The sad fate of printf function format specifiers for Unicode characters in Visual C ++
Unicode support on Windows appeared earlier than on most other operating systems. Because of this, many problems associated with the representation of characters in Windows were not solved in the same way as in other systems, the developers of which postponed the introduction of the new standard until better times [1]. The most telling example: on Windows, UCS-2 encoding is used to represent Unicode characters. It was recommended by the Unicode Consortium because version 1.0 only supported 65,536 characters [2]. Five years later, the Consortium changed its mind, but by then it was too late to change something in Windows, since Win32s, Windows NT 3.1, Windows NT 3.5, Windows NT 3.51 and Windows 95 had already been released to the market - they all used UCS encoding -2 [3].
But today we’ll talk about the format strings of the printf function.
Since Unicode was adopted on Windows earlier than in C, this meant that Microsoft developers had to figure out how to implement support for this standard in the C runtime. As a result, features like wcscmp , wcschr, and wprintf appeared . As for formatting strings in printf , the following qualifiers were introduced for them:
The idea was to write code like this:
And when compiling in ANSI mode, get this result:
And when compiling in Unicode mode - like this [4]:
Since the % s specifier accepts a string of the same width as the format string, this code will work correctly in both ANSI and Unicode formats. Also, this solution greatly simplifies the conversion of already written code from the ANSI format to the Unicode format, since a string of the required width is substituted for the % s specifier.
When Unicode support was officially added to C99, the C language standardization committee adopted a different format string model for the printf function:
That's where the problems started. Over the past six years by that time, a huge number of programs with a volume of billions of lines were written for Windows, and they used the old format. What about Visual C and C ++ compilers?
It was decided to stay on the old, non-standard model, so as not to break all the existing Windows programs in the world.
If you want your code to work in both runtime environments that adhere to the classical rules for printf and those that follow the rules of the C standard, you will have to restrict yourself to the % hs specifiers for regular strings and % ls for wide strings. In this case, the constancy of the results is guaranteed, regardless of whether the format string is passed to the sprintf or wsprintf function .
A separate TSTRINGWIDTH definition allows you to write, for example, this code:
Since people like the tabular presentation of information, here's a table for you.
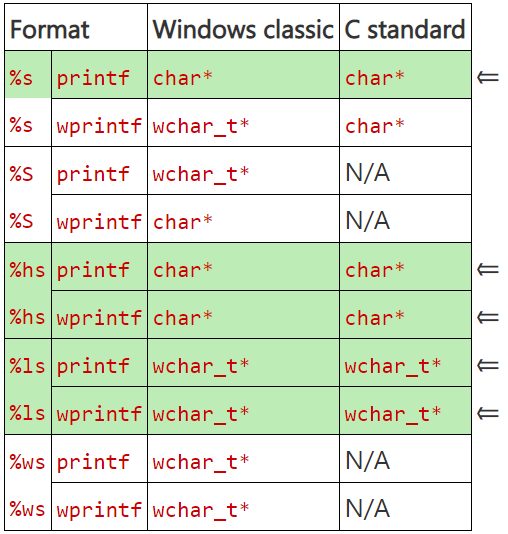
I highlighted the lines with qualifiers, which are defined in C in the same way as in the classical format adopted in Windows [5]. Use these qualifiers if you want your code to produce the same results in both formats.
Notes
[1] It would seem that the introduction of Unicode in Windows before other systems should have given Microsoft an advantage of the first move, but - at least in the case of Unicode - it turned into a “curse of the pioneer” for them, because the rest decided to just wait until better times, when there will be more promising solutions (such as UTF-8 encoding), and only after that introduce Unicode in their systems.
[2] Apparently, they believed that 65,536 characters should have been enough for everyone .
[3] It was later replaced by UTF-16. Fortunately, UTF-16 is backward compatible with UCS-2 for those code characters that can be represented in both encodings.
[4] Formally, the Unicode version should look like this:
The fact is that wchar_t was not yet an independent type, and until it was added to the standard, it was just a synonym for unsigned short . The twists and turns of fate wchar_t can be found in a separate article .
[5] The classic format developed by Windows was the first to appear, so it was more likely that the C standard had to adapt to it, and not vice versa.
Translator's Note
I am grateful to the author for this publication. Now it became clear how all this confusion with "% s" came about. The fact is that our users constantly asked the question why PVS-Studio reacts differently to their “portable” code, they depending on whether they collect their project under Linux or Windows. It was necessary to create a special separate section in the description of the V576 diagnostics devoted to this topic (see "Wide lines"). After this article, everything becomes even more clear and obvious. I think this note should be read to everyone who develops cross-platform applications. Read and tell colleagues.
