How discomfort helps us improve the development process.

I am a team leader and my task is to ensure the productive work of the team. This is not easy, since there is no ready-made recipe for success. Of course, there are recognized methodologies: Agile , Lean , Value Stream Mapping . They give common guidelines and values, which is already not bad, but these are just guidelines. And with specific solutions, be kind, turn yourself. That's why you and the team leader.
In the article I will tell how the team and I gradually formed and now regularly refine the approach to effective work. The key point is that the selected tools are really accepted by the whole team and have taken root in the work. This gives hope that the approach is useful.
A bit of context
At True Engineering, we are engaged in enterprise development. We make a huge, multi-year product in which many teams participate. Specifically, our team consists of seven people: four developers, one team-tech leader (writes code and a lot), one QA, one PM. The product the team is working on is two years old. The technical condition - through the efforts of the entire team - is close to exemplary.
Discomfort as a diagnostic tool
To find and recognize problems in the team, we use a fairly simple tool - the discomfort of the participants.
This, of course, is not about the situation when one person is air-conditioned and another is hot. I am talking about failures in the normal flow of work.
For example, the release went crookedly, although each individually did its job well. Or stabilization has been going on for two weeks now and the team is tearing, although we ourselves made assessments and no one bothered us to do well. Or the business did not get what it expected.
How to act in a similar situation:
- Stop the panic and realize why right now we are uncomfortable.
- Get to the bottom of the root cause. For example, using the Five Why technique or just common sense.
- Decide how to treat the problem. Guidelines for choosing the right solution will be discussed at the end of the article. Here I note a fundamentally important point: we use discomfort to diagnose problems, but this does not mean that the guideline for choosing solutions is to achieve comfort. Remember the main reason for your existence as a team - business value. Nobody needs a happy team that does not bring results.
- After a while, conduct a retrospective. If the decision did not help, we return to paragraph 1 with a new understanding. If it helps, we automate or add to the list of principles for future beginners. No control is needed anymore, the participants themselves will take the approach to work if it is really good.
The described algorithm is simple, but the specifics are not enough. Next, I will describe the principles that we have deduced using this approach. So that the article does not turn into a memoir, I will describe only the result obtained, and not the whole story from awareness of pain to its elimination.
The principles on which we build the process
1. We constantly create and shorten feedback loops
All human interaction with the outside world is built on feedback, without it it is impossible to verify the correctness of the performed action. Imagine what our life would be like if we didn’t feel pain jumping from a four-meter height or grabbing a red-hot teapot.
In development, code completion can serve as an example of a good, short feedback loop - it tells us about the correctness of the action right at the time of code entry.
Now an example of the absence of a feedback loop: we know about the problem with users, but we can’t reproduce it, we don’t have logs, there is no way to quickly roll out the fix and we don’t even know which version is currently on the prod. You will not wish the enemy.
Each action in the development process can and should give feedback: build, lint, passed self-tests, conducted testing, a test session with the business, successful deploy, monitoring prod - all these are ways to detect errors and adjust their further actions.
It is also worth noting that the cost of error increases as you move forward. If we released a production bug on production that spoils the data, then the task is not only to fix it, but also to restore the data (if at all possible). The cost of late elimination of such an error is very high, not to mention the consequences for the business.
Therefore, the presence of a large number of fast and informative feedback loops is vital.
Below are the loops that we consciously support and shorten if possible. I guess most of you know. But do you really have them and work?
- The ability to run and run a project locally.
- Designed in accordance with the principle of Fail Fast .
- Fast, informative CI build.
- Constant code review and work with code through pull requests.
- Availability of autotests. Tests are fast, stable, informative error messages.
- Automatic deployment, because manual will be performed less frequently.
- Frequent releases instead of accumulating and releasing a version a week after the completion of tasks.
- Informative logs, monitoring, diagnostic tools. Access to them from the whole team.
- The ability to filter and graphical visualization of logs.
- Continuous monitoring of the technical and functional indicators of the system as part of everyday work.
- Empirical study of the system - Google Analytics, analysis of the data accumulated in the system.
- Storing data change history instead of final state, if applicable.
- Tight, joint work of Dev, Ops, QA, business instead of “throwing over the fence” the results of the previous stage.
- Conducting regular retrospectives both within the team and with the business.
- Regular business feedback. Even better is the feedback from the end user.
- The ability to observe the work of users "in the fields."
- The ability to observe the user who sees your system for the first time.
In general, the feedback itself must be eye-catching. Like, for example, a broken build.
What is noteworthy, sometimes a very small change is enough for a radical improvement.
For example, you write logs in ELK . They are structured, analyzed, publicly available - everything is fine. But how often does the developer drop by during debugging? Most probably not.
If messages of warning level and higher are displayed directly in the IDE, then there is a chance to notice, for example, sagging query execution time. Even if it is not related to the current task. There is a chance to notice the problem earlier, and the cost of fixing it will be lower.
2. Any activity leaves public artifacts
Artifacts should be publicly available. And useful.
