Understanding message brokers. Learning the mechanics of messaging through ActiveMQ and Kafka. Chapter 3. Kafka
Continuation of the translation of a small book:
"Understanding Message Brokers",
author: Jakub Korab, publisher: O'Reilly Media, Inc., publication date: June 2017, ISBN: 9781492049296.
Previously Translated Part: Understanding Message Brokers. Learning the mechanics of messaging through ActiveMQ and Kafka. Chapter 1. Introduction
Kafka was developed on LinkedIn to circumvent some of the limitations of traditional message brokers and to avoid the need to configure multiple message brokers for different point-to-point interactions, which is described in the “Vertical and Horizontal Scaling” section on page 28 in this book. LinkedIn relied heavily on the unidirectional absorption of very large amounts of data, such as page clicks and access logs, while allowing multiple systems to use this data. am, without affecting the performance of other producers or konsyumerov. In fact, the reason Kafka exists is to get the messaging architecture that the Universal Data Pipeline describes.
Given this ultimate goal, other requirements naturally arose. Kafka should:
To achieve all this, Kafka has adopted an architecture that redefined the roles and responsibilities of clients and messaging brokers. The JMS model is very focused on the broker, where he is responsible for the distribution of messages, and customers need only worry about sending and receiving messages. Kafka, on the other hand, is customer-oriented, with the client taking on many of the functions of a traditional broker, such as the fair distribution of relevant messages among consumers, in exchange receiving an extremely fast and scalable broker. For people working with traditional messaging systems, working with Kafka requires a fundamental change in attitude.
This engineering direction has led to the creation of a messaging infrastructure that can increase throughput by many orders of magnitude compared to a conventional broker. As we will see, this approach is fraught with compromises, which mean that Kafka is not suitable for certain types of loads and installed software.
To fulfill the requirements described above, Kafka combined the publication-subscription and point-to-point messaging in one type of addressee - topic . This is confusing for people working with messaging systems, where the word "topic" refers to the broadcast mechanism from which (from the topic) reading is not reliable (is nondurable). Kafka topics should be considered a hybrid type of destination, as defined in the introduction to this book.
To fully understand how topics behave and what guarantees they provide, we first need to consider how they are implemented in Kafka.
Each topic in Kafka has its own magazine.
Producers who send messages to Kafka append to this magazine, and consumers read from the magazine using pointers that constantly move forward. Kafka periodically deletes the oldest parts of the journal, regardless of whether messages in these parts were read or not. A central part of Kafka's design is that the broker does not care about whether messages are read or not - this is the responsibility of the client.
This model is completely different from ActiveMQ, where messages from all queues are stored in one journal, and the broker marks messages as deleted after they have been read.
Let's now go a little deeper and look at the topic magazine in more detail.
Kafka Magazine consists of several partitions ( Figure 3-1 ). Kafka guarantees strict ordering in every partition. This means that messages written to the partition in a certain order will be read in the same order. Each partition is implemented as a rolling (log) log file that contains a subset of all messages sent to the topic by its producers. The created topic contains one partition by default. Partitioning is Kafka's central idea for horizontal scaling.
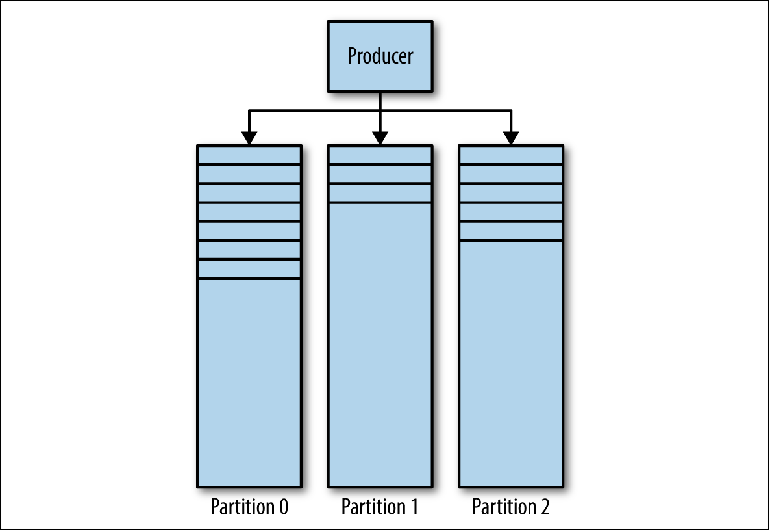
Figure 3-1. Partitions Kafka
When the producer sends a message to the Kafka topic, he decides which partition to send the message to. We will consider this in more detail later.
A client who wants to read messages controls a named pointer called a consumer group , which indicates the offset of the message in the partition. An offset is a position with an increasing number that starts at 0 at the beginning of the partition. This group of consumers, referred to in the API through the user-defined identifier group_id, corresponds to one logical consumer or system .
Most messaging systems read data from the recipient through multiple instances and threads for processing messages in parallel. Thus, there will usually be many instances of consumers who share the same group of consumers.
The reading problem can be represented as follows:
This is a nontrivial many-to-many problem. To understand how Kafka handles the relationships between groups of consumers, instances of consumers and partitions, let’s take a look at a series of increasingly complex reading scripts.
Let's take a single-partition topic as a starting point ( Figure 3-2 ).
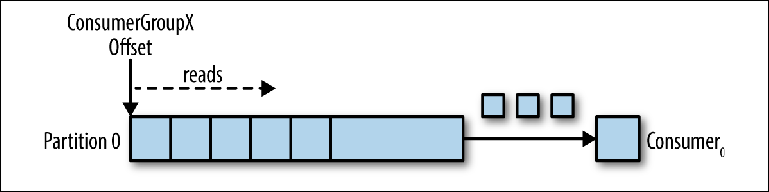
Figure 3-2. Consumer reads from the partition
When a consumer instance is connected with its own group_id to this topic, it is assigned a partition to read and an offset in this partition. The position of this offset is configured in the client as a pointer to the most recent position (the newest message) or the earliest position (the oldest message). The consumer requests (polls) messages from the topic, which leads to their sequential reading from the journal.
The offset position is regularly committed back to Kafka and saved as messages in the _consumer_offsets internal topic. Read messages are still not deleted, unlike a regular broker, and the client can rewind the offset in order to re-process already viewed messages.
