- Hi, my name is Andrey Sikerin, I am developing Yandex.Browser for iOS. I want to tell you what the browser experiment platform for iOS is, how we learned to use it, supported its more advanced features, how to diagnose and debug features rolled out using the experiment system, and also what is the source of entropy and where coin is stored.
So, let's begin. We in the Browser for iOS never roll feature to users at once. First, we conduct A / B testing, analyze product and technical metrics in order to understand how the rolled feature affects the user, whether he likes it or not, whether it squanders some technical metrics. For this we use analytics. Our analytics looks something like this:
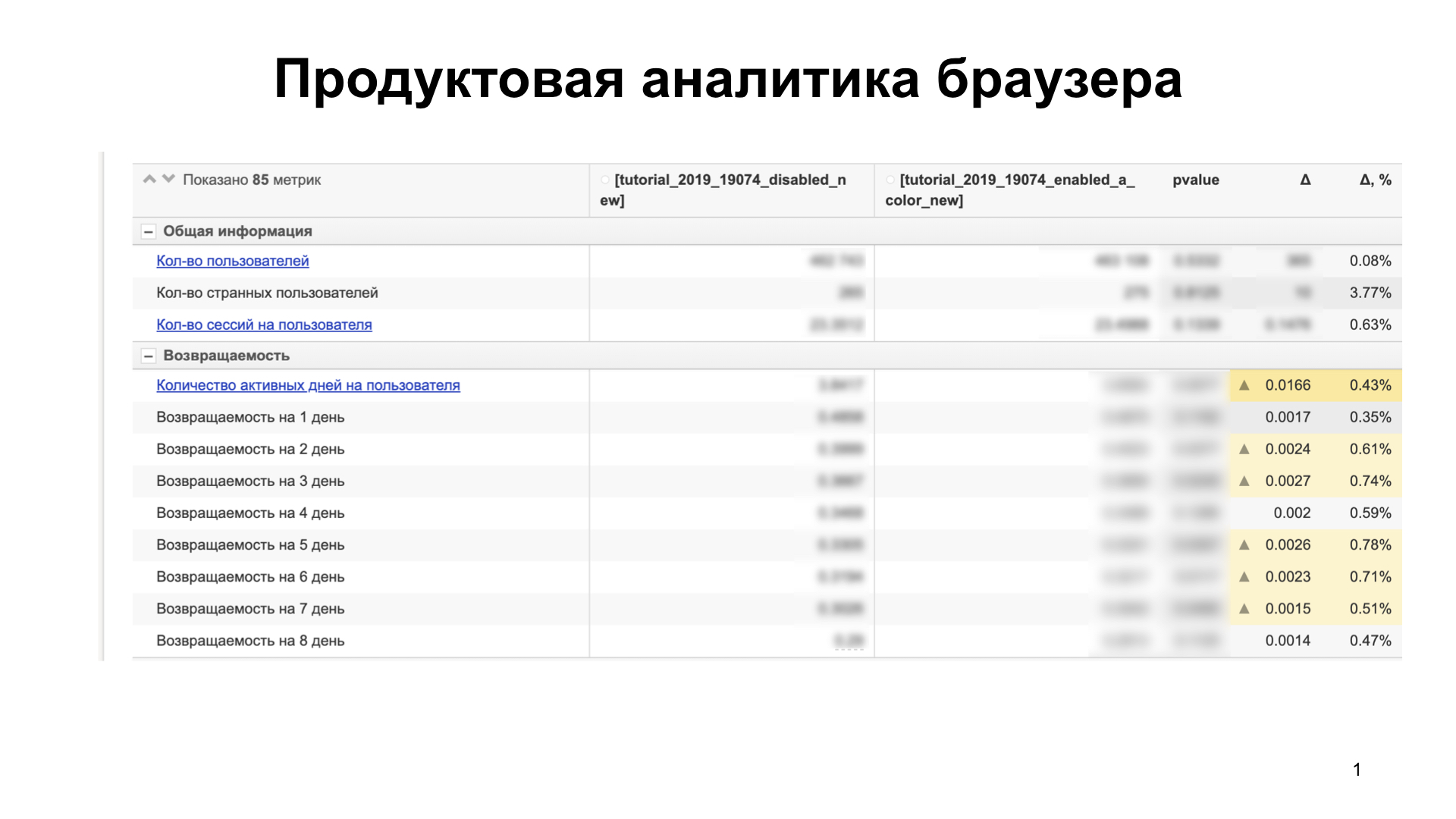
There are about 85 metrics. We compare several user groups. Suppose this increases our metrics — for example, the product’s ability to retain users (retention) —and doesn’t squander others that aren’t on the slide. This means that users like the feature and can roll on a large group of users.
If, nevertheless, we squander something, then we understand why. We build hypotheses, confirm them. If we draw technical metrics - this is a blocker. We fix them and rerun the experiment again. And so until we paint everything. Thus, we roll out the feature, which is not a source of regression.
Let's talk about the original experiment system that we used. She was already quite developed. Then I will tell you what did not suit us.

