Monitoring ETL processes in a small data warehouse
Many use specialized tools to create procedures for extracting, transforming, and loading data into relational databases. The process of working tools is logged, errors are recorded.
In case of an error, the log contains information that the tool failed to complete the task and which modules (often java) where they stopped. In the last lines you can find a database error, for example, a violation of a unique table key.
To answer the question, what role does ETL error information play, I classified all the problems that have occurred over the past two years in a rather large repository.

Characteristics of the storage where the classification was carried out:
Database errors include such as running out of space, disconnected, hung up session, etc.
Logical errors include violations of table keys, invalid objects, lack of access to objects, etc.
The scheduler may not start at the right time, it may hang, etc.
Simple errors do not require much time to fix. With most of them, a good ETL can cope on its own.
Complicated errors make it necessary to open and check procedures for working with data, and research data sources. Often lead to the need for testing changes and deployment.
So, half of all problems are related to the database. 48% of all errors are simple errors.
The third part of all problems is associated with a change in the logic or model of the repository; more than half of these errors are complex.
And less than a quarter of all problems are related to the task scheduler, 18% of which are simple errors.
In general, 22% of all errors that have occurred are complex; fixing them requires the most attention and time. They occur approximately once a week. While simple mistakes happen almost every day.
Obviously, monitoring ETL processes will then be effective when the location of the error is indicated as accurately as possible in the log and minimum time is required to find the source of the problem.
What did I want to see in the ETL monitoring process?
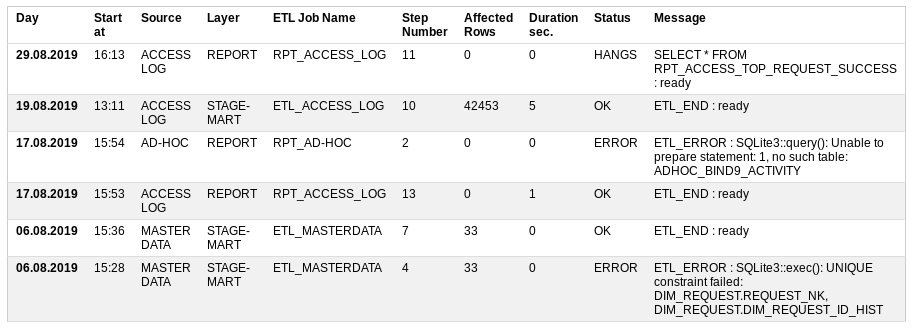
Start at - when started
Source - data source
Layer - what level of storage is loading,
ETL Job Name is a loading procedure that consists of many small steps,
Step Number - the number of the step to be performed,
Affected Rows - how much data has already been processed,
Duration sec - how long it takes to execute,
Status - whether everything is good or not: OK, ERROR, RUNNING, HANGS
Message - The last successful message or error description.
Based on the status of the records, you can send an email. letter to other participants. If there are no errors, then the letter is not necessary.
Thus, in the event of an error, the location of the incident is clearly indicated.
Sometimes it happens that the monitoring tool itself does not work. In this case, it is possible to directly call up a view (view) in the database, on the basis of which the report is built.
To implement monitoring of ETL processes, one table and one view are enough.
To do this, you can return to your small repository and create a prototype in the sqlite database.
Features of the table:
The necessary operations for working with the table are as follows:
In databases such as Oracle or Postgres, these operations can be implemented with built-in functions. Sqlite needs an external mechanism, and in this case it is prototyped in PHP .
Thus, error messages in data processing tools play a mega-important role. But it is difficult to call them optimal for a quick search for the causes of the problem. When the number of procedures approaches one hundred, the monitoring of processes turns into a complex project.
The article provides an example of a possible solution to the problem in the form of a prototype. The whole prototype of a small repository is available in gitlab SQLite PHP ETL Utilities .
In case of an error, the log contains information that the tool failed to complete the task and which modules (often java) where they stopped. In the last lines you can find a database error, for example, a violation of a unique table key.
To answer the question, what role does ETL error information play, I classified all the problems that have occurred over the past two years in a rather large repository.
Characteristics of the storage where the classification was carried out:
- 20 data sources connected
- 10.5 billion rows are processed daily
- which are aggregated up to 50 million rows,
- data processes 140 packets in 700 steps (a step is one sql request)
- server - 4-node X5 database
Database errors include such as running out of space, disconnected, hung up session, etc.
