Good day and my respect, readers of Habr!
Background
At our place, it’s customary to exchange interesting findings in development teams. At the next meeting, discussing the future of .NET and .NET 5 in particular, my colleagues and I focused on seeing a unified platform from this picture:
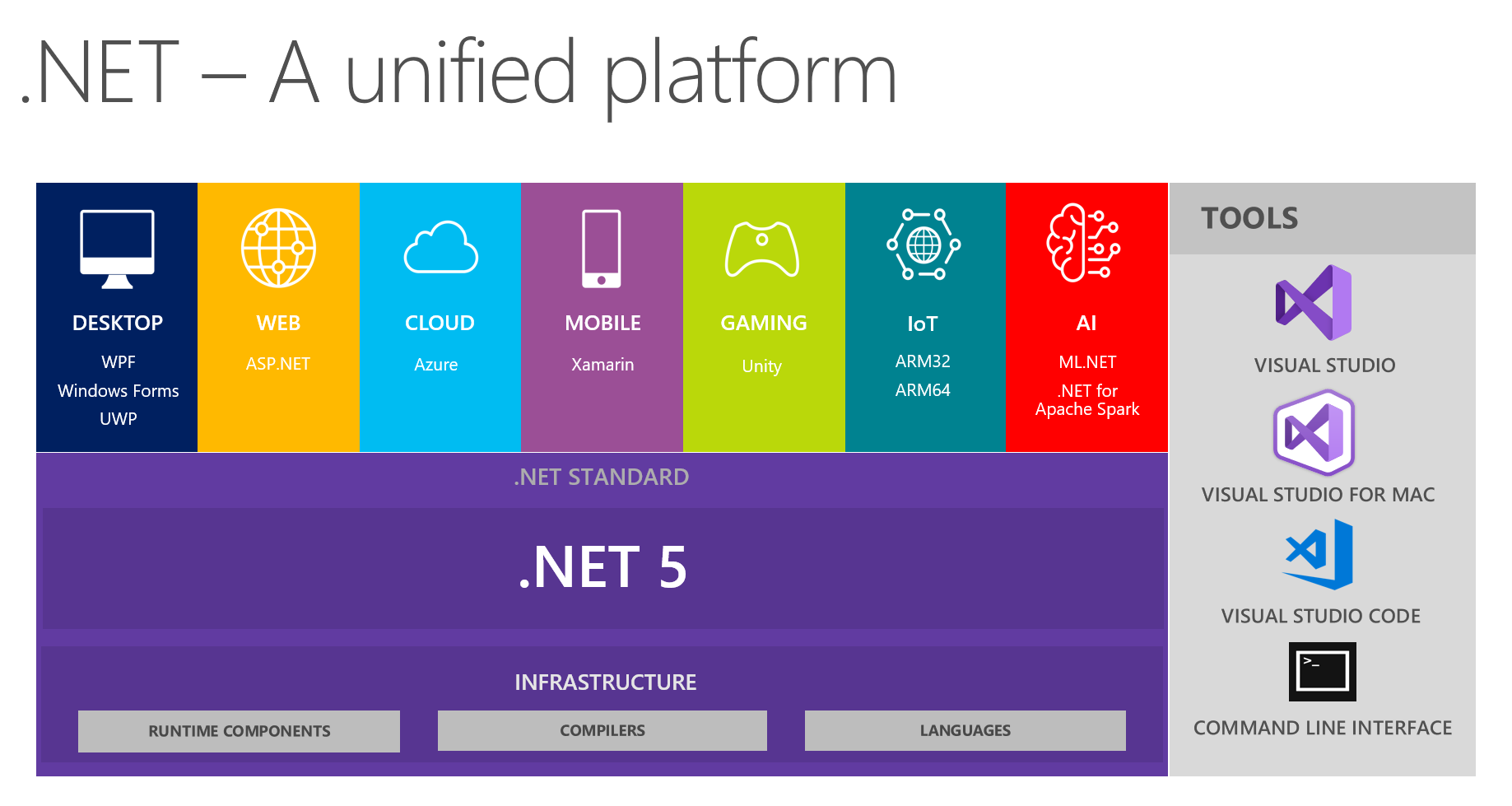
It shows that the platform combines DESKTOP, WEB, CLOUD, MOBILE, GAMING, IoT and AI. I got the idea to conduct a conversation in the form of a small report + questions / answers on each topic at the next meetings. The person responsible for a particular topic is preliminarily preparing, reading out information about the main innovations, trying to implement something using the selected technology, and then sharing his thoughts and impressions with us. As a result, everyone receives real feedback on the tools from a trusted source from the first hand - it’s very convenient, given that trying and storming all the topics yourself may not be handy, your hands won’t get corny.
