Painless Fallback Cache on Scala
In large or microservice architectures, the most important service is not always the most productive and is sometimes not intended for highload. We are talking about the backend. It works slowly - it loses time on data processing and waiting for a response between it and the DBMS, and does not scale. Even if the application itself scales easily, this bottleneck does not scale at all. How to solve this problem and ensure high performance? How to provide a system response when important sources of information are silent?

If your architecture is fully consistent with the Reactive manifest, the components of the application scale indefinitely with increasing load independently of each other, and withstand the fall of any node - you know the answer. But if not, Oleg Nizhnikov ( Odomontois ) will tell how the scalability problem was solved at Tinkoff by building his painless Fallback Cache on Scala without rewriting the application.
Note. The article will have a minimum of Scala code and a maximum of general principles and ideas.
When interacting with the backend, the average application is fast. But the backend does the bulk of the work and grinds most of the data internally - more time is spent on it. Extra time is wasted waiting for a backend and DBMS response. Even if the application itself scales easily, this bottleneck does not scale at all. How to ease the load on the backend and solve the problem?
The first idea is to take data to read, requests that receive data, and configure the cache at the level of each in-memory node.
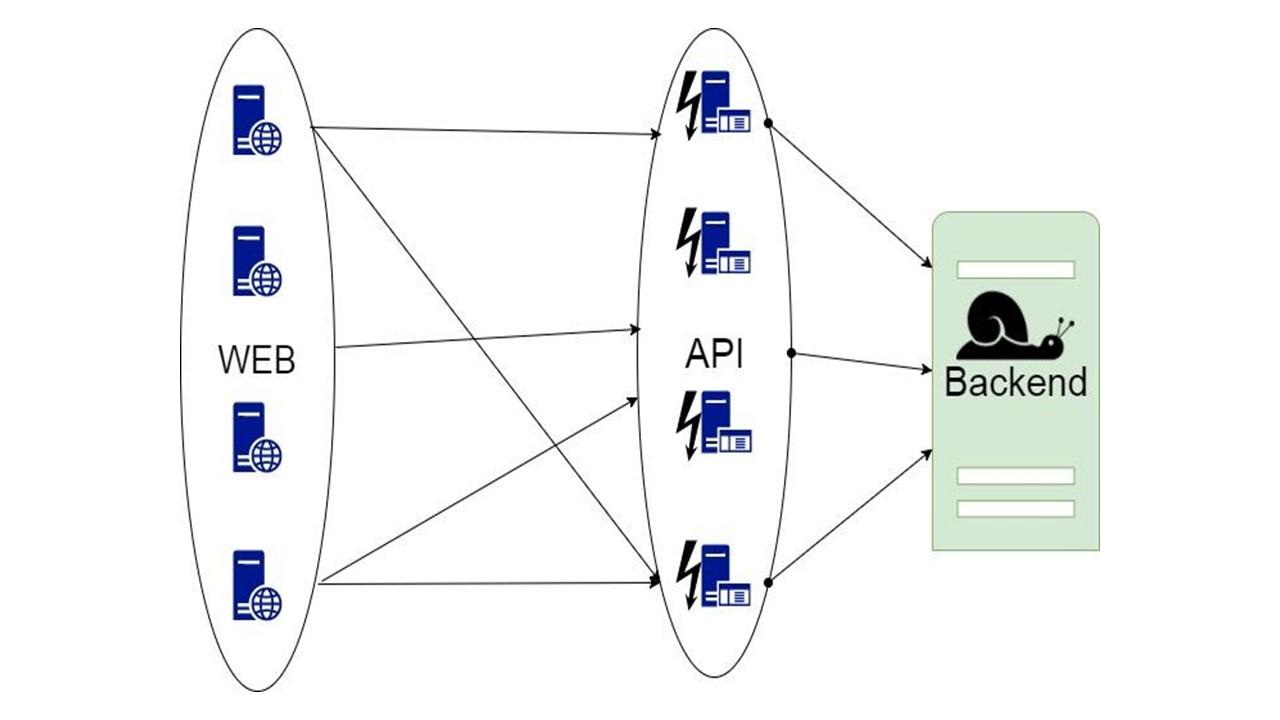
The cache lives until the node restarts and stores only the last piece of data. If the application crashes and new users who have not been in the last hour, day, or week come in, the application cannot do anything about it.
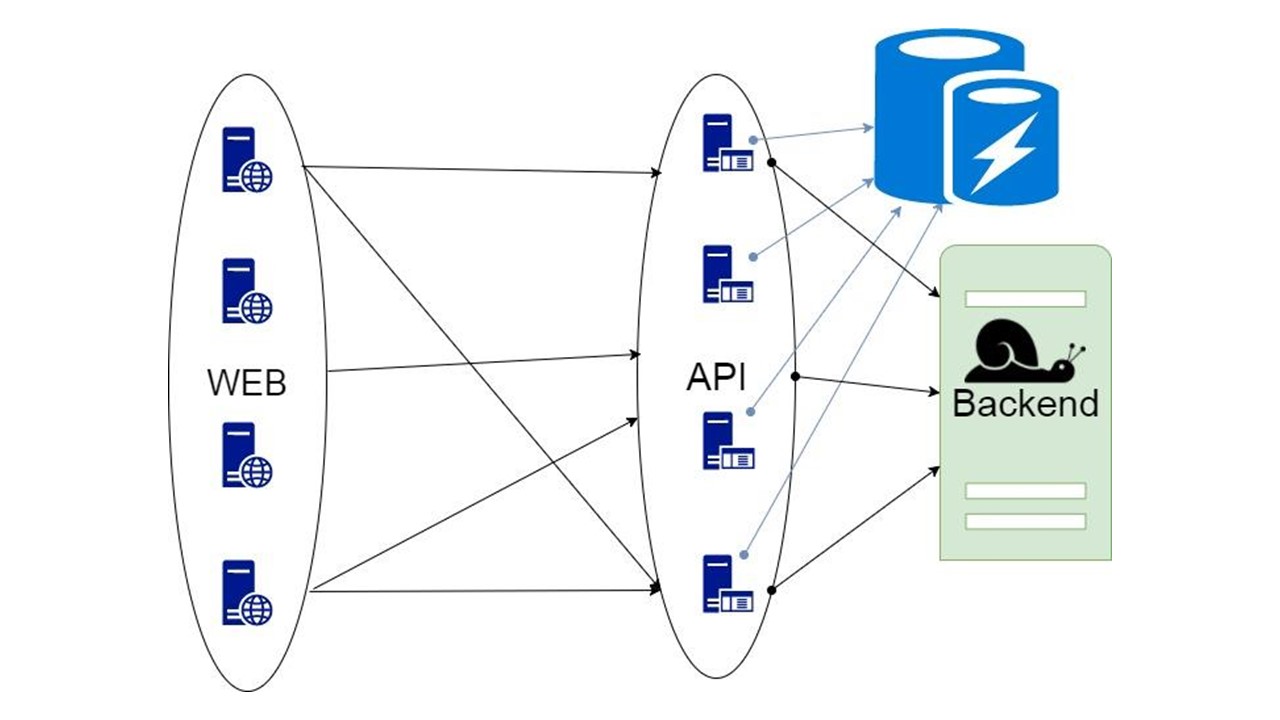
The second option is a proxy, which takes over part of the requests or modifies the application.
But in proxy, you cannot do all the work for the application itself.
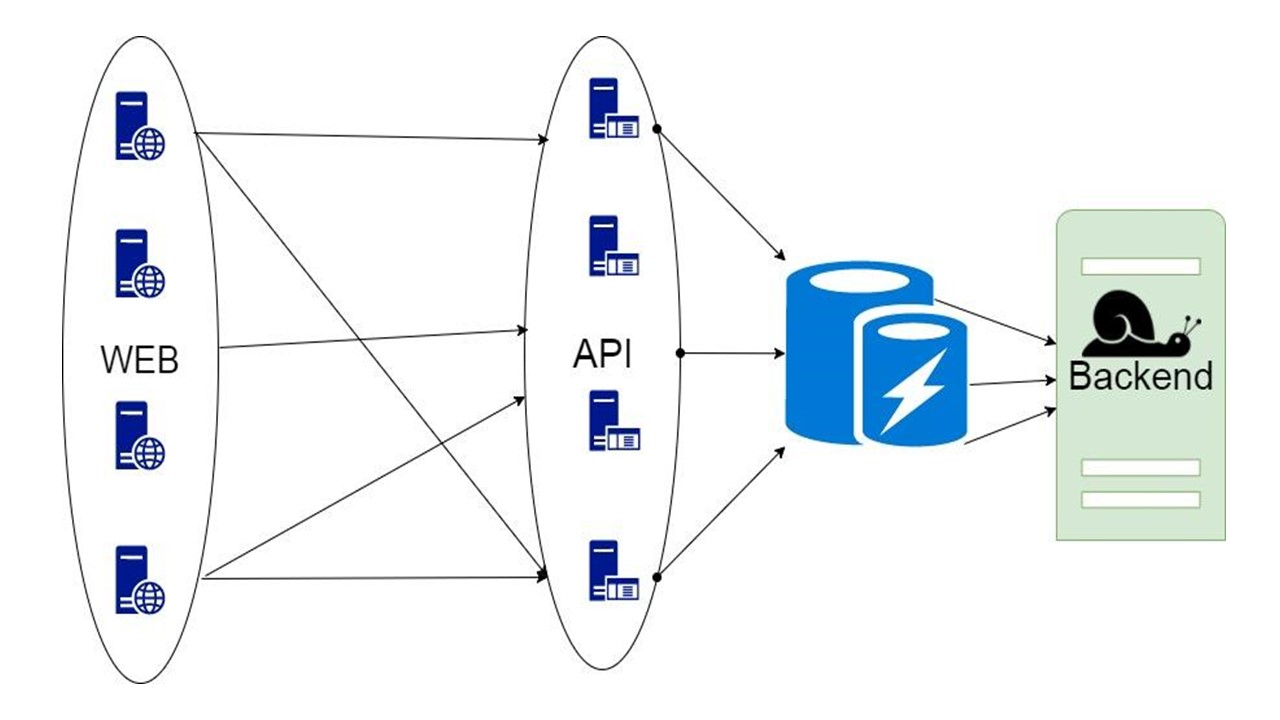
The third option is tricky when the part of the data that the backend returns can be put into storage for a long time. When they are needed, we show the client, even if they are no longer relevant. This is better than nothing.
Such a decision will be discussed.
This is our library. It is embedded in the application and communicates with the backend. With minimal refinement, it analyzes the data structure, generates serialization formats and, with the help of the Circuit Breaker algorithm, increases fault tolerance. Effective serialization can be implemented in any language where types can be analyzed in advance if they are defined strictly enough.
