Check the quality without leaving the cash register

The more affordable the means of production, the more acute the problem of fakes. And if the product is massive and easily fake, then the wave of counterfeit is almost guaranteed. To combat this scourge, we, the Center for the Development of Advanced Technologies, are developing a system for marking and tracking products. She got the name Honest SIGN . The manufacturer applies a unique DataMatrix code to each unit of its products, and customers can see by this code whether the product is in front of it, who produced it and how it got on the counter.
With this introductory post on our blog, we want to introduce you to the system and the principles of its operation, and in the following articles we will describe in more detail the technical structure and development features.
Who we are and what we do
We are the company CRPT , Center for the Development of Advanced Technologies. One of the directions of our activity is the development, implementation and development of a digital system for marking and tracing of any goods. It is needed so that every buyer can be sure right in the store whether there is a fake in front of him.
Today, Russian manufacturers of cigarettes, shoes, and medicines are connected to our database. So far, the most active users are representatives of the tobacco industry - compulsory labeling of all manufactured and imported products in the country has already begun in this group. Already, up to 50 million packs a day pass through the system. Light industry, manufacturers of milk, tires, cameras and other industries that are working out the technology in pilot mode as well are actively joining.
How the marking system works
The Russian government decides on the need for a pilot labeling project in a certain group of goods. Usually this decision appears on the initiative of business representatives. We are launching a pilot project, within which manufacturers choose a labeling format that is convenient for them and additional information for each unit of goods that will be placed in the database and encrypted in unique labeling codes - DataMatrix. This additional information can be very different - for example, the recommended retail price or expiration date. Then the manufacturers introduce software that allows them to put DataMatrix on the packaging, and we, as the system operator, give them free equipment - emission registrars, which are needed to transmit digital codes via secure communication channels.
While the pilot project is ongoing, we help participants debug marking and information exchange processes. And when everything is ready, the participation of other manufacturers from this industry in our system becomes mandatory.
As the goods move from the manufacturer to the shelves, all participants in the chain send various information to the Honest SIGN:
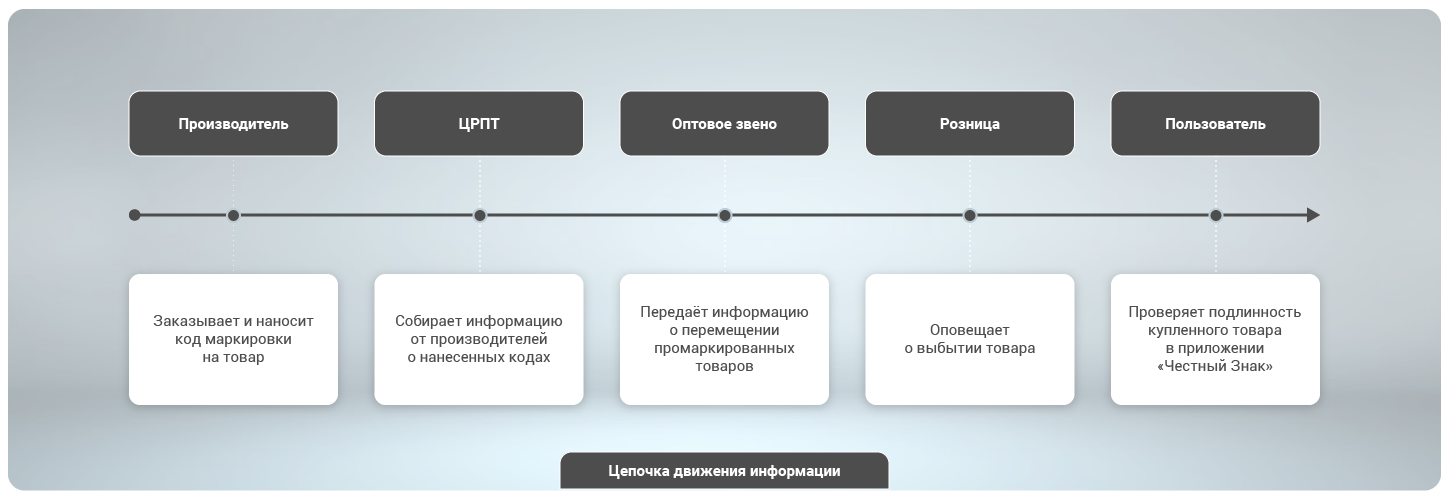
As a result, we collect all the information about the origin and movement of each product produced by the participants in the system and provide it to manufacturers, retailers and customers. When you come to the store, in front of the counter you can go to the Honest SIGN mobile app ( AppStore , Google Play ), scan the code on the package and immediately find out the country, city and address of production. That is, you will immediately know whether the fake is in front of you or not.
