Multilingual speech synthesis with cloning
Although neural networks began to be used for speech synthesis not so long ago ( for example ), they have already managed to overtake the classical approaches and each year they experience newer and newer tasks.
For example, a couple of months ago there was an implementation of speech synthesis with voice cloning Real-Time-Voice-Cloning . Let's try to figure out what it consists of and realize our multilingual (Russian-English) phoneme model.
Structure
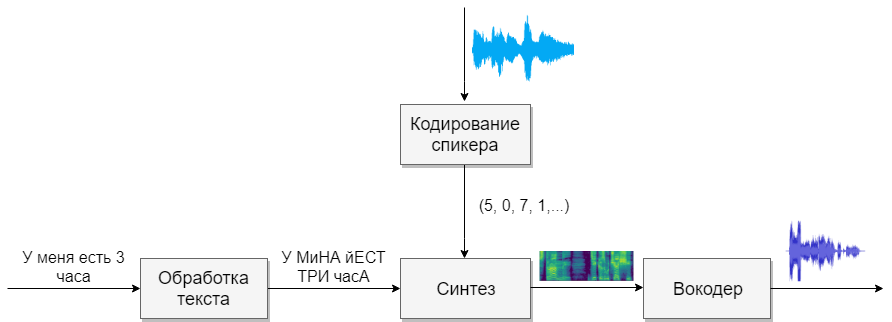
Our model will consist of four neural networks. The first will convert the text into phonemes (g2p), the second will convert the speech we want to clone into a vector of signs (numbers). Third - based on the outputs of the first two, Mel spectrograms will be synthesized. And finally, the fourth will receive sound from spectrograms.
Datasets
This model needs a lot of speech. Below are the bases that will help with this.
| Name | Language | Link | Comments | My link | Comments |
|---|---|---|---|---|---|
| Dictionary of phonemes | En ru | En ru | link | Combined Russian and English phoneme dictionary | |
| Libripepeech | En | link | 300 votes, 360 hours of pure speech | ||
| Voxceleb | En | link | 7000 votes, many hours of bad sound | ||
| M-AILABS | Ru | link | 3 votes, 46 hours of pure speech | ||
| open_tts, open_stt | Ru | open_tts , open_stt | many voices, many hours of bad sound | link | I cleaned 4 hours of speech of one speaker. Corrected annotation, divided into segments up to 7 seconds |
| Voxforge + audiobook | Ru | link | many votes, 25h of different quality | link | I chose good files. Broke into segments. Added audiobooks from the Internet. It turned out 200 speakers in a couple of minutes for each |
| RUSLAN | Ru | link | One voice, 40 hours of pure speech | link | Recoded at 16kHz |
| Mozilla | Ru | link | 50 votes, 30 hours normal quality | link | Recoded at 16kHz, scattered different users into folders |
| Russian Single | Ru | link | One voice, 9 hours of pure speech | link |
Word processing
The first task will be text processing. Imagine the text in the form in which it will be further voiced. We will represent numbers in words, and we will open abbreviations. Read more in the article on synthesis . This is a difficult task, so suppose that we have already processed text (in the databases above it has been processed).
The next question to be asked is whether to use grapheme or phoneme notation. For a monophonic and monolingual voice, a letter model is also suitable. If you want to work with a multi-voice multilingual model, then I advise you to use transcription (Google too ).
G2p
For the Russian language, there is an implementation called russian_g2p . It is built on the rules of the Russian language and copes well with the task, but has disadvantages. Not stresses all words, and also not suitable for a multilingual model. Therefore, take the dictionary created by her, add the dictionary for the English language and feed the neural network (for example, 1 , 2 )
Before you train the network, you should consider what sounds from different languages sound similar, and you can select one character for them, and for which it is impossible. The more sounds there are, the more difficult the model is to learn, and if there are too few of them, then the model will have an accent. Remember to emphasize individual characters with stressed vowels. For English, secondary stress plays a minor role, and I would not highlight it.
Speaker Coding
The network is similar to the task of identifying a user by voice. At the output, different users get different vectors with numbers. I suggest using the implementation of CorentinJ itself, which is based on the article . The model is a three-layer LSTM with 768 nodes, followed by a fully-connected layer of 256 neurons, giving a vector of 256 numbers.
Experience has shown that a network trained in English speaks well with Russian. This greatly simplifies life, as training requires a lot of data. I recommend taking an already trained model and retraining in English from VoxCeleb and LibriSpeech, as well as all Russian speech that you find. The encoder does not need a text annotation of speech fragments.
Workout
- Run
python encoder_preprocess.py <datasets_root>
to process the data - Run "visdom" in a separate terminal.
