As part of exploring the topic of C # 8, we suggest discussing the following article on the new rules for implementing interfaces.

Looking closely at how interfaces are structured in C # 8 , you need to consider that when implementing interfaces by default, you can break firewood.
Assumptions related to the default implementation can lead to corrupted code, runtime exceptions, and poor performance.
One of the actively advertised features of C # 8 interfaces is that you can add members to an interface without breaking existing implementers. But inattention in this case is fraught with big problems. Consider the code in which the wrong assumptions are made - this will make it clearer how important it is to avoid such problems.
All the code for this article is posted on GitHub: jeremybytes / interfaces-in-csharp-8 , specifically in the DangerousAssumptions project .
Note: This article discusses the features of C # 8, currently implemented only in .NET Core 3.0. In the examples I used, Visual Studio 16.3.0 and .NET Core 3.0.100 .
Assumptions about implementation details
The main reason why I articulate this problem is as follows: I found an article on the Internet where the author offers code with very poor assumptions about implementation (I will not indicate the article because I do not want the author to be rolled up with comments; I will contact him personally) .
The article talks about how good the default implementation is, because it allows us to supplement the interfaces even after the code already has implementers. However, a number of bad assumptions are made in this code (the code is in the BadInterface of folder in my GitHub project)
Here is the original interface:
The rest of the article demonstrates the implementation of the MyFile interface (for me, in the MyFile.cs file):
The article then shows how you can add the
Rename
method with the default implementation, and it will not break the existing
MyFile
class.
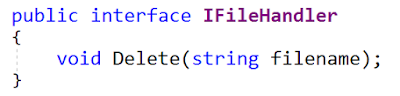
Here is the updated interface (from IFileHandler.cs file):

MyFile still works, so everything is fine. So? Not really.
Bad assumptions
The main problem with the Rename method is what a HUGE assumption is associated with it: implementations use a physical file located in the file system.
Consider the implementation that I created for use in a file system located in RAM. (Attention: this is my code. It is not from an article that I criticize. You will find the full implementation in the file MemoryStringFileHandler.cs .)

This class implements a formal file system using a dictionary located in RAM, which contains text files. There is nothing here that would affect the physical file system; there are generally no references to
System.IO
.
Faulty implementer
After updating the interface, this class is damaged.
If the client code calls the Rename method, it will generate a runtime error (or, worse, rename the file stored in the file system).
Even if our implementation will work with physical files, it can access files located in the cloud storage, and such files are not accessible through System.IO.File.
There is also a potential problem when it comes to unit testing. If the simulated or fake object is not updated, and the tested code is updated, then it will try to access the file system when performing unit tests.
Since the wrong assumption is about an interface, the implementers of that interface are corrupted.Unreasonable fears?
It is worthless to consider such fears unfounded. When I talk about abuses in the code, they answer me: "Well, it's just that a person does not know how to program." I can not disagree with this.
Usually I do this: I wait and look at how that will work. For example, I was afraid that the possibility of "static using" would be abused. So far, this has not had to be convinced.
It must be borne in mind that such ideas are in the air, so it is in our power to help others take a more convenient path, which will not be so painful to follow.
Performance issues
I began to think about what other problems could await us if we made incorrect assumptions about interface implementers.
In the previous example, code is called that is outside the interface itself (in this case, outside the System.IO). You will probably agree that such actions are a dangerous bell. But, if we use the things that are already part of the interface, everything should be fine, right?
Not always.
As an express example, I created the IReader interface.
The source interface and its implementation
Here is the original IReader interface (from the IReader.cs file - although now there are already updates in this file):

This is a generic interface with a method that allows you to get a collection of read-only items.
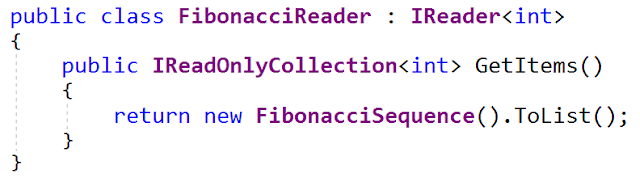
One of the implementations of this interface generates a sequence of Fibonacci numbers (yes, I have an unhealthy interest in generating Fibonacci sequences). Here is the
FibonacciReader
interface (from the FibonacciReader.cs file - it is also updated on my github):
The
FibonacciSequence
class is an implementation of
IEnumerable <int>
(from the FibonacciSequence.cs file). It uses a 32-bit integer as the data type, so overflow occurs quite quickly.