Since I have been actively interested in machine learning as a hobby for some time (and sometimes use it for non-business tasks at work), I got the topic of AI & ML.NET. In the process of preparation, I came across wonderful tools and materials, to my surprise I discovered that there is very little information about them on Habré. Earlier in the official blog Microsoft wrote about the release of ML.Net , and Model Builder in particular. I would like to share how I came to him and what impressions I got from working with him. The article is more about Model Builder than ML in .NET in general; we will try to look at what MS offers to the average .NET developer, but with the eyes of a person savvy in ML. At the same time, I will try to keep a balance between retelling the tutorial, absolutely chewing for beginners and describing details for ML-specialists, who for some reason needed to come to .NET.
Main part
So, a quick googling about ML in .NET brings me to the tutorial page :
It turns out that there is a special extension for Visual Studio called Model Builder, which "allows you to add machine learning to your project with the right mouse button" (free translation). I will briefly go over the main steps of the tutorial that are offered to be done, I will add details and my thoughts.
Download and install
Push the button, download, install. The studio will have to restart.
Create your app
To get started, create a regular C # application. The tutorial suggests creating Core, but it’s also suitable for Framework. And then, in fact, ML begins - right-click on the project, then Add -> Machine Learning. The window that will appear for creating the model will be analyzed, because it is in it that all the magic happens.
Pick a scenario
Select the "script" of your application. At the moment, 5 are available (the tutorial is a bit outdated, there are 4 so far):
- Sentiment analysis - analysis of tonality, binary classification (binary classification), the text determines its emotional color, positive or negative.
- Issue classification - multiclass classification, the target label for issue (ticket, errors, support calls, etc.) can be selected as one of three mutually exclusive options
- Price prediction - regression, the classic regression problem when the output is a continuous number; in an example it is an assessment of the apartment
- Image classification - multiclass classification, but already for images
- Custom scenario - your own scenario; I’m forced to grieve that there will be nothing new in this option, just at a later stage they will let me choose one of the four options described above.
Note that there is no multilabel classification when the target method can be many at the same time (for example, a statement can be offensive, racist and obscene at the same time, and it can be none of this). For images, there is no option to select a segmentation task. I suppose that with the help of the framework they are generally solvable, however today we focus on the builder. It seems that scaling the wizard to expand the number of tasks is not a difficult task, so you should expect them in the future.
Download and add data
It is proposed to download the dataset. From the need to download to your machine, we automatically conclude that the training will take place on our local machine. This has both pluses:
- You control all the data, you can correct, change locally and repeat the experiments.
- You do not upload data to the cloud, thus maintaining privacy. After all, do not upload, yes Microsoft ? :)
and cons:
- Learning speed is limited by the resources of your local machine.
It is further proposed to select the downloaded dataset as an input of the "File" type. There is also an option to use "SQL Server" - you will need to specify the necessary server details, then select the table. If I understand correctly, it is not yet possible to specify a specific script. Below I write about the problems that I had with this option.
Train your model
At this step, various models are trained sequentially, the speed is displayed for each, and at the end the best one is selected. Oh yes, I forgot to mention that this is AutoML - i.e. the best algorithm and parameters (not sure, see below) will be selected automatically, so you do not need to do anything! It is proposed to limit the maximum training time to the number of seconds. Heuristics for the definition of this time: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train . On my machine, in the default 10 seconds, only one model learns, so I have to bet a lot more. We start, we wait.
