The world saw the first prototype of object storage in 1996. After 10 years, Amazon Web Services will launch Amazon S3, and the world will begin to systematically go crazy with a flat address space. Thanks to working with metadata and its ability to scale without sagging under load, object storage quickly became the standard for most cloud storage services, and more. Another important feature is its good ability to store archives and similar rarely used files. Everyone who was involved in data storage rejoiced and carried the new technology on hand.

But the rumor of people was full of rumors that the object storage is only about big clouds, and if you do not need solutions from the damned capitalists, then it will be very difficult to make your own. Much has been written about the deployment of its cloud, but there is not much information about the creation of the so-called S3-compatible solutions.
Therefore, today we will figure out what are the options “To make it more like adults, not CEPH and a bigger file”, we will deploy one of them, and we will check with Veeam Backup & Replication to verify that everything works. It claims support for working with S3-compatible repositories, and we’ll check this statement.
How about others?
I suggest starting with a small overview of the market and options for object storage. A recognized leader and standard is the Amazon S3. The two closest pursuers are Microsoft Azure Blob Storage and IBM Cloud Object Storage.
Is that all? Are there really no other competitors? Of course, there are competitors, but someone goes his own way, like Google Cloud or Oracle Cloud Object Storage, with incomplete support for the S3 API. Someone is using older versions of the API like Baidu Cloud. And some, like Hitachi Cloud, require the use of special logic, which will certainly cause their difficulties. In any case, everyone is compared with Amazon, which can be considered an industrial standard.
But on-premise solutions have a lot more choices, so let's identify criteria that are important to us. In principle, only two are enough: support for the S3 API and the use of v4 signing. Hand on heart, we, as a future customer, are only interested in interfaces for interaction, and we are not so much interested in the internal kitchen of the storage itself.
Well, a lot of solutions are suitable for these simple conditions. For example, classic corporate heavyweights:
- DellEMC ECS
- NetApp S3 StorageGrid
- Nutanix buckets
- Pure Storage FlashBlade and StorReduce
- Huawei FusionStorage
There is a niche of pure software solutions that work out of the box:
- Red hat ceph
- SUSE Enterprise Storage
- Cloudian
And even those who like to carefully process the file after assembly were not offended:
- Pure ceph
- Minio (Linux version, for the Windows version there are many questions)
The list is far from complete, it can be discussed in the comments. Just remember to check the system performance in addition to the compatibility API before implementation. The last thing you need is the loss of terabytes of data due to hanging requests. So feel free to stress tests. In general, all adult software that works with large amounts of data has at least compatibility reports. In the case of Veeam, there is a whole program for mutual testing, which allows you to safely declare the full compatibility of our products with specific equipment. This is already a two-way work, not always fast, but we are constantly expanding the list of tested solutions.
Putting our stand together
I would like to talk a little about choosing a test subject.
Firstly, I wanted to find an option that would immediately work out of the box. Well, or at least with the maximum probability that he will earn without having to make extra gestures. Dancing with a tambourine and picking the console in the night is very exciting, but sometimes I want it to work right away. And the general reliability of such solutions is usually higher. And yes, the spirit of adventurism disappeared in us, we stopped climbing through the windows of our beloved women, etc. (c).
Secondly, to be honest, the need for working with object storage arises for fairly large companies, so this is the case when looking at the enterprise-level solutions is not only not ashamed, but even encouraged. In any case, I do not yet know examples of someone being fired for buying such solutions.
Based on the foregoing, my choice fell on the Dell EMC ECS Community Edition . This is a very interesting project, and I consider it necessary to tell you about it.
The first thing that comes to mind when looking at the Community Edition add-on is that it's just a tracing-paper from a full-fledged ECS with some restrictions that are removed by buying a license. So no!
Remember:
!!! Community Edition is a standalone project created for testing, and without technical support from Dell !!
And it cannot be turned into a full-fledged ECS, even if you really want to.
Let's understand
Many people think that Dell EMC ECS is almost the best solution if you need object storage. All projects under the ECS brand, including commercial and corporate, lie on the github . A kind of gesture of goodwill from Dell. And in addition to the software that runs on their branded hardware, there is an open source version that can be deployed even in the cloud, at least on a virtual machine, at least in the container, at least on any of your hardware. Looking ahead - there is even an OVA version, which we will use.
DELL ECS Community Edition itself is a mini-version of full-fledged software running on Dell EMC ECS branded servers.
I highlighted four main differences:
- No encryption support. It's a shame, but not critical.
- Missing Fabric Layer. This thing is responsible for cluster building, resource management, updates, monitoring and storage of Docker images. Here it is already very disappointing, but Dell can also be understood.
- The most nasty consequence of the previous paragraph: the size of the node cannot be expanded after the installation is completed.
- No tech support. This is a product for testing, which is not forbidden to use in small installations, but personally I would not dare to upload petabytes of important data there. But technically no one can stop you from doing this.