First, it is based on the Chromium experiment system and was not fully supported on iOS. Secondly, it was originally able to roll out features to different user groups and had a filter system on which it was possible to set requirements for devices. That is - the version of the application from which the feature is available, the device locale - let's say we want an experiment only for the Russian locale. Either the version of iOS on which this feature will be available, or the date by which this experiment will be valid - for example, if we want to conduct an experiment only until some date. In general, there were many tags and it was quite convenient.
The experiment system itself consists of a file that contains descriptions of the configurations of the experiments. That is, for one experiment there can be several configurations at once. This file is a text file, it is compiled into protobuf and laid out on the server.
Each configuration consists of groups. There is an experiment, it has several configurations, and in each of them there are several groups. The feature in the code is attached to the name of the active group of the active configuration. It may seem complicated enough, but now I will explain in detail what it is.

How does it work technically? A file with descriptions of all configurations is uploaded to the server. At startup, it is downloaded by the browser from the server and saved to disk. The next time we start, we decode this file the very first in the application initialization chain. And for each unique experiment we find one configuration that will be active.
The configuration that is suitable for the conditions specified and described in it can become active. If there are several active configurations that fit the specified conditions, then the configuration that will be higher in the file is activated.
Further in the active configuration, a coin is thrown. The coin is thrown locally, and according to this coin in a certain way, which I will discuss later, the active group of the experiment is selected. And it is precisely to the name of the active group of the experiment that we are attached in the code, checking whether our feature is available or not.
A key feature of this system is that it does not store anything by itself. That is, she does not have any storage on the disk. Each launch - we take the file, start calculating it, find the active configuration. Inside the configuration, according to the coin, we find the active group, and the experiment system for this experiment says: this group is selected. That is, everything is calculated, nothing is stored.