Our library looks something like this.

The left part is devoted to interacting with this repository, which includes two important components:
The right side is the general functionality that relates to Fallback.
How does it all work? There are queries in the middle of the application and intermediate types for storing state. This form expresses the data that we received from the backend for one or more requests. We send the parameters to our method, and we get the data from there. This data needs to be serialized somehow in order to be put into storage, so we wrap it in code. A separate module is responsible for this. We used the Circuit Breaker pattern.
Long shelf life - 30-500 days . Some actions could take a long time, and all this time it is required to store data. Therefore, we want a storage that can store data for a long time. In-memory is not suitable for this.
Large data volume - 100 GB-20 TB . We want to store dozens of terabytes of data in the cache, and even more because of growth. Keeping all this in memory is inefficient - most of the data is not constantly requested. They lie for a long time, waiting for their user, who will come in and ask. In-memory does not fall under these requirements.
High data availability . Anything can happen to the service, but we want the DBMS to remain available all the time.
Low storage costs . We send additional data to the cache. As a result, overhead occurs. When implementing our solution, we want to minimize it.
Support for queries at intervals . Our database should have been able to pull out a piece of data not only in its entirety, but at intervals: a list of actions, a user's history for a certain period. Therefore, a pure key value is not suitable.
Requirements narrow the list of candidates. We assume that we have implemented everything else, and make the following assumptions, knowing why exactly we need Fallback Cache.
Data integrity between two different GET requests is not required . Therefore, if they display two different states that are not consistent with each other, we will put up with this.
Relevance and invalidation of data is not required . At the time of the request, it is assumed that we have the latest version that we are showing.
We send and receive data from the backend. The structure of this data is known in advance .
As alternatives, we considered three main options.
The first is Cassandra . Advantages: high availability, easy scalability and built-in serialization mechanism with the UDT collection.
UDT or User Defined Types , means some type. They allow you to efficiently stack structured types. Type fields are known in advance. These serialization fields are marked with separate tags as in Protocol Buffers. After reading this structure, on the basis of tags you can understand what kind of fields there are. Enough metadata to find out their name and type.
Another plus of Cassandra is that in addition to partition key it has an additional clustering key . This is a special key, due to which the data is arranged on one node. This allows you to implement an option such as interval queries.
Cassandra has been around for a relatively long time, there are many monitoring solutions for it , and one minus is the JVM . This is not the most productive option for platforms on which you can write a DBMS. The JVM has problems with garbage collection and overhead.
The second option is CouchBase . Advantages: data accessibility, scalability and Schemaless.
With CouchBase, you need to think less about serialization. This is both a plus and a minus - we do not need to control the data scheme. There are global indexes that allow you to run interval queries globally across a cluster.
CouchBase is a hybrid where Memcache is added to a usual DBMS - fast cache . It allows you to automatically cache all the data on the node - the hottest, with very high availability. Thanks to its cache, CouchBase can be fast if the same data is requested very often.
Schemaless and JSON can also be a minus. Data can be stored for so long that the application has time to change. In this case, the data structure that CouchBase is going to store and read will also change. The previous version may not be compatible. You will learn about this only when reading, and not when developing data, when it lies somewhere in production. We have to think about proper migration, and this is exactly what we do not want to do.
The third option is Tarantool . It is famous for its super speed. It has a wonderful LUA engine that allows you to write a bunch of logic that will execute right on the server on LuaJit.
On the other hand, this is a modified key value. Data is stored in tuples. We need to think for ourselves on the correct serialization, this is not always an obvious task. Tarantool also has a specific approach to scalability . What is wrong with him, we will discuss further.
Our application may need Sharding / Replication . Three repositories implement them differently.
Cassandra suggests a structure that is usually called a “ring”.
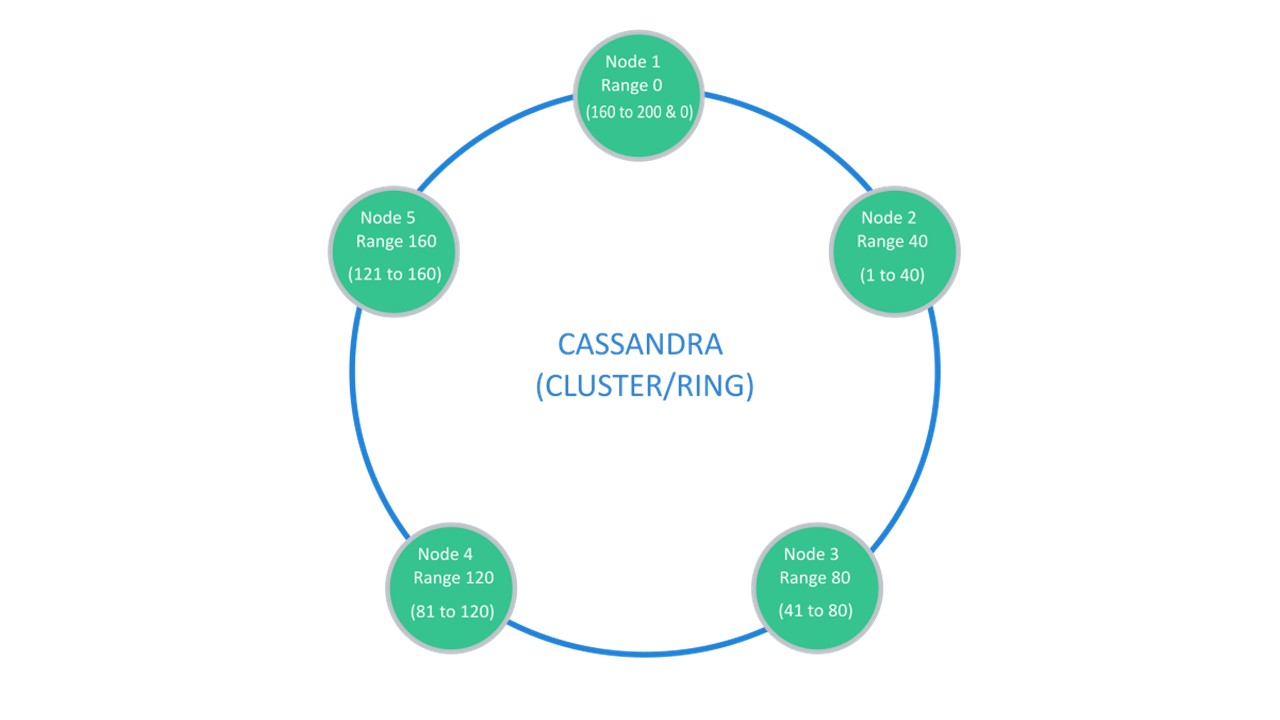
Many nodes are available. Each of them stores its data and data from the nearest nodes as replicas. If one drops out, the nodes next to it can serve part of its data until the dropout rises.
Sharding \ Replication is responsible for the same structure. To unpack into 10 pieces and Replication factor 3, 10 nodes are enough. Each of the nodes will store 2 replicas from the neighboring ones.
In CouchBase, the interaction structure between nodes is structured similarly:
If one node drops out, the neighboring ones, shared, take responsibility for the maintenance of this part of the keys.
In Tarantool, the architecture is similar to MongoDB. But with a nuance: there are sharding groups that are replicated with each other.
For the previous two architectures, if we want to make 4 shards and Replication factor 3, 4 nodes are required. For Tarantool - 12! But the disadvantage is offset by the speed that Tarantool guarantees.
Optional modules for sharding in Tarantool appeared only recently. Therefore, we chose the Cassandra DBMS as the main candidate. Recall that we talked about its specific serialization.
You can use this as an advantage. For example, serialize data so that the long field names of our leafy structures are not stored every time in our values. In this case, we will have some metadata that describes the data device. UDTs themselves also tell which fields the labels and tags correspond to.
Therefore, automatically generated serialization takes place in approximately the same way. If we have one of the basic types that can match the type from the database one to one, we do that. A set of types Int, Long, String, Double is also in Cassandra.
If an optional field is encountered in some structure, we do nothing extra. We indicate for him the type into which this field should turn. The structure will store null. If we find null in the structure at the deserialization level, we assume that this is not the value.
All collection types from the collection in Scala are converted to the list type. These are ordered collections that have an index matching element.
Unordered Set collections guarantee exactly one element with each value. For them, Cassandra also has a special set type.
Most likely, we will have a lot of mapping (), especially with string keys. Cassandra has a special map type for them. It is also typed and has two type parameters. So that we can create an appropriate type for any key
There are data types that we define ourselves in our application. In many languages they are called algebraic data types . They are defined by defining a named product of types, that is, a structure. We assign this structure to User Defined Type. Each field of the structure will correspond to one field in the UDT.
The second type is the algebraic sum of types . In this case, the type corresponds to several previously known subtypes or subspecies. Also, in a certain way, we assign a structure to it.
We have a structure, and we display it one to one - for each field we define the field in the created UDT in Cassandra:
Primitive types turn into primitive types. A reference to a type previously defined before that goes into frozen. This is a special wrapper in Cassandra, which means that you cannot read from this field piece by piece. The wrapper is “frozen” into this state. We can only read or save the user, or the list, as in the case of tags.
If we meet an optional field, then we discard this characteristic. We take only the data type corresponding to the type of field that will be. If we meet here non - the absence of a value - we will write null in the corresponding field. When reading, we will also take non-null correspondence.
If we meet a type that has several pre-known alternatives, then we also define a new data type in Cassandra. For each alternative, a field in our data type in UDT.
As a result, in this structure, only one of the fields at any given time will not be null. If you met some type of user, and it turned out to be an instance of a moderator in runtime, the moderator field will contain some value, the rest will be null. For admin - admin, the rest - null.
This allows you to encode the structure as follows: we have 4 optional fields, we guarantee that only one will be written from them. Cassandra uses only one tag to identify the presence of a particular field in the structure. Thanks to this, we get a storage structure without overhead.
In fact, in order to save the user type, if it is a moderator, it will take the same number of bytes that are required to store the moderator. Plus one byte to show which alternative is present here.
How does this process work?
It happens like this. We have types , tables, and queries . Types depend on other types, those on others. Tables depend on these types. Queries already depend on the tables from which they read data. Initialization will check all these dependencies and create in the DBMS everything that it can create, according to certain rules.
How to determine that a type can be incrementally migrated?
The developer can see this error even before he starts the functionality on production. I suppose that the exact same data scheme is in his development environment. He sees that he somehow created a non-migrable data schema, and to avoid these errors, he can override the automatically generated serialization, add options, rename fields or all types and tables as a whole.
Imagine that there are several types of definitions:
Case class - a class that contains a set of fields. This is an analogue of struct in Rust.