When a second logical consumer is connected using a different group_id, it controls a second pointer that is independent of the first ( Figure 3-3 ). Thus, the Kafka topic acts as a queue in which there is one consumer and, as a regular topic, a publisher-subscriber (pub-sub), to which several consumers are subscribed, with the additional advantage that all messages are saved and can be processed several times.
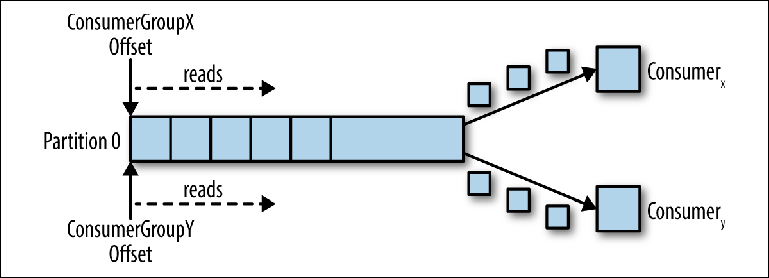
Figure 3-3. Two consumers in different groups of consumers read from the same partition
When one instance of the consumer reads data from the partition, it completely controls the pointer and processes the messages, as described in the previous section.
If several instances of the consumers were connected with the same group_id to the topic with the same partition, then the last connected instance will be given control over the pointer and from then on it will receive all messages ( Figure 3-4 ).
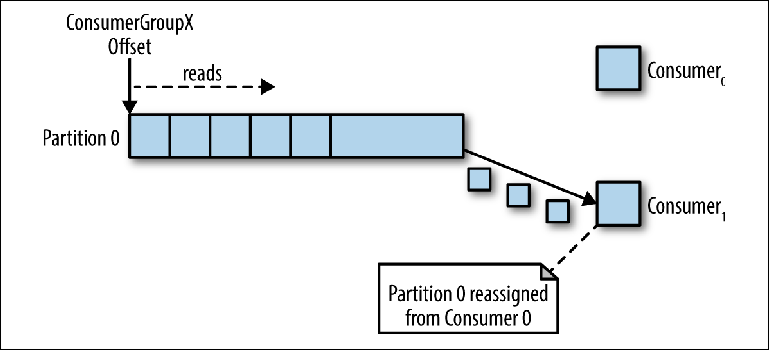
Figure 3-4. Two consumers in the same group of consumers read from the same partition
This processing mode, in which the number of instances of consumers exceeds the number of partitions, can be considered as a kind of monopoly consumer. This can be useful if you need “active-passive” (or “hot-warm”) clustering of your instances of consumers, although the parallel operation of several consumers (“active-active” or “hot-hot”) is much more typical than consumers In standby.
Most often, when we create several instances of compilers, we do this either for parallel processing of messages, or to increase the speed of reading, or to increase the stability of the reading process. Since only one instance of the consumer can read data from a partition, how is this achieved in Kafka?
One way to do this is to use one instance of the consumer to read all the messages and send them to the thread pool. Although this approach increases processing throughput, it increases the complexity of consumer logic and does nothing to increase the stability of the reading system. If one instance of the consumer is disconnected due to a power failure or a similar event, then the proofreading stops.
The canonical way to solve this problem in Kafka is to use more partitions.
Partitions are the main mechanism for parallelizing the reading and scaling of the topic beyond the bandwidth of one instance of the broker. To better understand this, let's look at a situation where there is a topic with two partitions and one consumer subscribes to this topic ( Figure 3-5 ).
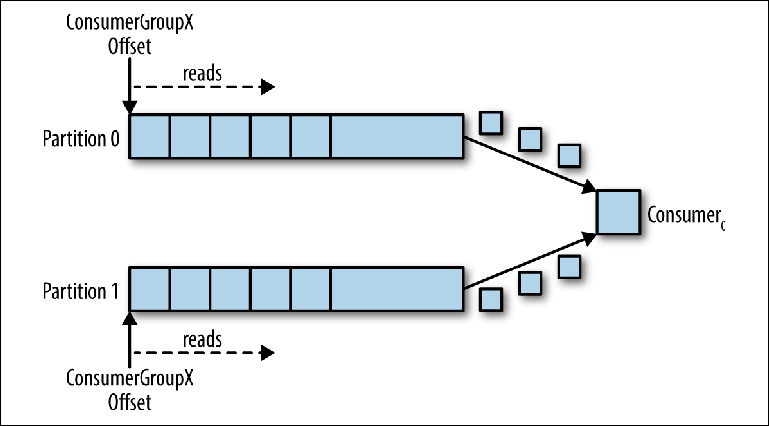
Figure 3-5. One consumer reads from several partitions
In this scenario, the consultant is given control over the pointers corresponding to its group_id in both partitions, and reading messages from both partitions begins.
When an additional compurator is added to this topic for the same group_id, Kafka reassigns (reallocate) one of the partitions from the first to the second one. After that, each instance of the consumer will be subtracted from one partition of the topic ( Figure 3-6 ).
To ensure that messages are processed in parallel in 20 threads, you will need at least 20 partitions. If there are fewer partitions, you will still have consumers who have nothing to work on, as described earlier in the discussion of exclusive monitors.
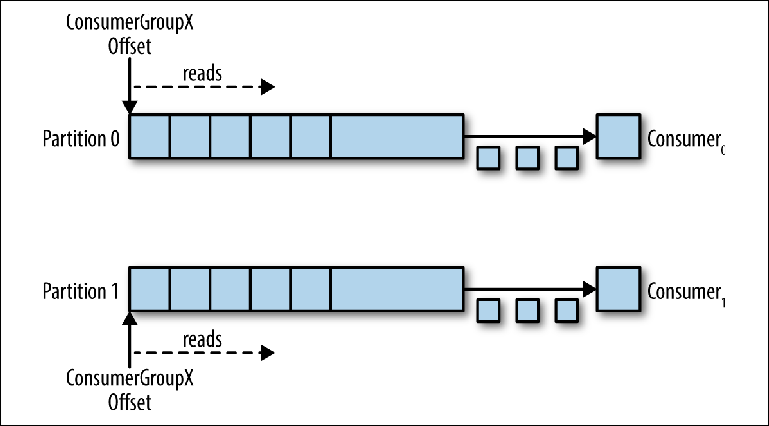
Figure 3-6. Two consumers in the same group of consumers read from different partitions
This scheme significantly reduces the complexity of the Kafka broker compared to the message distribution necessary to support the JMS queue. There is no need to take care of the following points:
All that the Kafka broker should do is to consistently send messages to the adviser when the latter requests them.
