
Neural networks in computer vision are actively developing, many tasks are still far from being solved. To be trending in your field, just follow the influencers on Twitter and read the relevant articles on arXiv.org. But we had the opportunity to go to the International Conference on Computer Vision (ICCV) 2019. This year it is being held in South Korea. Now we want to share with the readers of Habr that we saw and learned.
There were many of us from Yandex: unmanned vehicle developers, researchers, and those involved in CV tasks in services arrived. But now we want to introduce a slightly subjective point of view of our team - the machine intelligence laboratory (Yandex MILAB). Other guys probably looked at the conference from their angle.
What does the laboratory do
We do experimental projects related to the generation of images and music for entertainment purposes. We are especially interested in neural networks that allow you to change content from the user (for a photo this task is called image manipulation). An example of the result of our work from the YaC 2019 conference.
There are a lot of scientific conferences, but the top, so-called A * conferences stand out from them, where articles about the most interesting and important technologies are usually published. There is no exact list of A * conferences, here is an example and incomplete: NeurIPS (formerly NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. The last three specialize in the topic of CV.
ICCV at glance: posters, tutorials, workshops, stands
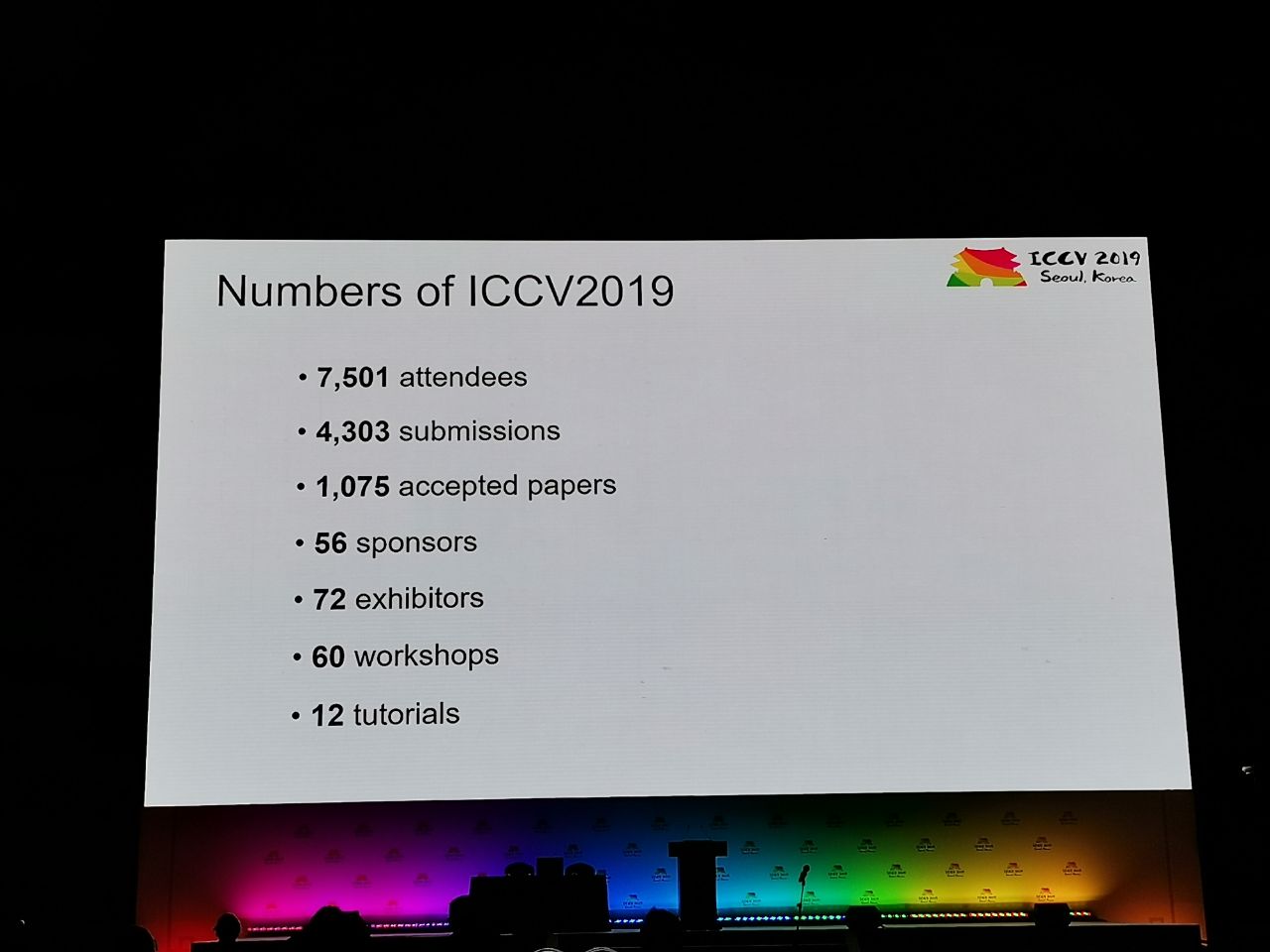
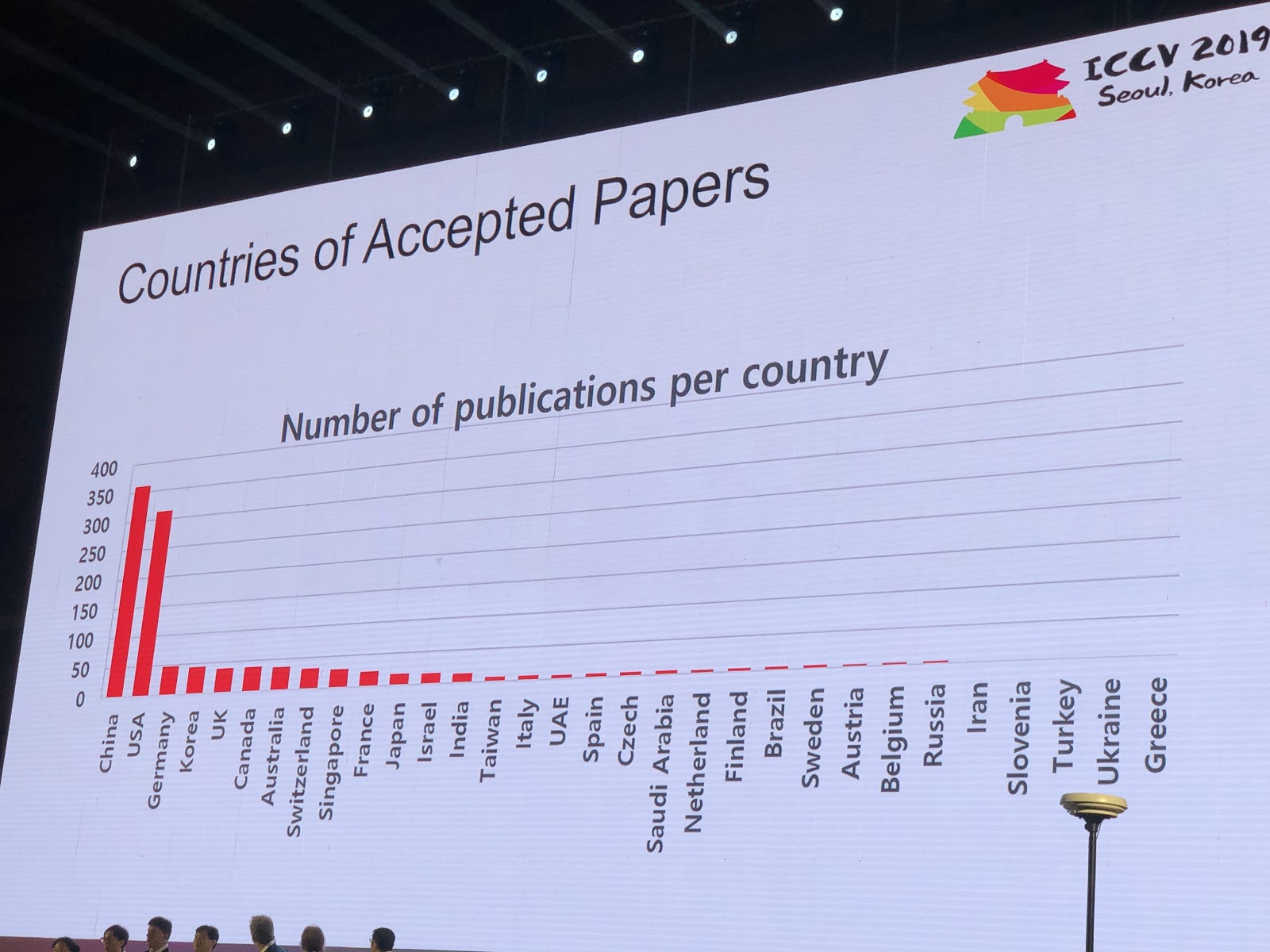
1075 papers were accepted at the conference, there were 7,500 participants. 103 people came from Russia, there were articles from employees of Yandex, Skoltech, Samsung AI Center Moscow and Samara University. This year, ICCV was visited by not many top researchers, but here, for example, Alexey (Alyosha) Efros, who always gathers a lot of people:

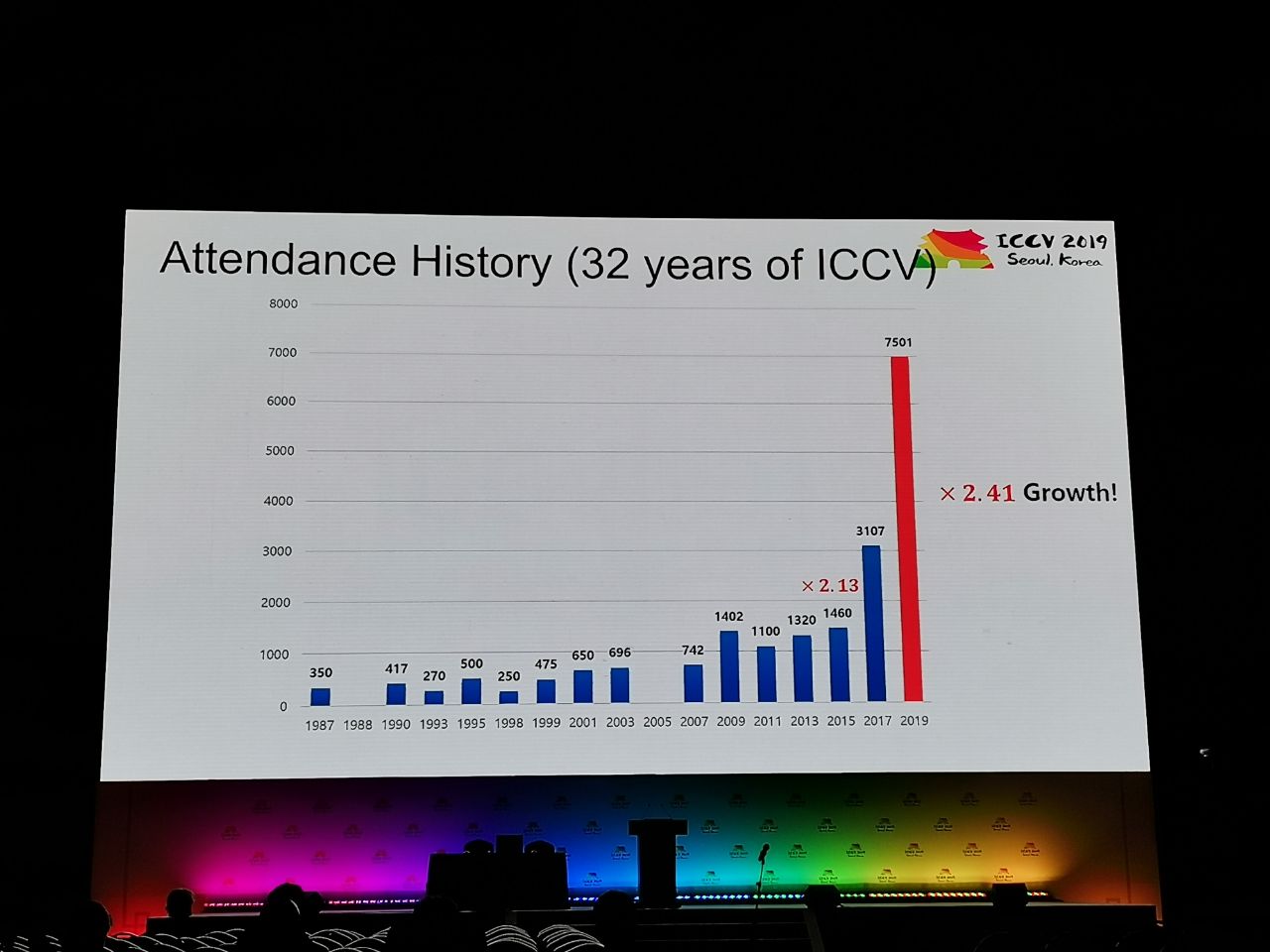
Statistics 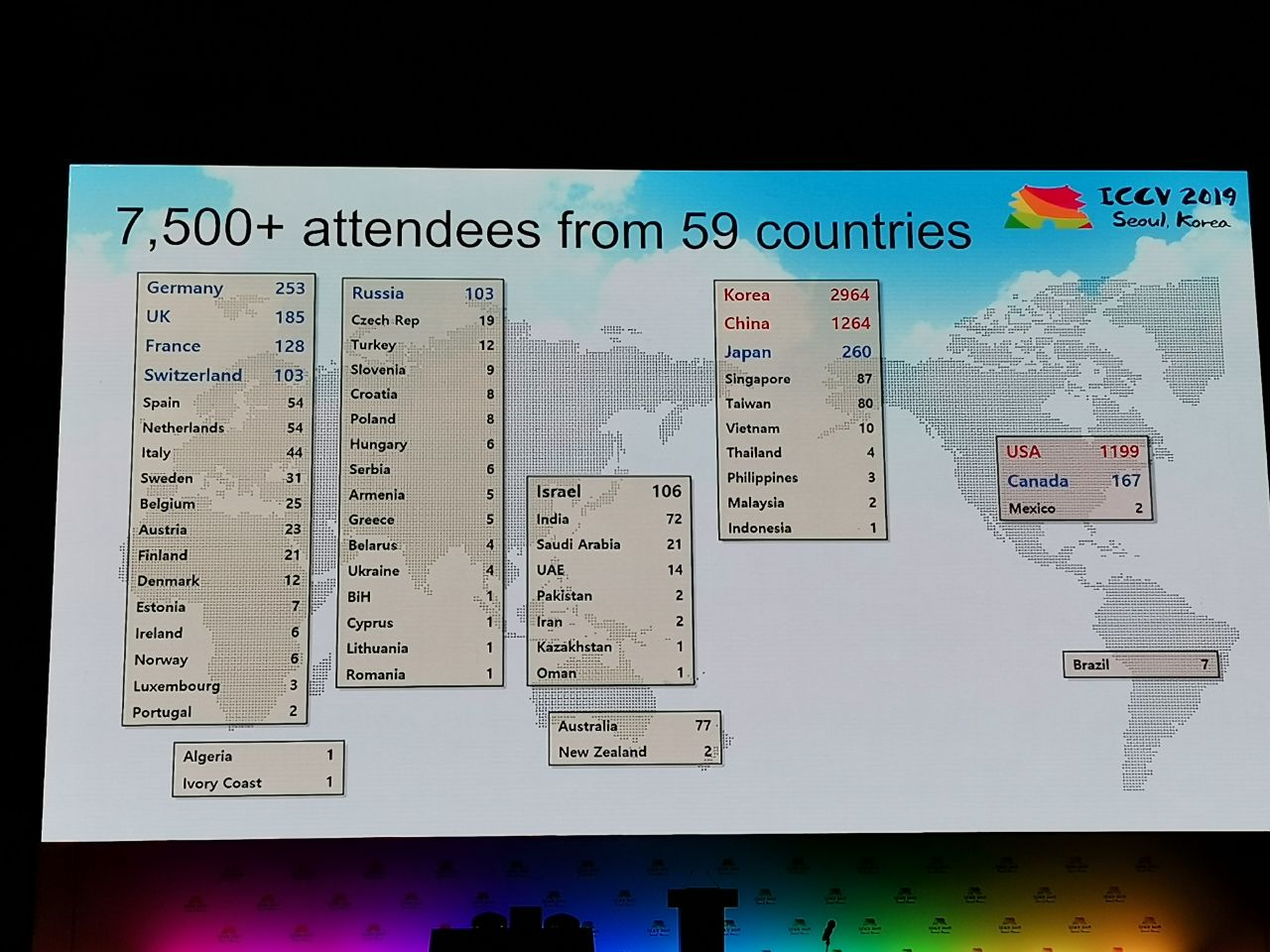