We generate approximately such data definitions for each of the 4 types - what we want to eventually crank up:
The type of user_offers depends on the type of offer, user_products depends on the type of product, user_info on the second and third types.

We have such a dependency between types, and we want to initialize it correctly. The diagram shows that we will initialize user_offers and user_products in parallel. This does not mean that we will launch two parallel operations. No, we start all statements, all analyzes sequentially, so as not to accidentally create the same type in two parallel threads.
But there is some parallelism at the level of error correction. If an error occurs in the type, everything that depends on it will pull the original error.
If an error is generated by any of the parallel branches, everything that depends on normally migrated data will be generated without an error. If there are further definitions of tables, prepared statements from them, we can safely initialize this part of our Fallback Cache. Communication will be lost only with some part of the backends or with some functionality. The remainders are initialized.
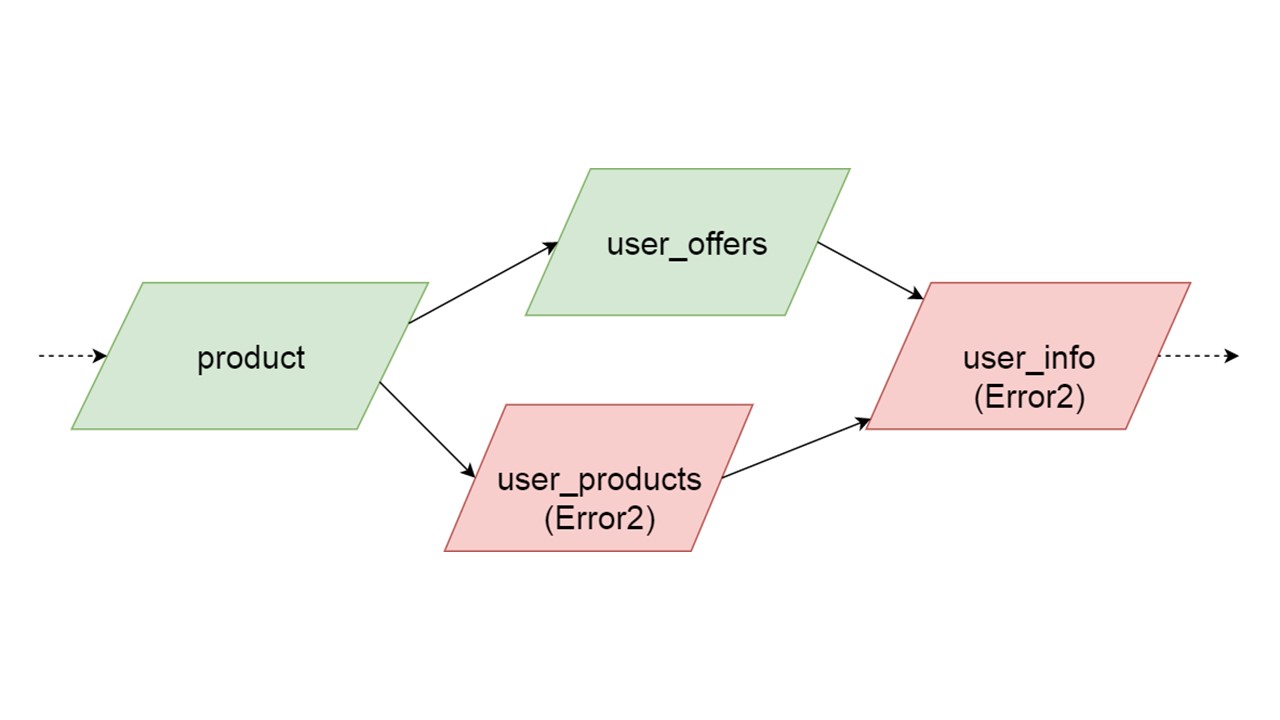
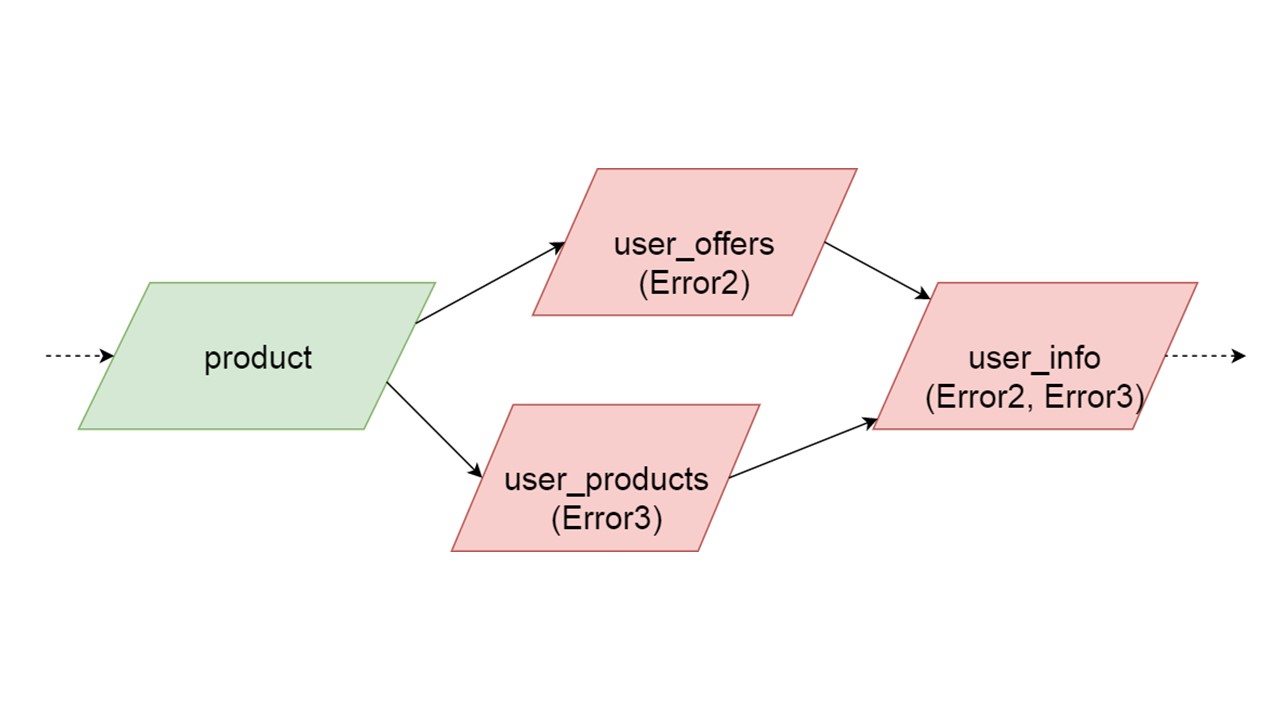
It may happen that two types that are simultaneously initialized generate different errors. In this case, functionality that depends on both types will give a summing type of error. The developer, initializing his Fallback in the development environment, will receive a complete list of data with errors. Naturally, he can fix it here and get the error further. But it will not be such that one completely independent branch closes the errors that we could get, regardless of this branch.
Next we create the tables.
Such a request can directly launch a REST or SOAP request, create additional operations inside, or even run several requests. It all depends on your code - how you organized the code will be so. Fallback absolutely does not analyze what happens inside the method on which you hang such a stub.
In Scala, this is tagged with a special type of Future. This means that the result will return someday. When exactly - it is unknown: maybe right away, or maybe not.
Create a table for the method. The key in the table is a tuple of all types that correspond to the parameters of this method. The non-key value is the result, which is returned asynchronously. For each such table, we prepare two parametric queries in advance: insert data and read data.
Everything is ready to interact with the DBMS. It remains to find out how we will read data from Fallback.
Here, responsibility passes into the zone of the famous Circuit Breaker pattern.
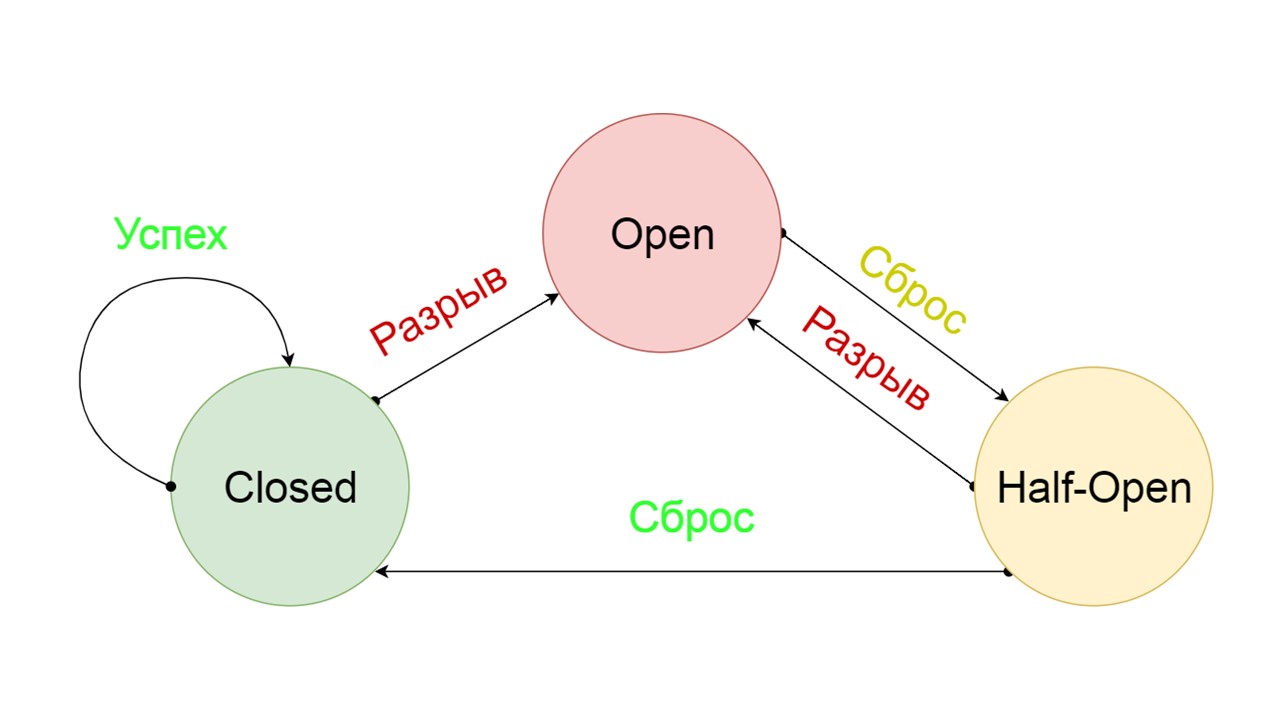
A typical Circuit Breaker includes three states.