However, the requirements for parallelizing the proofreading and re-sending unsuccessful messages are not disappearing - responsibility for them simply passes from the broker to the client. This means that they must be factored into your code.
Responsibility for deciding which partition to send the message to is the producer of the message. To understand the mechanism by which this is done, you first need to consider what exactly we are actually sending.
While in JMS we use a message structure with metadata (headers and properties) and a body containing payload, in Kafka the message is a key-value pair . The message payload is sent as a value. A key, on the other hand, is used primarily for partitioning and must contain a business-logic-specific key to put related messages in the same partition.
In Chapter 2, we discussed the online betting scenario when related events must be processed in order by one consumer:
If each event is a message sent to the topic, then in this case the account identifier will be the natural key.
When a message is sent using the Kafka Producer API, it is passed to the partition function, which, given the message and the current state of the Kafka cluster, returns the identifier of the partition to which the message should be sent. This function is implemented in Java through the Partitioner interface.
This interface is as follows:
The Partitioner implementation uses the default general-purpose hashing algorithm over the key or round-robin if the key is not specified to determine the partition. This default value works well in most cases. However, in the future you will want to write your own.
Let's look at an example when you want to send metadata along with the message payload. The payload in our example is an instruction for making a deposit to a game account. An instruction is something we would like to guarantee not to modify during transmission, and we want to be sure that only a trusted superior system can initiate this instruction. In this case, the sending and receiving systems agree on the use of the signature to authenticate the message.
In a regular JMS, we simply define the message signature property and add it to the message. However, Kafka does not provide us with a mechanism for transmitting metadata - only the key and value.
Since the value is the payload of a bank transfer (bank transfer payload), the integrity of which we want to maintain, we have no choice but to determine the data structure for use in the key. Assuming we need an account identifier for partitioning, since all messages related to the account should be processed in order, we will come up with the following JSON structure:
Because the signature value will vary depending on the payload, the default Partitioner interface hash strategy will not reliably group related messages. Therefore, we will need to write our own strategy, which will analyze this key and share the value of accountId.
The user partitioning strategy should ensure that all related messages end up in the same partition. Although this seems simple, the requirement can be complicated due to the importance of ordering related messages and how fixed the number of partitions is in the topic.
The number of partitions in the topic can change over time, as they can be added if the traffic goes beyond the initial expectations. Thus, message keys can be associated with the partition to which they were originally sent, implying a portion of the state that must be distributed between producer instances.
Another factor to consider is the uniform distribution of messages between partitions. As a rule, keys are not evenly distributed across messages, and hash functions do not guarantee a fair distribution of messages for a small set of keys.
It is important to note that, no matter how you decide to split the messages, the separator itself may need to be reused.
Consider the requirement for data replication between Kafka clusters in different geographic locations. For this purpose, Kafka comes with a command line tool called MirrorMaker, which is used to read messages from one cluster and transfer them to another.
MirrorMaker must understand the keys of the replicated topic in order to maintain the relative order between messages during replication between clusters, since the number of partitions for this topic may not coincide in two clusters.
Custom partitioning strategies are relatively rare, since default hashes or round robin work successfully in most scenarios. However, if you need strict guarantees of ordering or you need to extract metadata from the payloads, partitioning is something you should take a closer look at.
Kafka's scalability and performance benefits come from transferring some of the responsibilities of a traditional broker to a client. In this case, a decision is made on the distribution of potentially related messages among several consumers working in parallel.
Partitioning is not the only thing to consider when sending messages. Let's look at the send () methods of the Producer class in the Java API:
It should be noted right away that both methods return Future, which indicates that the send operation is not performed immediately. As a result, it turns out that the message (ProducerRecord) is written to the send buffer for each active partition and transmitted to the broker in the background stream in the Kafka client library. Although this makes the work incredibly fast, it means that an inexperienced application can lose messages if its process is stopped.
As always, there is a way to make the send operation more reliable due to performance. The size of this buffer can be set to 0, and the thread of the sending application will be forced to wait until the message is sent to the broker, as follows:
Reading messages has additional difficulties that need to be considered. Unlike the JMS API, which can start a message listener in response to a message, the Consumer Kafka interface only polls. Let's take a closer look at the poll () method used for this purpose:
The return value of the method is a container structure containing several ConsumerRecord objects from potentially several partitions. The ConsumerRecord itself is a holder object for a key-value pair with associated metadata, such as the partition from which it is derived.
As discussed in Chapter 2, we must constantly remember what happens to messages after they are successfully or unsuccessfully processed, for example, if the client cannot process the message or if it interrupts work. In JMS, this was handled through acknowledgment mode. The broker will either delete the successfully processed message, or re-deliver the raw or flipped message (provided that transactions have been used).
Kafka works in a completely different way. Messages are not deleted in the broker after proofreading and the responsibility for what happens upon failure lies with the code itself.
As we already said, a group of consumers is associated with an offset in the magazine. The log position associated with this bias corresponds to the next message that will be issued in response to poll () . Crucial in reading is the point in time when this offset increases.
Returning to the reading model discussed earlier, message processing consists of three stages:
The Kafka Consumer comes with the enable.auto.commit configuration option . This is a commonly used default setting, as is usually the case with settings containing the word “auto”.
Prior to Kafka 0.10, the client using this parameter sent the offset of the last read message on the next poll () call after processing. This meant that any messages that were already fetched could be re-processed if the client had already processed them, but was unexpectedly destroyed before calling poll () . Since the broker does not save any status regarding how many times the message has been read, the next consumer who retrieves this message will not know that something bad has happened. This behavior was pseudo transactional. The offset was committed only in case of successful processing of the message, but if the client interrupted, the broker again sent the same message to another client. This behavior was consistent with the " at least once " message delivery guarantee.