Let me, in fact, show you a file with descriptions of the experiments. The browser has such a feature - Translator. She rolled out in an experiment. The file starts with the study block. The configuration of any experiment begins with this block. The experiment is called a translator. There can be several such study blocks with this name. And inside the study block, there are many experiment blocks that are assigned different names. In this case, we see the experiment group enabled. And there is a filter block, which, in fact, describes under what conditions this configuration can become active, that is, its criteria.
There are two tags here - channel and ya_min_version. Channel means assembly view. BETA is indicated here, which means that this configuration in the file can become active only for those assemblies that we send to TestFlight. For the App Store build, this configuration by the channel criterion cannot become active.
ya_min_version means that with a minimal version of the application 19.3.4.43 this configuration can become active. Actually, in this version of the application the feature has already acquired such a form that you can enable it.
This is the simplest description of the translator experiment configuration group. There can be many such study blocks in a file. Using the tags in the filter block, we set them for different channels, for internal assemblies, for BETA assemblies, for various criteria.
Here is one experiment group called enabled, and it has a probability weight tag, the weight of the experiment group. This is a non-negative integer used to determine the active group at the moment the coin pops up.
Let's imagine that this configuration on the slide has become active. That is, we really installed the application with public beta, and we really have version 19.3.4.43 onwards. How is the coin tossed? A coin is a random number that is generated locally from zero to one.
So that during the next launch we fall into the same group, it is stored on disk. For now, we will take it that way. Next, I will tell you how to make sure that it is not stored. The coin is thrown out. Suppose 0.5 is thrown out. This coin is scaled in a segment from zero to the sum of groups of experiments. In this case, we have one enabled group, its weight is 1000, that is, the sum of all groups will be 1000. “0.5” scales to 500. Accordingly, all groups of experiments divide the interval from zero to the amount of experiments and gaps. And the group becomes active in whose interval the scaled value of the coin will indicate.
We can ask the name of the active group of experiments in the code and thus determine the accessibility - do we need to enable the feature or not.
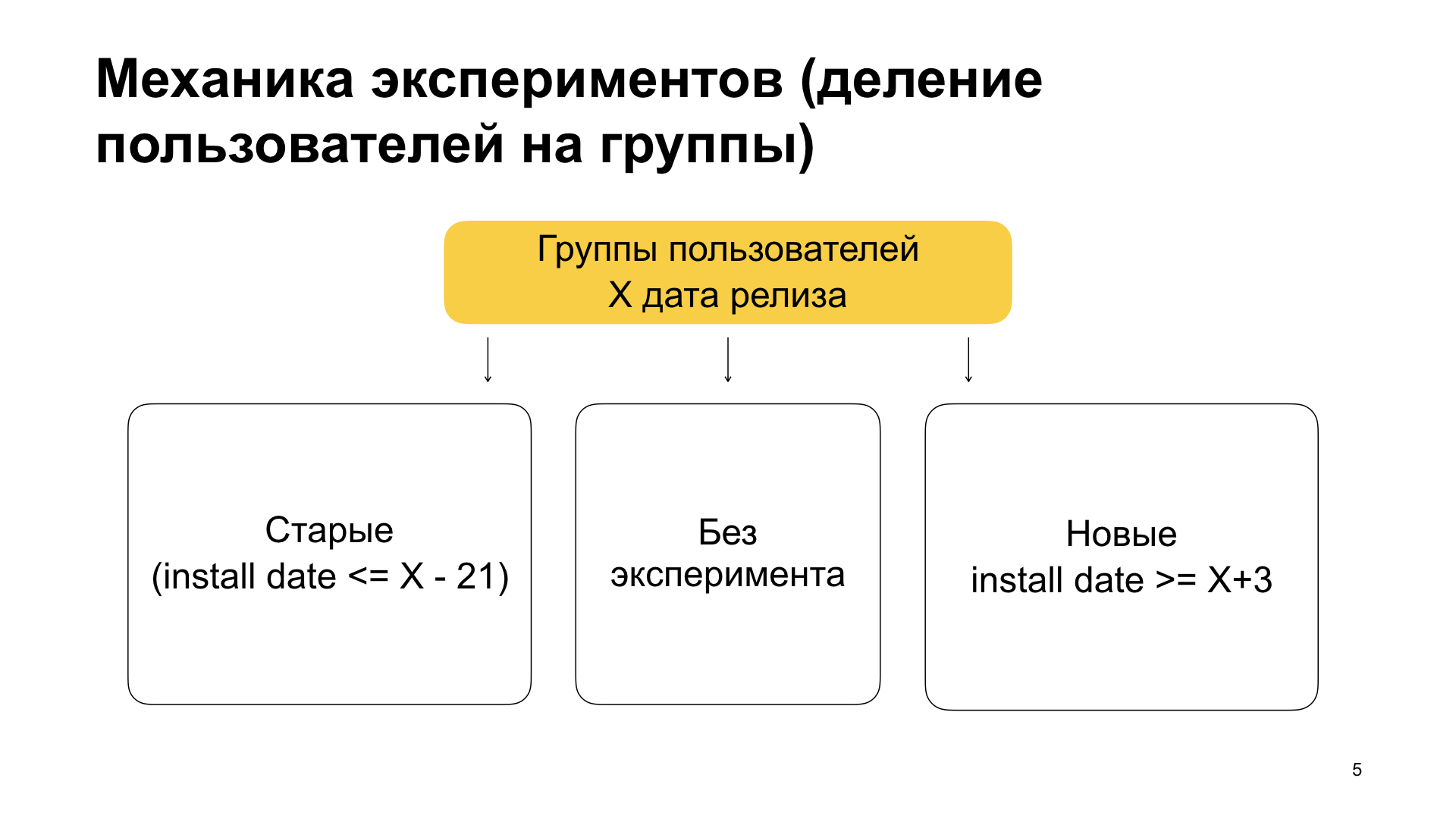
Further we will look at more complex experimental configurations that we use in production. Firstly, it’s clear that it’s stupid to roll out a feature for 100%, we use this only for beta or for internal assembly. For production, we use the following mechanics.
We divide users into three groups - old users, users without experiment and new users. In meaning, this means the following. Old users are those who have already used our application and installed the application with features on top of the old version. That is, they already used it, they did not have features, they got used to everything and suddenly update the application in which there is some kind of experiment, new functionality. Then - users without experiment and new users. New ones are those that put the application clean. That is, they never used Yandex.Browser, they suddenly decided to use it and installed the application.
How do we achieve this partition? We set the conditions on the min_install_date and max_install_date tags in the filter block. Suppose X is March 14, 2019 - this is the release date for the feature build. Then max_install_date for old users will be X minus 21 days, before the release of the assembly with features. If the application has such an install date, then it is highly likely that its first launch was prior to release. And before the release there was a version without features. And if he now has, conditionally, a version with features, it means that he received the application with the help of an update.
And for new users, we set min_install_date. We expose it as X plus a few days. This means: if he has such an install date, that is, he made the first launch after the release date of the version with features, then he had a clean installation. He now has a version with features, but install date was later than this version with features.
Thus, we break users into old ones, without experiment and new ones. We do this because we see: the behavior of old users is different from the behavior of new users. Accordingly, we can, for example, not paint over in a group with old users, but paint over in a group with new users, or vice versa. If we do an experiment on the whole mass, we may not see this.