Thanks to this principle, we minimize the bus factor , provide a unified understanding of the situation, work (and fakapim) consciously, constantly making conclusions.
Some practices are obvious and generally accepted: informative messages of commits, connection of commits with tasks, description of How To Test, Definition of Done.
There are less obvious points:
- You can’t “just screw it up,” the failure must be realized. If the analysis reveals poorly thought out requirements, then the deliberate refinement will become an artifact for all. If the problem is the architecture of the system, the artifact will be the described technical duty with a clear term for taking into work.
- The amount of knowledge in the mail, instant messengers, heads should be minimal. All refinements are reflected in the knowledge base or in the task tracker. So, when the tester accepts the task, the changing requirements for him will not be news. When a business accepts a result, everyone understands what they should get. This state turns the work into a continuous stream. Provide it (find out the details, update the knowledge base and description of tasks) - the task of each participant in the process.
- The test results are not just “I checked, everything is ok”, but a publicly accessible list of passed test cases, which was compiled and discussed before testing, and not during or after. The list can be studied and supplemented by each participant in the process.
3. We respect each other's right to concentrated work
The importance of work in the stream and the consequences of interruption , I believe, are already well known. Therefore, I will not dwell on the problem in detail, but I will immediately turn to our practices.
- Headphones are only encouraged.
- Working communication is asynchronous. Do not distract your colleague with a small question, ask him in the task tracker (see the section on publicly available artifacts).
- Sometimes things happen that interrupt the normal mode of operation: an accident at the prod, incomprehensible requirements for a task already taken into work. A signal can be a noisy discussion in the office, in which three or more people participate. If this situation is not resolved in a few minutes, I will appoint one person to clarify the details. The rest will return to normal operation until the responsible person brings information for further analysis.
4. We avoid multitasking
Because multitasking doesn't work . She only exhausts, sprays attention and delays the receipt of the result.
What practices help:
- Work In Progress Limit.
- Focusing on the flow of value, not resources. For example, the first developer can do the task in a day, and the second in three. But the first will be released only after a week. So, the second takes the task to work. We will spend more time on implementation, but we will deliver the result faster (three days instead of a week and one day) and move on to the next task. At the same time, we are not trying to “shove the unedited” to the first developer and are not distracted by the work that “hung” in his expectation.
- If several people are involved in one task and the work is 90% completed, then the number one goal for the team is to do everything to finish the last 10%. Only after that we move on.
5. We make architectural decisions as late as possible
This is not our know-how, but one of the basic principles of lean manufacturing .
The decision made and implemented limits the possibility of further changes. And if the decision is made in conditions of incomplete information (and this is almost always the case), then the chances of making the wrong decision are significantly higher.
If the failure to make a decision does not block the work and does not lead to an exponential increase in technical debt, it should be postponed, leaving the system ready for any decision in the future, when we have more information.
This is the basis of development - we do not build “large” architectures before the start of the project. Instead, we make the refactoring process safe (see the section on feedback loops) and turn it into a natural part of the process.
Similarly, we are not trying to guess the future requirements for the system or build a universal solution. The ability to safely refactor is more universal because it makes it possible to make any changes in the future.
6. The code is operational at any given time.
Of course, this state is unattainable in the absolute, the system will periodically break down after making changes. But this does not mean that one should not strive for this characteristic.
When a breakdown is an abnormal situation, and not a norm of life, then its causes are easy to find. This is usually the last commit. Therefore, the responsible person is understandable, the steps to eliminate are understandable, it is clear when we return to a stable state.
The resulting confidence in the system gives a valuable opportunity to make a release at any time.
The second value is that we are more confident in making promises of availability. If we divide the work into two phases: “development” and “stabilization”, then it is difficult to make a concrete promise, since “stabilization” is work with problems that we do not yet know. Therefore, we cannot accurately evaluate them.
If stabilization goes inextricably with development and there are all the necessary tools for this, then the situation is more predictable.
How we maintain continuous performance:
- Obvious: code review, autotests, feature flags.
- Any changes are immediately deployed to the test environment. If it’s broken, then you won’t be able to fix it later — QA is blocked.
- Testing in a continuous flow immediately after completion of tasks, while the developer remembers the task and the code and quickly makes corrections.
- We do not do the work in parts. If two people are needed for implementation, then they work in pairs, in one branch, upload the code to the main branch when it is completely ready and covered in tests.
- Delivery automation and fixed delivery artifacts that do not need to be “finished” manually.
- Each team member knows diagnostic tools, knows how to work with them, and knows how to make releases.
7. We are a team, not a development group.
What does “team" mean:
- All code is reviewed by at least one person. If a serious problem is discovered, then they are encouraged to sit down together and do pair programming. To share a book, an article, a detailed explanation instead of broadcasting personal opinions is priceless.
- Instead of developing in pieces with the subsequent painful integration of the result, we work tightly in pairs when necessary.
- We do not turn the reviewer into a typo checking tool, we bring clean, small, pull request to the review.