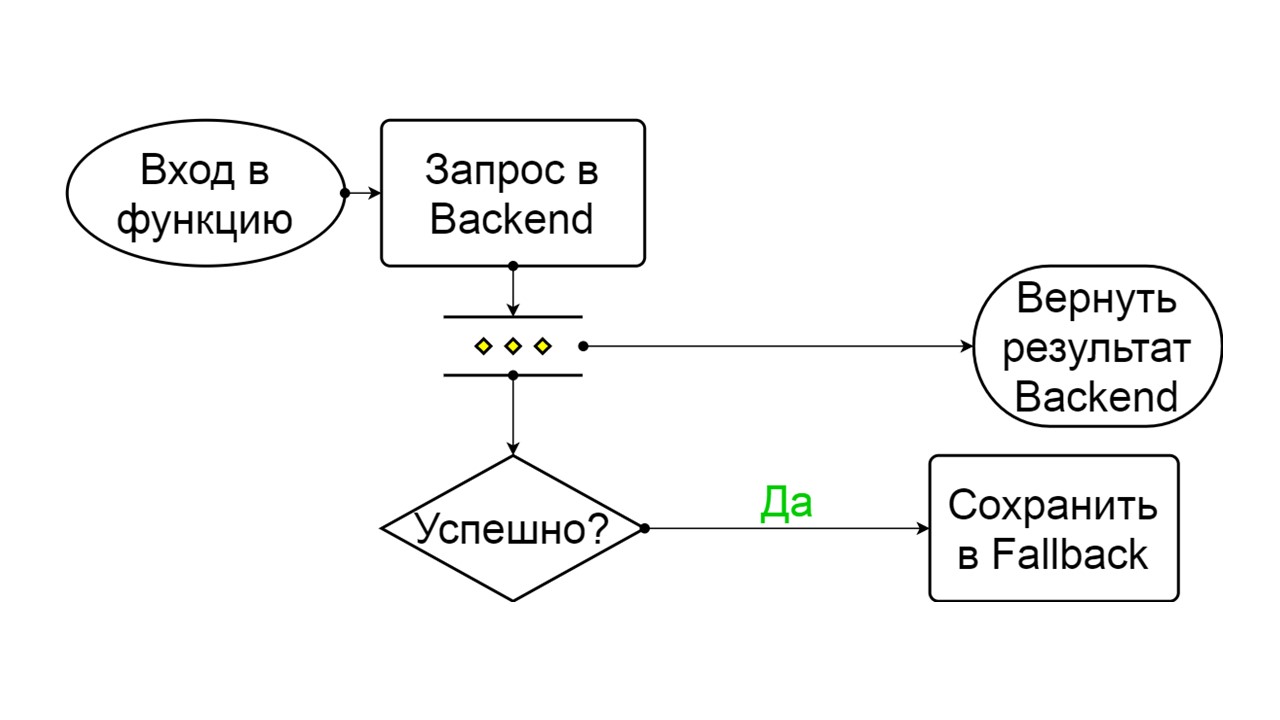
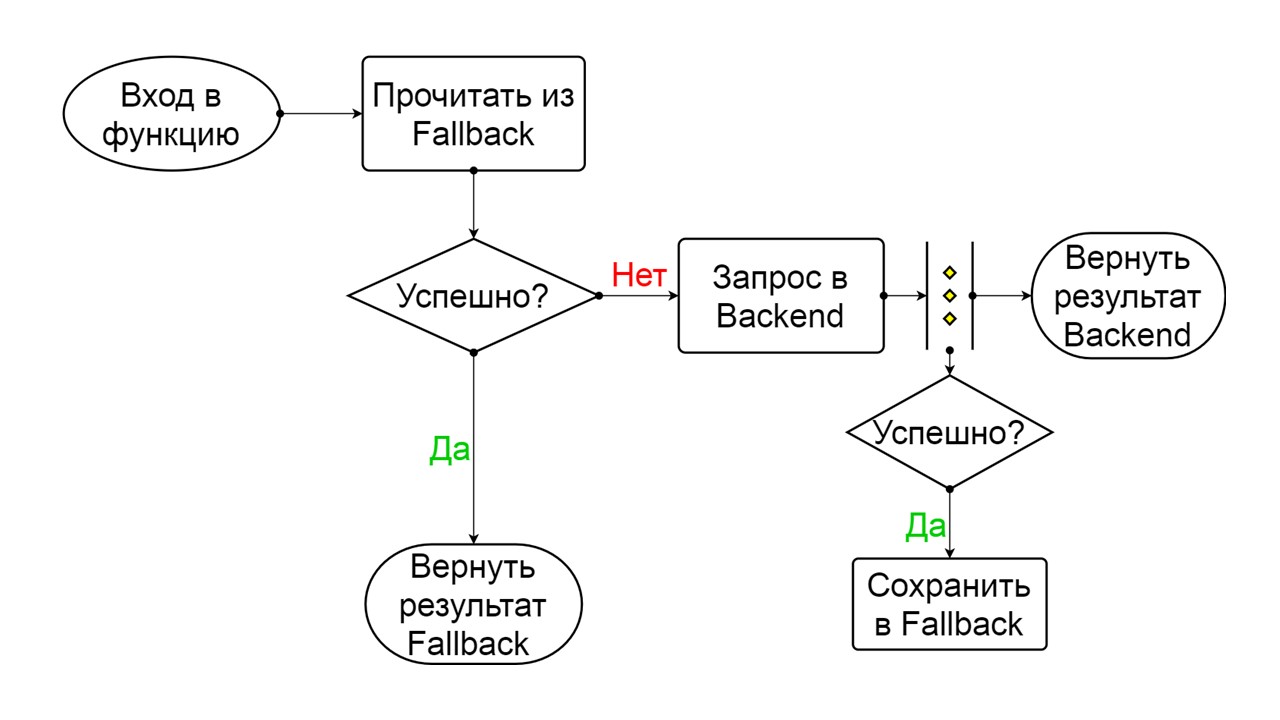
Closed - The default closed state that closes our backend. The principle is that we read the data first from the backend, and only if we could not get it, go to Fallback. If we managed to get the data, we don’t look in Fallback, but save the data in it, and nothing happens.
If the problems go one after another, we assume that the backend is lying. In order not to spam it with a gigantic amount of new requests, we switch to Open - in a torn state . In it, we are trying to read data only from Fallback. If it doesn’t work out, we immediately return an error, and don’t even touch the main backend.
After a while, we decide to find out if the backend woke up and try to reset the Half-Open state - a short-lived state . His life span is one request.
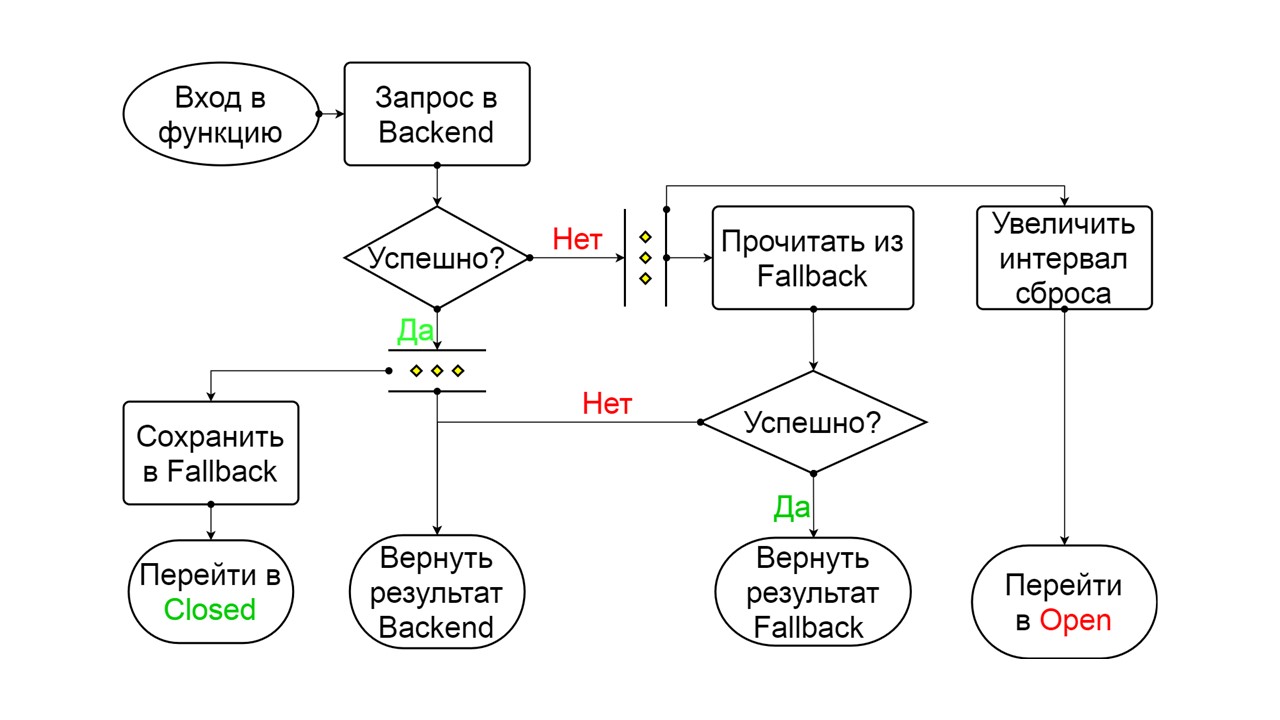
In a short-lived state, we choose to close again or open for an even longer time. If in the Half-Open state we successfully reach Fallback and receive the following request, we switch to the Closed state. If we couldn’t get through, we return to Open, but for a long time.