At all such conferences, articles are presented in the form of posters ( more about the format), and the best are also presented in the form of short reports.
Here is part of the work from Russia 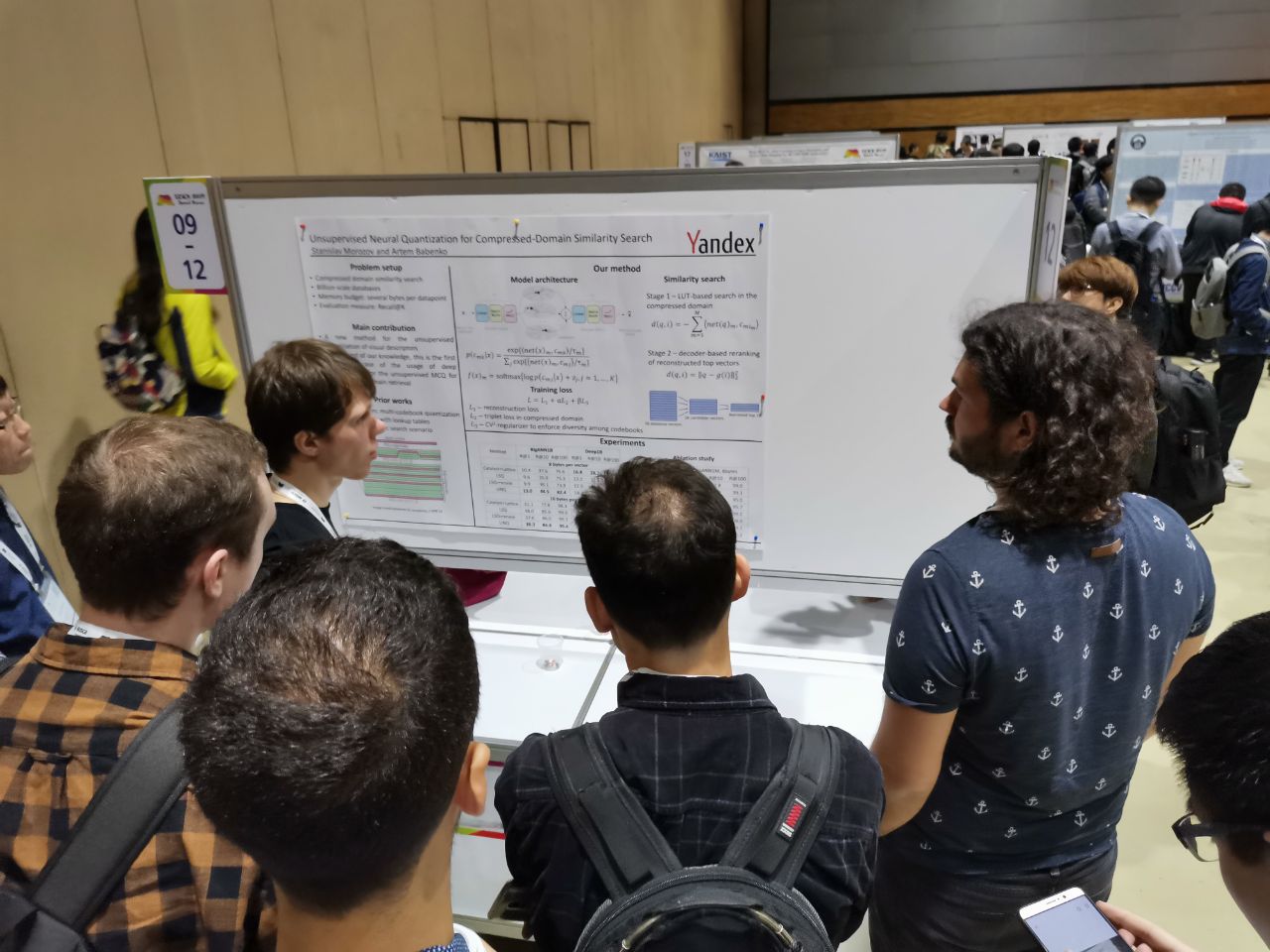


