
Good afternoon, I want to share with you my experience in configuring and using the AWS EKS (Elastic Kubernetes Service) service for Windows containers, or rather about the impossibility of using it, and a bug found in the AWS system container, for those who are interested in this service for Windows containers, please under cat.
I know that windows containers are not a popular topic, and few people use them, but nevertheless decided to write this article, since there were a couple of articles on kubernetes and windows on Habré and there are still such people.
Start
It all started with the fact that the services in our company, it was decided to migrate to kubernetes, it is 70% windows and 30% linux. For this, AWS EKS cloud service was considered as one of the possible options. Until October 8, 2019 AWS EKS Windows was in Public Preview, I started with it, the kubernetes version was used there old 1.11, but I decided to check it anyway and see at what stage this cloud service is working, if it turned out to be working at all, there was a bug with the addition of removing hearths, while the old ones stopped responding via the internal ip from the same subnet as the windows worker node.
Therefore, it was decided to abandon the use of AWS EKS in favor of their own cluster on kubernetes on the same EC2, only all the balancing and HA would have to be described by myself through CloudFormation.
Amazon EKS Windows Container Support now Generally Available
by Martin Beeby | on 08 OCT 2019
I didn’t have time to add a template to CloudFormation for my own cluster, as I saw this news Amazon EKS Windows Container Support now Generally Available
Of course, I postponed all my developments, and began to study what they did for GA, and how everything changed from Public Preview. Yes AWS fellows have updated the images for windows worker node to version 1.14 as well as the cluster version 1.14 in EKS now with support for windows nodes. They closed the Public Preview project on the github and said now use the official documentation here: EKS Windows Support
Integrating an EKS Cluster into the Current VPC and Subnets
In all sources, in the link above the announcement and also in the documentation, it was proposed to deploy the cluster either through the proprietary utility eksctl or through CloudFormation + kubectl after, only using public subnets in Amazon, as well as creating a separate VPC for a new cluster.
This option is not suitable for many, firstly, a separate VPC is the additional cost of its cost + peering traffic to your current VPC. What to do for those who already have a ready-made infrastructure in AWS with their Multiple AWS accounts, VPC, subnets, route tables, transit gateway and so on? Of course, I don’t want to break it down or redo it all, and I need to integrate the new EKS cluster into the current network infrastructure using the existing VPC and, to split up the maximum, create new subnets for the cluster.
In my case, this path was chosen, I used the existing VPC, added only 2 public subnets and 2 private subnets for a new cluster, of course, all the rules were taken into account according to the documentation Create your Amazon EKS Cluster VPC .
There was also one condition for no worker node in public subnets using EIP.
eksctl vs CloudFormation
I will make a reservation right away that I tried both methods of the cluster deployment, in both cases the picture was the same.
I will show an example only with the use of eksctl since the code is shorter here. Using eksctl cluster deploy in 3 steps:
1.Create the cluster itself + Linux worker node on which the system containers and the ill-fated vpc-controller will later be placed.
eksctl create cluster \ --name yyy \ --region www \ --version 1.14 \ --vpc-private-subnets=subnet-xxxxx,subnet-xxxxx \ --vpc-public-subnets=subnet-xxxxx,subnet-xxxxx \ --asg-access \ --nodegroup-name linux-workers \ --node-type t3.small \ --node-volume-size 20 \ --ssh-public-key wwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami auto \ --node-private-networking
In order to deploy to an existing VPC, just specify the id of your subnets, and eksctl will determine the VPC itself.
In order for your worker node to deploy only to the private subnet, you need to specify --node-private-networking for the nodegroup.
2. Install vpc-controller in our cluster, which will then process our worker nodes by counting the number of free ip addresses, as well as the number of ENI on the instance, adding and removing them.
eksctl utils install-vpc-controllers --name yyy --approve
3.After your system containers successfully started on your linux worker node including vpc-controller, it remains only to create another nodegroup with windows workers.
eksctl create nodegroup \ --region www \ --cluster yyy \ --version 1.14 \ --name windows-workers \ --node-type t3.small \ --ssh-public-key wwwwwwwwww \ --nodes 1 \ --nodes-min 1 \ --nodes-max 2 \ --node-ami-family WindowsServer2019CoreContainer \ --node-ami ami-0573336fc96252d05 \ --node-private-networking
After your node has successfully hooked to your cluster and everything seems to be fine, it is in Ready status, but no.
