 For the past 16 years, Greenplum, an open, massive parallel parallel database management system, has helped a variety of enterprises make decisions based on data analysis.
For the past 16 years, Greenplum, an open, massive parallel parallel database management system, has helped a variety of enterprises make decisions based on data analysis.
During this time, Greenplum penetrated into various business areas, including: retail, fintech, telecom, industry, e-commerce. Scaling to hundreds of nodes horizontally, fault tolerance, open source code, full compatibility with PostgreSQL, transactionality and ANSI SQL - it is difficult to imagine a better combination of properties for an analytical DBMS. Starting from huge clusters in world giant companies, such as Morgan Stanley (200 nodes, 25 Pb of data) or Tinkoff (> 70 nodes), and ending with small two-node installations in cozy startups, more and more companies choose Greenplum. It is especially pleasant to observe this trend in Russia - over the past two years, the number of large domestic companies using Greenplum has tripled.
In the fall of 2019, another major DBMS release was released. In this article, I will briefly talk about the main new features of GP 6.
The previous major release of Greenplum version 5 was published in September 2017, details can be found in this article . If you still do not know what Greenplum is, a brief introduction can be obtained from this article . It is old, but the DBMS architecture reflects correctly.
The current release, by right, can be called a collective brainchild: several companies from around the world participated in the development - among them Pivotal, Arenadata (where the author of this article works), Alibaba.
So what's new in Greenplum 6?
Replicated tables
Let me remind you that in Greenplum there were two types of distribution of tables across a cluster:
- Random uniform distribution
- Distribution on one or several fields
In most cases, joining two tables (JOINs) was performed with data redistribution between cluster segments during query execution, and only if both tables were initially distributed by JOIN join key occurred locally on segments without transferring data between segments.
GP 6 gives architects a new storage scheme optimization tool - replicated tables. Such tables are duplicated in full on all segments of the cluster. Any connection to such a table in the right part will be performed locally, without data redistribution. Basically, the feature is intended for storing voluminous directories.
Query example with replicated table
CREATE TABLE expand_replicated … DISTRIBUTED REPLICATED; CREATE TABLE expand_random … DISTRIBUTED RANDOMLY; explain select * from expand_rnd a2 left join expand_replicated a3 on a2.gen = a3.gen # , redistribute/broadcast Limit (cost=0.00..1680.04 rows=1 width=22) -> Gather Motion 144:1 (slice1; segments: 144) (cost=0.00..1680.04 rows=2 width=22) -> Hash Left Join (cost=0.00..1680.04 rows=1 width=22) Hash Cond: (expand_rnd.gen = expand_replicated.gen) -> Seq Scan on expand_rnd (cost=0.00..431.00 rows=1 width=10) -> Hash (cost=459.60..459.60 rows=2000000 width=12) -> Seq Scan on expand_replicated (cost=0.00..459.60 rows=2000000 width=12)
Zstandard Compression Algorithm (ZSTD)
Presented in 2016 by the Facebook developers, the lossless compression algorithm almost immediately fell into the soul of our Arenadata team, because compared to Zlib (used by default in Greenplum) it has higher compression ratios with less time required for compression and decompression:
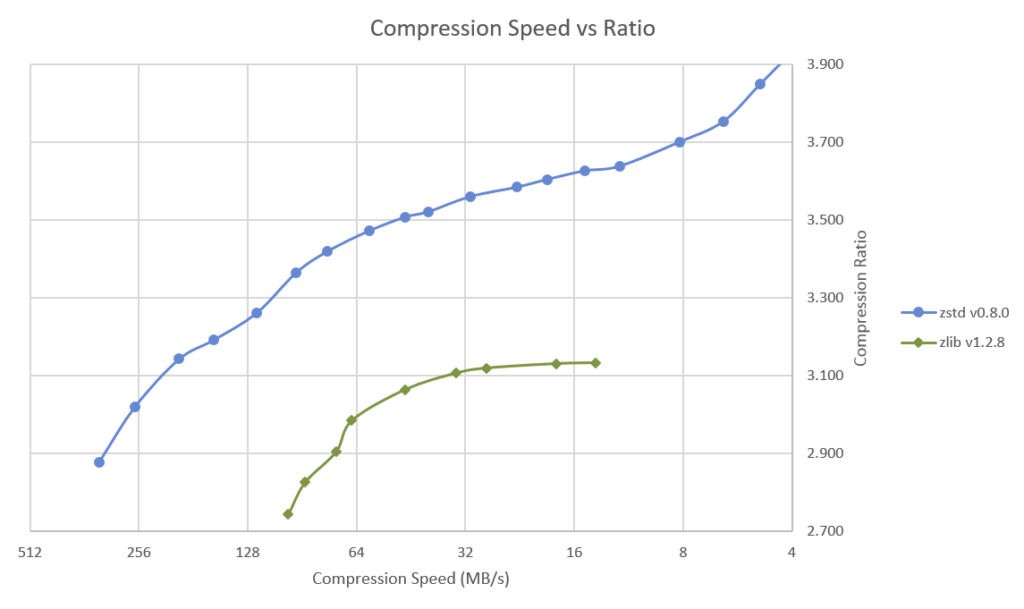
Source: cnx-software.com
Compression efficiency is one of the most important parameters of modern analytical DBMS. In fact, it allows you to reduce the load on the relatively expensive disk subsystem of the cluster by loading relatively cheap CPUs. By sequentially reading and writing large amounts of data, this results in a significant reduction in the TCO of the system.
