Tarantool Data Grid Architecture and Features

In 2017, we won the competition for the development of the transactional core of Alfa-Bank's investment business and started working (at HighLoad ++ 2018 , Vladimir Drynkin, Head of the Transactional Core of the Investment Business of Alfa Bank, spoke on the core of the investment business). This system was to aggregate transaction data from various sources in various formats, bring the data to a unified form, save it and provide access to them.
In the process of development, the system evolved and became functional, and at some point we realized that we were crystallizing something much more than just application software designed to solve a strictly defined range of tasks: we got a system for building distributed applications with persistent storage . Our experience formed the basis of a new product - Tarantool Data Grid (TDG).
I want to talk about TDG architecture and the solutions that we came to during the development process, introduce you to the basic functionality and show how our product can become the basis for building complete solutions.
Architecturally, we divided the system into separate roles , each of which is responsible for solving a certain range of tasks. One running instance of an application implements one or more types of roles. A cluster can have several roles of the same type:
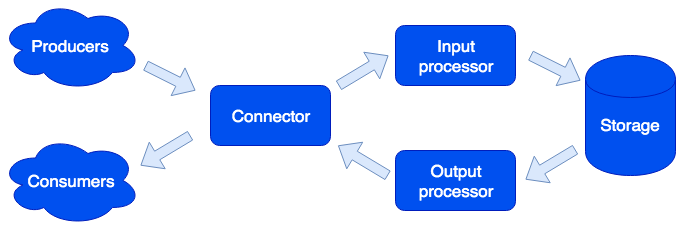
Connector
Connector is responsible for communication with the outside world; its task is to accept the request, parse it, and if it succeeds, then send the data for processing to the input processor. We support the formats HTTP, SOAP, Kafka, FIX. The architecture allows you to simply add support for new formats, IBM MQ support is coming soon. If the request parsing failed, connector will return an error; otherwise, he will reply that the request was processed successfully, even if an error occurred during its further processing. This is done on purpose, in order to work with systems that do not know how to repeat requests - or vice versa, do it too aggressively. In order not to lose data, the repair queue is used: the object first enters it and only after successful processing is deleted from it. The administrator can receive notifications about objects remaining in the repair queue, and after eliminating a software error or hardware failure, try again.
Input processor
Input processor classifies the received data by characteristic and calls suitable handlers. Handlers are Lua code that runs in the sandbox, so they cannot affect the functioning of the system. At this stage, the data can be brought to the desired form, and if necessary, run an arbitrary number of tasks that can implement the necessary logic. For example, in the MDM (Master Data Management) product, built on the Tarantool Data Grid, when adding a new user, in order not to slow down the processing of the request, we start the creation of a gold record as a separate task. The sandbox supports requests for reading, changing, and adding data; it allows you to perform some function on all roles such as storage and aggregate the result (map / reduce).
Handlers can be described in files:
sum.lua local x, y = unpack(...) return x + y
And then, declared in the configuration:
functions: sum: { __file: sum.lua }
Why Lua? Lua is a very simple language. Based on our experience, a couple of hours after meeting him, people begin to write code that solves their problem. And these are not only professional developers, but for example, analysts. In addition, thanks to the jit compiler, Lua is very fast.
Storage
Storage stores persistent data. Before saving, the data is validated for compliance with the data schema. To describe the scheme, we use the extended Apache Avro format. Example:
{ "name": "User", "type": "record", "logicalType": "Aggregate", "fields": [ { "name": "id", "type": "string"}, {"name": "first_name", "type": "string"}, {"name": "last_name", "type": "string"} ], "indexes": ["id"] }
Based on this description, DDL (Data Definition Language) for Tarantula DBMS and GraphQL schema for data access are automatically generated.
Asynchronous data replication is supported (plans to add synchronous).
Output processor
Sometimes it is necessary to notify external consumers about the arrival of new data, for this there is the role of Output processor. After saving the data, they can be transferred to the appropriate handler (for example, to bring them to the form that the consumer requires) - and then transferred to the connector for sending. The repair queue is also used here: if no one has accepted the object, the administrator can try again later.
