Like most developers, Python attracts us with its simplicity and concise syntax. We use it to solve machine learning problems using artificial neural networks. However, in practice, the product development language is not always Python, and this requires us to solve additional integration problems.
In this article I’ll talk about the solutions we came to when we needed to associate the Keras model of the Python language with Java.
What we pay attention to:
- Features bundles Keras model and Java;
- Preparing to work with the DeepLearning4j framework (DL4J for short);
- Importing a Keras model into DL4J (carefully, the section contains multiple insights) - how to register layers, what limitations the import module has, how to check the results of its work.
Why read?
- To save time at the start, if you are faced with the task of similar integration;
- To find out if our solution is right for you and if you can reuse our experience.

Integral characteristic for the importance of deep learning frameworks [ 2 ].
A summary of the most popular deep learning frameworks can be found here [ 3 ] and here [ 4 ].
As you can see, most of these frameworks are based on Python and C ++: they use C ++ as the kernel to accelerate basic and highly loaded operations, and Python as the interaction interface to speed up development.
In fact, many development languages are much more extensive. Java is the leader in product development for large enterprises and organizations. Some popular frameworks for neural networks have ports for Java in the form of JNI / JNA binders, but in this case there is a need to build a project for each architecture and the advantage of Java in the cross-platform issue is blurred. This nuance can be extremely important in replicated solutions.
Another alternative approach is to use Jython to compile into Java bytecode; but there is a drawback here - support for only the 2nd version of Python, as well as the limited ability to use third-party Python libraries.
To simplify the development of neural network solutions in Java, the DeepLearning4j framework (DL4J for short) is being developed. DL4 in addition to the Java API offers a set of pre-trained models [ 5 ]. In general, this development tool is difficult to compete with TensorFlow. TensorFlow outperforms DL4J with more detailed documentation and a number of examples, technical capabilities, community sizes, and fast-paced development. Nevertheless, the trend that Skymind adheres to is quite promising. Significant competitors in Java for this tool is not yet visible.
The DL4J library is one of the few (if not the only one) that makes it possible to import Keras-models; it expands in functionality with layers familiar to Keras [ 6 ]. The DL4J library contains a directory with examples of implementation of neural network ML-models (dl4j-example). In our case, the subtleties of implementing these models in Java are not so interesting. More detailed attention will be paid to importing the trained Keras / TF model into Java using DL4J methods.
Beginning of work
Before you begin, you need to install the necessary programs:
- Java version 1.7 (64-bit version) and higher.
- Apache Maven Project Build System.
- IDE to choose from: Intellij IDEA, Eclipse, Netbeans. Developers recommend the first option, and besides, the available training examples are discussed on it.
- Git (for cloning a project to your PC).
A detailed description with an example of launch can be found here [ 7 ] or in the video [ 8 ].
To import the model, DL4J developers propose using the KerasModelImport import module (appeared in October 2016). The functional of the module supports both architectures of models from Keras - it is Sequential (analog in java - class MultiLayerNetwork) and Functional (analog in java - class ComputationGraph). The model is imported either as a whole in HDF5 format or 2 separate files — the model’s weight with the h5 extension and a json file containing the neural network architecture.
For a quick start, the DL4J developers prepared a step-by-step analysis of a simple example on the Fisher iris data set for a model of type Sequential [ 9 ]. Another training example was considered from the perspective of importing models in two ways (1: in whole HDF5 format; 2: in separate files — model weights (h5 extension) and architecture (json extension)), followed by a comparison of the results of Python and Java models [ 10 ]. This concludes the discussion of the practical capabilities of the import module.
There is also a TF in Java, but it is in an experimental state and the developers do not give any guarantees of its stable operation [ 11 ]. There are problems with versioning, and TF in Java has an incomplete API - which is why this option will not be considered here.
Features of the original Keras / TF model:
Importing a neural network is straightforward. In more detail in the code we will analyze an example of integration of a neural network with architecture more complicated.
You should not go into the practical aspects of this model, it is indicative from the point of view of accounting for layers (in particular, registration of Lambda layers), some subtleties and limitations of the import module, as well as DL4J as a whole. In practice, the noted nuances may require adjustments to the network architecture, or even abandon the approach of launching the model through DL4J.