Here I really want to add that the names of the models personally seemed a little unusual to me, for example: AveragedPerceptronBinary, FastTreeOva, SdcaMaximumEntropyMulti. The word "Perceptron" is not used very often these days, "Ova" is probably one-vs-all, and "FastTree" I find it difficult to say what.
Another interesting fact is that LightGbmMulti is among the candidate algorithms. If I understand correctly, this is the same LightGBM, the gradient boosting engine that, together with CatBoost, is now competing with the once-alone rule of XGBoost. He is a little frustrated with his speed in the current performance - on my data, his training took the most time (about 180 seconds). Although the input is text, after vectorizing thousands of columns more than the input examples, this is not the best case for boosting and trees in general.
Evaluate your model
Actually, the assessment of the results of the model. At this step, you can look at what target metrics have been achieved, as well as drive the model live. About the metrics themselves can be read here: MS and sklearn .
First of all, I was interested in the question - what was tested on? A search on the same help page gives an answer - the partition is very conservative, 80% to 20%. I did not find the ability to configure this in the UI. In practice, I would like to control this, because when there is really a lot of data, the partition can be even 99% and 1% (according to Andrew Ng, I myself did not work with such data). It would also be useful to be able to set random seed data sampling, because the repeatability during the construction and selection of the best model is difficult to overestimate. It seems that adding these options is not difficult, to maintain transparency and simplicity, you can hide them behind some extra options checkbox.
In the process of building the model, tablets with speed indicators are displayed on the console, the generation code of which can be found in the projects from the next step. We can conclude that the generated code really works, and its honest output is output, no fake.
An interesting observation - while writing the article, I once again walked the steps of the builder, used the proposed dataset of comments from Wikipedia. But as a task I chose "Custom", then a multiclass classification as a target (although there are only two classes). As a result, the speed turned out to be about 10% worse (about 73% versus 83%) than the speed from the screenshot with binary classification. For me this is a little strange, because the system could have guessed that there are only two classes. In principle, classifiers of the one-vs-all type (a la one against all, when the multiclass classification problem is reduced to the sequential solution of N-binary problems for each of the N classes) should also show a similar binary speed in this situation.
Generate code
At this step, two projects will be generated and added to the solution. One of them has a full-fledged example of the use of the model, and the other should be looked only if implementation details are interesting.
For myself, I discovered that the entire learning process is succinctly formed into a pipeline (hello to the piplines from sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(slightly touched the code formatting to fit nicely)
Remember, I was talking about the parameters? I do not see any custom parameter, all default values. By the way, using the SentimentText_tf
label on the output of FeaturizeText
we can conclude that this is a term frequency (the documentation says that these are n-grams and char-grams of the text; I wonder if there is an IDF, inversed document frequency).
Consume your model
Actually, an example of use. I can only note that Predict is done elementarily.
Well, that’s all, actually - we examined all the steps of the builder and noted the key points. But this article would be incomplete without a test on its own data, because anyone who has ever encountered ML and AutoML knows very well that any machine is good at standard tasks, synthetic tests and datasets from the Internet. Therefore, it was decided to check the builder on its tasks; hereinafter it is always work with text or text + categorical features.
It was no coincidence that I had at hand a dataset with some errors / issue / defects registered on one of the projects. It has 2949 lines, 8 unbalanced target classes, 4mb.
ML.NET (loading, conversions, algorithms from the list below; took 219 seconds)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(stinged voids in the plate to fit in Markdown)
My Python version (loading, cleaning , converting, then LinearSVC; took 41 seconds):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0.80 vs 0.747 Micro and 0.73 vs 0.542 Macro (there may be some inaccuracy in the definition of Macro, if it’s interesting, I’ll tell you in the comments).
I am pleasantly surprised, only 5% of the difference. On some other datasets, the difference was even smaller, and sometimes it wasn’t at all. Analyzing the size of the difference, it is worth taking into account the fact that the number of samples in the datasets is small, and sometimes, after the next upload (something is deleted, something is added), I observed speed movements of 2-5 percent.