And what's in the big version?
We gallop through Europe for iron solutions in order to have a more complete picture of the ecosystem.
I will not confirm or refute the statement that DELL ECS is the best on-prem object storage, but if you have anything to say on this subject, I will read it in the comments with pleasure. In any case, according to IDC MarketScape 2018, Dell EMC is confidently one of the five leaders in the OBS market. Although cloud-based solutions are not taken into account there, this is a separate issue.
From a technical point of view, ECS is an object storage that provides access to data via cloud storage protocols. Supports AWS S3 and OpenStack Swift. For file-enabled bucket ECS supports NFSv3 for file export capabilities.
The process of recording information is quite unusual, especially after the classic block storage systems.
- When new data arrives, a new object is created that has a name, data itself and metadata.
- Objects beat on 128 MB chunks, and each chunk is recorded immediately on three nodes.
- The index file is updated, where identifiers and storage locations are recorded.
- The log file (log record) is updated and is also written to three nodes.
- A message about successful recording is sent to the client
All three copies of the data are recorded in parallel. Recording is considered successful only if all three copies have been recorded successfully.

Reading is simpler:
- The client requests data.
- The index is looking for a place to store data.
- Data is read from one node and sent to the client.

There are quite a few servers themselves, so let's look at the smallest Dell EMC ECS EX300. It starts at 60Tb, with the ability to grow to 1.5Pb. And his older brother Dell EMC ECS EX3000 can already store as much as 8.6Pb per rack.
Deploy
Technically, Dell ECS CE can be deployed arbitrarily large. In any case, I did not find any explicit restrictions. However, all scaling is conveniently done by cloning the very first node, for which we need:
- 8 vCPU
- 64GB RAM
- 16GB for OSes
- 1TB directly for storage
- Latest CentOS minimal release
This is an option for the case when you want to install everything yourself from the very beginning. For us, this option is not relevant, because I will use the OVA image for deployment.
But in any case, the requirements are very evil even for one node, and if you strictly follow the letter of the law, then there are four such nodes.
However, ECS CE developers live in the real world, and the installation is successful even with one node, and the minimum requirements are as follows:
- 4 vCPU
- 16 GB RAM
- 16 GB for OSes
- 104 GB self storage
It is these resources that are needed to deploy an OVA image. Already much more humane and realistic.
The installation node itself can be taken in the official github . There is also detailed documentation on an all-in-one deployment, but you can still read on the official readthedocs . Therefore, we will not dwell on the deployment of OVA in detail, there are no tricks. The main thing - do not forget before starting it, either expand the disk to the desired volume, or attach the necessary ones.
We start the car, open the console and use the best default credits:
- login: admin
- password: ChangeMe
Then we start sudo nmtui and configure the network interface - IP / mask, DNS and gate. Bearing in mind that CentOS minimal does not have net-tools, we check the settings via ip addr.

And since the seas only boldly submit, we do yum update, after which reboot. In fact, it is quite safe, because all deployment is done through playbooks, and all important docker packages are locked on the current version.
Now it's time to edit the installation script. No beautiful windows or pseudo UI for you - all through your favorite text editor. Purely technically, there are two ways: you can start each command with handles or immediately start the videploy configurator. It will simply open the config in vim, and upon exit, it will start its verification. But deliberately simplifying your life is not interesting, so we’ll do two more teams. Although it makes no sense, I warned you =)
So, we do vim ECS-CommunityEdition / deploy.xml and make the optimal minimum changes so that ECS turns on and works. The list of parameters can be shortened, but I did like this:
- licensed_accepted: true You can not change it, then when deploying you will be explicitly asked to accept it and will show a nice phrase. Perhaps this is even an easter egg.

- Uncomment the lines of autonames: and custom: Enter at least one desired name for the node - hostname will be replaced by it during the installation process.
- install_node: 192.168.1.1 Specify the real IP nodes. In our case, we indicate the same as in nmtui
- dns_domain: enter your domain.
- dns_servers: enter your dns.
- ntp_servers: you can specify any. I took the first one from the pool 0.pool.ntp.org (it became 91.216.168.42)
- autonaming: custom If you do not uncomment, the moon will be called Luna.
- ecs_block_devices:
/ dev / sdb
For some unknown reason, there may be a nonexistent block storage device / dev / vda - storage_pools:
members:
192.168.1.1 Here again we indicate the real IP nodes - ecs_block_devices:
/ dev / sdb Repeat the operation of cutting non-existent devices.
In general, the entire file is described in great detail in the documentation , but who will read it in such a hectic time. It also says that the minimum is enough to specify the IP and mask, but in my lab this set up was not good, and I had to expand to the above.