Let's look at this experiment. We see the following experiment configuration - Translator for the App Store, new users. Block study, name translator, group enabled_new. The prefix new means that we describe the configuration for many users who are new. Weight 500 (if the sum of all weights is 1000, then the power of this set is 50%). Control_new, weight 500, this is the second group. And the most interesting thing is the filters for the STABLE channel, that is, for assemblies that are assembled for production. Version in which the feature appeared: 19.4.1. And here is the min_install_date tag. Here, in Unix time format, it is encrypted on April 18, 2019. This is a few days after the release of version 19.4.1.
There is one more part here besides the new prefix, it is enabled and control. Here is the control prefix; it is not accidental. And besides the fact that we break users into new and old, we break them inside the experiment into groups into several parts.
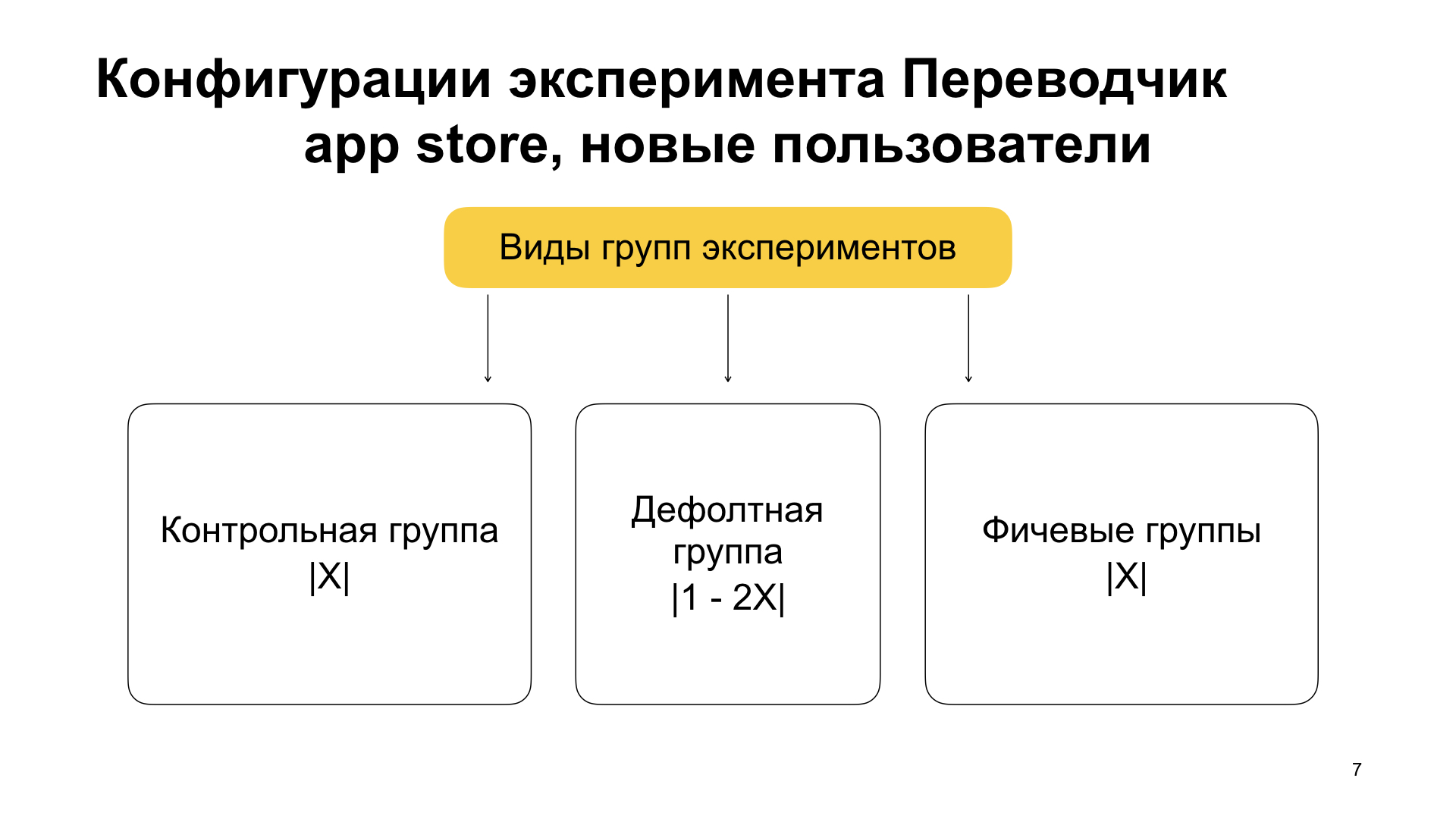
The first part of users is a control group, one that has the control prefix. There are no features in it. She has an X weight. She also has a feature group, usually called enabled. It also has X weight, and this is important: there the feature should turn on. And there is a default group that has a weight of 1 minus 2X (1000 minus 2X, since 1000 is the value of the total weight of all groups within the same configuration, which is accepted by default). The default group also does not include any feature. It simply stores users who remain after splitting into control and feature ones. You can also re-run the experiment from it, if necessary.