On the tutorials you can immerse yourself in some subject area, it resembles a lecture at a university. It is read by one person, usually without talking about specific works. Example cool tutorial ( Michael Brown, Understanding Color and the In-Camera Image Processing Pipeline for Computer Vision ):

In workshops, on the contrary, they talk about articles. Usually this is work in some narrow topic, stories from the heads of laboratories about all the latest works of students, or articles that were not accepted at the main conference.
Sponsoring companies come to the ICCV with stands. This year, Google, Facebook, Amazon and many other international companies arrived, as well as a large number of startups - Korean and Chinese. There were especially many startups that specialize in data markup. At the stands there are performances, you can take merchandise, ask questions. Sponsoring companies have parties for hunting. They manage to get to them if they convince recruiters that you are interested and that you can potentially be interviewed. If you published an article (or, moreover, spoke with it), started or ended PhD - this is a plus, but sometimes you can agree on a stand, asking interesting questions to the company's engineers.
Trends
The conference allows you to glance over the entire CV area. By the number of posters of a particular topic, you can evaluate how hot the topic is. Some conclusions beg for the keywords:

Zero-shot, one-shot, few-shot, self-supervised and semi-supervised: new approaches to long-studied problems
People learn to use data more efficiently. For example, in FUNIT it is possible to generate facial expressions of animals that were not in the training set (applying several reference pictures in the application). The ideas of Deep Image Prior have been developed, and now the GAN network can be trained in one picture - we will talk about this later in the highlights . You can use self-supervision for pre-training (solving a problem for which you can synthesize aligned data, for example, to predict the angle of rotation of a picture) or learn at the same time from marked and unlabeled data. In this sense, the crown of creation can be considered an article S4L: Self-Supervised Semi-Supervised Learning . But pre-training on ImageNet does not always help.