Surely you ask: “What prevents you from falsifying your codes?” The fact is that each marking code is signed with a small secure part, a cryptocode. And the fake code simply will not pass the check in the system, neither during application, nor during scanning by the buyer, nor at the checkout.
Where do the codes come from? There are two ways to get them:
- Or we ourselves entirely generate unique non-reproducible codes and provide them to manufacturers.
- Or, the manufacturer releases the serial part of the code on its own, so that it is more convenient to use marking with its accounting systems, and adds the cryptographic part that we generated.
How our system works
The basic scheme of work looks like this:

It includes five blocks.
The “entrance gate” to the system is routing - a kind of gateway. All the information from each participant in the trade chain comes here: manufacturers, wholesalers and retailers. Routing enriches the incoming data with additional attributes and decides which pipeline should process this or that information.
Processing is engaged in processing all incoming information, filtered and enriched with routing. Each industry is distinguished by its sets of business processes, which we constantly automate. For example, for tobacco it is excise taxes, for milk it is an expiration date.
The storage system is built on top of a distributed key-value base. There we put all the information about each labeling field, about each document that influenced the change in the status of this code. Each large product group has its own base, because the amount of information that needs to be backed up and scaled up is very large.
We use the data warehouse in different ways: we make selections, form a graphical display of information in your personal account, and give it to the participants of the system using an external API.
System components perform a number of tasks: authentication, authorization, interservice interaction. In other words, everything related to checking access rights and the interaction of system components with each other.
Finally, the personal account is a graphical interface for the system participants: manufacturers, wholesalers and retail organizations. That is, for companies engaged in sales, retirement and sale to the final consumer. In your personal account, reports and graphs are generated in a convenient form on how many codes the company sent, for what period, for which product categories, how many goods have already been sold in retail, and so on.
How does information flow through the system?
The manufacturer generates a batch of codes and sends us or creates an order to receive codes. In response, we send either the results of checking codes for patterns, or a list of ready-made codes. After that, the manufacturer puts these codes and reports that they were used or lost in the production process, that is, the goods with the code are rejected. This information is transferred from routing to processing, which directly interacts with the data warehouse. Also, personal accounts work with him, in which business logic for system participants is protected.
In other words, we receive data from participants:
- what codes are applied to the goods,
- What additional product information needs to be shown to end users.
Further, we aggregate this data, ensuring the uniqueness and security of the codes from counterfeiting, and in a convenient form we provide all users through mobile applications. And business representatives at any time can receive reports on all the information on their products available in our system.
Technologies
Since we are creating a national labeling system, it will daily “digest” information on all goods produced in the country and give it to tens of millions of users. Therefore, we chose technologies that not only provide high performance, but also allow us to quickly scale the system.
Today, we process up to 300 units of goods sold per second, and with approximately the same frequency — records of goods that go through the “released”, “code”, “transferred from one participant to another” stages. For one tobacco product alone, about a billion records are entered into the system every month, and the total amount of information reaches tens of Tb.
All services within the system - and there are about 250 of them - are deployed on a Kubernetes cluster, so we quietly increase the capacity and storage volume as necessary.
For the most part, the system is written in Java 11, and the processing is in Scala. For interserver communication, we chose Kafka. Labeling codes themselves are stored in Hbase, and related information is stored in PostgreSQL. We pack the system code into Docker containers, deliver Helm to Kubernetes clusters, monitor with Prometheus and monitor health in Grafana.
We have connected to the data warehouses the analytical servers developed by us, which build reports for the participants of the system. So far, the servers are built on the basis of Hbase, but we are very actively experimenting with ClickHouse.
System development
Many participants expect feedback from us - do we get all the information sent, are there any problems processing the document, does the participant in the system have the codes that he transmits? Such a feedback mechanism should be end-to-end, without using storage, so as not to duplicate information and not additionally load the system. Therefore, we will move away from intermediate repositories and are already working on the implementation of end-to-end transactions through routing, processing and vice versa.
In the following publications, we will describe in detail how each of the five architectural blocks is implemented, about our system, technologies and the people who create it.
The material was prepared with the support of Dmitry Poluyanov, head of the development team (Java) of the MDCT.
All Articles