Let's see, say, the configuration for old users. We will see a feature and control group here. enabled_old - featured. control_old, - control, 10%. default_old - default, 80%.
Note filter, ya_min_version 19.4.1, max_install_date March 28, 2019. This is a date earlier than the release date. Accordingly, this is a configuration with a list of users who received version 19.4.1 after the update. They used the application and now use the new version.
Why are feature and control groups needed? In the analytics that I showed on the first slide, we compare the control group and the feature group. They must be of equal power so that their product metrics can be compared.
Thus, we compare the control and feature groups in analytics for different user groups, old and new. If we color everything, then we roll the feature by 100%.

How does a code developer work with this system? He knows the names of feature groups, the date when the feature needs to be enabled, and writes some access layer, this is a pseudocode, requesting an active group by the name of the experiment. It may not be. Actually, all configurations may not be suitable for the device. Then the empty string will return.
After that, if the name of the active group is featured, then you need to enable the feature, otherwise turn it off. Further, this function is already used in the code, which includes functionality in the browser code.

So we lived with this system of experiments for several years. Everything was fine, but revealed a number of shortcomings. The first drawback of this approach is that it is impossible to add new experiment groups without correcting the code. That is, if the name of the experiment is unlikely to change for a feature, then adding a couple more additional groups, it can easily be. But your feature accessibility code does not know such groups, because you did not foresee it in advance. Accordingly, it is necessary to roll the version, to conduct experiments with this version, which is a problem. That is, it is necessary, by changing the code, to rebuild and post in the App Store.
Second, you cannot roll out parts of a feature or break a feature into pieces after you start the experiment. That is, if you suddenly decided that some of the features could be rolled out, and some still left in the experiment, then you can’t do this, you had to think over and split this feature in two in advance, and independently accept them in the experiment.
Third, you cannot configure a feature or compare configurations. In Translator, for example, there is a parameter - timeout time to the Translator API. That is, if we did not manage to translate in a few milliseconds, then we say that, try again, an error, no luck.
It is impossible to set this timeout in the experiment, because we either need to fix the groups and immediately in advance, let's have the following groups in advance - enabled_with_300_ms, enabled_with_600_ms in whose names the parameter value is encoded. But it is impossible to set the parameter numerically somehow. If we have not thought this out before, then we can no longer compare several configurations.
Fourth, analysts and developers are forced to agree on group names in advance. That is, in order for a developer to start developing a feature, he usually starts, in fact, with the availability policy of this feature. And he needs to know the names of feature groups. And for this, the analyst must explain the mechanics of the experiment - whether we will divide users into new and old or all users will be in the same group without division.
Or it could be a reverse experiment. For example, we can immediately consider that the feature is enabled, but be able to turn it off. This is not very interesting for the analyst, because the feature is not ready. He will determine the mechanics of the experiment when it is ready. But the developer needs the names of the groups and the mechanics of the experiment in advance, otherwise he will constantly have to make changes to the code.
We consulted and decided that it was enough to endure. So the Make Experiments Great Again project was born.

The key idea of this project is as follows. If earlier we were attached to a code, a code, to the names of the active groups that the analyst passed to us, now we have added two additional entities. This feature (Feature) and feature parameter (FeatureParam). And thus, the programmer invents features and feature parameters independently, choosing identifiers for them, choosing default values for them, and programming the availability of features for them.
After that, he passes these identifiers to the analyst, and the analyst, thinking through the mechanics of the experiments, specifies them in a special way in the experiment groups using the feature_association tag. If this group becomes active, then please remember to enable or disable the feature with the identifier such and such, and set the parameters with such identifiers.

What does it look like in the experiment configuration file? Here we are watching an experiment group. Name enabled, the optional feature_association tag is added, in this enable_feature or disable_feature command tag, and identifiers are added.
There is also a param block, of which there can be several. Here, too, there is a name - timeout, and the value that needs to be set is added.

What does this look like from code? The programmer declares the entities of the Feature and FeatureParam classes. And it writes values from these primitives to the feature access layer. Then it passes this identifier to the analyst, and it already in the configuration file sets the identifiers in the block of the experiment group using the feature_association tag. As soon as the experiment group becomes active, the values of features and parameters with these identifiers in the code are set from the file. If there are no parameters and features in the group, the default values are used, which are indicated from the code.
It would seem that this gave us? First, when adding a new group, the analyst does not need to ask the programmer to add a new feature group to the code, because the data access layer operates with identifiers that do not change when a new group is added to the experiment system.
Secondly, we posted the time when programmers come up with these identifiers for features and feature parameters, with the time when the analyst develops the mechanics of the experiment. The analyst develops when the feature is ready, and the programmer comes up with these identifiers when he writes the code, at the very beginning.
It also allows you to break the feature into pieces. Suppose there is a feature called Translator, which includes, in fact, the Translator. And there is a feature of TranslateServiceAPITimeout, it includes additional functionality that can set a custom timeout to the Translator API. Thus, we can do two groups of experiments, in both of which the Translator is turned on, but at the same time we compare which value is better: 300 milliseconds or 600.
That is, you can break the feature into sub-features and then include part of the sub-features in the experiment in different groups. And compare. And you can configure the same feature with different parameters due to new feature parameter entities (FeatureParam).
It would seem that we have solved all the problems, a victory, we can celebrate. But, no, they came for us. Not other developers, not analysts, not managers, came for us. Testing came for us. What was the testing problem?