In 2017, our team added ZSTD support for column tables in Greenplum, however, according to the release policy, this revision did not get into the official minor releases of Greenplum. Until today, it was available only to Arenadata commercial customers, and with the release of 6.0, everyone can use it.
Cluster expansion optimization (expand)
In previous versions of GP, horizontal cluster expansion (adding new nodes) had some limitations:
- Even though the redistribution of data occurred in the background without downtime, a system restart was necessary when adding new nodes
- The hashing and data distribution algorithm required a complete redistribution of all tables during expansion - the background data distribution process could take hours or even days for especially large clusters
- During the background distribution of tables, any join was only distributed
Greenplum 6 introduced a completely new cluster expansion algorithm, due to which:
- Expansion now occurs without restarting the system - downtime is not needed
- The consistent hashing algorithm allows you to redistribute only part of the blocks when adding nodes, that is, the background redistribution of tables works many times faster
- The logic for changing system directories has changed - now even during the expansion process all connections (JOINs) work as usual - both locally and distributed
Now the Greenplum extension is a matter of minutes, not hours, this will allow clusters to follow the ever growing appetites of business units.
Column-level security
Now it is possible to distribute rights to specific columns in the tables (the feature came from PostgreSQL):
grant all (column_name) on public.table_name to gpadmin;
Jsonb
Binary, optimal storage of JSON-type objects is now available in the GP. Read more about the format here .
Auto Explain
Another great extension that came to the GP from PostgreSQL. It was modified to work in distributed mode on the Greenplum cluster by the Arenadata team.
Allows automatically for each (or separately taken) request in the DBMS to save information about:
- request plan;
- consumed resources at each stage of query execution on each segment (node);
- time spent;
- the number of rows processed at each stage of the query on each segment (node).
Diskquota
PostgreSQL extension to limit the available disk storage available to individual users and schemes:
select diskquota.set_schema_quota('schema_name', '1 MB'); select diskquota.set_role_quota('user_name', '1 MB');
New Arenadata DB Distribution Features
Disclaimer - there will be a couple of lines of advertising next :)
Let me remind you, we, Arenadata, are developing, implementing and supporting our data storage platform based on open source technologies - Greenplum, Kafka, Hadoop, Clickhouse. Our clients are the largest Russian companies in the fields of retail, telecom, fintech and others. On the one hand, we are the contributors of open-source projects themselves (committing changes to the kernel), on the other hand, we are developing additional functionality that is available only to our commercial customers. Further we will talk about the main features.
Tkhemali Connector aka Connector Greenplum -> Clickhouse
In projects, we often use the Greenplum + Clickhouse bunch - on the one hand, this allows us to use the best classical models of building data warehouses (from sources to data marts) that require many connections, developed ANSI SQL syntax, transactionality and other chips that Greenplum has, on the other, to provide access to the built-in wide shop-windows with a maximum speed to a significant number of users - and Clickhouse has no competitors in this.
For the effective use of such a bundle, we have developed a special parallel connector, which transactionally (that is, consistent even in the case of a rollback transaction) allows you to transfer data from the GP to KH. In general, the architecture of this connector deserves a separate, purely technical article - in fact, inside we had to implement parallel asynchronous queues with a system for dynamically selecting the number of threads per insert and data flow.
The result is a fantastic interaction speed: in our tests on typical SATA disks, we get up to 1 Gb / s per insert on one pair of Greenplum servers - Clickhouse. Given that the average GP cluster at our customers consists of 20+ servers, the interaction speed is more than sufficient.
Kafka connector
We did the same with integration with the Kafka message broker - we often encounter the task of overloading data from Kafka to Greenplum in near real-time mode (seconds or tens of seconds). However, the connector architecture for Kafka is different. A connector is a cluster of separate synchronized processes (launched in Docker) with auto-discovery, which, on the one hand, are Kafka consumiers, and on the other hand, they insert data directly into Greenplum segments. The connector can work with Kafka Registry and ensures the complete consistency of the transferred data even in case of hardware failures.
Management and monitoring system
The operation of the system in production places high demands on the deployment, updating and monitoring of the cluster. It is important that everything that happens in the DBMS is transparent to operations and DBA specialists.
Our Arenadata Cluster Manager (ADCM) management and monitoring system gives operation professionals all the tools they need. In fact, deploying and updating the Greenplum cluster is done at the click of a button in the graphical interface (all OS, services, disk mounting and network settings are done automatically), in addition, you get a fully configured monitoring stack, ready to integrate with your corporate systems. By the way, Arenadata Cluster Manager can manage not only Greenplum, but also Hadoop, Kafka, Clickhouse (our assemblies of these services are required. Their free versions, like ADCM itself, can be downloaded absolutely free on our website , just by filling in pop-up).
Conclusion
If you are using Greenplum 5.X, I recommend considering upgrading your cluster to the current version 6.X in the next 2-3 months.
If you are not using Greenplum yet, join us! We, Arenadata, are always ready to help you with this.
References
Greenplum on github
Greenplum Russia Telegram channel - ask your questions directly to Greenplum users
Greenplum 6 Documentation