While I was personally experimenting, there were no problems using the builder. However, during the presentation, colleagues still met several jambs:
- We tried to honestly load one of the datasets from the table into the database, but stumbled upon an uninformative error message. I had some idea of what kind of plan the text data is there, and immediately figured out that the problem could be in line feeds. Well, I downloaded the dataset using pandas.read_csv , cleaned it from \ n \ r \ t, saved it in tsv, and moved on.
- During the training of the next model, they received an exception, reporting that a matrix of ~ 220,000 per 1000 cannot comfortably fit in memory, so that training is stopped. At the same time, the model was not generated either. What to do next is unclear; we got out of the situation by substituting the learning time limit “by eye” so that the falling algorithm does not have time to start working.
By the way, from the second paragraph we can conclude that the number of words and n-grams during vectorization is not really limited by the upper boundary, and "n" is probably equal to two. I can say from my own experience that 200k is clearly too much. Usually it is either limited to the most frequent occurrences, or is applied over various kinds of dimensional reduction algorithms, for example, SVD or PCA.
conclusions
The builder offers a choice of several scenarios in which I did not find critical places that require immersion in ML. From this point of view, it is perfect as a tool "getting started" or solving typical simple problems here and now. Actual use cases are entirely up to your imagination. You can go for the options offered by MS:
- solve the problem of sentiment assessment, for example, in the comments on the products on the site
- classify tickets by categories or teams (issue classification)
- continue to mock tickets, but with the help of price prediction - estimate time costs
And you can add something of your own, for example, to automate the task of distributing incoming errors / incidents by developers, reducing it to the task of classification by text (the target label is the ID / Surname of the developer). Or you can please the operators of the internal workstation who fill in the fields in the card with a fixed set of values (drop-down list) for other fields or text description. To do this, you just need to prepare a selection in csv (even several hundred lines are enough for experiments), teach the model directly from UI Visual Studio and apply it in your project by copying the code from the generated example. I lead to the fact that, in my opinion, ML.NET is quite suitable for solving practical, pragmatic, mundane tasks that do not require special qualifications and in vain eat up time. Moreover, it can be applied in the most ordinary project, which does not claim to be innovative. Any .NET developer who is ready to master the new library can become the author of such a model.
I have a bit more background on ML than the average .NET developer, so for myself I decided this way: for pictures, probably not, for complex cases, and for simple table tasks, definitely yes. At the moment, it’s more convenient for me to do any ML task on the more familiar Python / numpy / pandas / sk-learn / keras / pytorch technology stack, however I would have done a typical case for later embedding in a .NET application using ML.NET .
By the way, it’s nice that the text framework works perfectly without any unnecessary gestures and the need for tuning by the user. In general, this is not surprising, because in practice on small amounts of data the good old TfIDFs with classifiers like SVC / NaiveBayes / LR work quite well. This was discussed at the summer DataFest in a report from iPavlov - on some test suite word2vec, GloVe, ELMo (sort of) and BERT were compared with TfIdf. On the test, it was possible to achieve superiority of a couple of percent in only one case out of 7-10 cases, although the amount of resources spent on training is not at all comparable.
PS The popularization of ML among the masses is now in trend, even taking the " Google tool for creating AI, which even a schoolboy can use ." It's all funny and intuitive to the user, but what is really going on behind the scenes in the cloud is unclear. In this regard, for .NET developers, ML.NET with a model builder looks like a more attractive option.
PSS Presentation went off with a bang, colleagues were motivated to try :)
Feedback
By the way, in one of the mailings with the heading "ML.NET Model Builder" it was said:
Give Us Your Feedback
If you run into any issues, feel that something is missing, or really love something about ML.NET Model Builder, let us know by creating an issue in our GitHub repo.
Model Builder is still in Preview, and your feedback is super important in driving the direction we take with this tool!
This article can be considered feedback!
References
To an older article with guidance