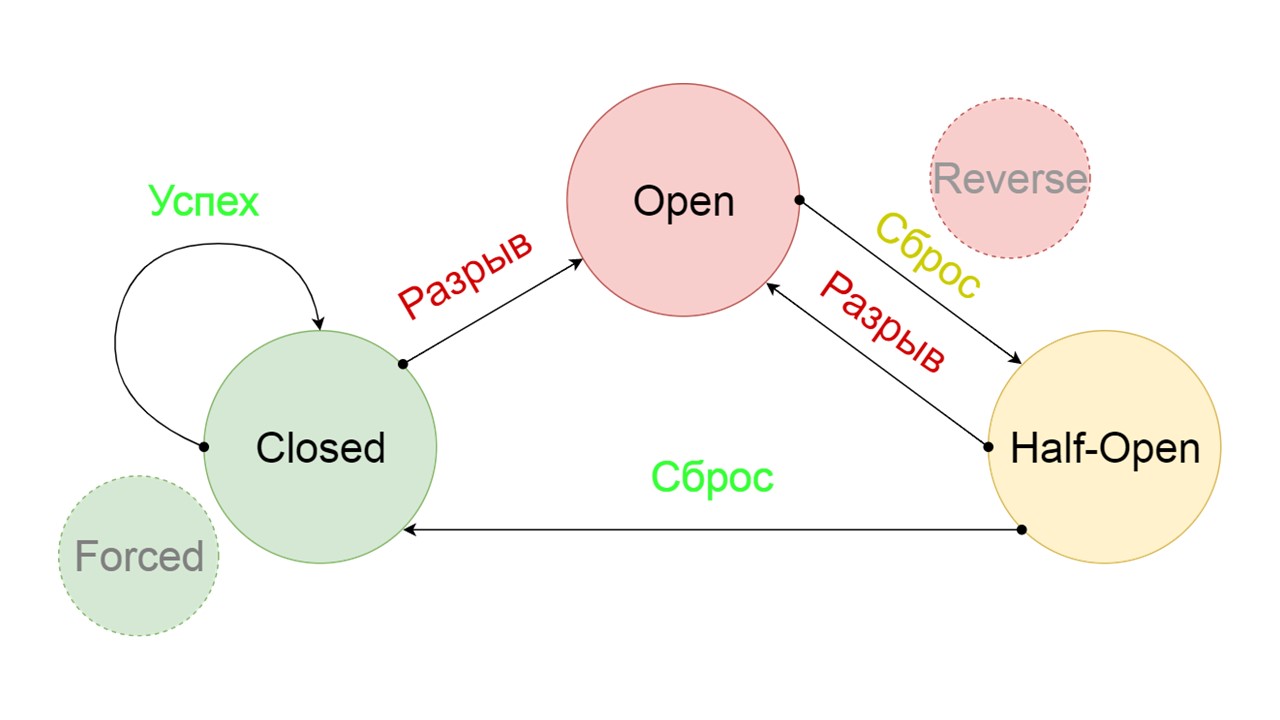
We added two additional states that are clearly not related to the Circuit Breaker circuit:
Let's see what they do.
Closed The scheme is large, but it is enough to understand the general principle from it. We keep Fallback in parallel with how we return the result from the backend, if everything went well there and read from Fallback. If it’s bad everywhere, we return the error priority.
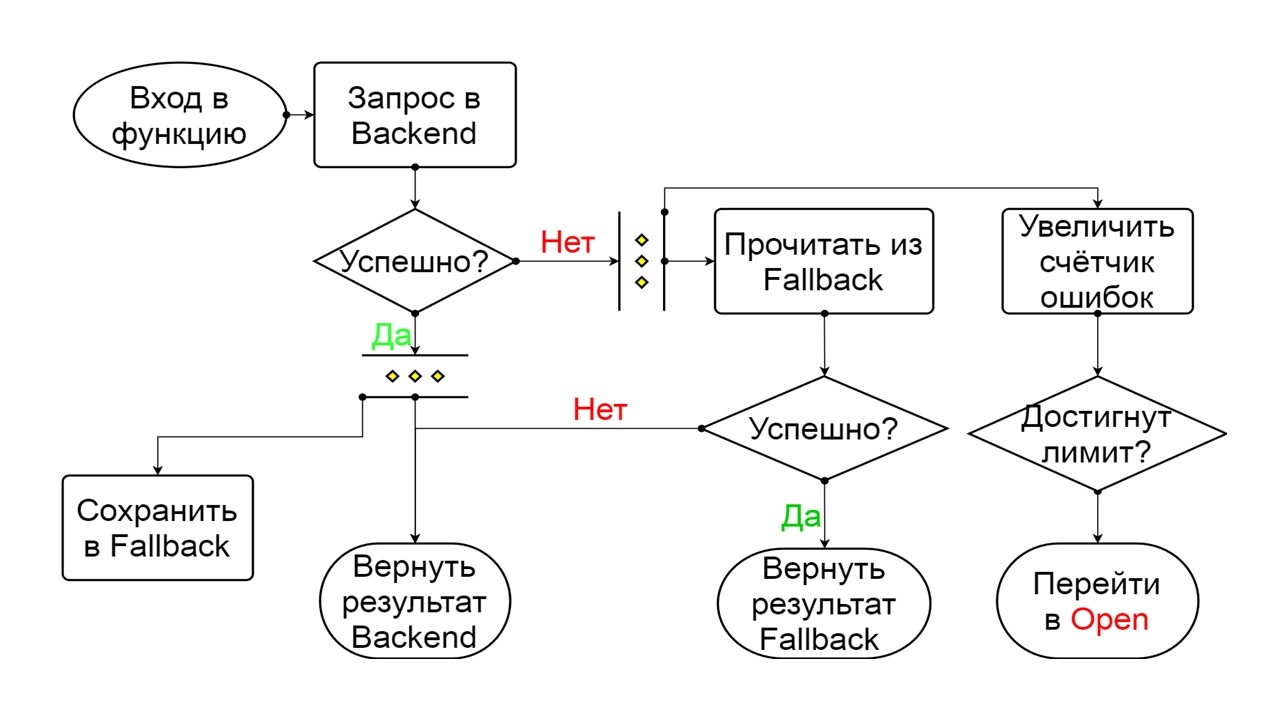
If there are no errors, we increment the counter in parallel with this and switch to the open state when there are too many requests.
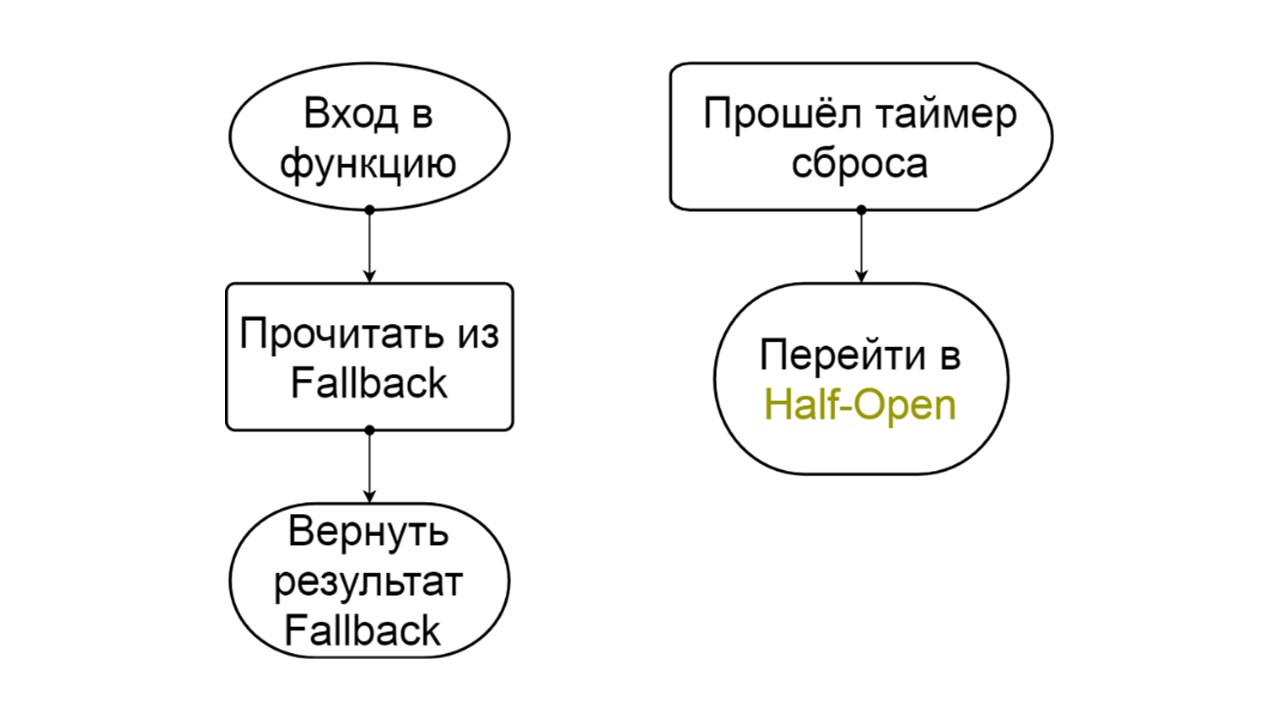
Open The open state of Open is simpler - we constantly read from Fallback, no matter what happens, and after a while we try to switch to the Half-Open state.
Half-open . The state in structure resembles Closed. The difference is that in the case of a successful answer, we go into a closed state. In case of failure - we return back to the open with an extended interval.
Forced is an extra state for warming up the cache . When we fill it with data, it never tries to read from Fallback, but only adds records.
Reversed is a second far-fetched state . It works like a persistent cache. We turn on the state when we want to permanently remove the load from the backend, even if the data may be irrelevant. Reversed first searches in Fallback, and if the search failed, it goes to the backend and deals with it.
With this whole scheme we had several problems. The most serious one is with an understanding of how prepared statements work in Cassandra. This problem is fixed in version 4.0, which has not yet been released, so I’ll tell you.
Cassandra is designed to connect millions of clients to it at the same time, and everyone is trying to prepare their prepared statements. Naturally, Cassandra does not prepare every prepared statement, otherwise it will run out of memory. It calculates the MD5 parameter based on text, key space, and query options. If she receives exactly the same request with exactly the same MD5, she takes the already prepared request. It already has information about metadata and how to handle it.
But there are version issues. We are releasing a new release, it successfully rolled migrations, added fields in types, and run prepared statements. They come back with the previous version of our state and metadata - with types without fields. At the time of reading the data, we are trying to write their new required columns, and are faced with the fact that they simply do not exist! Cassandra says that this is generally a different type that she does not know.
We dealt with this problem as follows: we added a unique text to each of our prepared requests .
We will not have millions of connected clients, but only one session for each node that holds several connections. For each prepare statement once. We assume that it’s okay if for each version of the application or for each start of the node a unique text is generated, which will obviously be in the text of our request.
We added a special field to trick him. When inserting, we write a constant in this field. It is unique for each launch or application version - this is configured in the library. When reading, we use this name as alias for the value we get. The request is exactly the same, we are still doing select value, but the text is different. Cassandra does not realize that this is the same request, computes another MD5 and prepares the request again with new metadata.
The second problem is the migration race . For example, we want to make several parallel migrations. Let's start some nodes and at the same time they will start calculations, they will run create tables, create types. This can lead to the fact that on each node or in each of the parallel threads everything will be successful and two tables seem to be created successfully. But inside Cassandra gets confused, and we will receive timeouts for writing and reading.
If we know that we must have Fallback migration, we migrate from one special node before release . Only then will we start all our nodes during the release. So we solved this problem.