In Kafka 0.10, the client code was changed in such a way that the commit began to be periodically started by the client library, in accordance with the setting auto.commit.interval.ms . This behavior is somewhere between the JMS AUTO_ACKNOWLEDGE and DUPS_OK_ACKNOWLEDGE modes. When using auto-commit, messages could be confirmed regardless of whether they were actually processed - this could happen in the case of a slow consumer. If the compurator was interrupted, messages were retrieved by the next compurator, starting from a secured position, which could lead to a message skipping. In this case, Kafka did not lose messages, the reading code simply did not process them.
This mode has the same prospects as in version 0.9: messages can be processed, but in the event of a failure, the offset may not be closed, which could potentially lead to a duplication of delivery. The more messages you retrieve when doing poll () , the greater this problem.
As discussed in the section “Reading Messages from the Queue” on page 21, there is no such thing as a one-time message delivery in the messaging system, given the failure modes.
In Kafka, there are two ways to fix (commit) an offset (offset): automatically and manually. In both cases, messages can be processed several times, in the event that the message was processed but failed before committing. You can also not process the message at all if the commit occurred in the background and your code was completed before it started processing (possibly in Kafka 0.9 and earlier versions).
You can control the process of committing offsets manually in the Kafka Consumer API by setting the enable.auto.commit parameter to false and explicitly calling one of the following methods:
If you want to process the message “at least once”, you must commit the offset manually using commitSync () by executing this command immediately after processing the messages.
These methods do not allow messages to be acknowledged before they are processed, but they do nothing to eliminate potential processing doubles, while at the same time creating the appearance of transactionality. Kafka has no transactions. The client cannot do the following:
If we cannot rely on transactions, how can we provide semantics closer to those provided by traditional messaging systems?
If there is a possibility that the offset of the consumer can increase before the message has been processed, for example, during the failure of the customer, then the customer does not have a way to find out if the group of customers passed the message when they assign a partition. Thus, one strategy is to rewind the offset to the previous position. The Kafka Consumer Advisor API provides the following methods for this:
The seek () method can be used with the method
offsetsForTimes (Map <TopicPartition, Long> timestampsToSearch) to rewind to a state at any particular point in the past.
Implicitly, using this approach means that it is very likely that some messages that were processed earlier will be read and processed again. To avoid this, we can use idempotent reading, as described in Chapter 4, to track previously viewed messages and eliminate duplicates.
As an alternative, the code of your consumer can be simple if the loss or duplication of messages is permissible. When we look at usage scenarios for which Kafka is usually used, for example, processing log events, metrics, click tracking, etc., we understand that the loss of individual messages is unlikely to have a significant impact on surrounding applications. In such cases, the default values are acceptable. On the other hand, if your application needs to transfer payments, you must carefully take care of each individual message. It all comes down to context.
Personal observations show that with increasing message intensity, the value of each individual message decreases. High volume messages tend to become valuable when viewed in aggregated form.
Kafka’s high availability approach is very different from ActiveMQ. Kafka is developed on the basis of horizontally scalable clusters in which all instances of the broker receive and distribute messages simultaneously.
The Kafka cluster consists of several broker instances running on different servers. Kafka was designed to work on a conventional stand-alone hardware, where each node has its own dedicated storage. Using Network Attached Storage (SAN) is not recommended because multiple compute nodes can compete for storage timeslots and create conflicts.
Kafka is a constantly on system. Many large Kafka users never extinguish their clusters and the software always provides updates through a consistent restart. This is achieved by guaranteeing compatibility with the previous version for messages and interactions between brokers.
Brokers are connected to a ZooKeeper server cluster , which acts as a given configuration registry and is used to coordinate the roles of each broker. ZooKeeper itself is a distributed system that provides high availability through information replication by establishing a quorum .
In the base case, the topic is created in the Kafka cluster with the following properties:
Using ZooKeepers for coordination, Kafka is trying to fairly distribute new partitions between brokers in the cluster. This is done by one instance, which acts as the Controller.
In runtime for each partition of the topic, the Controller assigns to the broker the roles of leader (leader, master, leader) and followers (followers, slaves, subordinates). The broker, acting as the leader for this partition, is responsible for receiving all messages sent to him by the producers, and distributing messages to consumers. When sending messages to a topic partition, they are replicated to all broker's nodes acting as followers for this partition. Each node that contains the logs for the partition is called a replica . A broker can act as a leader for some partitions and as a follower for others.
A follower containing all messages stored by the leader is called a synchronized replica (a replica in a synchronized state, in-sync replica). If the broker acting as the leader for the partition is disconnected, any broker who is in the updated or synchronized state for this partition can assume the role of leader. This is an incredibly sustainable design.
Part of the producer’s configuration is the acks parameter, which determines how many replicas should acknowledge receipt of a message before the application stream continues sending: 0, 1, or all. If the value is set to all , then when the message is received, the leader will send a confirmation back to the producer as soon as he receives confirmation of the record from several replicas (including himself) defined by the min.insync.replicas topic setting (by default 1). If the message cannot be successfully replicated, then the producer will throw an exception for the application ( NotEnoughReplicas or NotEnoughReplicasAfterAppend ).
In a typical configuration, a topic is created with a replication coefficient of 3 (1 leader, 2 followers for each partition) and the min.insync.replicas parameter is set to 2. In this case, the cluster will allow one of the brokers managing the partition to be disconnected without affecting client applications.
This brings us back to the already familiar compromise between performance and reliability. Replication occurs due to the additional waiting time for acknowledgments (acknowledgments) from followers. Although, since it runs in parallel, replication, at least to three nodes, has the same performance as to two (ignoring the increase in network bandwidth usage).
Using this replication scheme, Kafka cleverly avoids having to physically write each message to disk using the sync () operation . Each message sent by the producer will be written to the partition log, but, as discussed in Chapter 2, writing to the file is initially performed in the operating system buffer. If this message is replicated to another instance of Kafka and is in its memory, the loss of a leader does not mean that the message itself was lost - a synchronized replica can take it upon itself.
