{kind=link}

Around the same time, a announcement was made about the Vulcain project. This message included the words: "TL / DR: GraphQL you no longer need!". And finally, a great article by Mark Nottingham on the powerful HTTP / 2 features and what those features mean for those who design the API has been released. Darrel Miller shared a link to this article with his subscribers.
{kind=link}
What was happening made me think about GraphQL and HTTP / 2. If everything starts working using HTTP / 2 (and HTTP / 3), will this mean that we have no reason to use GraphQL? I would like to find out today.
HTTP / 2 innovations
To get started, let's figure out what HTTP / 2 technology can affect the value of GraphQL in the eyes of developers. HTTP / 2 has a lot to offer. This is, for example, a new binary format and improved header compression. But in our case, the main role is played by how the delivery of requests and responses is processed when using HTTP / 2.
Opening a TCP connection is a costly operation. Clients using HTTP / 1 tend to not run it too often. For this reason, due to the large additional load on the system, developers often tried to limit the number of requests by resorting to a variety of technologies. This, for example, executing batch queries, using query languages, embedding CSS / JS code in the page code, using sprite sheets instead of individual images, and so on. In HTTP / 1.1. an attempt was made to solve some of these problems using persistent connections and pipelined data processing. These two technologies allowed browsers to send, within the same connection, several requests, and to receive answers to them. The disadvantage of such a data exchange scheme was that it was subject to the problem of blocking the beginning of the queue ( Head-of-line blocking ). This problem is expressed in the fact that one slow request can slow down the processing of all requests following it. The experts who worked on HTTP / 2 suggested different ways to solve this problem. Together with the new binary protocol, HTTP / 2 also introduces a new data delivery strategy. During the interaction of systems using the HTTP / 2 protocol, a single connection is opened, within which multiplexing of requests and responses is performed using a new binary level designed to work with frames when each frame is part of a stream. Using this mechanism, clients and servers can recreate request and response flows based on the information about them that is in frames. This allows HTTP / 2 to very effectively support the processing of multiple requests that are executed within a single connection.
But that's not all. HTTP / 2 has a new concept called Server Push. Without going into details, we can say that this technology allows servers to send data to clients in advance, doing this before clients request this data. The most striking examples of this behavior are sending stylesheets and JavaScript resources to clients in advance. In the process of generating a response to an HTTP request, the server can find out that a certain CSS file is needed to render the HTML page, and find out in advance that the client will contact him soon for this file. This allows the server to send the given file to the client even before the client requests it. This is how the aforementioned Vulcain project works, using this technology to organize the efficient loading of related resources.
So, while everything is clear. But what does all this have to do with GraphQL?
GraphQL: one query that solves all problems
GraphQL technology is partly due to its attractiveness in that it helps developers cope with the disadvantages typical of HTTP / 1 connections.
That is why GraphQL allows customers, in one session to communicate with the server, to fulfill requests to receive almost anything. This can be contrasted with the Hypermedia-API, when using which you usually need to perform many network requests (sometimes, however, caching can improve the situation).