Error in vpc-controller
If we try to run pods on the windows worker node, we get an error:
NetworkPlugin cni failed to teardown pod "windows-server-iis-7dcfc7c79b-4z4v7_default" network: failed to parse Kubernetes args: pod does not have label vpc.amazonaws.com/PrivateIPv4Address]
Looking deeper, we see that our AWS instance looks like this:

And it should be like this:

From this it is clear that vpc-controller did not work out its part for some reason and could not add new ip-addresses to the instance so that pods could use them.
We climb to watch the vpc-controller pod logs and this is what we see:
kubectl log <vpc-controller-deployment> -n kube-system
I1011 06:32:03.910140 1 watcher.go:178] Node watcher processing node ip-10-xxx.ap-xxx.compute.internal. I1011 06:32:03.910162 1 manager.go:109] Node manager adding node ip-10-xxx.ap-xxx.compute.internal with instanceID i-088xxxxx. I1011 06:32:03.915238 1 watcher.go:238] Node watcher processing update on node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.200423 1 manager.go:126] Node manager failed to get resource vpc.amazonaws.com/CIDRBlock pool on node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxxx E1011 06:32:08.201211 1 watcher.go:183] Node watcher failed to add node ip-10-xxx.ap-xxx.compute.internal: failed to find the route table for subnet subnet-0xxx I1011 06:32:08.201229 1 watcher.go:259] Node watcher adding key ip-10-xxx.ap-xxx.compute.internal (0): failed to find the route table for subnet subnet-0xxxx I1011 06:32:08.201302 1 manager.go:173] Node manager updating node ip-10-xxx.ap-xxx.compute.internal. E1011 06:32:08.201313 1 watcher.go:242] Node watcher failed to update node ip-10-xxx.ap-xxx.compute.internal: node manager: failed to find node ip-10-xxx.ap-xxx.compute.internal.
Google searches did not lead to anything, since apparently no one had caught such a bug yet, well, or posted an issue on it, I had to think first of all the options myself. The first thing that came to mind is that maybe vpc-controller cannot sober up ip-10-xxx.ap-xxx.compute.internal and get through to it and so the errors go around.
Yes, indeed, we use custom dns servers in VPC and we don’t use Amazon servers, so even forwarding was not configured on this domain ap-xxx.compute.internal. I checked this option, and it did not bring any results, maybe the test was not clean, and therefore, when communicating with technical support, I succumbed to their idea.
Since there weren’t any ideas, all security groups were created by eksctl itself, so there was no doubt that they were working, the route tables were also correct, nat, dns, there was also Internet access with worker nodes.
At the same time, if you deploy a worker node to a public subnet without using --node-private-networking, this node was immediately updated by vpc-controller and everything worked like a clock.
There were two options:
- Hammer in and wait for someone to describe this bug in AWS and they will fix it and then you can safely use AWS EKS Windows, because they just got into GA (it took 8 days at the time of writing), most likely many will go the same way as me .
- Write to AWS Support and explain to them the essence of the problem with the whole bunch of logs from everywhere and prove to them that their service does not work when using your VPC and subnets, it was not in vain that we had Business support, we must use it at least once :-)
Communication with AWS Engineers
Having created a ticket on the portal, I mistakenly chose to reply to me via Web - email or support center, through this option they can answer you after a few days at all, despite the fact that my ticket had Severity - System impaired, which implied a response within <12 hours, and since the Business support plan has 24/7 support, I was hoping for the best, but it turned out as always.
My ticket landed in Unassigned from Friday to Mon, then I decided to write it again and chose the Chat answer option. After a short wait, Harshad Madhav was appointed to me, and then it began ...