If you are interested in this implementation, take a look at my TDDing into a Fibonacci Sequence in C # article.
The DangerousAssumptions project is a console application that displays the results of FibonacciReader (from the Program.cs file):

And here is the conclusion:

Updated interface
So now we have the working code. But, sooner or later, we may need to get a separate element from IReader, and not the entire collection at once. Since we use a generic type with the interface, and yet we do not have the “natural ID” property in the object, we will draw an element located at a specific index.
Here is our interface to which the
GetItemAt
method is
GetItemAt
(from the final version of the IReader.cs file):

GetItemAt
here assumes a default implementation. At first glance - not so bad. It uses an existing interface member (
GetItems
), therefore, no "external" assumptions are made here. With the results, he uses the LINQ method. I am a big fan of LINQ, and this code, in my opinion, is built reasonably.
Performance differences
Since the default implementation calls
GetItems
, it requires the entire collection to be returned before a specific item is selected.
In the case of
FibonacciReader
this implies that all values will be generated. In an updated form, the Program.cs file will contain the following code:

So we call
GetItemAt
. Here is the conclusion:

If we put a checkpoint inside the FibonacciSequence.cs file, we will see that the entire sequence is generated for this.
Having launched the program, we will stumble upon this control point twice: first when calling
GetItems
, and then when calling
GetItemAt
.
Assumption harmful to performance
The most serious problem with this method is that it requires retrieving the entire collection of elements. If this
IReader
is going to take it from the database, then a lot of elements will have to be pulled out of it, and then only one of them will be selected. It would be much better if such a final selection were handled in a database.
Working with our
FibonacciReader
, we calculate each new element. Thus, the entire list must be computed entirely to get just one element that we need. Fibonacci sequence calculation is an operation that does not load the processor too much, but what if we deal with something more complicated, for example, we will calculate prime numbers?
You might say: “Well, we have a
GetItems
method that returns everything. If he works too long, then probably he should not be here. And this is an honest statement.
However, the calling code knows nothing about this. If I call
GetItems
, then I know that (probably) my information will have to go through the network, and this process will be date-intensive. If I ask for a single item, then why should I expect such costs?
Specific Performance Optimization
In the case of
FibonacciReader
we can add our own implementation to significantly improve performance (in the final version of the FibonacciReader.cs file):

The
GetItemAt
method overrides the default implementation provided in the interface.
Here I use the same LINQ
ElementAt
method as in the default implementation. However, I do not use this method with the read-only collection that GetItems returns, but with FibonacciSequence, which is
IEnumerable
.
Since
FibonacciSequence
is
IEnumerable
, the call to
ElementAt
end as soon as the program reaches the element we have selected. So, we will not generate the entire collection, but only the elements located up to the specified position in the index.
To try this, leave the control point that we made above in the application and run the application again. This time we stumble upon a breakpoint just once (when calling
GetItems
). When calling
GetItemAt
this will not happen.
A slightly contrived example
This example is a little far-fetched, because, as a rule, you don’t have to select elements from the set of data by index. However, you can imagine something similar that could happen if we worked with the natural ID property.
If we were pulling elements by ID, not by index, we could have faced the same performance problems with the default implementation. The default implementation requires the return of all elements, after which only one is selected from them. If you let the database or other “reader” pull out a specific element by its ID, such an operation would be much more efficient.
Think about your assumptions
Assumptions are indispensable. If we tried to take into account any possible use cases of our libraries in the code, then no task would ever be completed. But you still need to carefully consider the assumptions in the code.
This does not mean that the
GetElementAt
implementation is necessarily bad. Yes, there are potential performance issues with it. However, if the data sets are small, or the computed elements are “cheap,” then the default implementation may be a reasonable compromise.
I, nevertheless, do not welcome changes in the interface after it already has implementers. But I understand that there are also such scenarios in which alternative options are preferred. Programming is the solution of problems, and when solving problems it is necessary to weigh the pros and cons inherent in each tool and approaches that we use.
The default implementation can potentially harm interface implementers (and possibly the code that will invoke these implementations). Therefore, you need to be especially careful about assumptions related to default implementations.
Good luck in your work!