3D and 360 °
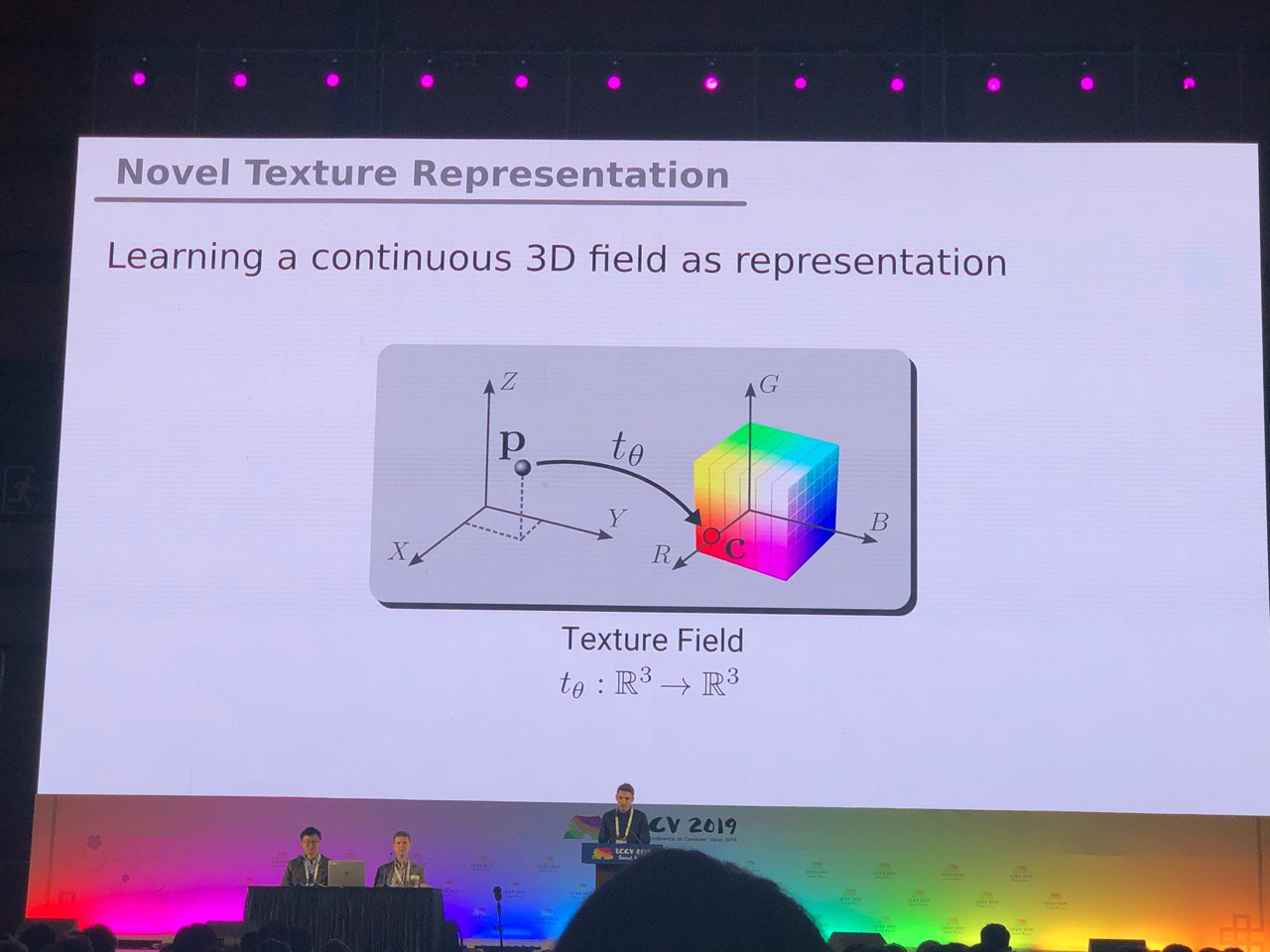
Tasks, mostly solved for photos (segmentation, detection), require additional research for 3D models and panoramic videos. We saw many articles on converting RGB and RGB-D to 3D. Some tasks, such as determining a person’s pose (pose estimation), are solved more naturally if we go to three-dimensional models. But so far there is no consensus on exactly how to represent 3D models - in the form of a grid, a cloud of points, voxels or SDF . Here is another option:
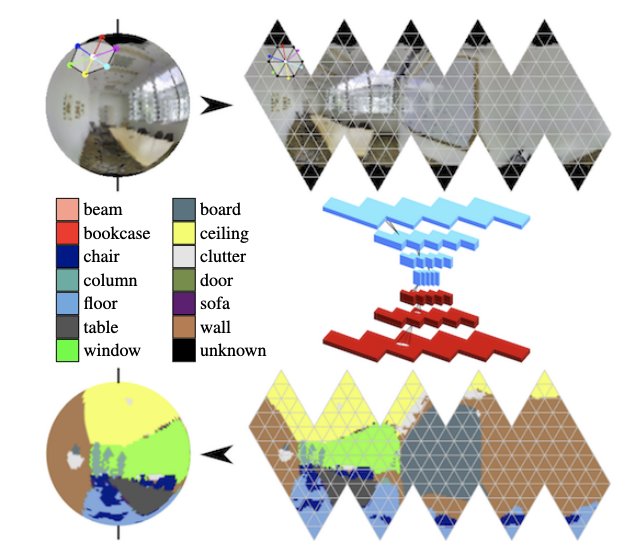
In panoramas, convolutions on the sphere are actively developing (see Orientation-aware Semantic Segmentation on Icosahedron Spheres ) and the search for key objects in the frame.
Definition of posture and prediction of human movements
In order to determine the position in 2D, there is already success - now the focus has shifted towards working with multiple cameras and in 3D. For example, you can also determine the skeleton through the wall, tracking changes in the Wi-Fi signal as it passes through the human body.
Much work has been done in the field of detection of key points on the hand (hand keypoint detection). New datasets appeared, including those based on video with two people’s dialogs - now you can predict hand gestures by audio or text of a conversation! The same progress has been made in gaze assessment tasks.

You can also highlight a large cluster of works related to the prediction of human movement (for example, Human Motion Prediction via Spatio-Temporal Inpainting or Structured Prediction Helps 3D Human Motion Modeling ). The task is important and, based on conversations with the authors, it is most often used to analyze the behavior of pedestrians in autonomous driving.
Manipulating people in photos and videos, virtual fitting rooms
The main trend is to change facial images in terms of interpreted parameters. Ideas: deepfake on one picture, change of expression by face rendering ( PuppetGAN ), feedforward-change of parameters (for example, age ). Style transfers moved from the title of the topic to the application of work. Another story - virtual fitting rooms, they work almost always badly, here is an example of a demo.


Sketch / Graph Generation
The development of the idea “Let the grid generate something based on previous experience” has become different: “Let's show the grid which option interests us.”
SC-FEGAN allows you to do guided inpaint: the user can draw part of the face in the erased area of the image and get the restored image depending on the rendering.

In one of the 25 Adobe articles for ICCV, two GANs are combined: one draws a sketch for the user, the other generates a photo-realistic picture from the sketch ( project page ).