The third problem is the lack of data in Fallback Cache . It may be that we “fullbacked” the method, it should store historical data for a year ago, but in reality we launched it yesterday.
The problem was solved by warming up . We used the Forced state and launched special nodes that will not communicate with real users. They will take all possible keys that we assume and will warm up the cache in a circle. Warming up is going so fast so as not to kill the backend with which we are reading.
If your architecture is fully consistent with the Reactive manifest, the components of the application scale indefinitely with increasing load independently of each other, and withstand the fall of any node - you know the answer. But if not, Oleg Nizhnikov ( Odomontois ) will tell how the scalability problem was solved at Tinkoff by building his painless Fallback Cache on Scala without rewriting the application.
Note. The article will have a minimum of Scala code and a maximum of general principles and ideas.
Unstable or slow backend
When interacting with the backend, the average application is fast. But the backend does the bulk of the work and grinds most of the data internally - more time is spent on it. Extra time is wasted waiting for a backend and DBMS response. Even if the application itself scales easily, this bottleneck does not scale at all. How to ease the load on the backend and solve the problem?
| Your service
| Backend
| |
| Net work time in each answer: (de) serialization, checks, logic, asynchrony costs
| 53 ms
| 785ms
|
| Waiting for backend and DBMS
| 3015 ms
| 1932 ms
|
| Number of nodes
| 32
| 2
|
| Summary answer
| 3070 ms
| 2702 ms
|
Embedded cache
The first idea is to take data to read, requests that receive data, and configure the cache at the level of each in-memory node.
The cache lives until the node restarts and stores only the last piece of data. If the application crashes and new users who have not been in the last hour, day, or week come in, the application cannot do anything about it.
Proxy
The second option is a proxy, which takes over part of the requests or modifies the application.
But in proxy, you cannot do all the work for the application itself.
Caching database
The third option is tricky when the part of the data that the backend returns can be put into storage for a long time. When they are needed, we show the client, even if they are no longer relevant. This is better than nothing.
Such a decision will be discussed.
Fallback cache
This is our library. It is embedded in the application and communicates with the backend. With minimal refinement, it analyzes the data structure, generates serialization formats and, with the help of the Circuit Breaker algorithm, increases fault tolerance. Effective serialization can be implemented in any language where types can be analyzed in advance if they are defined strictly enough.
Components
Our library looks something like this.
The left part is devoted to interacting with this repository, which includes two important components:
- the component that is responsible for the initialization process - preliminary actions with the DBMS before using Fallback Cache;
- automatic serialization generation module.
The right side is the general functionality that relates to Fallback.
How does it all work? There are queries in the middle of the application and intermediate types for storing state. This form expresses the data that we received from the backend for one or more requests. We send the parameters to our method, and we get the data from there. This data needs to be serialized somehow in order to be put into storage, so we wrap it in code. A separate module is responsible for this. We used the Circuit Breaker pattern.
Storage requirements
Long shelf life - 30-500 days . Some actions could take a long time, and all this time it is required to store data. Therefore, we want a storage that can store data for a long time. In-memory is not suitable for this.
Large data volume - 100 GB-20 TB . We want to store dozens of terabytes of data in the cache, and even more because of growth. Keeping all this in memory is inefficient - most of the data is not constantly requested. They lie for a long time, waiting for their user, who will come in and ask. In-memory does not fall under these requirements.
High data availability . Anything can happen to the service, but we want the DBMS to remain available all the time.
Low storage costs . We send additional data to the cache. As a result, overhead occurs. When implementing our solution, we want to minimize it.
Support for queries at intervals . Our database should have been able to pull out a piece of data not only in its entirety, but at intervals: a list of actions, a user's history for a certain period. Therefore, a pure key value is not suitable.
Assumptions
Requirements narrow the list of candidates. We assume that we have implemented everything else, and make the following assumptions, knowing why exactly we need Fallback Cache.
Data integrity between two different GET requests is not required . Therefore, if they display two different states that are not consistent with each other, we will put up with this.
Relevance and invalidation of data is not required . At the time of the request, it is assumed that we have the latest version that we are showing.
We send and receive data from the backend. The structure of this data is known in advance .
Storage selection
As alternatives, we considered three main options.
The first is Cassandra . Advantages: high availability, easy scalability and built-in serialization mechanism with the UDT collection.
UDT or User Defined Types , means some type. They allow you to efficiently stack structured types. Type fields are known in advance. These serialization fields are marked with separate tags as in Protocol Buffers. After reading this structure, on the basis of tags you can understand what kind of fields there are. Enough metadata to find out their name and type.
Another plus of Cassandra is that in addition to partition key it has an additional clustering key . This is a special key, due to which the data is arranged on one node. This allows you to implement an option such as interval queries.
Cassandra has been around for a relatively long time, there are many monitoring solutions for it , and one minus is the JVM . This is not the most productive option for platforms on which you can write a DBMS. The JVM has problems with garbage collection and overhead.
The second option is CouchBase . Advantages: data accessibility, scalability and Schemaless.
With CouchBase, you need to think less about serialization. This is both a plus and a minus - we do not need to control the data scheme. There are global indexes that allow you to run interval queries globally across a cluster.
CouchBase is a hybrid where Memcache is added to a usual DBMS - fast cache . It allows you to automatically cache all the data on the node - the hottest, with very high availability. Thanks to its cache, CouchBase can be fast if the same data is requested very often.
Schemaless and JSON can also be a minus. Data can be stored for so long that the application has time to change. In this case, the data structure that CouchBase is going to store and read will also change. The previous version may not be compatible. You will learn about this only when reading, and not when developing data, when it lies somewhere in production. We have to think about proper migration, and this is exactly what we do not want to do.
The third option is Tarantool . It is famous for its super speed. It has a wonderful LUA engine that allows you to write a bunch of logic that will execute right on the server on LuaJit.
On the other hand, this is a modified key value. Data is stored in tuples. We need to think for ourselves on the correct serialization, this is not always an obvious task. Tarantool also has a specific approach to scalability . What is wrong with him, we will discuss further.
Sharding / replication
Our application may need Sharding / Replication . Three repositories implement them differently.
Cassandra suggests a structure that is usually called a “ring”.
Many nodes are available. Each of them stores its data and data from the nearest nodes as replicas. If one drops out, the nodes next to it can serve part of its data until the dropout rises.
Sharding \ Replication is responsible for the same structure. To unpack into 10 pieces and Replication factor 3, 10 nodes are enough. Each of the nodes will store 2 replicas from the neighboring ones.
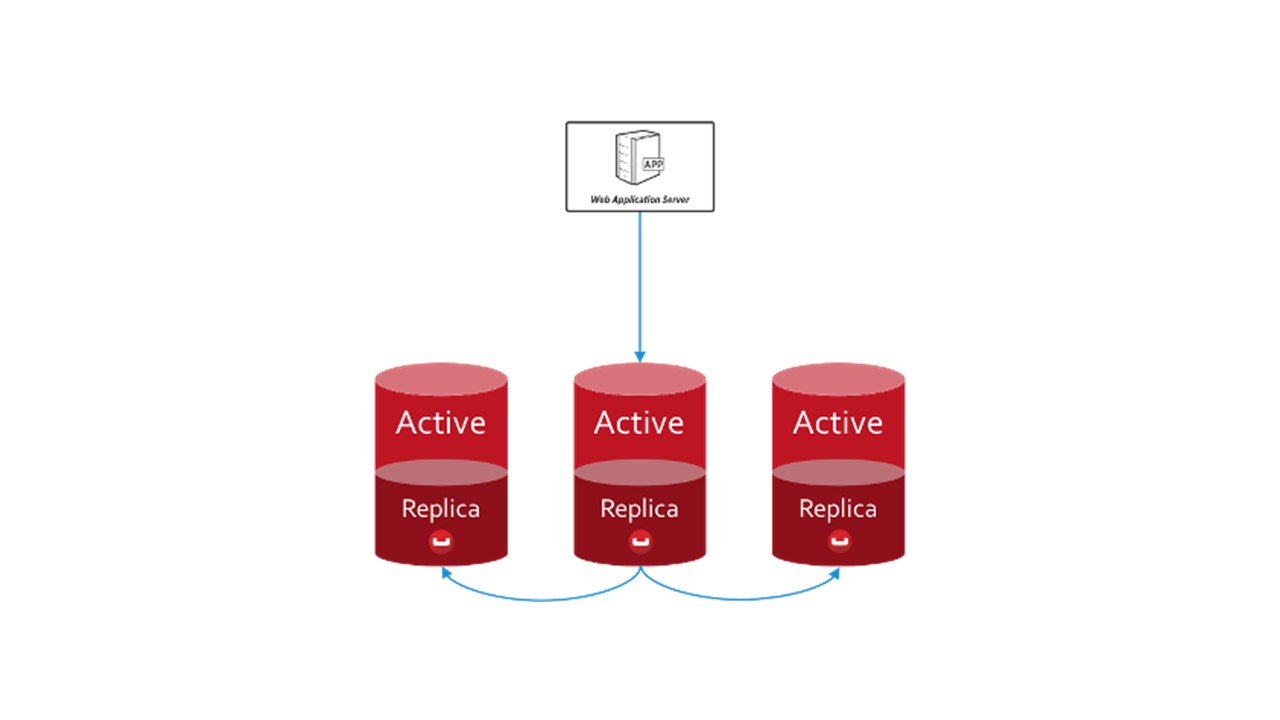
In CouchBase, the interaction structure between nodes is structured similarly:
- there is data that is marked as active, for which the node itself is responsible;
- There are replicas of neighboring nodes that CouchBase stores.
If one node drops out, the neighboring ones, shared, take responsibility for the maintenance of this part of the keys.