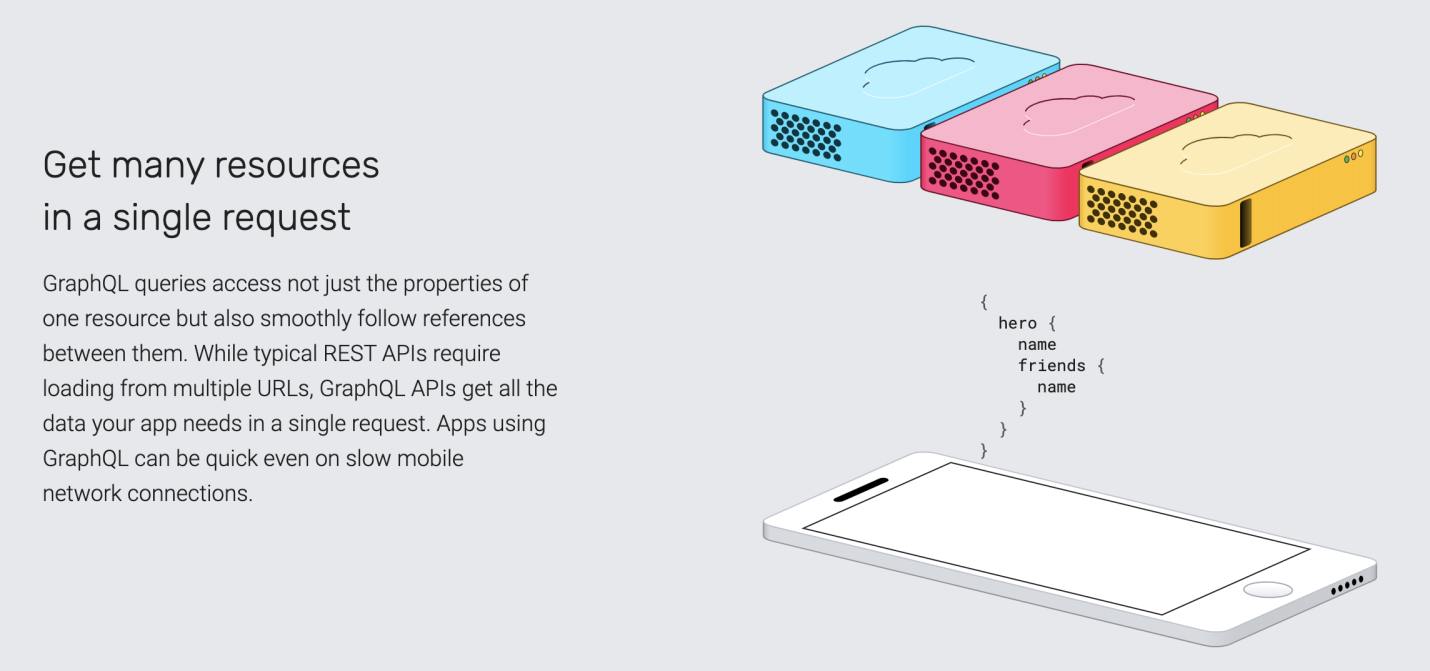
The ability to receive multiple resources within a single query is one of GraphQL's strengths , to which the creators of this technology attract the attention of its potential users.
Many of those who say that nobody needs GraphQL technology with the advent of HTTP / 2 mean this possibility. Using batch APIs, query languages (such as GraphQL), optimizing relationships, and even creating aggregated endpoints, now look less attractive than before. The thing is that the "cost" of query execution becomes small. And that is true. But is this only why we use GraphQL? I do not think so.
Perhaps the point is that now is still the early days of HTTP / 2 clients and some server applications?
I do not think that the question posed in the title of this section serves as a worthy explanation for the fact that we are still widely using GraphQL. But it's worth mentioning. Using application-level HTTP / 2 in some ecosystems is a challenge that is far from being resolved. Look for, for example, the words "Rack / Rails over HTTP / 2." It will be interesting. The thing is that many server parts of applications are built using the request / response pattern. As a result, switching to the concept of HTTP / 2 streams is not so simple. Especially in the case of some frameworks. But this is an unworthy excuse, many ecosystems perfectly support such a scheme of interaction between clients and servers, and, in theory, we should still strive to improve such interaction. (Most proxies also support this, but it’s not easy to organize something like sending data to a client at the server’s initiative if the server application is stuck in the past using a request / response pattern).
GraphQL is more than reducing the time of receiving and transmitting data, or optimizing the amount of information transmitted
Although reducing the time of receiving and transmitting data and optimizing the amount of transmitted information are the strengths of GraphQL that we constantly hear about, this technology gives us much more.
The power of GraphQL technology lies in its focus on client systems. The client is the environment in which GraphQL makes many compromises. In recent years, this has bothered many. So, Daniel Jacobson wrote many good articles about some of these problems 5-7 years ago. Here and there - a couple of his publications. He says in one of them: "Our REST APIs, although they are able to handle general requests, are not optimized for any of these requests."