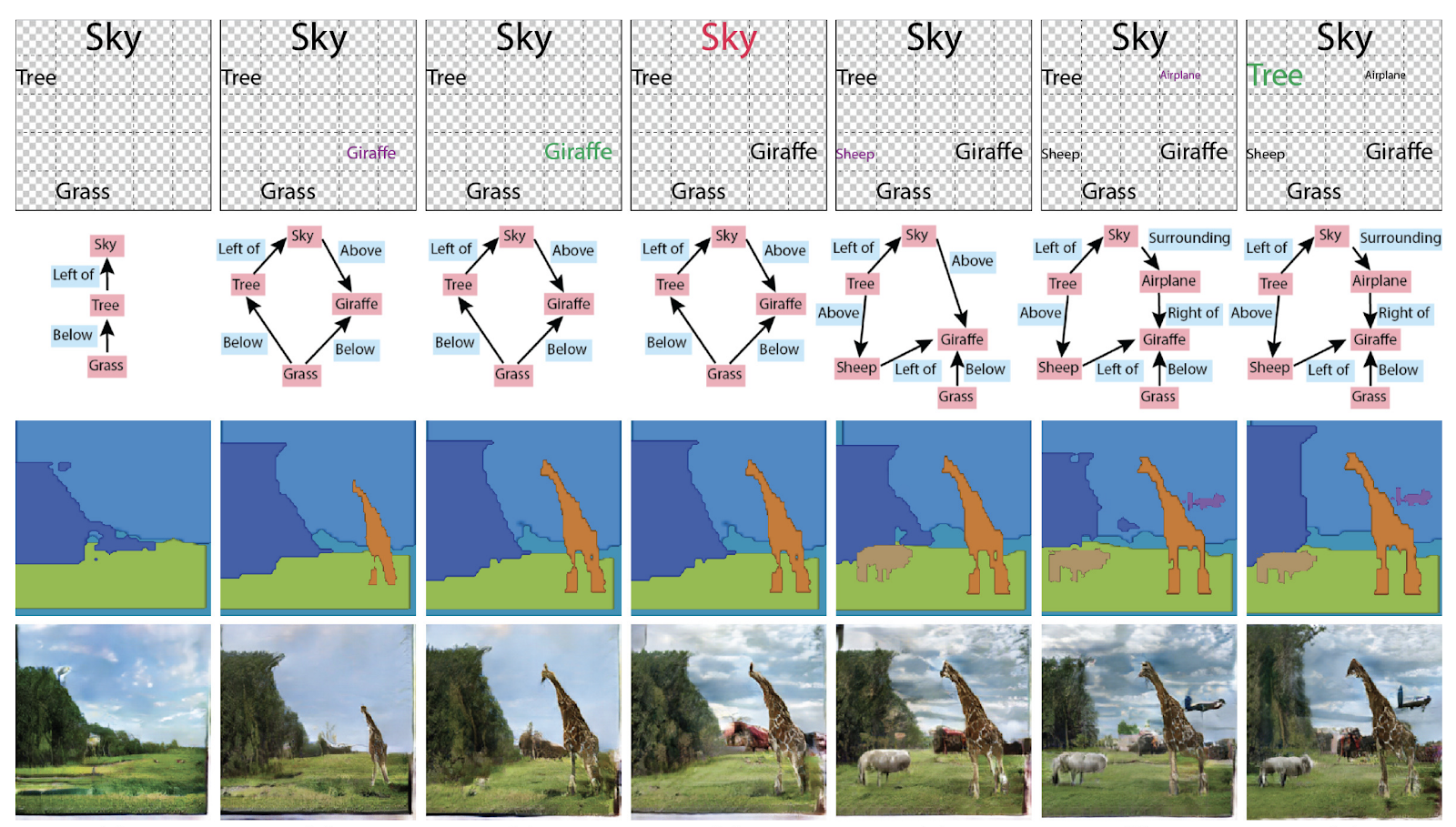
Earlier in the generation of images graphs were not needed, but now they have been made a container of knowledge about the scene. The ICCV Best Paper Honorable Mentions award was also awarded to the article Specifying Object Attributes and Relations in Interactive Scene Generation . In general, you can use them in different ways: generate graphs from pictures, or pictures and texts from graphs.
Re-identification of people and cars, counting the number of crowds (!)
Many articles are devoted to tracking people and re-identification of people and machines. But what surprised us was a bunch of articles on counting people in a crowd, and all from China.
Posters 




But Facebook, on the contrary, anonymizes the photo. Moreover, it does this in an interesting way: it teaches the neural network to generate a face without unique details - similar, but not so much that it is correctly determined by facial recognition systems.

Adversarial Attack Protection
With the development of computer vision applications in the real world (in unmanned vehicles, in face recognition), the question of the reliability of such systems more often arises. To make full use of CV, you need to be sure that the system is resistant to adversarial attacks - therefore there were no less articles about protection against them than about the attacks themselves. A lot of work was about explaining network predictions (saliency map) and measuring confidence in the result.
Combined Tasks
In most tasks with one target, the possibilities of improving quality are almost exhausted; one of the new areas of further quality growth is to teach neural networks to solve several similar problems at the same time. Examples:
- prediction of actions + prediction of optical flow,
- video presentation + language representation ( VideoBERT ),
- super-resolution + HDR .
And there were articles on segmentation, determining the posture and reidentification of animals!

Highlights
Almost all articles were known in advance, the text was available on arXiv.org. Therefore, the presentation of such works as Everybody Dance Now, FUNIT, Image2StyleGAN seems rather strange - these are very useful works, but not new at all. It seems that the classic process of scientific publication is failing here - science is developing too fast.
It is very difficult to determine the best works - there are a lot of them, different subjects. Several articles have received awards and references .
We want to highlight works that are interesting from the point of view of image manipulation, since this is our topic. They turned out to be quite fresh and interesting for us (we do not pretend to be objective).
SinGAN (best paper award) and InGAN
SinGAN: project page , arXiv , code .InGAN: project page , arXiv , code .
Development of the Deep Image Prior idea by Dmitry Ulyanov, Andrea Vedaldi and Victor Lempitsky. Instead of training GAN on a dataset, networks learn from fragments of the same picture in order to remember statistics inside it. The trained network allows you to edit and animate photos (SinGAN) or generate new images of any size from the texture of the original image, while maintaining the local structure (InGAN).
SinGAN:

InGAN:

Seeing What a GAN Cannot Generate
Project page .Image-generating neural networks often receive a random noise vector as their input. In a trained network, many input vectors form a space, small movements along which lead to small changes in the picture. Using optimization, you can solve the inverse problem: find a suitable input vector for a picture from the real world. The author shows that it is almost never possible to find a completely matching picture in a neural network almost never. Some objects in the picture are not generated (apparently, due to the great variability of these objects).
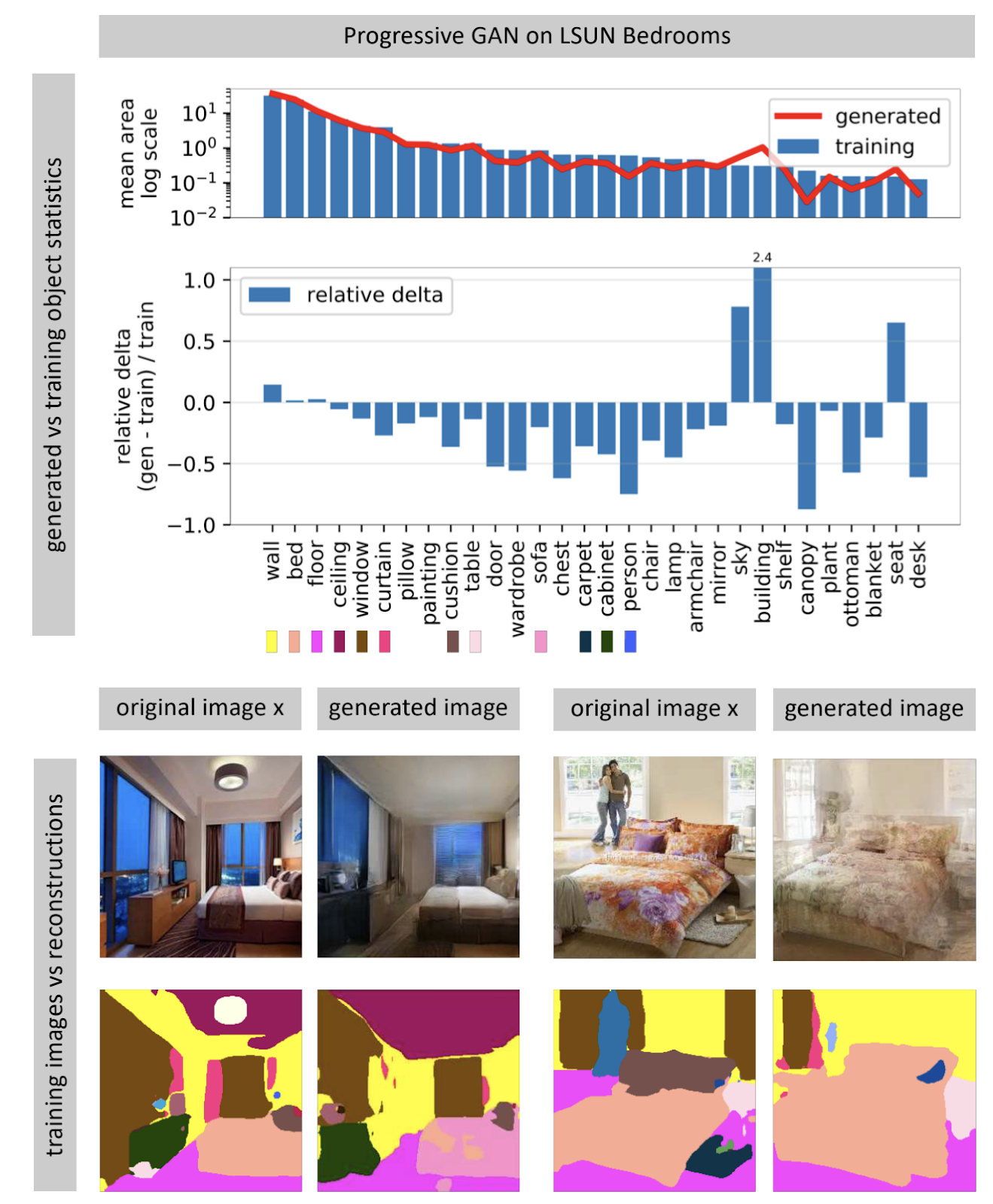
The author hypothesizes that the GAN does not cover the entire space of pictures, but only some subset stuffed with holes, like cheese. When we try to find photos from the real world in it, we will always fail, because the GAN still generates not quite real photos. You can overcome the differences between real and generated images only by changing the weight of the network, that is, retraining it for a specific photo.

When the network is retrained for a specific photo, you can try to carry out various manipulations with this image. In the example below, a window was added to the photo, and the network additionally generated reflections on the kitchen set. This means that the network after retraining for photography did not lose the ability to see the connection between the objects of the scene.

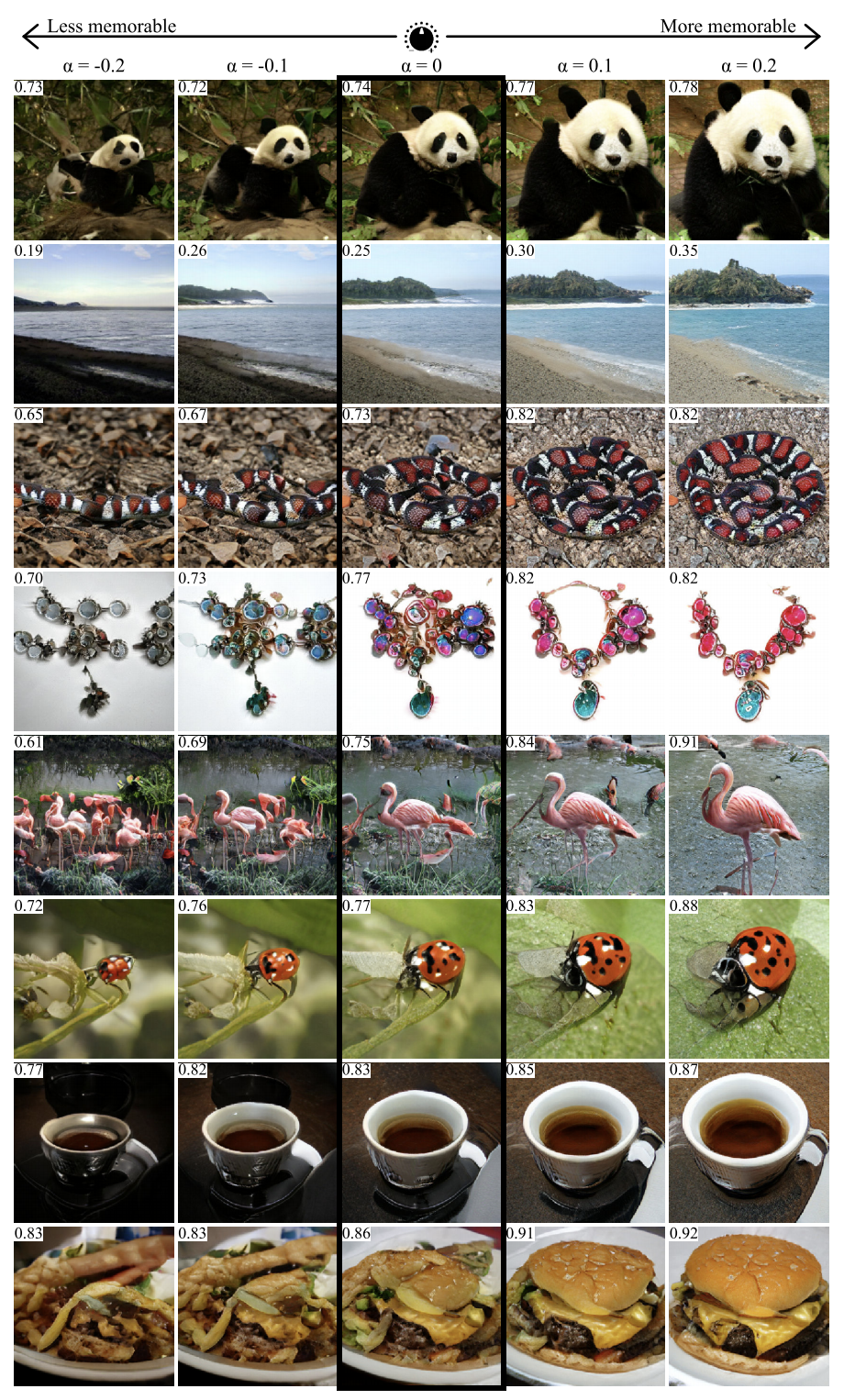
GANalyze: Toward Visual Definitions of Cognitive Image Properties
Project Page , arXiv .Using the approach from this work, you can visualize and analyze what the neural network has learned. The authors propose training GAN to create pictures for which the network will generate given predictions. Several networks were used as examples in the article, including MemNet, which predicts photo memorability. It turned out that for better memorability, the object in the photo should:
- be closer to the center
- have a round or square shape and simple structure,
- be on a uniform background,
- contain expressive eyes (at least for photos of dogs),
- be brighter, richer, in some cases - redder.
Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis
Project page , arXiv , code .Pipeline for generating photos of people from one photo. The authors show successful examples of transferring the movement of one person to another, transferring clothes between people and generating new perspectives of a person - all from one photograph. Unlike previous works, here, to create conditions, not key points in 2D (pose) are used, but a 3D mesh of the body (pose + shape). The authors also figured out how to transfer information from the original image to the generated one (Liquid Warping Block). The results look decent, but the resolution of the resulting image is only 256x256. For comparison, vid2vid, which appeared a year ago, is capable of generating at a resolution of 2048x1024, but it needs as much as 10 minutes of video shooting as a dataset.