We debated with him online for 3 hours in a row, transferring logs, deploying the same cluster to the AWS laboratory to emulate the problem, re-creating the cluster on my part, and so on, the only thing we came to was that the logs showed that the resolution was not working AWS internal domain names, as I wrote above, and Harshad Madhav asked me to create forwarding, supposedly we use custom DNS and this can be a problem.
Forwarding
ap-xxx.compute.internal -> 10.xx2 (VPC CIDRBlock) amazonaws.com -> 10.xx2 (VPC CIDRBlock)
What was done, the day was over. Harshad Madhav unsubscribed that check and it should work, but no, the resolution did not help.
Then there was a conversation with 2 more engineers, one just fell off the chat, apparently scared of a complicated case, the second spent my day again on a full debug cycle, sending logs, creating clusters on both sides, in the end he just said well, it works for me, here I am official documentation I do everything step by step do it and you and you will succeed.
To which I politely asked him to leave, and assign another to my ticket if you do not know where to look for the problem.
The final
On the third day, a new engineer Arun B. was appointed to me, and from the very beginning of communication with him it was immediately clear that these were not 3 previous engineers. He read the whole history and immediately asked to collect the logs with his own script on ps1 which lay on his github. Then all the iterations of creating clusters, outputting the results of teams, collecting logs followed again, but Arun B. was moving in the right direction judging by the questions asked to me.
When we got to including -stderrthreshold = debug in their vpc-controller, and what happened next? it certainly does not work) pod just does not start with this option, only -stderrthreshold = info works.
This is where we ended and Arun B. said that he would try to reproduce my steps to get the same error. The next day I get a response from Arun B. He did not drop this case, but took on the review code of their vpc-controller and found the same place where it does and why it does not work:
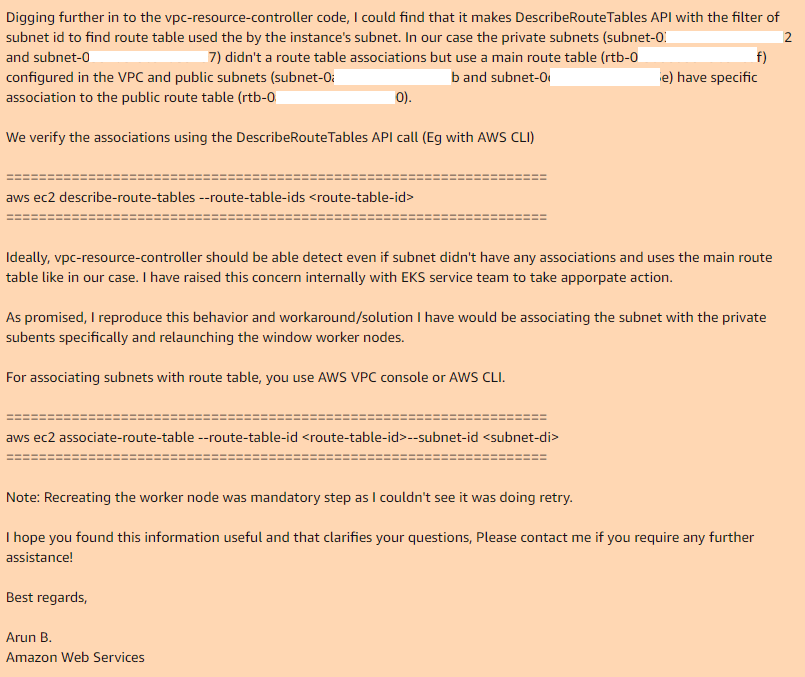
Thus, if you use the main route table in your VPC, then by default it does not have associations with the necessary subnets, so the necessary vpc-controller, in the case of the public subnet, it has a custom route table that has an association.
By manually adding associations for the main route table with the desired subnets, and re-creating nodegroup, everything works perfectly.
I hope that Arun B. will indeed report this bug to the EKS developers and we will see a new version of vpc-controller where everything will work out of the box. Currently the latest version: 602401143452.dkr.ecr.ap-southeast-1.amazonaws.com/eks/vpc-resource-controllerPoint.2.1
has this problem.
Thanks to everyone who read to the end, test everything that you are going to use in production, before implementation.