Opt out of sync () operationmeans that Kafka can receive messages at the speed with which it can write them to memory. Conversely, the longer you can avoid flushing memory to disk, the better. For this reason, it is not uncommon for Kafka brokers to allocate 64 GB or more of memory. This memory usage means that one instance of Kafka can easily work at speeds many thousands of times faster than a traditional message broker.
Kafka can also be configured to use sync ()to message packages. Since everything at Kafka is package oriented, it actually works pretty well for many use cases and is a useful tool for users who require very strong guarantees. Most of Kafka’s net performance is related to messages that are sent to the broker in the form of packets, and the fact that these messages are read from the broker in successive blocks using zero-copy operations (operations that do not perform the task of copying data from one memory area to another). The latter is a big gain in terms of performance and resources and is only possible through the use of the underlying log data structure that defines the partition scheme.
In a Kafka cluster, much higher performance is possible than when using a single Kafka broker, since the topic partitions can be scaled horizontally on many separate machines.
In this chapter, we examined how the Kafka architecture reinterprets the relationship between clients and brokers to provide an incredibly robust messaging pipeline, with throughput many times greater than that of a regular message broker. We discussed the functionality that it uses to achieve this, and briefly reviewed the architecture of the applications that provide this functionality. In the next chapter, we will look at common problems that messaging applications need to solve and discuss strategies for resolving them. We conclude the chapter by outlining how to talk about messaging technologies in general so that you can evaluate their suitability for your use cases.
Previously translated part: . ActiveMQ Kafka. 1
: tele.gg/middle_java
...
"Understanding Message Brokers",
author: Jakub Korab, publisher: O'Reilly Media, Inc., publication date: June 2017, ISBN: 9781492049296.
Previously Translated Part: Understanding Message Brokers. Learning the mechanics of messaging through ActiveMQ and Kafka. Chapter 1. Introduction
CHAPTER 3
Kafka
Kafka was developed on LinkedIn to circumvent some of the limitations of traditional message brokers and to avoid the need to configure multiple message brokers for different point-to-point interactions, which is described in the “Vertical and Horizontal Scaling” section on page 28 in this book. LinkedIn relied heavily on the unidirectional absorption of very large amounts of data, such as page clicks and access logs, while allowing multiple systems to use this data. am, without affecting the performance of other producers or konsyumerov. In fact, the reason Kafka exists is to get the messaging architecture that the Universal Data Pipeline describes.
Given this ultimate goal, other requirements naturally arose. Kafka should:
- Be extremely fast
- Provide greater messaging throughput
- Support Publisher-Subscriber and Point-to-Point models
- Do not slow down with the addition of consumers. For example, the performance of both queues and topics in ActiveMQ deteriorates as the number of consumers at the destination increases.
- Be horizontally scalable; if one broker that stores (persists) messages can only do this at maximum disk speed, then to increase productivity it makes sense to go beyond the limits of one broker instance
- Delineate access to message retention and retrieval
To achieve all this, Kafka has adopted an architecture that redefined the roles and responsibilities of clients and messaging brokers. The JMS model is very focused on the broker, where he is responsible for the distribution of messages, and customers need only worry about sending and receiving messages. Kafka, on the other hand, is customer-oriented, with the client taking on many of the functions of a traditional broker, such as the fair distribution of relevant messages among consumers, in exchange receiving an extremely fast and scalable broker. For people working with traditional messaging systems, working with Kafka requires a fundamental change in attitude.
This engineering direction has led to the creation of a messaging infrastructure that can increase throughput by many orders of magnitude compared to a conventional broker. As we will see, this approach is fraught with compromises, which mean that Kafka is not suitable for certain types of loads and installed software.
Unified Destination Model
To fulfill the requirements described above, Kafka combined the publication-subscription and point-to-point messaging in one type of addressee - topic . This is confusing for people working with messaging systems, where the word "topic" refers to the broadcast mechanism from which (from the topic) reading is not reliable (is nondurable). Kafka topics should be considered a hybrid type of destination, as defined in the introduction to this book.
In the remainder of this chapter, unless we explicitly specify otherwise, the term topic will refer to the Kafka topic.
To fully understand how topics behave and what guarantees they provide, we first need to consider how they are implemented in Kafka.
Each topic in Kafka has its own magazine.
Producers who send messages to Kafka append to this magazine, and consumers read from the magazine using pointers that constantly move forward. Kafka periodically deletes the oldest parts of the journal, regardless of whether messages in these parts were read or not. A central part of Kafka's design is that the broker does not care about whether messages are read or not - this is the responsibility of the client.
The terms “journal” and “index” are not found in the Kafka documentation . These well-known terms are used here to help understanding.
This model is completely different from ActiveMQ, where messages from all queues are stored in one journal, and the broker marks messages as deleted after they have been read.
Let's now go a little deeper and look at the topic magazine in more detail.
Kafka Magazine consists of several partitions ( Figure 3-1 ). Kafka guarantees strict ordering in every partition. This means that messages written to the partition in a certain order will be read in the same order. Each partition is implemented as a rolling (log) log file that contains a subset of all messages sent to the topic by its producers. The created topic contains one partition by default. Partitioning is Kafka's central idea for horizontal scaling.
Figure 3-1. Partitions Kafka
When the producer sends a message to the Kafka topic, he decides which partition to send the message to. We will consider this in more detail later.
Reading messages
A client who wants to read messages controls a named pointer called a consumer group , which indicates the offset of the message in the partition. An offset is a position with an increasing number that starts at 0 at the beginning of the partition. This group of consumers, referred to in the API through the user-defined identifier group_id, corresponds to one logical consumer or system .
Most messaging systems read data from the recipient through multiple instances and threads for processing messages in parallel. Thus, there will usually be many instances of consumers who share the same group of consumers.
The reading problem can be represented as follows:
- The topic has several partitions
- Multiple groups of consumers can use the topic at the same time.
- Consumer group may have several separate instances.
This is a nontrivial many-to-many problem. To understand how Kafka handles the relationships between groups of consumers, instances of consumers and partitions, let’s take a look at a series of increasingly complex reading scripts.
Consumers and Consumer Groups
Let's take a single-partition topic as a starting point ( Figure 3-2 ).
