
Disclaimer This article is not a call to action and does not state that there is the only reasonably correct way to hide data. This article is intended to offer the reader a possibly new perspective on encapsulation. There are many situations where access modifiers are preferable, but this is not a reason to be silent about interfaces.
In general, encapsulation is defined as a means of hiding the internal implementation of an object from a client in order to preserve the integrity of the object and conceal the complexity of this very internal implementation.
There are several ways to achieve this concealment. One is the use of access modifiers, the other is the use of interfaces (protocols, header files, ...). There are other tricky features, but the article is not about them.
Access modifiers at first glance may seem more powerful in terms of hiding the implementation, since they give control over each field individually and give more access options. In reality, this is partly just a shortcut for creating several interfaces to the class. Access modifiers provide capabilities no wider than interfaces, since they express, except for one detail. About her below.
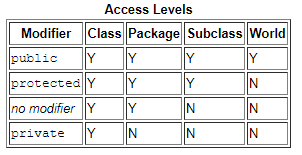
Field visibility indicated by different access modifiers in Java.
The code snippet below shows a class with access modifiers to methods and equivalent representations in the form of interfaces.
public class ConsistentObject { public void methodA() { /* ... */ } protected void methodB() { /* ... */ } void methodC() { /* ... */ } private void methodD() { /* ... */ } } public interface IPublicConsistentObject { void methodA() { /* ... */ } } public interface IProtectedConsistentObject: IPublicConsistentObject { void methodB() { /* ... */ } } public interface IDefaultConsistentObject: IProtectedConsistentObject { void methodC() { /* ... */ } }
Protocols have several advantages. It is enough to mention that this is the main means of implementing polymorphism in OOP, which reaches newcomers much later than they could.
The only difficulty approaching with the protocols is that you need to control the process of creating objects. Generating templates are needed precisely to protect dangerous code containing specific types from pure code that works with interfaces. Observing this simple rule, we get the same encapsulation as using qualifiers, but at the same time we get more flexibility.
Such code in C #
public class DataAccessObject { private void readDataFromFixedSource() { // ... } public byte[] getData() { // ... } }
It will be equivalent to such opportunities for the client.
public class DataAccessObjectFactory { public IDataAccessObject createNew() { return new DataAccessObject(); } } public interface IDataAccessObject { byte[] getData(); } class DataAccessObject: IDataAccessObject { void readDataFromFixedSource() { // ... } public byte[] getData() { // ... } }
Due to the existence of access modifiers, beginners will not know about interfaces for a very long time. Because of this, they do not use the real power of the PLO. That is, there is some substitution of concepts. Access modifiers are undoubtedly an attribute of OOP, but they also drag the blanket from interfaces that open OOP much more strongly.
Moreover, the interfaces make you consciously choose what features a client can receive from an object. That is, we have the opportunity to provide completely unrelated protocols for different clients, while modifiers do not distinguish between clients. This is a big plus in favor of interfaces.