How to bypass captcha using sound recognition
On the Internet, captchas still remain relevant, which as an option offer to listen to the text from the image by clicking on the corresponding button. If someone is familiar with the picture below and / or is interested in how to get around it using an offline sound recognition system, it is suggested to read it.
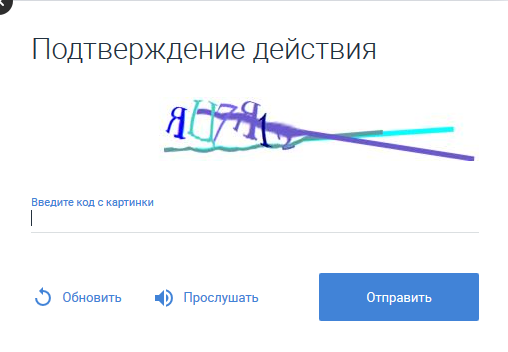
We will not torment the intrigues of specialists in the field of speech recognition, immediately stating that no proprietary voice recognition system for the stated purposes has been developed. The article uses the good old Pocketsphinx, but with a certain degree of customization.
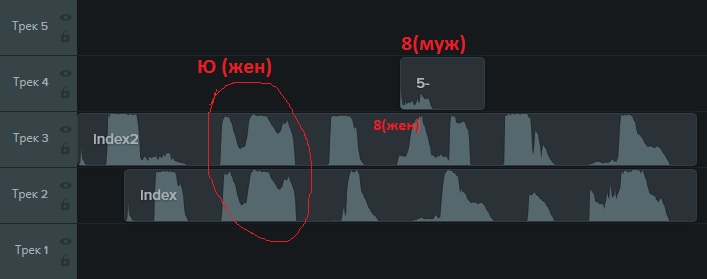
They sound both letters (and Russian), and numbers.
At first glance, everything is sad. But there is a positive point in that the sounds for the same letters coincide.
So far, this knowledge does not help much. How to push all this into the package of the Sphinx?
* There is an article on Habré where sound is fed to google translator online through sound output redirection. And this could end this post if all this worked for this case.
Installing Pocketsphinx itself on windows (and on linux as well) is not very complicated - download , install.
Since by default pocketsphinx comes with an English language, acoustic models, dictionary, you will need all the same for the Russian language.
Download the Russian version - link .
After unpacking the Russian model in the file structure, you can try the test .wav file decoder-text.wav with the following python code:
The contents of the audio file should be displayed on the line: "Ilya Ilf Evgeny Petrov Golden Calf."
If it doesn’t display (as in my situation), then you need to convert decoder-test.wav to another audio format.
You will need ffmpeg for this.
After downloading the ffmpeg utility, put decoder-test.wav in C: \ python3 \ ffmpeg \ bin.
Next, convert the command line:
Next, fix the link to the original audio file in python code:
Now, after working out the code:

True, you have to wait until the second coming, the code works very slowly - about 20 seconds.
We convert audio captcha by the same principle from mp3 to wav and feed audio from captcha. Take a look at the code:

Some kind of ignorance, but there is a result. It would have been much worse if nothing had been brought out. As with a female voice:

Let's see how to improve the result and at the same time accelerate it.
You will need your own dictionary. In this case, it will consist of all the letters of the Russian alphabet (except for b, s, b) and numbers.
All characters must be placed in a plain text file, one on each line in UTF-8 encoding.
Now you need to convert the dictionary.
You will need to install perl (it is needed for the converter to work).
Next, download the project for converting ru4sphinx .
And convert the previously created dictionary:
The output is a dictionary for work:

The dictionary extension must be renamed from .txt to .dic format, and the file itself should be put in an accessible place.
In python code, we’ll indicate the location of the dictionary by commenting out the old dictionary:
Run through the program and see the result:

Better, but just as slowly, and not all letters are correctly identified.
This will significantly increase the speed of work and a little accuracy of the result.
Let's go a short way from the instructions .
Follow the link and upload our dictionary, previously created in .txt format (not .dic!) To the website:
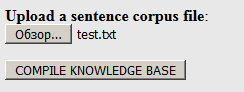
Click "Compile ...". At the output, you can download the resulting package in the .tgz archive (it contains all the necessary files):
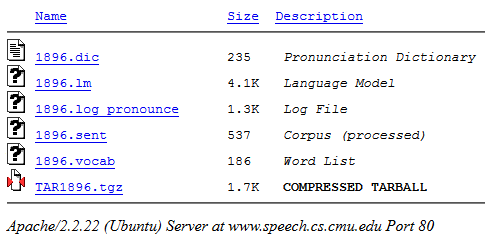
Next, we take a file with the extension .lm (our model) from the archive.
Let's fix the python recognition script by replacing the model with a newly made one:
We try:

It works much faster - less than a second, in addition, all letters are defined.
But here a small remark is needed.
Not all characters are recognized correctly, and if instead of the correct letter a different character is displayed, you can manually correct the previously created .dic dictionary by matching the correspondence of the letter.
For example, instead of the letter a, displays e. It is necessary to take a line from the dictionary e:
and transfer (deleting the old) it, changing the letter:
But since the letter “a” is already in the dictionary, then you need to add “(2)” (or 3.4) to the letter, in general, a serial number, depending on how many sounds are already in the dictionary:
Re-convert the dictionary is not necessary. In such a simple way you can "pick up" phonemes of all letters, almost.
Model and vocabulary work, but not with a female voice. If the voice of the captcha is female, then we get nothing at the output. This is both good and bad at the same time. First about the good.
If you didn’t recognize anything when starting the program, it means we are dealing with a female voice, so you can filter “female” captchas.
But what to do with them?
Here you need to work with conversion.
For example, with a “male” captcha, the frequency was 16000, and for a female “captcha” 24000:

All sounds are defined (in each line by sound), but their correspondence is lame.
It is better to create a separate dictionary for the female model and then edit it.
However, this is for self-study.
Useful links:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom
2.https: //itnan.ru/post.php? C = 1 & p = 351376
3. ru.wikipedia.org/wiki/Cherchez_la_femme
Files:
1. The program .
2. The model .
3. The Russian model .
4. Dictionary .
5. Test captcha .
6. ffmpeg .
7. A pack of captcha .
We will not torment the intrigues of specialists in the field of speech recognition, immediately stating that no proprietary voice recognition system for the stated purposes has been developed. The article uses the good old Pocketsphinx, but with a certain degree of customization.
Training
“You run into the office of competitors who have voice control on computers, shout“ Sudo EREM minus EREF home ”and run away.” From comments.So, the captcha offers to listen to itself by clicking on the appropriate button. If you save the resulting sound file, you can find out what it is like a short piece of audio in .mp3. At the same time, as it turned out, captchas are offered with voice acting in a female or male voice. The "drawing" of the same sounds made by a man and a woman is different:
They sound both letters (and Russian), and numbers.
At first glance, everything is sad. But there is a positive point in that the sounds for the same letters coincide.
So far, this knowledge does not help much. How to push all this into the package of the Sphinx?
Installing Pocketsphinx, a Russian sound model
* There is an article on Habré where sound is fed to google translator online through sound output redirection. And this could end this post if all this worked for this case.
Installing Pocketsphinx itself on windows (and on linux as well) is not very complicated - download , install.
Since by default pocketsphinx comes with an English language, acoustic models, dictionary, you will need all the same for the Russian language.
Download the Russian version - link .
After unpacking the Russian model in the file structure, you can try the test .wav file decoder-text.wav with the following python code:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path #from pocketsphinx import Pocketsphinx model_path = get_model_path() data_path = get_data_path() config = { 'verbose': False, 'audio_file': os.path.join(data_path, 'C://python3//decoder-test.wav'), 'buffer_size': 2048, 'no_search': False, 'full_utt': False, 'hmm': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//zero_ru.cd_cont_4000'), 'lm': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.lm'), 'dict': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.dic') } audio = AudioFile(**config) for phrase in audio: print(phrase)
The contents of the audio file should be displayed on the line: "Ilya Ilf Evgeny Petrov Golden Calf."
If it doesn’t display (as in my situation), then you need to convert decoder-test.wav to another audio format.
You will need ffmpeg for this.
Ffmpeg
After downloading the ffmpeg utility, put decoder-test.wav in C: \ python3 \ ffmpeg \ bin.
Next, convert the command line:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
Next, fix the link to the original audio file in python code:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
Now, after working out the code:
True, you have to wait until the second coming, the code works very slowly - about 20 seconds.
We convert audio captcha by the same principle from mp3 to wav and feed audio from captcha. Take a look at the code:
Some kind of ignorance, but there is a result. It would have been much worse if nothing had been brought out. As with a female voice:
Let's see how to improve the result and at the same time accelerate it.
Dictionary
You will need your own dictionary. In this case, it will consist of all the letters of the Russian alphabet (except for b, s, b) and numbers.
All characters must be placed in a plain text file, one on each line in UTF-8 encoding.
Now you need to convert the dictionary.
You will need to install perl (it is needed for the converter to work).
Next, download the project for converting ru4sphinx .
And convert the previously created dictionary:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
The output is a dictionary for work:
The dictionary extension must be renamed from .txt to .dic format, and the file itself should be put in an accessible place.
In python code, we’ll indicate the location of the dictionary by commenting out the old dictionary:
#'dict': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.dic') 'dict': os.path.join(model_path, 'C://python3//my_dict.dic')
Run through the program and see the result:
Better, but just as slowly, and not all letters are correctly identified.
Create your own model
This will significantly increase the speed of work and a little accuracy of the result.
Let's go a short way from the instructions .
Follow the link and upload our dictionary, previously created in .txt format (not .dic!) To the website:
Click "Compile ...". At the output, you can download the resulting package in the .tgz archive (it contains all the necessary files):
Next, we take a file with the extension .lm (our model) from the archive.
Let's fix the python recognition script by replacing the model with a newly made one:
#'lm': os.path.join(model_path, 'C://python3//zero_ru_cont_8k_v3//ru.lm'), 'lm': os.path.join(model_path, 'C://python3//my_model//1896.lm'),
We try:
It works much faster - less than a second, in addition, all letters are defined.
But here a small remark is needed.
Not all characters are recognized correctly, and if instead of the correct letter a different character is displayed, you can manually correct the previously created .dic dictionary by matching the correspondence of the letter.
For example, instead of the letter a, displays e. It is necessary to take a line from the dictionary e:
ry
and transfer (deleting the old) it, changing the letter:
ry
But since the letter “a” is already in the dictionary, then you need to add “(2)” (or 3.4) to the letter, in general, a serial number, depending on how many sounds are already in the dictionary:
a(2) ry
Re-convert the dictionary is not necessary. In such a simple way you can "pick up" phonemes of all letters, almost.
Cherchez la femme
Model and vocabulary work, but not with a female voice. If the voice of the captcha is female, then we get nothing at the output. This is both good and bad at the same time. First about the good.
If you didn’t recognize anything when starting the program, it means we are dealing with a female voice, so you can filter “female” captchas.
But what to do with them?
Here you need to work with conversion.
For example, with a “male” captcha, the frequency was 16000, and for a female “captcha” 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav
All sounds are defined (in each line by sound), but their correspondence is lame.
It is better to create a separate dictionary for the female model and then edit it.
However, this is for self-study.
Useful links:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom
2.https: //itnan.ru/post.php? C = 1 & p = 351376
3. ru.wikipedia.org/wiki/Cherchez_la_femme
Files:
1. The program .
2. The model .
3. The Russian model .
4. Dictionary .
5. Test captcha .
6. ffmpeg .
7. A pack of captcha .
All Articles