Figure 3-2. Consumer reads from the partition
When a consumer instance is connected with its own group_id to this topic, it is assigned a partition to read and an offset in this partition. The position of this offset is configured in the client as a pointer to the most recent position (the newest message) or the earliest position (the oldest message). The consumer requests (polls) messages from the topic, which leads to their sequential reading from the journal.
The offset position is regularly committed back to Kafka and saved as messages in the _consumer_offsets internal topic. Read messages are still not deleted, unlike a regular broker, and the client can rewind the offset in order to re-process already viewed messages.
When a second logical consumer is connected using a different group_id, it controls a second pointer that is independent of the first ( Figure 3-3 ). Thus, the Kafka topic acts as a queue in which there is one consumer and, as a regular topic, a publisher-subscriber (pub-sub), to which several consumers are subscribed, with the additional advantage that all messages are saved and can be processed several times.
Figure 3-3. Two consumers in different groups of consumers read from the same partition
Consumers in the Consumer Group
When one instance of the consumer reads data from the partition, it completely controls the pointer and processes the messages, as described in the previous section.
If several instances of the consumers were connected with the same group_id to the topic with the same partition, then the last connected instance will be given control over the pointer and from then on it will receive all messages ( Figure 3-4 ).
Figure 3-4. Two consumers in the same group of consumers read from the same partition
This processing mode, in which the number of instances of consumers exceeds the number of partitions, can be considered as a kind of monopoly consumer. This can be useful if you need “active-passive” (or “hot-warm”) clustering of your instances of consumers, although the parallel operation of several consumers (“active-active” or “hot-hot”) is much more typical than consumers In standby.
This message distribution behavior, described above, can be surprising compared to how a regular JMS queue behaves. In this model, messages sent to the queue will be evenly distributed between the two consumers.
Most often, when we create several instances of compilers, we do this either for parallel processing of messages, or to increase the speed of reading, or to increase the stability of the reading process. Since only one instance of the consumer can read data from a partition, how is this achieved in Kafka?
One way to do this is to use one instance of the consumer to read all the messages and send them to the thread pool. Although this approach increases processing throughput, it increases the complexity of consumer logic and does nothing to increase the stability of the reading system. If one instance of the consumer is disconnected due to a power failure or a similar event, then the proofreading stops.
The canonical way to solve this problem in Kafka is to use more partitions.
Partitioning
Partitions are the main mechanism for parallelizing the reading and scaling of the topic beyond the bandwidth of one instance of the broker. To better understand this, let's look at a situation where there is a topic with two partitions and one consumer subscribes to this topic ( Figure 3-5 ).
Figure 3-5. One consumer reads from several partitions
In this scenario, the consultant is given control over the pointers corresponding to its group_id in both partitions, and reading messages from both partitions begins.
When an additional compurator is added to this topic for the same group_id, Kafka reassigns (reallocate) one of the partitions from the first to the second one. After that, each instance of the consumer will be subtracted from one partition of the topic ( Figure 3-6 ).
To ensure that messages are processed in parallel in 20 threads, you will need at least 20 partitions. If there are fewer partitions, you will still have consumers who have nothing to work on, as described earlier in the discussion of exclusive monitors.
Figure 3-6. Two consumers in the same group of consumers read from different partitions
This scheme significantly reduces the complexity of the Kafka broker compared to the message distribution necessary to support the JMS queue. There is no need to take care of the following points:
- Which consumer should receive the next message based on round-robin distribution, current prefetch buffer capacity, or previous messages (as for JMS message groups).
- What messages were sent to which consumers and should they be resent in the event of a failure.
All that the Kafka broker should do is to consistently send messages to the adviser when the latter requests them.
However, the requirements for parallelizing the proofreading and re-sending unsuccessful messages are not disappearing - responsibility for them simply passes from the broker to the client. This means that they must be factored into your code.
Sending messages
Responsibility for deciding which partition to send the message to is the producer of the message. To understand the mechanism by which this is done, you first need to consider what exactly we are actually sending.
While in JMS we use a message structure with metadata (headers and properties) and a body containing payload, in Kafka the message is a key-value pair . The message payload is sent as a value. A key, on the other hand, is used primarily for partitioning and must contain a business-logic-specific key to put related messages in the same partition.
In Chapter 2, we discussed the online betting scenario when related events must be processed in order by one consumer:
- User account is configured.
- Money is credited to the account.
- A bet is made that withdraws money from the account.
If each event is a message sent to the topic, then in this case the account identifier will be the natural key.
When a message is sent using the Kafka Producer API, it is passed to the partition function, which, given the message and the current state of the Kafka cluster, returns the identifier of the partition to which the message should be sent. This function is implemented in Java through the Partitioner interface.
This interface is as follows:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }
The Partitioner implementation uses the default general-purpose hashing algorithm over the key or round-robin if the key is not specified to determine the partition. This default value works well in most cases. However, in the future you will want to write your own.
Writing your own partitioning strategy
Let's look at an example when you want to send metadata along with the message payload. The payload in our example is an instruction for making a deposit to a game account. An instruction is something we would like to guarantee not to modify during transmission, and we want to be sure that only a trusted superior system can initiate this instruction. In this case, the sending and receiving systems agree on the use of the signature to authenticate the message.
In a regular JMS, we simply define the message signature property and add it to the message. However, Kafka does not provide us with a mechanism for transmitting metadata - only the key and value.
Since the value is the payload of a bank transfer (bank transfer payload), the integrity of which we want to maintain, we have no choice but to determine the data structure for use in the key. Assuming we need an account identifier for partitioning, since all messages related to the account should be processed in order, we will come up with the following JSON structure:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }
Because the signature value will vary depending on the payload, the default Partitioner interface hash strategy will not reliably group related messages. Therefore, we will need to write our own strategy, which will analyze this key and share the value of accountId.
Kafka includes checksums to detect message corruption in the repository and has a complete set of security features. Even then, industry-specific requirements sometimes appear, such as the one above.
The user partitioning strategy should ensure that all related messages end up in the same partition. Although this seems simple, the requirement can be complicated due to the importance of ordering related messages and how fixed the number of partitions is in the topic.
The number of partitions in the topic can change over time, as they can be added if the traffic goes beyond the initial expectations. Thus, message keys can be associated with the partition to which they were originally sent, implying a portion of the state that must be distributed between producer instances.