Please note that this idea is valid not only when applied to REST technology. Client applications often have to perform more server requests than their developers would like. These applications have to deal with receiving unnecessary data from servers. This is more about designing APIs that would be nice to build so that they support many different uses. The usual way to solve this problem is to have the client logic as close as possible to the server logic. An example of this approach is the Netflix client adapters mentioned in this 2012 article. Since then, some Netflix teams have even switched to GraphQL. The BFF pattern is also aimed at solving such problems.
GraphQL technology is changing the concept of the boundary between the client and the server, helping us create server systems that can include information about how they will be used by clients. This is quite clearly manifested when using the technology of constant requests, since here we are talking, in essence, about server resources generated at the initiative of the client.
When thinking about the relevance of GraphQL in the HTTP / 2 world, remember that we are talking about server abstraction. Supporting a variety of server-side use cases can lead to problems in traditional endpoint-based APIs. GraphQL allows those who support the API to concentrate on giving users of these APIs a wide range of features. At the same time, the owners of the API can not worry about the growing load on existing customers, and that the support for the API will become much more complicated due to the need to support many different resources. (Support for many different resources has its drawbacks. So, such schemes complicate performance optimization. Such resources are not always well cached. APIs that can be heavily tuned face the same problems).
Client Systems and GraphQL Development
In this article, I mainly talk about servers, but it is important to remember that client developers are very fond of GraphQL technology. If you combine GraphQL fragments with the component approach from modern front-end frameworks, you get a completely amazing abstraction. And, again, if we add constant queries here, we can say that GraphQL makes life easier for developers of client systems.
GraphQL is a holistic system with remarkable features
GraphQL is not something that has completely unique capabilities. There are alternatives to this system. Typed scheme? The same thing is with OpenAPI! Server abstractions that support different client use cases? This can be implemented in many ways. Introspection? Using Hypermedia allows clients to discover actions and start working with the root entity. A Delicious GraphiQL Tool? I am sure something similar was created for OpenAPI. GraphQL's capabilities can always be recreated using other technologies. However, GraphQL is a holistic system. This is what attracts such a large audience of developers to GraphQL who are happy to use this system. I suspect that this is one of the reasons for the rapid spread and development of GraphQL. In addition, since the construction of the GraphQL-API is well documented, GraphQL libraries designed for various languages are usually of high quality and popularity.
Networking is still a limiting factor (and maybe it will always be that way?)
Here is another thought that I want to dwell on. There is a feeling that the network, when it comes to working with the API, will always play the role of a certain limiting factor. It doesn’t matter how fast the network requests are. That is why we do not design web APIs in the same way as regular objects used in different programming languages. Here , for example, we are talking about why interfaces with a high level of detail are not very suitable for creating systems designed for remote work with them.
While HTTP / 2 definitely encourages the execution of requests with high granularity, I think that there are some trade-offs to be made here.
Can HTTP / 2 help GraphQL?
So, GraphQL gives the developer a lot of important and useful tools, but HTTP / 2 is also a great technology. Let's look into the future and think about the benefits that GraphQL systems can benefit from using HTTP / 2. For example, it might look like this:
query { viewer { name posts(first: 100) @stream { title } } }
It turns out that we can well use the server-side abstraction of GraphQL, the declarative query language of this technology, and at the same time use the capabilities of HTTP / 2 streams. I think that web sockets are used here. I still need to figure this out, but I'm sure that many are already exploring GraphQL directives such as
@defer
,
@stream
and
@live
.
Summary
HTTP / 2 is a wonderful technology (and the examples given here are just some kind of miracle). GraphQL can only be perceived as a technology that reduces the number of client-server communication sessions, or helps to optimize the volume of transmitted data. If so, then anyone who sees GraphQL from a similar perspective will be quite happy using APIs based on HTTP / 2 capabilities. However, if you see in GraphQL a combination of technologies that give the developer a lot of useful things, it becomes clear that the power of GraphQL is not at all limited to improving the use of network resources and saving traffic.
Dear readers! If you use GraphQL technology, please tell us what you don't like about it the most.