- Run
python encoder_train.py my_run <datasets_root>
to train the encoder
Synthesis
Let's move on to the synthesis. The models I know do not get sound directly from the text, because it is difficult (too much data). First, the text produces sound in spectral form, and only then the fourth network will translate into a familiar voice. Therefore, we first understand how the spectral form is associated with the voice. It’s easier to figure out the inverse problem of how to get a spectrogram from sound.
The sound is divided into segments of 25 ms in increments of 10 ms (the default in most models). Then, using the Fourier transform for each piece, the spectrum is calculated (harmonic oscillations, the sum of which gives the original signal) and presented in the form of a graph, where the vertical strip is the spectrum of one segment (in frequency), and in the horizontal - a sequence of segments (in time). This graph is called a spectrogram. If the frequency is encoded nonlinearly (the lower frequencies are better than the upper ones), then the vertical scale will change (necessary to reduce the data), then this graph is called the Mel spectrogram. This is how the human hearing is arranged, that we hear a slight deviation at the lower frequencies better than at the higher ones, therefore the sound quality will not suffer
There are several good spectrogram synthesis implementations such as Tacotron 2 and Deepvoice 3 . Each of these models has its own implementations, for example 1 , 2 , 3 , 4 . We will use (like CorentinJ) the Tacotron model from Rayhane-mamah.
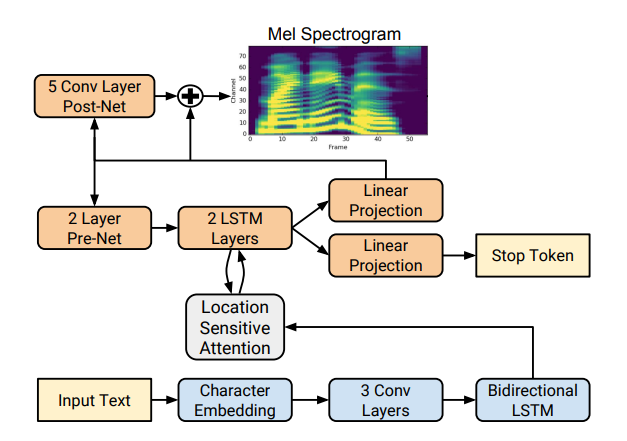
Tacotron is based on the seq2seq network with an attention mechanism. Read the details in the article .
Workout
Do not forget to edit utils / symbols.py if you synthesize not only English speech, hparams.p, but also preprocess.py.
Synthesis requires a lot of clean, well-marked sound from different speakers. Here a foreign language will not help.
- Run
python synthesizer_preprocess_audio.py <datasets_root>
to create processed sound and spectrograms - Run
python synthesizer_preprocess_embeds.py <datasets_root>
to encode the sound (get the signs of a voice) - Run
python synthesizer_train.py my_run <datasets_root>
to train the synthesizer
Vocoder
Now it remains only to convert the spectrograms to sound. For this, the last network is the vocoder. The question arises, if spectrograms are obtained from sound using the Fourier transform, is it possible to obtain sound again using the inverse transformation? The answer is yes and no. The harmonic oscillations that make up the original signal contain both amplitude and phase, and our spectrograms contain information only about amplitude (for the sake of reducing parameters and working with spectrograms), so if we do the inverse Fourier transform, we get a bad sound.
To solve this problem, they invented a fast Griffin-Lim algorithm. He does the inverse Fourier transform of the spectrogram, getting a "bad" sound. Then he makes a direct conversion of this sound and receives a spectrum that already contains a little information about the phase, and the amplitude does not change in the process. Next, the inverse transformation is taken again and a cleaner sound is obtained. Unfortunately, the quality of speech generated by such an algorithm leaves much to be desired.
It was replaced by neural vocoders such as WaveNet , WaveRNN , WaveGlow and others. CorentinJ used the WaveRNN model by fatchord

For data preprocessing, two approaches are used. Either get spectrograms from sound (using the Fourier transform), or from text (using the synthesis model). Google recommends a second approach.
Workout
- Run
python vocoder_preprocess.py <datasets_root>
to synthesize spectrograms - Run
python vocoder_train.py <datasets_root>
for vocoder
Total
We got a model of multilingual speech synthesis that can clone a voice.
Run toolbox: python demo_toolbox.py -d <datasets_root>
Examples can be heard here
Tips and conclusions
- Need a lot of data (> 1000 votes,> 1000 hours)
- The speed of operation is comparable with real time only in the synthesis of at least 4 sentences
- For the encoder, use the pre-trained model for the English language, slightly retraining. She is doing well
- A synthesizer trained on "clean" data works better, but clones worse than one who trained on a larger volume, but dirty data
- The model works well only on the data on which I studied
You can synthesize your voice online using colab , or see my implementation on github and download my weights .
All Articles