, : Feature FeatureParam. Feature FeatureParam . , Feature FeatureParam, , . . - , , .
-, Feature&FeatureParam. , «», , , . FeatureParam , , API — 300 600 ?
. . - , . public beta, . , .
, : .

? , , .
: . URL, , .
: browser://version — show-variations-cmd. : cheat-, . : .
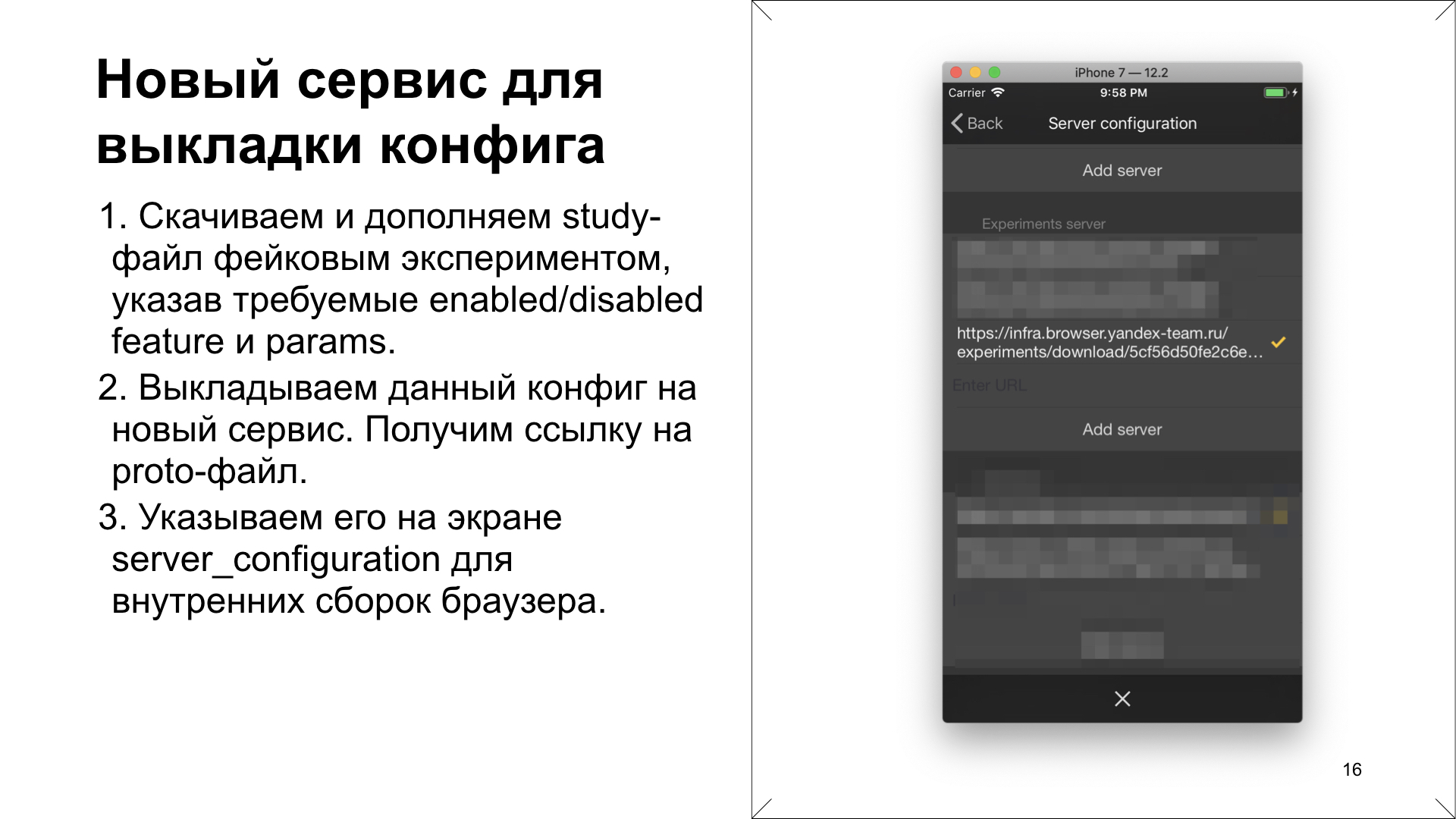
. , . proto- - , study-, . , . Feature&FeatureParam, . , , . , , Feature&FeatureParam .
. proto- . . , . , , .