Model Features:
1. Type of model - Functional (network with branching);
2. The training parameters (the size of the batch, the number of eras) are selected small: the size of the batch - 100, the number of eras - 10, steps per era - 10;
3. 13 layers, a summary of the layers is shown in the figure:

Short layer description
- input_1 - input layer, accepts a 2-dimensional tensor (represented by a matrix);
- lambda_1 - the user layer, in our case makes the padding in TF of the tensor the same numerical values;
- embedding_1 - builds Embedding (vector representation) for the input sequence of text data (converts 2-D tensor to 3-D);
- conv1d_1 - 1-D convolutional layer;
- lstm_2 - LSTM layer (goes after embedding_1 (No. 3) layer);
- lstm_1 - LSTM layer (goes after conv1d (No. 4) layer);
- lambda_2 is the user layer where the tensor is truncated after the lstm_2 (No. 5) layer (the operation opposite to padding in the lambda_1 (No. 2) layer);
- lambda_3 is a user layer where the tensor is truncated after lstm_1 (No. 6) and conv1d_1 (No. 4) layers (the operation opposite to padding in the lambda_1 (No. 2) layer);
- concatenate_1 - bonding of truncated (No. 7) and (No. 8) layers;
- dense_1 - a fully connected layer of 8 neurons and an exponential linear activation function “elu”;
- batch_normalization_1 - layer of normalization;
- dense_2 - fully connected layer of 1 neuron and sigmoid activation function "sigmoid";
- lambda_4 - a user layer where compression of the previous layer (squeeze in TF) is performed.
4. Loss function - binary_crossentropy
5. Model quality metric - harmonic mean (F-measure)
In our case, the issue of quality metrics is not as important as the correctness of import. The correctness of the import is determined by the coincidence of the results in Python and Java NN-models working in the Inference mode.
Import Keras models in DL4J:
Used versions: Tensorflow 1.5.0 and Keras 2.2.5. In our case, the model from Python was uploaded as a whole by the HDF5 file.
# saving model model1.save('model1_functional.h5')
When importing a model into DL4J, the import module does not provide API methods for passing additional parameters: the name of the tensorflow module (from where the functions were imported when building the model).
Generally speaking, DL4J only works with Keras functions, an exhaustive list is given in the Keras Import section [ 6 ], so if the model was created on Keras using methods from TF (as in our case), the import module will not be able to identify them.
General guidelines for importing a model
Obviously, working with the Keras-model implies its repeated training. To this end, to save time, training parameters were set (1 epoch) and 1 step per epoch (steps_per_epoch).
When you first import a model, in particular with unique custom layers and rare layer combinations, success is unlikely. Therefore, it is recommended to carry out the import process iteratively: reduce the number of layers of the Keras model until you can import and run the model in Java without errors. Next, add one layer at a time to the Keras model and import the resulting model into Java, resolving the errors that occur.
Using TF Loss Function
To prove that, when importing into Java, the loss function of the trained model must be from Keras, we use log_loss from tensorflow (as the most similar to the custom_loss function). We get the following error in the console:
Exception in thread "main" org.deeplearning4j.nn.modelimport.keras.exceptions.UnsupportedKerasConfigurationException: Unknown Keras loss function log_loss.
Replacing TF Methods with Keras
In our case, the functions from the TF module are used 2 times and in all cases they are found only in lambda layers.
Lambda layers are custom layers that are used to add an arbitrary function.
Our model has only 4 lambda layers. The fact is that in Java it is necessary to register these lambda layers manually through KerasLayer.registerLambdaLayer (otherwise we will get an error [ 12 ]). In this case, the function defined inside the lambda layer should be a function from the corresponding Java libraries. In Java, there are no examples of registering these layers, as well as comprehensive documentation for this; an example is here [ 13 ]. General considerations were borrowed from examples [ 14 , 15 ].
Sequentially consider registering all the lambda layers of the model in Java:
1) Lambda layer for adding constants to the tensor (matrix) a finite number of times along given directions (in our case, left and right):
The input of this layer is connected to the input of the model.
1.1) Python layer:
padding = keras.layers.Lambda(lambda x: tf.pad(x, paddings=[[0, 0], [10, 10]], constant_values=1))(embedding)
For clarity, the functions of this layer, the numerical values in the python-layers are explicitly substituted.