- We do not throw tasks “over the fence”, but carefully hand over the work of QA, checking the happy path yourself. We help QA understand what and how to test, we help in passing border scenarios (for example, artificially breaking the system).
- QA, in turn, examines the internal structure of the system, knows how to collect all the necessary details (logs, data status) and get an extremely informative bug.
8. We chop tails
In order to maximize the efficiency and concentration of the current work, we eliminate the "debts" associated with the work already done:
- Tasks are brought to sales as quickly as possible. Only after that we consider them done.
- We are constantly eliminating technical debt so that it does not grow to the high cost of fixing (a week) and does not block work, ruining plans for the delivery of business functionality.
- We do not start tasks that we will do “someday,” but we delete long-lived tasks. A business will certainly come for a task when (if) the time to do it really comes. And just in case, in the task tracker, you can restore the deleted task. But this function has never been useful to us.
- Long-lived branches, commented-out code, To-do-shki - all this is a dead code, whose place is in the basket.
- Unstable tests are immediately fixed or removed and replaced with lower-level ones.
- We track "creeping" tasks.
The last point is worth a separate explanation.
I call “creeping” tasks with initially small labor costs, but hanging in In Progress for several days or weeks.
Why can this be:
- The task was initially poorly designed, it already required a lot of refinements, clarifications are contradictory or incomplete. So, we stop wasting time, stop work on the task and return to the statement.
- The task is in a state of waiting for a result from someone. For example, a service from another team or refinement from a business. We keep such tasks on a pencil and do not let them go on their own.
It is difficult to comply with this point. First of all, “creep” must be realized. Then you need to make a strong-willed decision and take a step back to detail. This is difficult for the developer to do since time has already been spent. And of course, such a decision will meet the resistance of the business. But practice shows that this reduces the chances of producing a result that neither the team, nor the business, nor the users will be happy with.
The cycle time graph helps in the search for such tasks. It shows the time from the moment of taking to work to completion. If the task is "out of the crowd," then this is a candidate for scrutiny.
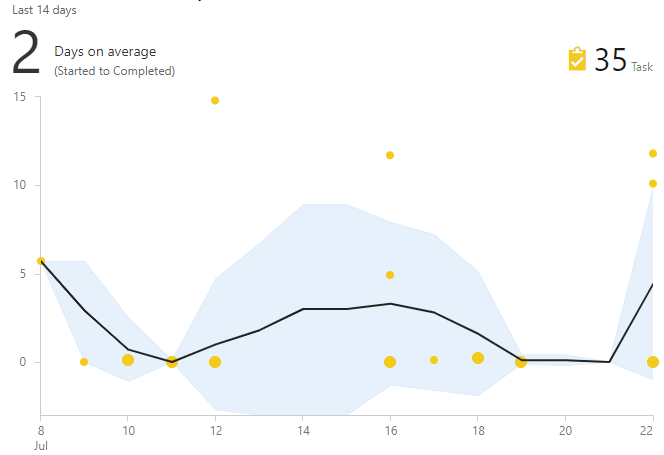
How to choose useful solutions
Unfortunately, I do not have a ready-to-go recipe. Team efficiency is a heuristic task, which means it does not have guaranteed solutions.
But there is still some checklist. There he is:
- I wrote about this at the beginning of the article and I repeat here: the fact that we use discomfort to diagnose problems does not mean that we strive for comfort when making decisions. Remember the main goal - increasing value for the business.
- When analyzing problems, remember that all participants have good intentions . If your thinking is based on a paranoid belief that someone is intentionally harming you, then making a good decision is very difficult.
- Do not try to break everything down and rebuild. Move in small steps, making changes gradually. Wait until the changes made bring results, and only then introduce new ones.
- If there is no clear solution, move in small steps, constantly evaluating the result and trying various options. A clear feedback loop and constant reflection are an inexhaustible development tool for you and the team.
- Forge the iron while it’s hot. Do not postpone the analysis until retrospective - the team will already forget what was happening. It is better to come to a retrospective with an already recognized problem and ready-made solutions that remain to be weighed with the team and choose the best.
- . «» , — .
- , . , , .
- . SMART , - . « ».
- , . , « », .
Conclusion
In conclusion, let's discuss the weaknesses of the approach.
First of all, this approach works to search for local optimizations; it is not possible to build a development strategy for the product and the entire company with it. Of course, awareness of problems is better than unconsciously crap and burn at work, but this is only the first step.
I also ask you, do not take a ready-made list of principles, take the tool with which it was created. Here's why:
Our list is not complete. It contains only what we have already implemented in everyday work.
The team will not take root principles, the importance of which she did not realize herself, through the pain of their absence. Instead of working ideas, you will get a bogeyman that everyone will carry around the office for some time, and then put dust in a corner.
Our list is specific. For example, if the technical debt on the project has been ignored for five years and is comparable to the US public debt, then it will be very difficult to get the benefit of the principle of constant extermination of the technical debt. It is fair to admit: a debt of this size will never be repaid. And focus on solutions that really help make the situation better.
How do you improve the process? And what principles have you already adopted in your work?
All Articles