
I work as a semi-DevOps engineer in a large IT company. Our company is developing software for highly loaded services, but I am responsible for performance, maintenance and deployment. They set a standard task for me: update the application on one server. The application is written in Django, during the upgrade, migrations are performed (changing the database structure), and before this process we remove the full database dump through the standard pg_dump program just in case.
An unexpected error occurred while removing the dump (Postgres version is 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
The error "invalid page in block" indicates problems at the file system level, which is very bad. On various forums, they suggested making FULL VACUUM with the zero_damaged_pages option to solve this problem. Well, a popprobeum ...
Recovery Preparation
ATTENTION! Be sure to backup Postgres before any attempt to restore the database. If you have a virtual machine, stop the database and take a snapshot. If it is not possible to take a snapshot, stop the database and copy the contents of the Postgres directory (including wal-files) to a safe place. The main thing in our business is not to make things worse. Read this .
Since the database worked for me as a whole, I limited myself to the usual database dump, but excluded the table with damaged data (option -T, --exclude-table = TABLE in pg_dump).
The server was physical, it was impossible to take a snapshot. Backup is removed, move on.
File system check
Before attempting to restore the database, you need to make sure that everything is in order with the file system itself. And in case of errors, fix them, because otherwise you can only make it worse.
In my case, the file system with the database was mounted in “/ srv” and the type was ext4.
We stop the database: systemctl stop postgresql@9.5-main.service and verify that no one is using the file system and that it can be unmounted using the lsof command :
lsof + D / srv
I had to stop the redis database as well, as it also used "/ srv" . Next, I unmounted / srv (umount).
Checking the file system was performed using the e2fsck utility with the -f option ( Force checking even if filesystem is marked clean ):
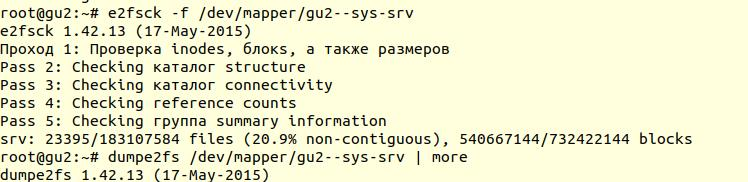
Next, using the dumpe2fs utility ( sudo dumpe2fs / dev / mapper / gu2 - sys-srv | grep checked ), you can verify that the check was indeed performed:

e2fsck says that no problems were found at the ext4 file system level, which means that you can continue to try to restore the database, or rather return to vacuum full (of course, you need to mount the file system back and start the database).
If your server is physical, be sure to check the status of the disks (via smartctl -a / dev / XXX ) or the RAID controller to make sure that the problem is not at the hardware level. In my case, the RAID turned out to be “iron”, so I asked the local administrator to check the status of the RAID (the server was several hundred kilometers from me). He said that there were no errors, which means that we can definitely begin the restoration.
Attempt 1: zero_damaged_pages
We connect to the database via psql account with superuser rights. We need exactly the superuser, because only he can change the zero_damaged_pages option. In my case, this is postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]
The zero_damaged_pages option is needed to ignore read errors (from postgrespro website):
When a damaged page title is found, Postgres Pro usually reports an error and aborts the current transaction. If the zero_damaged_pages parameter is enabled, the system instead displays a warning, clears the damaged page in memory, and continues processing. This behavior destroys data, namely all lines in a damaged page.Turn on the option and try to make full vacuum tables:
VACUUM FULL VERBOSE
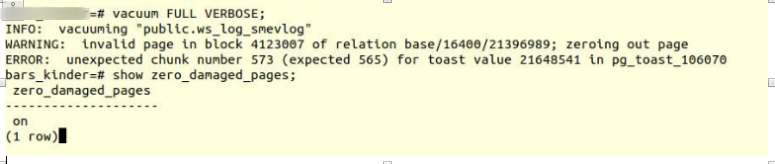
Unfortunately, failure.
We encountered a similar error:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast - the mechanism for storing "long data" in Postgres, if they do not fit on the same page (8kb by default).
Attempt 2: reindex
The first google tip didn't help. After a few minutes of searching, I found a second tip - to make reindex a damaged table. I met this advice in many places, but it did not inspire confidence. Make reindex:
reindex table ws_log_smevlog