Another factor to consider is the uniform distribution of messages between partitions. As a rule, keys are not evenly distributed across messages, and hash functions do not guarantee a fair distribution of messages for a small set of keys.
It is important to note that, no matter how you decide to split the messages, the separator itself may need to be reused.
Consider the requirement for data replication between Kafka clusters in different geographic locations. For this purpose, Kafka comes with a command line tool called MirrorMaker, which is used to read messages from one cluster and transfer them to another.
MirrorMaker must understand the keys of the replicated topic in order to maintain the relative order between messages during replication between clusters, since the number of partitions for this topic may not coincide in two clusters.
Custom partitioning strategies are relatively rare, since default hashes or round robin work successfully in most scenarios. However, if you need strict guarantees of ordering or you need to extract metadata from the payloads, partitioning is something you should take a closer look at.
Kafka's scalability and performance benefits come from transferring some of the responsibilities of a traditional broker to a client. In this case, a decision is made on the distribution of potentially related messages among several consumers working in parallel.
JMS brokers must also deal with such requirements. Interestingly, the mechanism for sending related messages to the same account implemented through JMS Message Groups (a kind of sticky load balancing (SLB) balancing strategy) also requires the sender to mark messages as related. In the case of JMS, the broker is responsible for sending this group of related messages to one of the many customers and transferring ownership of the group if the customer has fallen off.
Producer agreement
Partitioning is not the only thing to consider when sending messages. Let's look at the send () methods of the Producer class in the Java API:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback);
It should be noted right away that both methods return Future, which indicates that the send operation is not performed immediately. As a result, it turns out that the message (ProducerRecord) is written to the send buffer for each active partition and transmitted to the broker in the background stream in the Kafka client library. Although this makes the work incredibly fast, it means that an inexperienced application can lose messages if its process is stopped.
As always, there is a way to make the send operation more reliable due to performance. The size of this buffer can be set to 0, and the thread of the sending application will be forced to wait until the message is sent to the broker, as follows:
RecordMetadata metadata = producer.send(record).get();
Once again about reading messages
Reading messages has additional difficulties that need to be considered. Unlike the JMS API, which can start a message listener in response to a message, the Consumer Kafka interface only polls. Let's take a closer look at the poll () method used for this purpose:
ConsumerRecords < K, V > poll(long timeout);
The return value of the method is a container structure containing several ConsumerRecord objects from potentially several partitions. The ConsumerRecord itself is a holder object for a key-value pair with associated metadata, such as the partition from which it is derived.
As discussed in Chapter 2, we must constantly remember what happens to messages after they are successfully or unsuccessfully processed, for example, if the client cannot process the message or if it interrupts work. In JMS, this was handled through acknowledgment mode. The broker will either delete the successfully processed message, or re-deliver the raw or flipped message (provided that transactions have been used).
Kafka works in a completely different way. Messages are not deleted in the broker after proofreading and the responsibility for what happens upon failure lies with the code itself.
As we already said, a group of consumers is associated with an offset in the magazine. The log position associated with this bias corresponds to the next message that will be issued in response to poll () . Crucial in reading is the point in time when this offset increases.
Returning to the reading model discussed earlier, message processing consists of three stages:
- Retrieve a message to read.
- Process the message.
- Confirm message.
The Kafka Consumer comes with the enable.auto.commit configuration option . This is a commonly used default setting, as is usually the case with settings containing the word “auto”.
Prior to Kafka 0.10, the client using this parameter sent the offset of the last read message on the next poll () call after processing. This meant that any messages that were already fetched could be re-processed if the client had already processed them, but was unexpectedly destroyed before calling poll () . Since the broker does not save any status regarding how many times the message has been read, the next consumer who retrieves this message will not know that something bad has happened. This behavior was pseudo transactional. The offset was committed only in case of successful processing of the message, but if the client interrupted, the broker again sent the same message to another client. This behavior was consistent with the " at least once " message delivery guarantee.
In Kafka 0.10, the client code was changed in such a way that the commit began to be periodically started by the client library, in accordance with the setting auto.commit.interval.ms . This behavior is somewhere between the JMS AUTO_ACKNOWLEDGE and DUPS_OK_ACKNOWLEDGE modes. When using auto-commit, messages could be confirmed regardless of whether they were actually processed - this could happen in the case of a slow consumer. If the compurator was interrupted, messages were retrieved by the next compurator, starting from a secured position, which could lead to a message skipping. In this case, Kafka did not lose messages, the reading code simply did not process them.
This mode has the same prospects as in version 0.9: messages can be processed, but in the event of a failure, the offset may not be closed, which could potentially lead to a duplication of delivery. The more messages you retrieve when doing poll () , the greater this problem.
As discussed in the section “Reading Messages from the Queue” on page 21, there is no such thing as a one-time message delivery in the messaging system, given the failure modes.
In Kafka, there are two ways to fix (commit) an offset (offset): automatically and manually. In both cases, messages can be processed several times, in the event that the message was processed but failed before committing. You can also not process the message at all if the commit occurred in the background and your code was completed before it started processing (possibly in Kafka 0.9 and earlier versions).
You can control the process of committing offsets manually in the Kafka Consumer API by setting the enable.auto.commit parameter to false and explicitly calling one of the following methods:
void commitSync(); void commitAsync();
If you want to process the message “at least once”, you must commit the offset manually using commitSync () by executing this command immediately after processing the messages.
These methods do not allow messages to be acknowledged before they are processed, but they do nothing to eliminate potential processing doubles, while at the same time creating the appearance of transactionality. Kafka has no transactions. The client cannot do the following:
- Automatically roll back a rollback message. Consumers themselves must handle exceptions that arise from problematic payloads and backend disconnections, as they cannot rely on the broker to re-deliver messages.
- Send messages to several topics within one atomic operation. As we will soon see, control over various topics and partitions can be located on different machines in the Kafka cluster, which do not coordinate transactions when sending. At the time of this writing, some work has been done to make this possible with the KIP-98.
- Associate reading one message from one topic with sending another message to another topic. Again, the architecture of Kafka depends on many independent machines working as a single bus and no attempt is made to hide it. For example, there are no API components that would allow the Consumer and the Producer to be linked in a transaction. In JMS, this is provided by the Session object from which MessageProducers and MessageConsumers are created.