Table with an example of an arbitrary tensor 2x2
| It was 2x2 | It has become 2x22 |
| [[ 1 , 2 ],
[ 3 , 4 ]] | [[37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 1 , 2 , 37, 37, 37, 37, 37, 37, 37, 37, 37, 37],
[37, 37, 37, 37, 37, 37, 37, 37, 37, 37, 3 , 4 , 37, 37, 37, 37, 37, 37, 37, 37, 37, 37]] |
1.2) Java layer:
KerasLayer.registerLambdaLayer("lambda_1", new SameDiffLambdaLayer() { @Override public SDVariable defineLayer(SameDiff sameDiff, SDVariable sdVariable) { return sameDiff.nn().pad(sdVariable, new int[][]{ { 0, 0 }, { 10, 10 }}, 1); } @Override public InputType getOutputType(int layerIndex, InputType inputType) { return InputType.feedForward(20); } });
In all registered lambda layers in Java, 2 functions are redefined:
The first function “definelayer” is responsible for the method used (not at all an obvious fact: this method can only be used from under nn () backend); getOutputType is responsible for the output of the registered layer, the argument is a numerical parameter (here 20, but in general any integer value is allowed). It looks inconsistent, but it works like this.
2) Lambda layer for trimming the tensor (matrix) along given directions (in our case, left and right):
In this case, the LSTM layer enters the input of the lambda layer.
2.1) Python layer:
slicing_lstm = keras.layers.Lambda(lambda x: x[:, 10:-10])(lstm)
Table with an example of an arbitrary tensor 2x22x5
| It was 2x22x5 | It has become 2x2x5 |
| [[[1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1 , 2,3,4,5], [1,2,3,4,5], [ 1 , 2 , 3 , 4 , 5 ], [ 1 , 2 , 3 , 4 , 5 ], [1,2 , 3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3 , 4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4 , 5], [1,2,3,4,5]],
[[1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [ 1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1, 2,3,4,5], [1,2,3,4,5], [ 1 , 2 , 3 , 4 , 5 ], [ 1 , 2 , 3 , 4 , 5 ], [1,2, 3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3, 4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4,5], [1,2,3,4, 5], [1,2,3,4,5]]] | [[[ 1 , 2 , 3 , 4 , 5 ], [ 1 , 2 , 3 , 4 , 5 ]],
[[ 1 , 2 , 3 , 4 , 5 ], [ 1 , 2 , 3 , 4 , 5 ]]] |
2.2) Java layer:
KerasLayer.registerLambdaLayer("lambda_2", new SameDiffLambdaLayer() { @Override public SDVariable defineLayer(SameDiff sameDiff, SDVariable sdVariable) { return sameDiff.stridedSlice(sdVariable, new int[]{ 0, 0, 10 }, new int[]{ (int)sdVariable.getShape()[0], (int)sdVariable.getShape()[1], (int)sdVariable.getShape()[2]-10}, new int[]{ 1, 1, 1 }); } @Override public InputType getOutputType(int layerIndex, InputType inputType) { return InputType.recurrent(60); } });
In the case of this layer, the InputType parameter changed from feedforward (20) to recurrent (60). In the recurrent argument, the number can be any integer (nonzero), but its sum with the recurrent argument of the next lambda layer should give 160 (i.e., in the next layer, the argument must be 100). The number 160 is due to the fact that the tensor with the dimension (None, None, 160) must be received at the input concatenate_1 of the layer.
The first 2 arguments are variables, depending on the size of the input string.
3) Lambda layer for trimming the tensor (matrix) along given directions (in our case, left and right):
The input of this layer is the LSTM layer, before which the conv1_d layer is
3.1) Python layer:
slicing_convolution = keras.layers.Lambda(lambda x: x[:,10:-10])(lstm_conv)
This operation is completely identical to the operation in paragraph 2.1.
3.2) Java layer:
KerasLayer.registerLambdaLayer("lambda_3", new SameDiffLambdaLayer() { @Override public SDVariable defineLayer(SameDiff sameDiff, SDVariable sdVariable) { return sameDiff.stridedSlice(sdVariable, new int[]{ 0, 0, 10 }, new int[]{ (int)sdVariable.getShape()[0], (int)sdVariable.getShape()[1], (int)sdVariable.getShape()[2]-10}, new int[]{ 1, 1, 1 }); } @Override public InputType getOutputType(int layerIndex, InputType inputType) { return InputType.recurrent(100); } });
This lambda layer repeats the previous lambda layer with the exception of the recurrent (100) parameter. Why "100" is taken is noted in the description of the previous layer.
In points 2 and 3, the lambda layers are located after the LSTM layers, so the recurrent type is used. But if before the lambda-layer there was not LSTM, but conv1d_1, then it is still necessary to set recurrent (it looks inconsistent, but it works like that).
4) Lambda layer to compress the previous layer:
The input of this layer is a fully connected layer.
