–40: k ≤ 4
5. (30 points) tests 41–46: no additional restrictions
Decision
As you know, the constant that minimizes the SSE value for a set of values f 1 , f 2 , ..., f n is the average of the values listed here. Moreover, as it is easy to verify by simple calculations, the value SSE = .
The decision is 10 points : we simply consider the average of all values of the function and SSE as O (n).
The decision is 30 points : we sort out the last point related to the first part of the constancy of two, for a fixed partition we calculate the SSE and select the optimal one. In addition, it is important not to forget to disassemble the case when there is only one section of constancy. Difficulty - O (n 2 ).
Solution for 50 points : we sort the boundaries of the partition into sections of constancy for O (n 2 ), for a fixed partition into 3 segments, we calculate the SSE and choose the optimal one. Difficulty - O (n 3 ).
The decision is 70 points : we calculate the sums and sums of squares of the values of f i on the prefixes, this will allow you to quickly calculate the average and SSE on any segment. We sort the boundaries of the partition into 4 sections of constancy for O (n 3 ), using the pre-calculated values on the prefixes for O (1), we calculate the SSE. Difficulty - O (n 3 ).
Complete solution : consider the dynamic programming function dp [s] [i]. This is the smallest SSE value if we approximate the first i values using s segments. Then
dp [0] [0] = 0, and for all other sets of parameters we set the value equal to infinity in order to further minimize this value. We will solve the problem, gradually increasing the value of s. How to calculate dp [s] [i] if the dynamics values for all smaller s are already calculated? It is enough to designate for t the number of first points covered by the previous (s - 1) segments, and sort through all the values of t, and approximate the remaining (i - t) points using the remaining segment. It is necessary to choose the best value t for the final SSE at i points. If we calculate the sums and sums of squares of the values of f i on the prefixes, then this approximation will be performed in O (1), and the value dp [s] [i] can be calculated in O (n). The final answer is dp [k] [n]. The total complexity of the algorithm is O (kn 2 ).
Complete Solution Code:
n, k = map(int, input().split()) f = list(map(float, input().split())) prefix_sum = [0.0] * (n + 1) prefix_sum_sqr = [0.0] * (n + 1) for i in range(1, n + 1): prefix_sum[i] = prefix_sum[i - 1] + f[i - 1] prefix_sum_sqr[i] = prefix_sum_sqr[i - 1] + f[i - 1] ** 2 def get_best_sse(l, r): num = r - l + 1 s_sqr = (prefix_sum[r] - prefix_sum[l - 1]) ** 2 ss = prefix_sum_sqr[r] - prefix_sum_sqr[l - 1] return ss - s_sqr / num dp_curr = [1e100] * (n + 1) dp_prev = [1e100] * (n + 1) dp_prev[0] = 0.0 for num_segments in range(1, k + 1): dp_curr[num_segments] = 0.0 for num_covered in range(num_segments + 1, n + 1): dp_curr[num_covered] = 1e100 for num_covered_previously in range(num_segments - 1, num_covered): dp_curr[num_covered] = min(dp_curr[num_covered], dp_prev[num_covered_previously] + get_best_sse(num_covered_previously + 1, num_covered)) dp_curr, dp_prev = dp_prev, dp_curr print(dp_prev[n])
C. Prediction of user clicks
Condition
One of the most important signals for a recommender system is user behavior. Such data is often enough to build a baseline of acceptable quality.
..
2 : (train.csv) (test.csv). , . :
— sample_id — id ,
— item — id ,
— publisher — id ,
— user — id ,
topic_i, weight_i — id i- ( 0 100) (i = 0, 1, 2, 3, 4),
— target — (1 — , 0 — ). .
.
, item, publisher, user, topic .
csv-, : sample_id target, sample_id — id , target — . test.csv. sample_id ( , test.csv). target 0 1.
logloss.
150 . logloss :
logloss . 2 , logloss 4 .
/
Fragment train.csv:
Snippet test.csv:
A fragment of a possible solution file:
: yadi.sk/d/pVna8ejcnQZK_A . , .
logloss :
logloss logloss .
logloss :
Input format
Fragment train.csv:
sample_id,item,publisher,user,topic_0,topic_1,topic_2,topic_3,topic_4,weight_0,weight_1,weight_2,weight_3,weight_4,target
|
sample_id,item,publisher,user,topic_0,topic_1,topic_2,topic_3,topic_4,weight_0,weight_1,weight_2,weight_3,weight_4
|
Output format
A fragment of a possible solution file:
sample_id,target
|
Notes
: yadi.sk/d/pVna8ejcnQZK_A . , .
logloss :
EPS = 1e-4
def logloss(y_true, y_pred):
if abs (y_pred - 1) < EPS:
y_pred = 1 - EPS
if abs (y_pred) < EPS:
y_pred = EPS
return -y_true ∗ log(y_pred) - (1 - y_true) ∗ log(1 - y_pred)
logloss logloss .
logloss :
def score(logloss):
if logloss > 0.5:
return 0.0
return min(150, (200 ∗ (0.5 - logloss)) ∗∗ 2)
Decision
, . . , (, , , ) , — , - , .
, 100 ( 150).
— CatBoost . CatBoost ( ), . , . , -: , , , , - ( ).
. , - , : FM (Factorization Machines) FFM (Field-aware Factorization Machines).
, ML- .