Scaling
The roles of the connector, input processor and output processor are stateless, which allows us to scale the system horizontally, simply adding new instances of the application with the included role of the desired type. For horizontal storage scaling, an approach is taken to organize a cluster using virtual buckets. After adding a new server, part of the bucket from the old servers in the background moves to the new server; This happens transparently to users and does not affect the operation of the entire system.
Data Properties
Objects can be very large and contain other objects. We ensure atomicity of adding and updating data, saving the object with all the dependencies on one virtual bucket. This eliminates the "smearing" of the object across multiple physical servers.
Versioning is supported: each update of the object creates a new version, and we can always make a time slice and see how the world looked then. For data that does not need a long history, we can limit the number of versions or even store only one - the last - that is, actually disable versioning for a certain type. You can also limit the history by time: for example, delete all objects of a certain type older than 1 year. Archiving is also supported: we can unload objects older than the specified time, freeing up space in the cluster.
Tasks
Of the interesting features, it is worth noting the ability to run tasks on a schedule, at the request of the user, or programmatically from the sandbox:

Here we see another role - runner. This role has no state, and if necessary, additional application instances with this role can be added to the cluster. The responsibility of the runner is to complete the tasks. As stated, the creation of new tasks from the sandbox is possible; they are queued on storage and then run on the runner. This type of task is called Job. We also have a type of task called Task - these are user-defined tasks that are scheduled to run (using the cron syntax) or on demand. To run and track such tasks, we have a convenient task manager. In order for this functionality to be available, you must enable the scheduler role; this role has a state, therefore it does not scale, which, however, is not required; however, she, like all other roles, can have a replica that starts to work if the master suddenly refuses.
Logger
Another role is called logger. It collects logs from all cluster members and provides an interface for uploading and viewing them through the web interface.
Services
It is worth mentioning that the system makes it easy to create services. In the configuration file, you can specify which requests should be sent to the user-written handler running in the sandbox. In this handler it is possible, for example, to execute some kind of analytical query and return the result.
The service is described in the configuration file:
services: sum: doc: "adds two numbers" function: sum return_type: int args: x: int y: int