The second one. Feature&FeatureParam? Chromium, . Chromium browser://version, show-variations-cmd.
: enabled-features, force-fieldtrials force-fieldtrials-params, . , . ? , . , Feature1 trial1. Feature2 trial2. Feature3 .
trial1 group1. trial2 group2. force-fieldtrials-params, , trial1 group1, p1 v1, p2 v2. trial2 group2, p3 v3, p4 v4.
, . Chromium, iOS. , .
. --force-fieldtrials=translator/enabled_new/ enabled_new translator.
--force-fieldtrial-params==translator.enablew_new:timeout/5000, translator enabled_new, , , translator, enabled_new timeout, 5 000 .
--enabled-features=TranslateServiceAPITimeout<translator , - translator translator , , , TranslateServiceAPITimeout. , , , , .

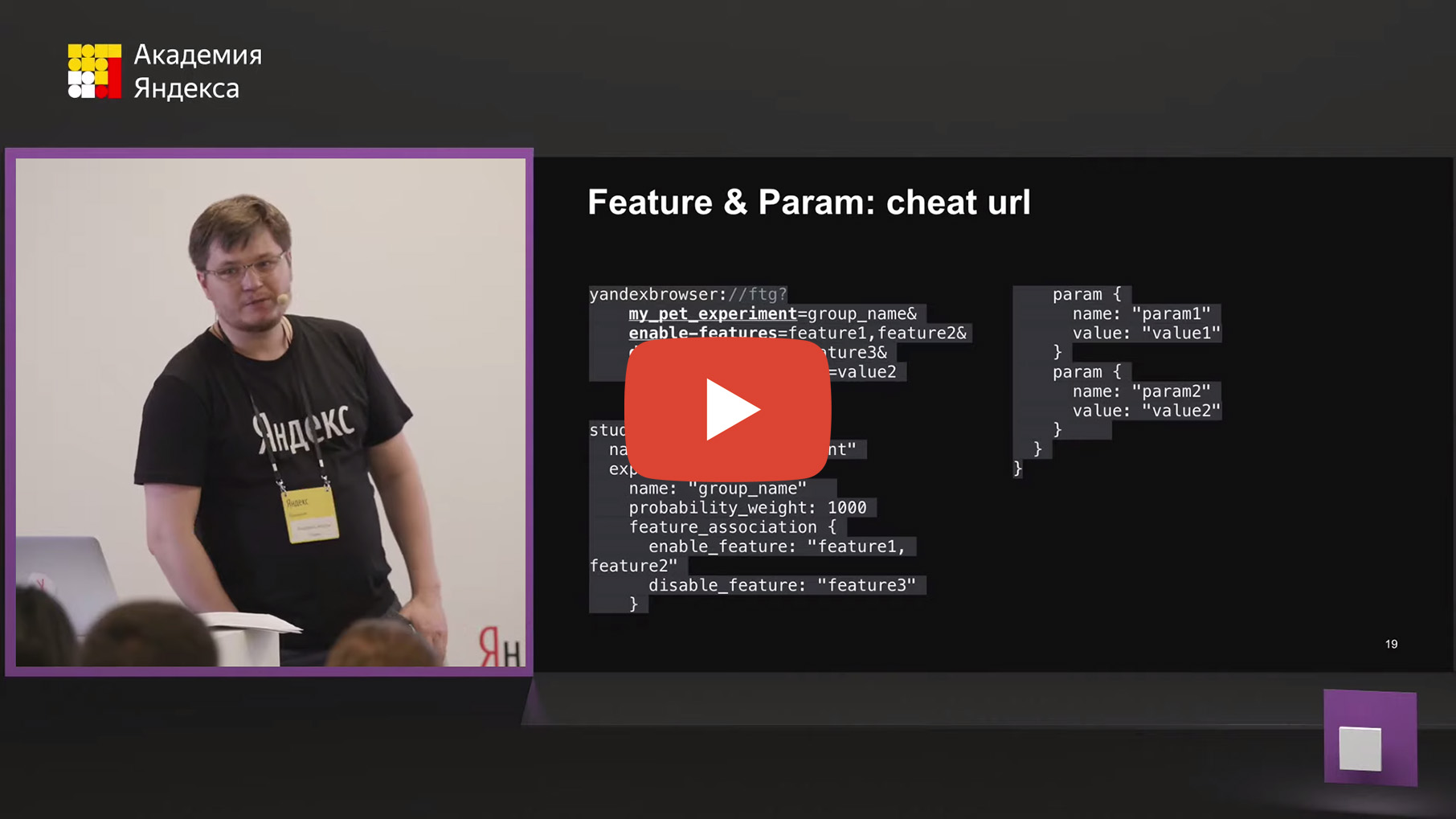
(cheat urls). , , , , , , . . . .
yandexbrowser:// (.), , . . my_pet_experiment=group_name. , enable-features=, , disable-features=, . , &.
(cheat url), . , , , . , , . filter, my_pet_experiment , . 1000, feature_association, , .
, . , , . , — my_pet_experiment — , , . , , study .
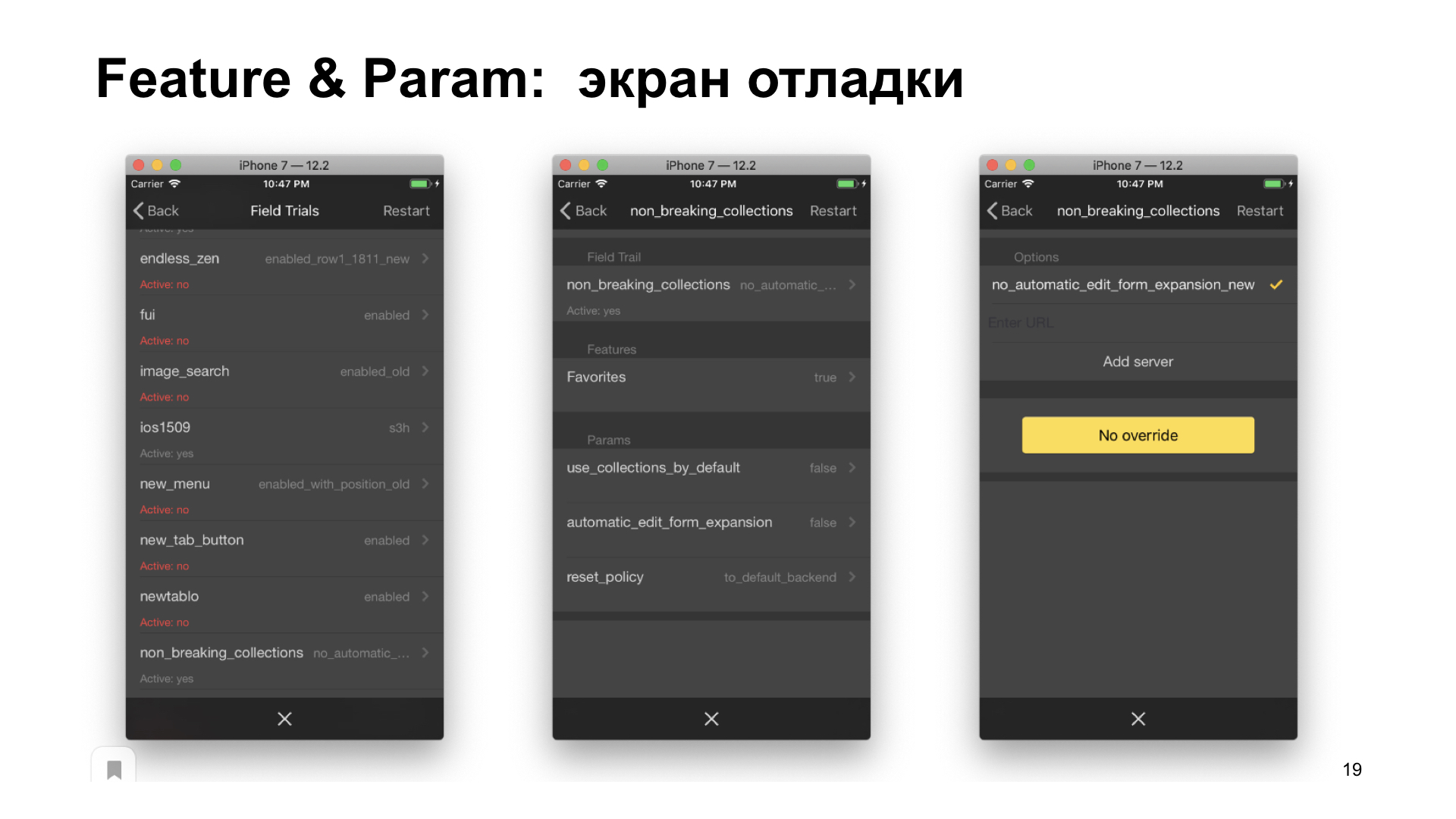
, . — , . . , .
, .

, , , , . , . , .
. . , , ? , . , ?
. .

, . , , UUID, application Identifier, . . hash .
? ? , , UUID, . ? , , . . ? hash hash , . , Google, An Efficient Low-Entropy Provider.
, — UUID, , , . , , Chromium.
, , ? ? :
- : , -. .
- . , , , .
- . , , , .
- , .
- . , , (. hromium variation service ).
Chromium, . iOS, . , . Thanks.