FSGAN: Subject Agnostic Face Swapping and Reenactment
Project Page , arXiv .At first it seems that nothing unusual: deepfake with more or less normal quality. But the main achievement of the work is the substitution of faces in one picture. Unlike previous works, training was required on a variety of photographs of a particular person. The pipeline turned out to be cumbersome (reenactment and segmentation, view interpolation, inpainting, blending) and with a lot of technical hacks, but the result is worth it.

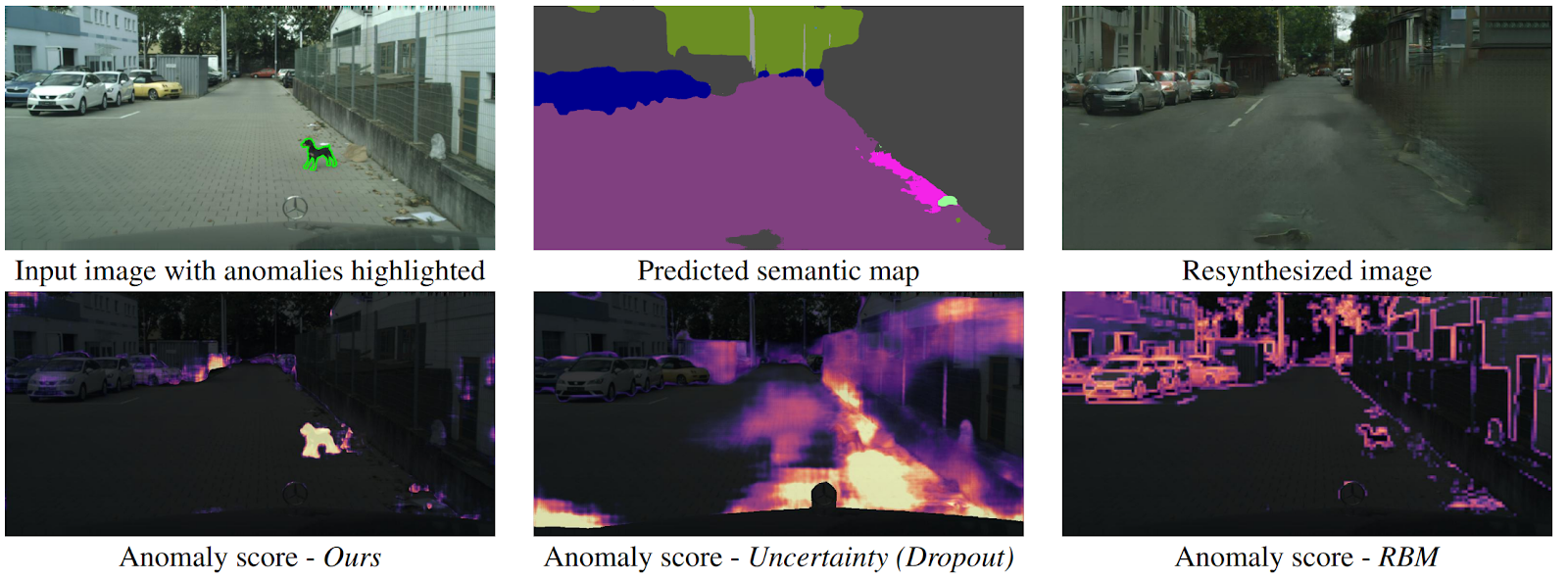
Detecting The Unexpected via Image Resynthesis
arXiv .How can a drone understand that an object suddenly appeared in front of it that does not fall into any class of semantic segmentation? There are several methods, but the authors offer a new, intuitive algorithm that works better than its predecessors. Semantic segmentation is predicted from the input image of the road. It is fed to the GAN input (pix2pixHD), which tries to restore the original image only from the semantic map. Anomalies that do not fall into any of the segments will differ significantly in the source and the generated image. Then three images (initial, segmentation and reconstructed) are fed into another network, which predicts anomalies. The dataset for this was generated from the well-known Cityscapes dataset, randomly changing classes on semantic segmentation. Interestingly, in this setting, a dog standing in the middle of the road, but correctly segmented (which means there is a class for it), is not an anomaly, since the system was able to recognize it.
Conclusion
Before the conference, it is important to know what your scientific interests are, what speeches I would like to get to, with whom to talk. Then everything will be much more productive.
ICCV is primarily networking. You understand that there are top institutions and top scientists, you begin to understand this, to get to know people. And you can read articles on arXiv - and by the way, it’s very cool that you can’t go anywhere for knowledge.
In addition, at the conference you can deeply immerse yourself in topics that are not close to you, see trends. Well, write out a list of articles to read. If you are a student - this is an opportunity for you to get acquainted with a potential scientist, if you are from the industry - then with a new employer, and if the company - then show yourself.
Subscribe to @loss_function_porn ! This is a personal project: we are together with karfly . All the work that we liked during the conference, we posted here: @loss_function_live .