4.1) Python layer:
squeeze = keras.layers.Lambda(lambda x: tf.squeeze( x, axis=-1))(dense)
Table with an example of an arbitrary tensor 2x4x1
| It was 2x4x1 | Became 2x4 |
| [[[ [1], [2], [3], [4]] ,
[ [1], [2], [3], [4] ]] | [[ 1, 2, 3, 4 ],
[ 1, 2, 3, 4 ]] |
4.2) Java layer:
KerasLayer.registerLambdaLayer("lambda_4", new SameDiffLambdaLayer() { @Override public SDVariable defineLayer(SameDiff sameDiff, SDVariable sdVariable) { return sameDiff.squeeze(sdVariable, -1); } @Override public InputType getOutputType(int layerIndex, InputType inputType) { return InputType.feedForward(15); } });
The input of this layer receives a fully connected layer, InputType for this feedForward layer (15), parameter 15 does not affect the model (any integer value is allowed).
Download Imported Model
The model is loaded through the ComputationGraph module:
ComputationGraph model = org.deeplearning4j.nn.modelimport.keras.KerasModelImport.importKerasModelAndWeights("/home/user/Models/model1_functional.h5");
Outputting data to the Java console
In Java, in particular in DL4J, tensors are written in the form of arrays from the high-performance Nd4j library, which can be considered an analogue of the Numpy library in Python.
Let's say our input string consists of 4 characters. Symbols are represented as integers (as indices), for example, according to some numbering. An array of the corresponding dimension (4) is created for them.
For example, we have 4 index-encoded characters: 1, 3, 4, 8.
Code in Java:
INDArray myArray = Nd4j.zeros(1,4); // one row 4 column array myArray.putScalar(0,0,1); myArray.putScalar(0,1,3); myArray.putScalar(0,2,4); myArray.putScalar(0,3,8); INDArray output = model.outputSingle(myArray); System.out.println(output);
The console will display the probabilities for each input element.
Imported Models
The architecture of the original neural network and weights are imported without errors. Both Keras and Java neural network models in Inference mode agree on the results.
Python model:

Java model:
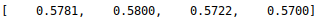
In reality, importing models is not so simple. Below we will briefly highlight some points that in some cases may be critical.
1) The patch normalization layer does not work after recursive layers. Issue has been open on GitHub for almost a year [ 16 ]. For example, if you add this layer to the model (after the contact layer), we get the following error:
Exception in thread "main" java.lang.IllegalStateException: Invalid input type: Batch norm layer expected input of type CNN, CNN Flat or FF, got InputTypeRecurrent(160) for layer index -1, layer name = batch_normalization_1
In practice, the model refused to work, citing a similar error when the layer of normalization was added after conv1d. After a fully connected layer, the addition works flawlessly.
2) After a fully connected layer, setting the Flatten layer results in an error. A similar error is mentioned on Stackoverflow [ 17 ]. For six months, no feedback.
Definitely this is not all the restrictions that you can encounter when working with DL4J.
The final operating time for the model is here [ 18 ].
Conclusion
In conclusion, it can be noted that painlessly imported trained Keras models into DL4J can only be for simple cases (of course, if you have no such experience, and indeed a good command of Java).
The fewer user layers, the more painless the model will be imported, but if the network architecture is complex, you will have to spend a lot of time transferring it to DL4J.
The documentary support of the developed import module, the number of related examples, seemed rather damp. At each stage, new questions arise - how to register Lambda layers, meaningfulness of parameters, etc.
Given the speed of complexity of neural network architectures and interactions between layers, layer complexity, DL4J has yet to develop actively in order to reach the level of top-end frameworks for working with artificial neural networks.
In any case, the guys are worthy of respect for their work and would like to see the continuation of the development of this direction.
References
- Top 5 best Programming Languages for Artificial Intelligence field
- Deep Learning Framework Power Scores 2018
- Comparison of deep-learning software
- Top 9 Frameworks in the World of Artificial Intelligence
- DeepLearning4j. Available models
- DeepLearning4j. Keras model import. Supported features.
- Deeplearning4j. Quickstart
- Lecture 0: Getting started with DeepLearning4j
- Deeplearing4j: Keras model import
- Lecture 7 | Keras model import
- Install TensorFlow for Java
- Using Keras Layers
- DeepLearning4j: Class KerasLayer
- DeepLearning4j: SameDiffLambdaLayer.java
- DeepLearning4j: KerasLambdaTest.java
- DeepLearning4j: BatchNorm with RecurrentInputType
- StackOverFlow: Problem opening a keras model in java with deeplearning4j (https://deeplearning4j.org/)
- GitHub: Full code for the model in question
- Skymind: Comparison of AI Frameworks