Hello! My name is Vlad and I work as a data scientist in the Tinkoff team of speech technologies that are used in our voice assistant Oleg.
In this article, I would like to give a short overview of speech synthesis technologies used in the industry and share the experience of our team in building our own synthesis engine.

Speech synthesis
Speech synthesis is the creation of sound based on text. This problem today is solved by two approaches:
- Unit selection [1], or a concatenative approach. It is based on gluing fragments of recorded audio. Since the late 90s, it has long been considered the de facto standard for developing speech synthesis engines. For example, a voice using the unit selection method could be found in Siri [2].
- Parametric speech synthesis [3], the essence of which is the construction of a probabilistic model that predicts the acoustic properties of an audio signal for a given text.
The speech of unit selection models is of high quality, low variability and requires a large amount of data for training. At the same time, for training parametric models, a much smaller amount of data is needed, they generate more diverse intonations, but until recently they suffered from an overall rather poor sound quality compared to the unit selection approach.
However, with the development of deep learning technologies, parametric synthesis models have achieved significant growth in all quality metrics and are able to create speech that is practically indistinguishable from human speech.
Quality metrics
Before talking about which speech synthesis models are better, you need to determine the quality metrics by which the algorithms will be compared.
Since the same text can be read in an infinite number of ways, a priori the right way to pronounce a specific phrase does not exist. Therefore, often the metrics for the quality of speech synthesis are subjective and depend on the perception of the listener.
The standard metric is the MOS (mean opinion score), an average assessment of the naturalness of speech, given by assessors for synthesized audio on a scale of 1 to 5. One means completely implausible sound, and five means speech that is indistinguishable from human. Real people records usually get a value of about 4.5, and a value greater than 4 is considered quite high.
How speech synthesis works
The first step to building any speech synthesis system is collecting data for training. Usually these are high-quality audio recordings on which the announcer reads specially selected phrases. The approximate size of the dataset required for training unit selection models is 10–20 hours of pure speech [2], while for neural network parametric methods, the upper estimate is approximately 25 hours [4, 5].
We discuss both synthesis technologies.
Unit selection
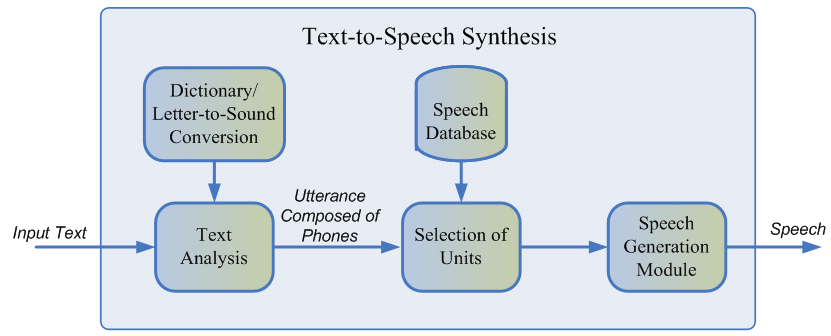
Typically, the recorded speech of the speaker cannot cover all the possible cases in which the synthesis will be used. Therefore, the essence of the method is to split the entire audio base into small fragments called units, which are then glued together using minimal post-processing. Units are usually the minimum acoustic language units, such as half phones or diphons [2].
The entire generation process consists of two stages: the NLP frontend, which is responsible for extracting the linguistic representation of the text, and the backend, which calculates the unit penalty function for the given linguistic features. The NLP frontend includes:
- The task of normalizing the text is the translation of all non-letter characters (numbers, percent signs, currencies, and so on) into their verbal representation. For example, “5%” should be converted to “five percent”.
- Extracting linguistic features from a normalized text: phoneme representation, stress, parts of speech and so on.
Usually, the NLP frontend is implemented using manually prescribed rules for a specific language, but recently there has been an increasing bias towards the use of machine learning models [7].
The penalty estimated by the backend subsystem is the sum of the target cost, or the correspondence of the acoustic representation of the unit for a particular phoneme, and the concatenation cost, that is, the appropriateness of connecting two neighboring units. To evaluate the fine functions, one can use the rules or the already trained acoustic model of parametric synthesis [2]. The selection of the most optimal sequence of units from the point of view of the above-defined penalties occurs using the Viterbi algorithm [1].
Approximate values of MOS unit selection models for the English language: 3.7-4.1 [2, 4, 5].
Advantages of the unit selection approach:
- The natural sound.
- High speed generation.
- Small size of models - this allows you to use synthesis directly on your mobile device.
Disadvantages:
- The synthesized speech is monotonous, does not contain emotions.
- Characteristic gluing artifacts.
- It requires a sufficiently large training base of audio data to cover all sorts of contexts.
- In principle, it cannot generate sound that is not found in the training set.
Parametric speech synthesis
The parametric approach is based on the idea of constructing a probabilistic model that estimates the distribution of acoustic features of a given text.
The process of speech generation in parametric synthesis can be divided into four stages:
- NLP frontend is the same stage of data preprocessing as in the unit selection approach, the result of which is a large number of context-sensitive linguistic features.