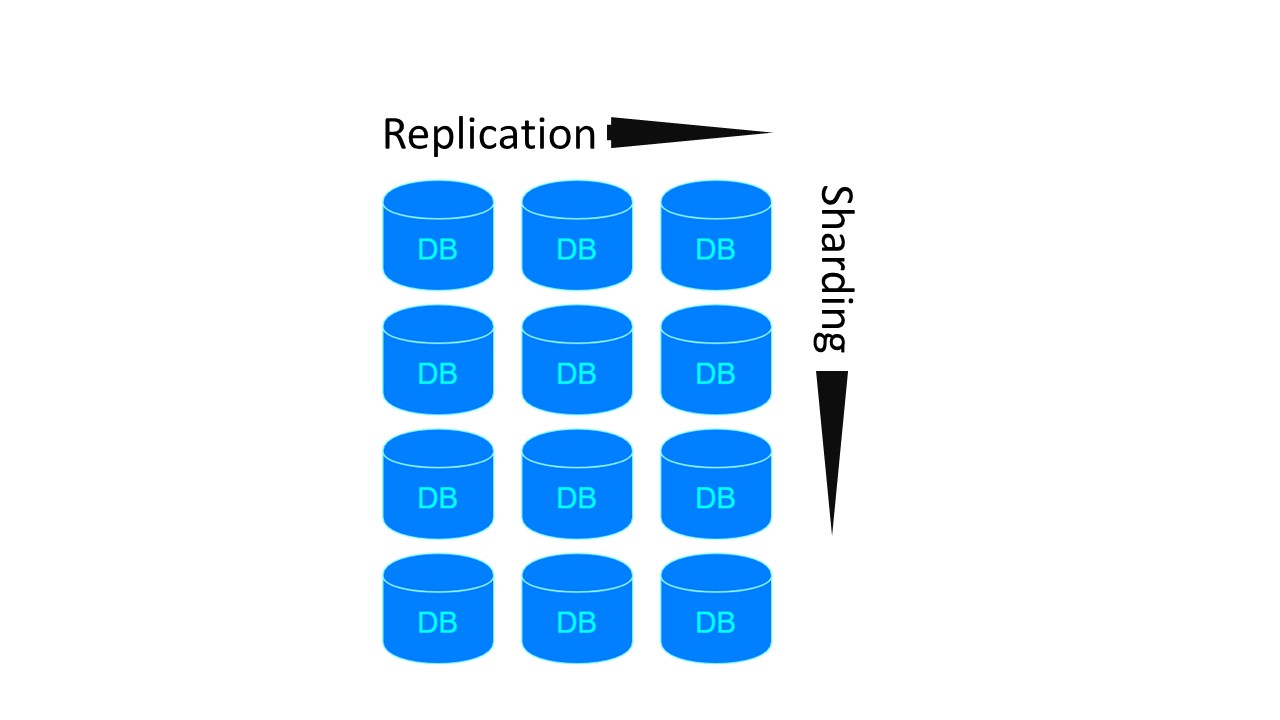
In Tarantool, the architecture is similar to MongoDB. But with a nuance: there are sharding groups that are replicated with each other.
For the previous two architectures, if we want to make 4 shards and Replication factor 3, 4 nodes are required. For Tarantool - 12! But the disadvantage is offset by the speed that Tarantool guarantees.
Cassandra
Optional modules for sharding in Tarantool appeared only recently. Therefore, we chose the Cassandra DBMS as the main candidate. Recall that we talked about its specific serialization.
Auto serialization
The SQL protocol assumes that you are fairly free to define a data schema.
You can use this as an advantage. For example, serialize data so that the long field names of our leafy structures are not stored every time in our values. In this case, we will have some metadata that describes the data device. UDTs themselves also tell which fields the labels and tags correspond to.
Therefore, automatically generated serialization takes place in approximately the same way. If we have one of the basic types that can match the type from the database one to one, we do that. A set of types Int, Long, String, Double is also in Cassandra.
| Application Data Type
| Data type in cassandra
|
| Primitive type
(Int, Long, String, Double, BigDecimal) | Primitive type
(int, biging, text, double, decimal) |
If an optional field is encountered in some structure, we do nothing extra. We indicate for him the type into which this field should turn. The structure will store null. If we find null in the structure at the deserialization level, we assume that this is not the value.
| Application Data Type
| Data type in cassandra
|
| Option [A]
| a
|
All collection types from the collection in Scala are converted to the list type. These are ordered collections that have an index matching element.
| Application Data Type
| Data type in cassandra
|
| Seq [A], List [A], Stream [A], Vector [A]
| frozen <list "a">
|
Unordered Set collections guarantee exactly one element with each value. For them, Cassandra also has a special set type.
| Application Data Type
| Data type in cassandra
|
| Set [A]
| frozen <set "a">
|
Most likely, we will have a lot of mapping (), especially with string keys. Cassandra has a special map type for them. It is also typed and has two type parameters. So that we can create an appropriate type for any key
| Application Data Type
| Data type in cassandra
|
| Map [K, V]
| frozen <map "k, v">
|
There are data types that we define ourselves in our application. In many languages they are called algebraic data types . They are defined by defining a named product of types, that is, a structure. We assign this structure to User Defined Type. Each field of the structure will correspond to one field in the UDT.
| Application Data Type
| Data type in cassandra
|
| Type Product: case class
| UDT
|
The second type is the algebraic sum of types . In this case, the type corresponds to several previously known subtypes or subspecies. Also, in a certain way, we assign a structure to it.
| Application Data Type
| Data type in cassandra
|
| Type Sum: sealed trait \ class
| UDT
|
Abstract Data Type translate to UDT
We have a structure, and we display it one to one - for each field we define the field in the created UDT in Cassandra:
case class Account ( id: Long, tags: List[String], user: User, finData: Option[FinData] ) create type account ( id bigint, tags: frozen<list<text>>, user frozen<user>, fin_data frozen<fin_data> )
Primitive types turn into primitive types. A reference to a type previously defined before that goes into frozen. This is a special wrapper in Cassandra, which means that you cannot read from this field piece by piece. The wrapper is “frozen” into this state. We can only read or save the user, or the list, as in the case of tags.
If we meet an optional field, then we discard this characteristic. We take only the data type corresponding to the type of field that will be. If we meet here non - the absence of a value - we will write null in the corresponding field. When reading, we will also take non-null correspondence.
If we meet a type that has several pre-known alternatives, then we also define a new data type in Cassandra. For each alternative, a field in our data type in UDT.
As a result, in this structure, only one of the fields at any given time will not be null. If you met some type of user, and it turned out to be an instance of a moderator in runtime, the moderator field will contain some value, the rest will be null. For admin - admin, the rest - null.
This allows you to encode the structure as follows: we have 4 optional fields, we guarantee that only one will be written from them. Cassandra uses only one tag to identify the presence of a particular field in the structure. Thanks to this, we get a storage structure without overhead.
In fact, in order to save the user type, if it is a moderator, it will take the same number of bytes that are required to store the moderator. Plus one byte to show which alternative is present here.
Initialization
Initialization is a preliminary procedure that must be completed before we can use our fallback.
How does this process work?
- On each node, we generate definitions of tables, types, and query texts based on the types that are presented.
- Read the current schema from the DBMS. In Cassandra, this is easy to do by simply connecting to it. When connected, in almost all drivers, the “session” object itself pumps out the key space metadata to which it is connected. Then you can see what they have.
- We go through the metadata, compare and verify that everything that we want to create is allowed and that incremental migration is possible.
- If everything is normal and initialization is possible, we perform the migration.
- We are preparing requests.
sealed trait User case class Anonymous extends User case class Registered extends User case class Moderator extends User case class Admin extends User create type user ( anonymous frozen<anonymous>, registered frozen<registered>, moderator frozen<moderator>, admin frozen<admin> )
It happens like this. We have types , tables, and queries . Types depend on other types, those on others. Tables depend on these types. Queries already depend on the tables from which they read data. Initialization will check all these dependencies and create in the DBMS everything that it can create, according to certain rules.
Type Migration
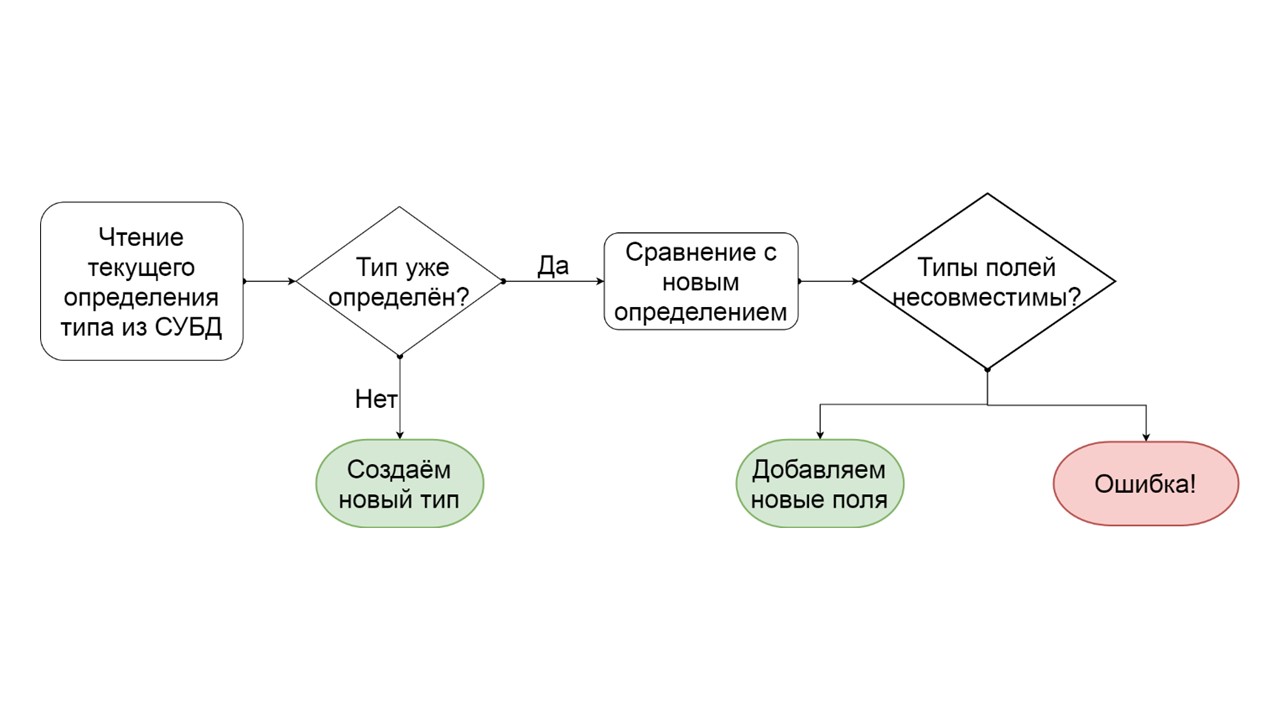
How to determine that a type can be incrementally migrated?
- We read how this type is defined in the DBMS.
- If there is no such type, that is, we came up with a new one - we create it.
- If such a type already exists, we are trying to compare field by field the existing definition with the one we want to give to this type.
- If it turns out that we want to add just a few fields that no longer exist, we do that. Create a list of mutating ALTER TYPE operations, and start them.
- If it turns out that we have some kind of field that was of a different type - we generate an error. For example, there was a list - it became a map, or there was a link to one user-defined type, and we are trying to make it different.
The developer can see this error even before he starts the functionality on production. I suppose that the exact same data scheme is in his development environment. He sees that he somehow created a non-migrable data schema, and to avoid these errors, he can override the automatically generated serialization, add options, rename fields or all types and tables as a whole.