reindex completed without problems.
However, this did not help, VACUUM FULL crashed with a similar error. Since I was used to failures, I began to look for advice on the Internet further and came across a rather interesting article .
Attempt 3: SELECT, LIMIT, OFFSET
The article above suggested looking at the table line by line and deleting the problematic data. To start, it was necessary to look at all the lines:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
In my case, the table contained 1,628,991 rows! In a good way, it was necessary to take care of the partitioning of the data , but this is a topic for a separate discussion. It was Saturday, I ran this command in tmux and went to sleep:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
By morning, I decided to check how things were going. To my surprise, I found that in 20 hours only 2% of the data was scanned! I did not want to wait 50 days. Another complete failure.
But I did not give up. I wondered why the scan took so long. From the documentation (again on postgrespro) I found out:
OFFSET indicates to skip the specified number of lines before starting to produce lines.Obviously, the above command was erroneous: firstly, there was no order by , the result could be erroneous. Secondly, Postgres first had to scan and skip OFFSET lines, and with an increase in OFFSET, performance would decrease even more.
If both OFFSET and LIMIT are specified, the system first skips OFFSET lines and then starts counting lines to limit LIMIT.
When using LIMIT, it is also important to use the ORDER BY clause so that the result lines are returned in a specific order. Otherwise, unpredictable subsets of strings will be returned.
Attempt 4: remove the dump in text form
Further, a seemingly brilliant idea came to my mind: to remove the dump in text form and analyze the last recorded line.
But first, let's look at the ws_log_smevlog table structure :

In our case, we have a column “id” , which contained a unique identifier (counter) for the row. The plan was this:
- We start to remove the dump in text form (in the form of sql commands)
- At some point in time, the dump would be interrupted due to an error, but the text file would still be saved on disk
- We look at the end of the text file, thereby we find the identifier (id) of the last line that was shot successfully
I started to remove the dump in text form:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
The dump dump, as expected, was interrupted with the same error:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Further, through tail, I looked at the end of the dump ( tail -5 ./my_dump.dump ) and found that the dump was interrupted on line with id 186 525 . “So, the problem is in the line with id 186 526, it’s broken, and it needs to be deleted!” I thought. But by making a request to the database:
“ Select * from ws_log_smevlog where id = 186529 ” it turned out that everything was fine with this line ... Lines with indices 186 530 - 186 540 also worked without problems. Another "brilliant idea" failed. Later I realized why this happened: when deleting / changing data from the table, they are not physically deleted, but are marked as “dead tuples”, then autovacuum comes and marks these lines as deleted and allows the use of these lines again. To understand, if the data in the table is changed and autovacuum is turned on, then they are not stored sequentially.
Attempt 5: SELECT, FROM, WHERE id =
Failures make us stronger. You should never give up, you need to go to the end and believe in yourself and your capabilities. So I decided to try one more option: just view all the entries in the database one at a time. Knowing the structure of my table (see above), we have an id field that is unique (primary key). In the table, we have 1,628,991 rows and id go in order, which means that we can just iterate through them one at a time:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
If someone does not understand, the command works as follows: it scans the table line by line and sends stdout to / dev / null , but if the SELECT command fails, the error text is displayed (stderr is sent to the console) and a line containing the error is output (thanks to ||, which means that select had problems (command return code is not 0)).
I was lucky, I created indexes on the id field:

This means that finding the line with the desired id should not take much time. In theory, it should work. Well, run the command in tmux and go to sleep.
By morning, I found that about 90,000 records were viewed, which is just over 5%. Excellent result when compared with the previous method (2%)! But I did not want to wait 20 days ...
Attempt 6: SELECT, FROM, WHERE id> = and id <
An excellent server was allocated for the customer under the database: dual-processor Intel Xeon E5-2697 v2 , in our location there were as many as 48 threads! The server load was average, we could take about 20 threads without any problems. RAM was also enough: as much as 384 gigabytes!
Therefore, the command needed to be parallelized:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Here it was possible to write a beautiful and elegant script, but I chose the fastest way to parallelize: manually break the range 0-1628991 into intervals of 100,000 records and run 16 commands of the form separately:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
But that's not all. In theory, connecting to a database also takes some time and system resources. Connecting 1,628,991 was not very reasonable, agree. Therefore, let's extract 1000 rows in one connection instead of one. As a result, the team transformed into this:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Open 16 windows in the tmux session and run the commands:
A day later, I got the first results! Namely (the values XXX and ZZZ have not been preserved):1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
This means that we have three lines contain an error. The id of the first and second problem records were between 829,000 and 830,000, the id of the third was between 146,000 and 147,000. Next, we just had to find the exact id value of the problem records. To do this, look through our range with problem records in step 1 and identify id:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Happy ending
We found the problematic lines. We go into the database via psql and try to delete them:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
To my surprise, the entries were deleted without any problems, even without the zero_damaged_pages option.
Then I connected to the database, made VACUUM FULL (I think it was not necessary to do it), and finally successfully removed the backup using pg_dump . The dump was shot without any errors! The problem was solved in such a stupid way. There was no limit to joy, after so many failures we managed to find a solution!
Acknowledgments and Conclusions
This is my first experience in restoring a real Postgres database. I will remember this experience for a long time.
And finally, I would like to thank PostgresPro for the translated documentation into Russian and for the completely free online courses that helped a lot during the analysis of the problem.