If we cannot rely on transactions, how can we provide semantics closer to those provided by traditional messaging systems?
If there is a possibility that the offset of the consumer can increase before the message has been processed, for example, during the failure of the customer, then the customer does not have a way to find out if the group of customers passed the message when they assign a partition. Thus, one strategy is to rewind the offset to the previous position. The Kafka Consumer Advisor API provides the following methods for this:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions);
The seek () method can be used with the method
offsetsForTimes (Map <TopicPartition, Long> timestampsToSearch) to rewind to a state at any particular point in the past.
Implicitly, using this approach means that it is very likely that some messages that were processed earlier will be read and processed again. To avoid this, we can use idempotent reading, as described in Chapter 4, to track previously viewed messages and eliminate duplicates.
As an alternative, the code of your consumer can be simple if the loss or duplication of messages is permissible. When we look at usage scenarios for which Kafka is usually used, for example, processing log events, metrics, click tracking, etc., we understand that the loss of individual messages is unlikely to have a significant impact on surrounding applications. In such cases, the default values are acceptable. On the other hand, if your application needs to transfer payments, you must carefully take care of each individual message. It all comes down to context.
Personal observations show that with increasing message intensity, the value of each individual message decreases. High volume messages tend to become valuable when viewed in aggregated form.
High Availability
Kafka’s high availability approach is very different from ActiveMQ. Kafka is developed on the basis of horizontally scalable clusters in which all instances of the broker receive and distribute messages simultaneously.
The Kafka cluster consists of several broker instances running on different servers. Kafka was designed to work on a conventional stand-alone hardware, where each node has its own dedicated storage. Using Network Attached Storage (SAN) is not recommended because multiple compute nodes can compete for storage timeslots and create conflicts.
Kafka is a constantly on system. Many large Kafka users never extinguish their clusters and the software always provides updates through a consistent restart. This is achieved by guaranteeing compatibility with the previous version for messages and interactions between brokers.
Brokers are connected to a ZooKeeper server cluster , which acts as a given configuration registry and is used to coordinate the roles of each broker. ZooKeeper itself is a distributed system that provides high availability through information replication by establishing a quorum .
In the base case, the topic is created in the Kafka cluster with the following properties:
- The number of partitions. As discussed earlier, the exact value used here depends on the desired level of concurrent reading.
- The replication coefficient (factor) determines how many broker instances in the cluster should contain the logs for this partition.
Using ZooKeepers for coordination, Kafka is trying to fairly distribute new partitions between brokers in the cluster. This is done by one instance, which acts as the Controller.
In runtime for each partition of the topic, the Controller assigns to the broker the roles of leader (leader, master, leader) and followers (followers, slaves, subordinates). The broker, acting as the leader for this partition, is responsible for receiving all messages sent to him by the producers, and distributing messages to consumers. When sending messages to a topic partition, they are replicated to all broker's nodes acting as followers for this partition. Each node that contains the logs for the partition is called a replica . A broker can act as a leader for some partitions and as a follower for others.
A follower containing all messages stored by the leader is called a synchronized replica (a replica in a synchronized state, in-sync replica). If the broker acting as the leader for the partition is disconnected, any broker who is in the updated or synchronized state for this partition can assume the role of leader. This is an incredibly sustainable design.
Part of the producer’s configuration is the acks parameter, which determines how many replicas should acknowledge receipt of a message before the application stream continues sending: 0, 1, or all. If the value is set to all , then when the message is received, the leader will send a confirmation back to the producer as soon as he receives confirmation of the record from several replicas (including himself) defined by the min.insync.replicas topic setting (by default 1). If the message cannot be successfully replicated, then the producer will throw an exception for the application ( NotEnoughReplicas or NotEnoughReplicasAfterAppend ).
In a typical configuration, a topic is created with a replication coefficient of 3 (1 leader, 2 followers for each partition) and the min.insync.replicas parameter is set to 2. In this case, the cluster will allow one of the brokers managing the partition to be disconnected without affecting client applications.
This brings us back to the already familiar compromise between performance and reliability. Replication occurs due to the additional waiting time for acknowledgments (acknowledgments) from followers. Although, since it runs in parallel, replication, at least to three nodes, has the same performance as to two (ignoring the increase in network bandwidth usage).
Using this replication scheme, Kafka cleverly avoids having to physically write each message to disk using the sync () operation . Each message sent by the producer will be written to the partition log, but, as discussed in Chapter 2, writing to the file is initially performed in the operating system buffer. If this message is replicated to another instance of Kafka and is in its memory, the loss of a leader does not mean that the message itself was lost - a synchronized replica can take it upon itself.
Opt out of sync () operationmeans that Kafka can receive messages at the speed with which it can write them to memory. Conversely, the longer you can avoid flushing memory to disk, the better. For this reason, it is not uncommon for Kafka brokers to allocate 64 GB or more of memory. This memory usage means that one instance of Kafka can easily work at speeds many thousands of times faster than a traditional message broker.
Kafka can also be configured to use sync ()to message packages. Since everything at Kafka is package oriented, it actually works pretty well for many use cases and is a useful tool for users who require very strong guarantees. Most of Kafka’s net performance is related to messages that are sent to the broker in the form of packets, and the fact that these messages are read from the broker in successive blocks using zero-copy operations (operations that do not perform the task of copying data from one memory area to another). The latter is a big gain in terms of performance and resources and is only possible through the use of the underlying log data structure that defines the partition scheme.
In a Kafka cluster, much higher performance is possible than when using a single Kafka broker, since the topic partitions can be scaled horizontally on many separate machines.
Summary
In this chapter, we examined how the Kafka architecture reinterprets the relationship between clients and brokers to provide an incredibly robust messaging pipeline, with throughput many times greater than that of a regular message broker. We discussed the functionality that it uses to achieve this, and briefly reviewed the architecture of the applications that provide this functionality. In the next chapter, we will look at common problems that messaging applications need to solve and discuss strategies for resolving them. We conclude the chapter by outlining how to talk about messaging technologies in general so that you can evaluate their suitability for your use cases.
Previously translated part: . ActiveMQ Kafka. 1
: tele.gg/middle_java
...
All Articles