Initialization: Types
Imagine that there are several types of definitions:
case class Product (id: Long, name: ctring, price: BigDecimal) case class UserOffers (valiDate: LocalDate, offers: Seq[Products]) case class UserProducts (user User, products: Map[Date, Product]) case class UserInfo: UserOffers, products: UserProducts)
Case class - a class that contains a set of fields. This is an analogue of struct in Rust.
We generate approximately such data definitions for each of the 4 types - what we want to eventually crank up:
CREATE TYPE product (id bigint, name text, price decimal); CREATE TYPE user_offers (valid_date date, offers frozen<list<frozen<offer>>>); CREATE TYPE user_products (user frozen<user>, products frozen<map<date, frozen<product>>); CREATE TYPE user_jnfo (offers: frozen<user_offers>, products: frozen<user_products>);
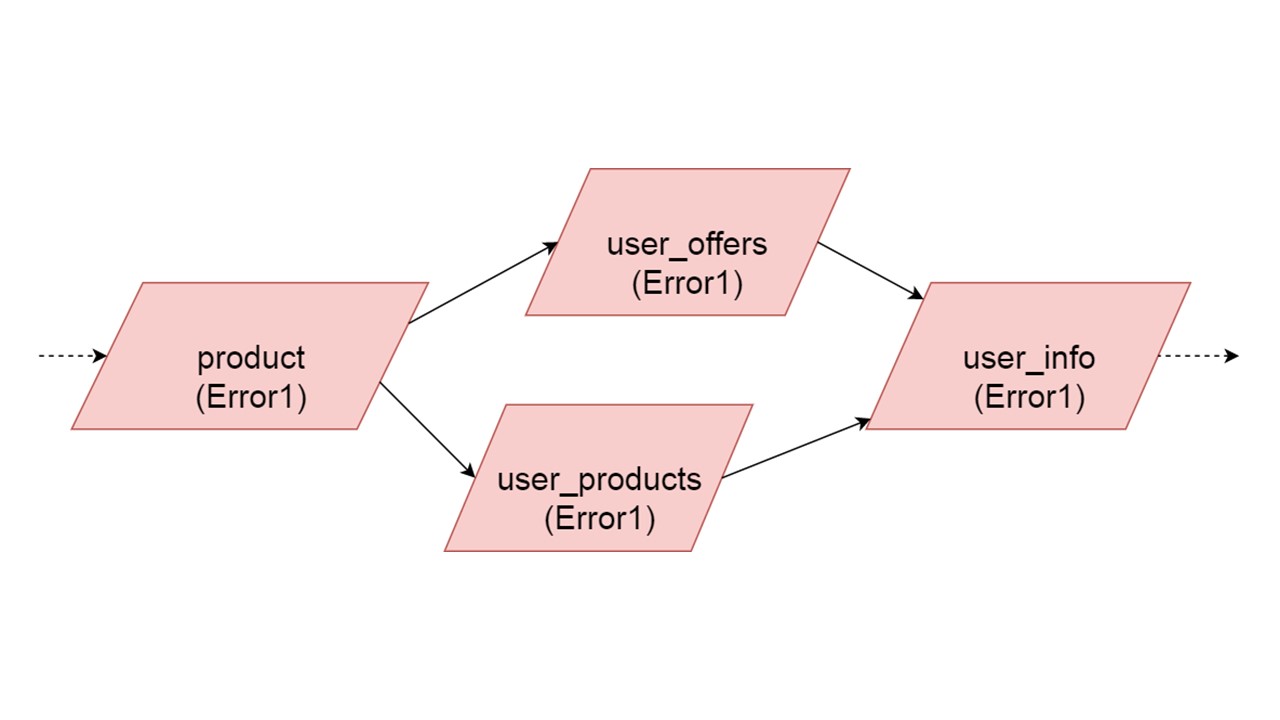
The type of user_offers depends on the type of offer, user_products depends on the type of product, user_info on the second and third types.
We have such a dependency between types, and we want to initialize it correctly. The diagram shows that we will initialize user_offers and user_products in parallel. This does not mean that we will launch two parallel operations. No, we start all statements, all analyzes sequentially, so as not to accidentally create the same type in two parallel threads.
But there is some parallelism at the level of error correction. If an error occurs in the type, everything that depends on it will pull the original error.
If an error is generated by any of the parallel branches, everything that depends on normally migrated data will be generated without an error. If there are further definitions of tables, prepared statements from them, we can safely initialize this part of our Fallback Cache. Communication will be lost only with some part of the backends or with some functionality. The remainders are initialized.
It may happen that two types that are simultaneously initialized generate different errors. In this case, functionality that depends on both types will give a summing type of error. The developer, initializing his Fallback in the development environment, will receive a complete list of data with errors. Naturally, he can fix it here and get the error further. But it will not be such that one completely independent branch closes the errors that we could get, regardless of this branch.
Initialization: Tables
Next we create the tables.
def getOffer (user: User, number: Long): Future[OfferData] create table get_offer( key frozen<tuple<frozen<user>, bigint>>PRIMARY KEY, value frozen<friend_data> )
Such a request can directly launch a REST or SOAP request, create additional operations inside, or even run several requests. It all depends on your code - how you organized the code will be so. Fallback absolutely does not analyze what happens inside the method on which you hang such a stub.
The method must be asynchronous, because Fallback is the same.
In Scala, this is tagged with a special type of Future. This means that the result will return someday. When exactly - it is unknown: maybe right away, or maybe not.
Create a table for the method. The key in the table is a tuple of all types that correspond to the parameters of this method. The non-key value is the result, which is returned asynchronously. For each such table, we prepare two parametric queries in advance: insert data and read data.
insert into get_offer(key, value) values (?key, ?value); select value from get_offer where key = ?key;
Everything is ready to interact with the DBMS. It remains to find out how we will read data from Fallback.
Circuit breaker
Here, responsibility passes into the zone of the famous Circuit Breaker pattern.
A typical Circuit Breaker includes three states.
Closed - The default closed state that closes our backend. The principle is that we read the data first from the backend, and only if we could not get it, go to Fallback. If we managed to get the data, we don’t look in Fallback, but save the data in it, and nothing happens.
If the problems go one after another, we assume that the backend is lying. In order not to spam it with a gigantic amount of new requests, we switch to Open - in a torn state . In it, we are trying to read data only from Fallback. If it doesn’t work out, we immediately return an error, and don’t even touch the main backend.
After a while, we decide to find out if the backend woke up and try to reset the Half-Open state - a short-lived state . His life span is one request.
In a short-lived state, we choose to close again or open for an even longer time. If in the Half-Open state we successfully reach Fallback and receive the following request, we switch to the Closed state. If we couldn’t get through, we return to Open, but for a long time.
We added two additional states that are clearly not related to the Circuit Breaker circuit:
- Forced - forcefully closed state;
- Reversed - priority for open, closed state is inverted.
Let's see what they do.
The principle of operation of states
Closed The scheme is large, but it is enough to understand the general principle from it. We keep Fallback in parallel with how we return the result from the backend, if everything went well there and read from Fallback. If it’s bad everywhere, we return the error priority.
Of the two errors, select the backend error.
If there are no errors, we increment the counter in parallel with this and switch to the open state when there are too many requests.
Open The open state of Open is simpler - we constantly read from Fallback, no matter what happens, and after a while we try to switch to the Half-Open state.
Half-open . The state in structure resembles Closed. The difference is that in the case of a successful answer, we go into a closed state. In case of failure - we return back to the open with an extended interval.
Forced is an extra state for warming up the cache . When we fill it with data, it never tries to read from Fallback, but only adds records.
Reversed is a second far-fetched state . It works like a persistent cache. We turn on the state when we want to permanently remove the load from the backend, even if the data may be irrelevant. Reversed first searches in Fallback, and if the search failed, it goes to the backend and deals with it.
Problems
With this whole scheme we had several problems. The most serious one is with an understanding of how prepared statements work in Cassandra. This problem is fixed in version 4.0, which has not yet been released, so I’ll tell you.
Cassandra is designed to connect millions of clients to it at the same time, and everyone is trying to prepare their prepared statements. Naturally, Cassandra does not prepare every prepared statement, otherwise it will run out of memory. It calculates the MD5 parameter based on text, key space, and query options. If she receives exactly the same request with exactly the same MD5, she takes the already prepared request. It already has information about metadata and how to handle it.
But there are version issues. We are releasing a new release, it successfully rolled migrations, added fields in types, and run prepared statements. They come back with the previous version of our state and metadata - with types without fields. At the time of reading the data, we are trying to write their new required columns, and are faced with the fact that they simply do not exist! Cassandra says that this is generally a different type that she does not know.
We dealt with this problem as follows: we added a unique text to each of our prepared requests .
create table get_offer( key frozen<tuple<frozen<user>, bigint>> PRIMARY KEY, value frozen<friend_data>, query_tag text ) insert into get_offer (key, value, query_tag) values (?key, ?value, 'tag_123'); select value as tag_123 from get_offer where key = ?key;
We will not have millions of connected clients, but only one session for each node that holds several connections. For each prepare statement once. We assume that it’s okay if for each version of the application or for each start of the node a unique text is generated, which will obviously be in the text of our request.
We added a special field to trick him. When inserting, we write a constant in this field. It is unique for each launch or application version - this is configured in the library. When reading, we use this name as alias for the value we get. The request is exactly the same, we are still doing select value, but the text is different. Cassandra does not realize that this is the same request, computes another MD5 and prepares the request again with new metadata.
The second problem is the migration race . For example, we want to make several parallel migrations. Let's start some nodes and at the same time they will start calculations, they will run create tables, create types. This can lead to the fact that on each node or in each of the parallel threads everything will be successful and two tables seem to be created successfully. But inside Cassandra gets confused, and we will receive timeouts for writing and reading.
You can break Cassandra if you try to parallel processes from multiple threads or from multiple nodes.
If we know that we must have Fallback migration, we migrate from one special node before release . Only then will we start all our nodes during the release. So we solved this problem.
The third problem is the lack of data in Fallback Cache . It may be that we “fullbacked” the method, it should store historical data for a year ago, but in reality we launched it yesterday.
The problem was solved by warming up . We used the Forced state and launched special nodes that will not communicate with real users. They will take all possible keys that we assume and will warm up the cache in a circle. Warming up is going so fast so as not to kill the backend with which we are reading.
Scaling applications, backend, big data and frontend - Scala is suitable for all this. On November 26th we are holding a professional conference for Scala developers . Styles, approaches, dozens of solutions for the same problem, the nuances of using old and proven approaches, the practice of functional programming, the theory of radical functional cosmonautics - we'll talk about all this at the conference. Apply for a report if you want to share your Scala experience before September 26, or book your tickets .
All Articles