
I must say right away that we at Acronis are especially careful about testing APIs. The fact is that our own products access services through the same APIs that are used to connect external systems. Therefore, performance testing of each interface is required. We test the operation of the API and isolate the operation of the UI in isolation. Test results will allow you to evaluate whether the API itself works well, as well as user interfaces. Confirm successful development or formulate a task for further development.
But tests differ. Sometimes a service does not demonstrate degradation right away. Even if we run a service similar to the products already released in the release, for verification you can load it with the same data that is used “in prod”. In this case, you can see the regression, but it is absolutely impossible to assess the perspective. You simply don’t know what will happen if the amount of data increases sharply or the frequency of requests increases.
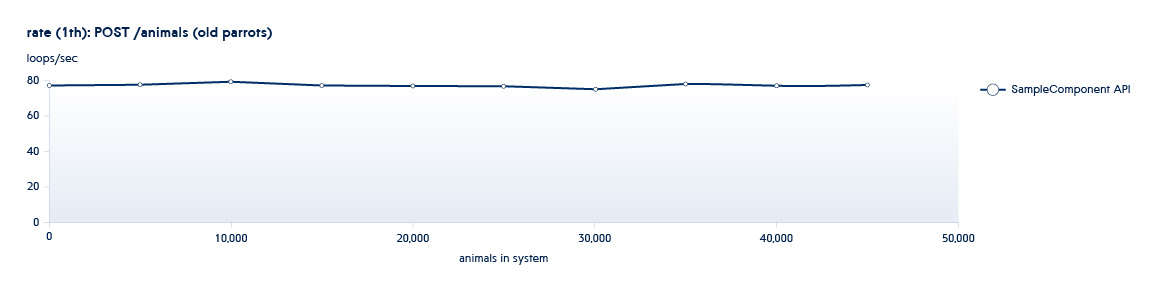
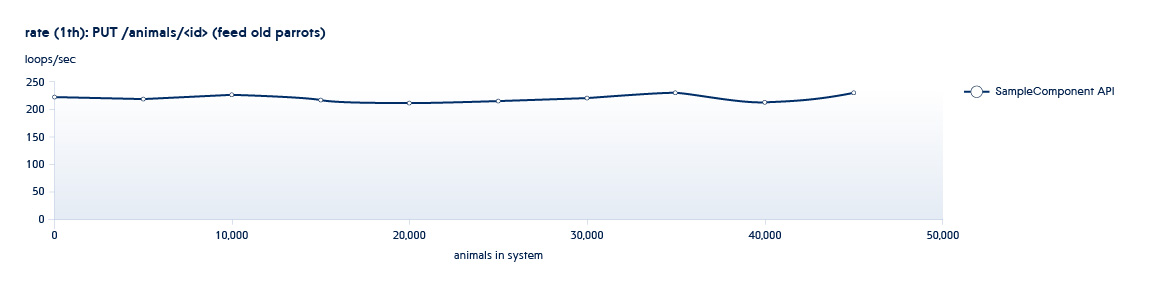
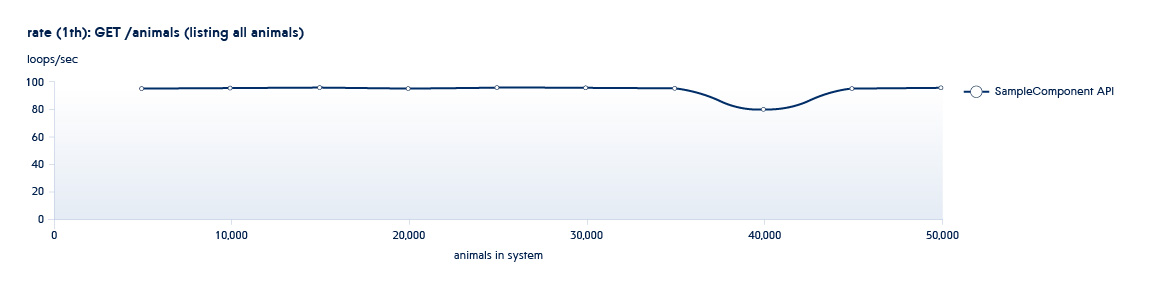
Below is a graph showing how the number of APIs processed by the backend per second changes with the growth of data in the system

Suppose that the service we are testing is in a state typical of the beginning of this schedule. In this case, even with a small growth of the system, the speed of this API will sharply decrease.
To eliminate such situations, we increase the amount of data by several times, increase the number of parallel threads to understand how the service will behave if the load increases dramatically.
But there is one more nuance. If the work of a “familiar” service changes in accordance with the growth in the amount of data, its development, the emergence of new functions, with new services the situation is even more complicated. When a conceptually new service appears in a product, it needs to be considered from many different angles. For this situation, you need to prepare special data sets, conduct load testing, suggesting possible use cases.