The GraphQL API is automatically generated and the service becomes available for calling:
query { sum(x: 1, y: 2) }
This will call the
sum
handler, which will return the result:
3
Query Profiling and Metrics
To understand the system and query profiling, we implemented support for the OpenTracing protocol. The system can, on demand, send information to tools that support this protocol, for example, Zipkin, which will help to understand how the request was executed:
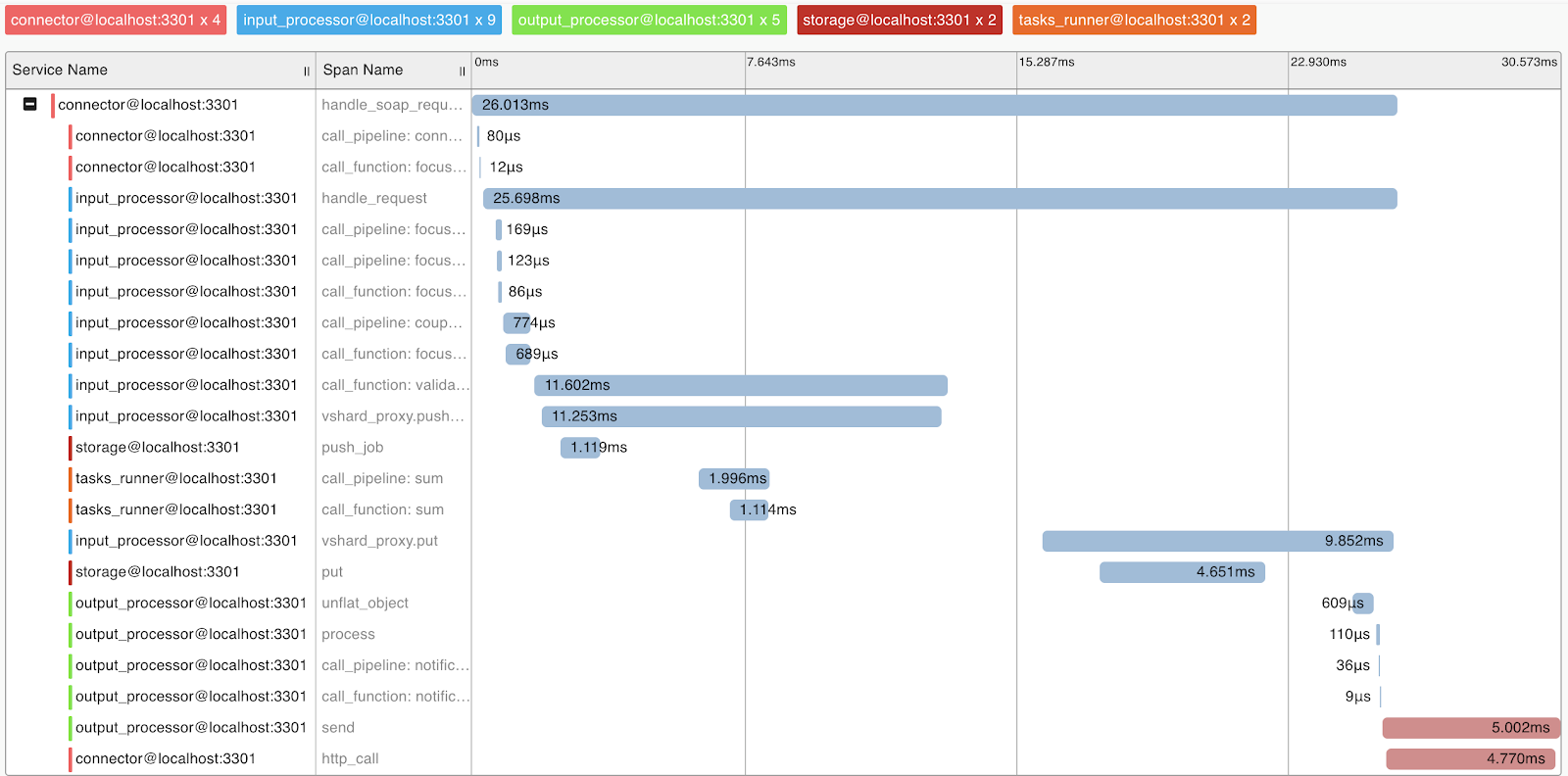
Naturally, the system provides internal metrics that can be collected using Prometheus and visualized using Grafana.
Deploy
Tarantool Data Grid can be deployed from RPM packages or archive, using the utility from the delivery or Ansible, there is also support for Kubernetes ( Tarantool Kubernetes Operator ).
An application that implements business logic (configuration, processors) is loaded into the Tarantool Data Grid cluster as an archive via the UI or using a script through the API provided by us.
Application examples
What applications can I create with the Tarantool Data Grid? In fact, most business tasks are somehow related to processing the data stream, storing and accessing it. Therefore, if you have large streams of data that need to be stored securely and have access to them, then our product can save you a lot of time in development and focus on your business logic.
For example, we want to collect information about the real estate market in order to subsequently, for example, have information about the best offers. In this case, we distinguish the following tasks:
- Robots collecting information from open sources - these will be our data sources. You can solve this problem using ready-made solutions or writing code in any language.
- Next, the Tarantool Data Grid will accept and save the data. If the format of the data from different sources is different, then you can write code in the Lua language, which will lead to the conversion to a single format. At the pre-processing stage, you can also, for example, filter recurring offers or additionally update information on agents operating in the market in the database.
- Now you already have a scalable solution in the cluster, which can be filled with data and make data samples. Then you can implement new functionality, for example, write a service that will query the data and issue the most profitable offer in a day — this will require a few lines in the configuration file and a bit of Lua code.
What's next?
Our priority is to increase the development convenience with the Tarantool Data Grid . For example, this is an IDE with support for profiling and debugging sandboxed handlers.
We also pay great attention to security issues. Right now, we are undergoing certification by the FSTEC of Russia to confirm the high level of security and meet the requirements for certification of software products used in personal data information systems and state information systems.
All Articles