- Duration model predicting phoneme duration.
- An acoustic model that restores the distribution of acoustic features over linguistic ones. Acoustic features include fundamental frequency values, spectral representation of the signal, and so on.
- A vocoder translating acoustic features into a sound wave.
For training duration and acoustic models, hidden Markov models [3], deep neural networks, or their recurrent varieties [6] can be used. A traditional vocoder is an algorithm based on the source-filter model [3], which assumes that speech is the result of applying a linear noise filter to the original signal.
The overall speech quality of classical parametric methods is quite low due to the large number of independent assumptions about the structure of the sound generation process.
However, with the advent of deep learning technologies, it has become possible to train end-to-end models that directly predict acoustic signs by letter. For example, the neural networks Tacotron [4] and Tacotron 2 [5] input a sequence of letters and return the chalk spectrogram using the seq2seq algorithm [8]. Thus, steps 1-3 of the classical approach are replaced by a single neural network. The diagram below shows the architecture of the Tacotron 2 network, which achieves a fairly high sound quality.
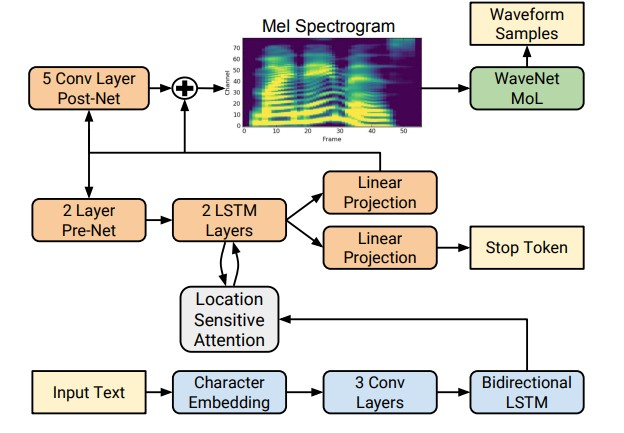
Another factor of significant growth in the quality of synthesized speech was the use of neural network vocoders instead of digital signal processing algorithms.
The first such vocoder was the WaveNet neural network [9], which sequentially, step by step, predicted the amplitude of the sound wave.
Due to the use of a large number of convolutional layers with gaps to capture more context and skip connection in the network architecture, it was possible to achieve about 10% improvement in MOS compared to unit selection models. The diagram below shows the architecture of the WaveNet network.

The main disadvantage of WaveNet is the low speed associated with a sequential sampling circuit. This problem can be solved either by using engineering optimization for a specific iron architecture, or by replacing the sampling scheme with a faster one.
Both approaches have been successfully implemented in the industry. The first is at Tinkoff.ru, and as part of the second approach, Google introduced the Parallel WaveNet network [10] in 2017, the achievements of which are used in the Google Assistant.
Approximate values of MOS for neural network methods: 4.4–4.5 [5, 11], that is, synthesized speech is practically no different from human speech.
Advantages of parametric synthesis:
- Natural and smooth sound using the end-to-end approach.
- Greater variety in intonation.
- Use less data than unit selection models.
Disadvantages:
- Low speed compared to unit selection.
- Great computational complexity.
How Tinkoff Speech Synthesis Works
As follows from the review, methods of parametric speech synthesis based on neural networks are currently significantly superior in quality to the unit selection approach and are much simpler to develop. Therefore, to build our own synthesis engine, we used them.
For training models, about 25 hours of pure speech of a professional speaker was used. The texts for reading were specially selected so as to most fully cover the phonetics of colloquial speech. In addition, in order to add more variety to the synthesis in intonation, we asked the announcer to read texts with an expression depending on the context.
The architecture of our solution conceptually looks like this:
- NLP frontend, which includes neural network text normalization and a model for placing pauses and stresses.
- Tacotron 2 accepting letters as input.
- Autoregressive WaveNet, working in real time on the CPU.
Thanks to this architecture, our engine generates high-quality expressive speech in real time, does not require building a phoneme dictionary, and makes it possible to control stresses in individual words. Examples of synthesized audio can be heard by clicking on the link .
References:
[1] AJ Hunt, AW Black. Unit selection in a concatenative speech synthesis system using a large speech database, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio , R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Siri On-Device Deep Learning-Guided Unit Selection Text-to-Speech System, Interspeech, 2017.
[3] H. Zen, K. Tokuda, AW Black. Statistical parametric speech synthesis, Speech Communication, Vol. 51, no. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous . Tacotron: Towards End-to-End Speech Synthesis.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions.
[6] Heiga Zen, Andrew Senior, Mike Schuster. Statistical parametric speech synthesis using deep neural networks.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman, Brian Roark. Neural Models of Text Normalization for Speech Applications.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Networks.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu. WaveNet: A Generative Model for Raw Audio.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman , Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov, Demis Hassabis. Parallel WaveNet: Fast High-Fidelity Speech Synthesis.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Parallel Wave Generation in End-to-End Text-to-Speech.
[12] Dario Rethage, Jordi Pons, Xavier Serra. A Wavenet for Speech Denoising.