After exiting the editor, run update_deploy /home/admin/ECS-CommunityEdition/deploy.yml, and if everything is done correctly, this will be reported explicitly.

Then you still have to start videploy, wait for the environment to be updated, and you can start the installation itself with the ova-step1 command, and after its successful execution, the ova-step2 command. Important: do not stop the scripts with your hands! Some steps can take considerable time, not performed on the first try and look like everything has broken. In any case, you must wait for the script to complete in a natural way. At the end you should see something like this message.

Now, finally, we can open the WebUI control panel over the IP we know. If you did not change the configuration step, then the default account will be root / ChangeMe. You can even immediately use our S3-compatible storage. It is available on ports 9020 for HTTP, and 9021 for HTTPS. Again, if you didn’t change anything, then access_key: object_admin1 and secret_key: ChangeMeChangeMeChangeMeChangeMeChangeMe.
But let's not get ahead of ourselves and start in order.

At the first login, you will be forcibly asked to change the password to an adequate one, which is absolutely correct. The main dashboard is extremely understandable, so let's do something more interesting than explaining the obvious metrics. For example, create a user that we will use to access the repository. In the world of service providers, they are called tenant. This is done in Manage> Users> New Object User

When creating a user, we are asked to specify a namespace. Technically, nothing prevents us from getting them as many as there will be users. And vice versa. This allows you to manage resources independently for each tenant.
Accordingly, we select the functions we need and generate the user keys. S3 / Atmos will be enough for me. And do not forget to save the key;)

The user was created, now it's time for him to select the bucket. Go to Manage> Bucket and fill in the required fields. Everything is simple here.

Now we are ready for a fully combat use of our S3 storage.
Customize Veeam
So, as we recall, one of the main applications of object storage is the long-term storage of information that is rarely accessed. An ideal example is the need to store backups on a remote site. In Veeam Backup & Replication, this feature is called Capacity Tier.
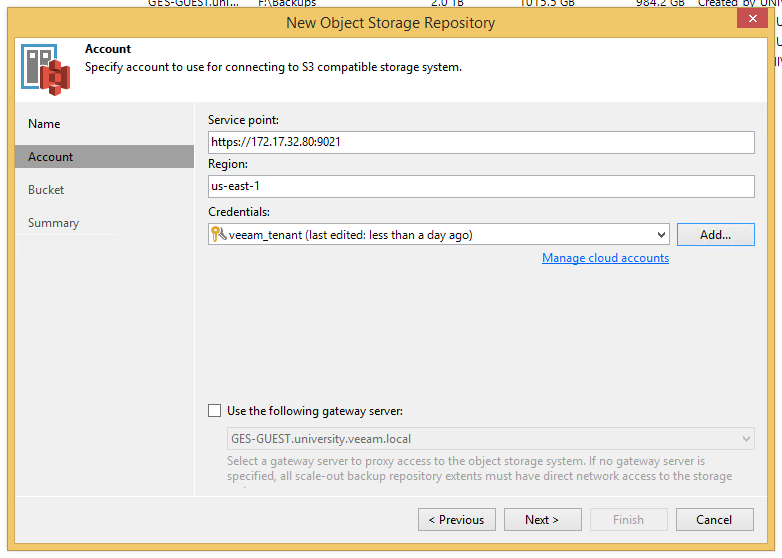
Let's start the setup by adding our Dell ECS CE to the Veeam interface. On the Backup Infrastructure tab, launch the Add New Repository Wizard and select the Object Storage item.

We choose what it was all about - S3 Compatible.

In the window that appears, write the desired name and go to the Account step. Here you need to specify the Service point in the form https: // your_IP: 9021 , you can leave the region as is, and add the created user. A gate server is needed if your storage is located on a remote site, but this is already a topic of infrastructure optimization and a separate article, so you can safely skip here.
If everything is specified and configured correctly, a certificate warning will come out and then a window with a bucket where you can create a folder for our files.

We go through the wizard to the end and enjoy the result.

In the next step, you need to either create a new Scale-out Backup Repository, or add our S3 to the existing one - it will be used as Capacity Tier for archive storage. Functions to use S3-compatible repositories directly, like a regular repository, are not in the current release. Too many rather unobvious problems must be solved for this, but everything can be.
We go into the repository settings and turn on Capacity Tier. Everything is transparent there, but there is an interesting nuance: if you want all the data to be sent to the object storage as soon as possible, just set 0 days.

After passing the wizard, if you do not want to wait, you can click ctrl + RMB on the repository, force the Tiering job to start and watch the charts crawl.

That's all for now. I consider the task to show that block storage is not as scary as it is customary to think, I managed. Yes, decisions and options for the execution of a wagon and a small trolley, but for one article, there is nothing to cover. So let's share the experience in the comments.