Features of performance testing in Acronis
Typically, our testing processes take place in a “spiral pattern." One of the testing phases involves using the API to increase the number of entities (sizing), and the second performing new operations on existing datasets (usage). All tests run in a different number of threads. For example, we have the Animals service, and it has the following APIs:
POST /animals PUT /animals/<id> GET /animals?filter=criteria
1 and 2 are APIs called in sizing tests - they increase the number of new entities in the system.
3 are APIs called in the usage phase. This API has a ton of filtering options. Accordingly, there will be more than one test
Thus, by running iteratively sizing and usage tests, we get a picture of the change in system performance with its growth

Framework needed ...
To conduct large-scale testing of a large number of new and updated services, we needed a flexible framework that would allow us to run different scripts. And the main thing is to really test the API, and not just create a load on services with repetitive operations.
Performance testing can take place both on a synthetic load and using a load pattern recorded from production. Both approaches have their pros and cons. A method with a real load can be more characterized as stress testing - we get a real picture of the system’s performance under such a load, but we don’t have the ability to easily identify problem areas, measure the throughput of the components individually, we don’t get the exact numbers which load the individual components can withstand. In the case of the synthetic approach, we get exact numbers, we have great flexibility, and we can easily fix the problem areas, and by running several test scripts in parallel, we can reproduce the stress load. The main disadvantages of the second approach are the high labor costs for writing test scripts, as well as the growing risk of missing some important script. Therefore, we decided to go the more difficult way.
So, the choice of a framework was determined by the task. And our task is to:
- Finding API bottlenecks
- Check resistance to high loads
- Evaluate the effectiveness of the service with the growth of data volumes
- Identify cumulative errors that occur over time
There are so many Performance frameworks on the market that can fire a huge number of identical requests. Many of them do not allow changing anything inside (for example, Apache Benchmark) or with limited capabilities for describing scripts (for example, JMeter).
We usually use more complex scripts in testing. Often, API calls need to be made sequentially - one after another, or to change the request parameters in accordance with some kind of logic. The simplest example when we want to test a REST API of the form
PUT /endpoint/resource/<id>
In this case, you need to know in advance the <id> of the resource that we want to change in order to measure the net query execution time.
Therefore, we need the ability to create scripts to run complex test queries.
Faster
Because Acronis products are designed for high load, we are testing the API in tens of thousands of requests per second. It turned out that not every framework can allow this to be done. For example, Python is not always and not always possible to use for testing, because due to the peculiarities of the language the ability to create a large multi-threaded load is limited
Another problem is the use of resources. For example, we first looked at the Locust framework, which can be run from multiple hardware nodes at once and get good performance. But at the same time, a lot of resources are spent on the work of the test system, and it turns out to be expensive to operate.
As a result, we chose the K6 framework, which allows us to describe scripts in full-fledged Javascript, and provides above-average performance. This framework is written in Go, and is rapidly gaining popularity. For example, on Github, the project has already received almost 5.5 thousand stars! K6 is actively developing, and the community has already proposed almost 3 thousand commits, and the project has 50 contributors who have created 36 code branches. Of course, K6 is still far from ideal, but gradually the framework is getting better, and you can read about its comparison with Jmeter here .
Difficulties and their solutions
Given the “youth” of K6, even after a balanced choice of the framework, we ran into a number of problems. For example, before testing an API of the form / endpoint /, you must first find these endpoints somehow. We cannot use the same values, because due to caching the results will be incorrect.
You can get the data you need in different ways:
- You can request them via API
- You can use direct access to the database
The second method works faster, and when using relational DBs it often turns out to be much more convenient, since it allows you to save significant time during lengthy tests. The only “but” is that you can use it only if the service code and tests are written by the same people. Because to work through the database, tests must always be up to date. However, in the case of K6, the framework does not have database access mechanisms. Therefore, I had to write the appropriate module myself.
Another problem arises when testing non-idempotent APIs. In this case, it is important that they are called only once with the same parameters (for example, the DELETE API). In our tests, we prepare the test data in advance, at the setup phase, when the system is set up and prepared. And during the test, measurements are made of pure API calls, since time and resources for preparing data are no longer required. However, this raises the problem of distributing pre-prepared data across non-synchronized flows of the main test. This problem was successfully resolved by writing an internal data queue. But this is a whole big topic, which we will talk about in future posts.
Ready Framework
Summing up, I would like to note that it was not easy to find a completely ready-made framework, and I still had to finish some things with my hands. Nevertheless, today we have a tool that is suitable for us, which, taking into account the improvements, allows us to conduct complex tests, creating a simulation of high loads to guarantee the performance of the API and GUI in different conditions.
In the next post, I will talk about how we solved the problem of testing a service that supports the simultaneous connection of hundreds of thousands of connections using minimal resources.