But today we’ll talk about the format strings of the printf function.
Since Unicode was adopted on Windows earlier than in C, this meant that Microsoft developers had to figure out how to implement support for this standard in the C runtime. As a result, features like wcscmp , wcschr, and wprintf appeared . As for formatting strings in printf , the following qualifiers were introduced for them:
- % s represents a string of the same width as the format string;
- % S represents a string with the width inverse to the width of the format string;
- % hs represents a regular string regardless of the width of the format string;
- % ws and % ls represent a wide string regardless of the width of the format string.
The idea was to write code like this:
TCHAR buffer[256]; GetSomeString(buffer, 256); _tprintf(TEXT("The string is %s.\n"), buffer);
And when compiling in ANSI mode, get this result:
char buffer[256]; GetSomeStringA(buffer, 256); printf("The string is %s.\n", buffer);
And when compiling in Unicode mode - like this [4]:
wchar_t buffer[256]; GetSomeStringW(buffer, 256); wprintf(L"The string is %s.\n", buffer);
Since the % s specifier accepts a string of the same width as the format string, this code will work correctly in both ANSI and Unicode formats. Also, this solution greatly simplifies the conversion of already written code from the ANSI format to the Unicode format, since a string of the required width is substituted for the % s specifier.
When Unicode support was officially added to C99, the C language standardization committee adopted a different format string model for the printf function:
- % s and % hs represent a regular string;
- % ls represents a wide string.
That's where the problems started. Over the past six years by that time, a huge number of programs with a volume of billions of lines were written for Windows, and they used the old format. What about Visual C and C ++ compilers?
It was decided to stay on the old, non-standard model, so as not to break all the existing Windows programs in the world.
If you want your code to work in both runtime environments that adhere to the classical rules for printf and those that follow the rules of the C standard, you will have to restrict yourself to the % hs specifiers for regular strings and % ls for wide strings. In this case, the constancy of the results is guaranteed, regardless of whether the format string is passed to the sprintf or wsprintf function .
#ifdef UNICODE #define TSTRINGWIDTH TEXT("l") #else #define TSTRINGWIDTH TEXT("h") #endif TCHAR buffer[256]; GetSomeString(buffer, 256); _tprintf(TEXT("The string is %") TSTRINGWIDTH TEXT("s\n"), buffer); char buffer[256]; GetSomeStringA(buffer, 256); printf("The string is %hs\n", buffer); wchar_t buffer[256]; GetSomeStringW(buffer, 256); wprintf("The string is %ls\n", buffer);
A separate TSTRINGWIDTH definition allows you to write, for example, this code:
_tprintf(TEXT("The string is %10") TSTRINGWIDTH TEXT("s\n"), buffer);
Since people like the tabular presentation of information, here's a table for you.
I highlighted the lines with qualifiers, which are defined in C in the same way as in the classical format adopted in Windows [5]. Use these qualifiers if you want your code to produce the same results in both formats.
Notes
[1] It would seem that the introduction of Unicode in Windows before other systems should have given Microsoft an advantage of the first move, but - at least in the case of Unicode - it turned into a “curse of the pioneer” for them, because the rest decided to just wait until better times, when there will be more promising solutions (such as UTF-8 encoding), and only after that introduce Unicode in their systems.
[2] Apparently, they believed that 65,536 characters should have been enough for everyone .
[3] It was later replaced by UTF-16. Fortunately, UTF-16 is backward compatible with UCS-2 for those code characters that can be represented in both encodings.
[4] Formally, the Unicode version should look like this:
unsigned short buffer[256]; GetSomeStringW(buffer, 256); wprintf(L"The string is %s.\n", buffer);
The fact is that wchar_t was not yet an independent type, and until it was added to the standard, it was just a synonym for unsigned short . The twists and turns of fate wchar_t can be found in a separate article .
[5] The classic format developed by Windows was the first to appear, so it was more likely that the C standard had to adapt to it, and not vice versa.
Translator's Note
I am grateful to the author for this publication. Now it became clear how all this confusion with "% s" came about. The fact is that our users constantly asked the question why PVS-Studio reacts differently to their “portable” code, they depending on whether they collect their project under Linux or Windows. It was necessary to create a special separate section in the description of the V576 diagnostics devoted to this topic (see "Wide lines"). After this article, everything becomes even more clear and obvious. I think this note should be read to everyone who develops cross-platform applications. Read and tell colleagues.
All Articles