Logical errors include violations of table keys, invalid objects, lack of access to objects, etc.
The scheduler may not start at the right time, it may hang, etc.
Simple errors do not require much time to fix. With most of them, a good ETL can cope on its own.
Complicated errors make it necessary to open and check procedures for working with data, and research data sources. Often lead to the need for testing changes and deployment.
So, half of all problems are related to the database. 48% of all errors are simple errors.
The third part of all problems is associated with a change in the logic or model of the repository; more than half of these errors are complex.
And less than a quarter of all problems are related to the task scheduler, 18% of which are simple errors.
In general, 22% of all errors that have occurred are complex; fixing them requires the most attention and time. They occur approximately once a week. While simple mistakes happen almost every day.
Obviously, monitoring ETL processes will then be effective when the location of the error is indicated as accurately as possible in the log and minimum time is required to find the source of the problem.
Effective monitoring
What did I want to see in the ETL monitoring process?
Start at - when started
Source - data source
Layer - what level of storage is loading,
ETL Job Name is a loading procedure that consists of many small steps,
Step Number - the number of the step to be performed,
Affected Rows - how much data has already been processed,
Duration sec - how long it takes to execute,
Status - whether everything is good or not: OK, ERROR, RUNNING, HANGS
Message - The last successful message or error description.
Based on the status of the records, you can send an email. letter to other participants. If there are no errors, then the letter is not necessary.
Thus, in the event of an error, the location of the incident is clearly indicated.
Sometimes it happens that the monitoring tool itself does not work. In this case, it is possible to directly call up a view (view) in the database, on the basis of which the report is built.
ETL Monitoring Table
To implement monitoring of ETL processes, one table and one view are enough.
To do this, you can return to your small repository and create a prototype in the sqlite database.
DDL tables
CREATE TABLE UTL_JOB_STATUS ( /* Table for logging of job execution log. Important that the job has the steps ETL_START and ETL_END or ETL_ERROR */ UTL_JOB_STATUS_ID INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT, SID INTEGER NOT NULL DEFAULT -1, /* Session Identificator. Unique for every Run of job */ LOG_DT INTEGER NOT NULL DEFAULT 0, /* Date time */ LOG_D INTEGER NOT NULL DEFAULT 0, /* Date */ JOB_NAME TEXT NOT NULL DEFAULT 'N/A', /* Job name like JOB_STG2DM_GEO */ STEP_NAME TEXT NOT NULL DEFAULT 'N/A', /* ETL_START, ... , ETL_END/ETL_ERROR */ STEP_DESCR TEXT, /* Description of task or error message */ UNIQUE (SID, JOB_NAME, STEP_NAME) ); INSERT INTO UTL_JOB_STATUS (UTL_JOB_STATUS_ID) VALUES (-1);
DDL submission / report
CREATE VIEW IF NOT EXISTS UTL_JOB_STATUS_V AS /* Content: Package Execution Log for last 3 Months. */ WITH SRC AS ( SELECT LOG_D, LOG_DT, UTL_JOB_STATUS_ID, SID, CASE WHEN INSTR(JOB_NAME, 'FTP') THEN 'TRANSFER' /* file transfer */ WHEN INSTR(JOB_NAME, 'STG') THEN 'STAGE' /* stage */ WHEN INSTR(JOB_NAME, 'CLS') THEN 'CLEANSING' /* cleansing */ WHEN INSTR(JOB_NAME, 'DIM') THEN 'DIMENSION' /* dimension */ WHEN INSTR(JOB_NAME, 'FCT') THEN 'FACT' /* fact */ WHEN INSTR(JOB_NAME, 'ETL') THEN 'STAGE-MART' /* data mart */ WHEN INSTR(JOB_NAME, 'RPT') THEN 'REPORT' /* report */ ELSE 'N/A' END AS LAYER, CASE WHEN INSTR(JOB_NAME, 'ACCESS') THEN 'ACCESS LOG' /* source */ WHEN INSTR(JOB_NAME, 'MASTER') THEN 'MASTER DATA' /* source */ WHEN INSTR(JOB_NAME, 'AD-HOC') THEN 'AD-HOC' /* source */ ELSE 'N/A' END AS SOURCE, JOB_NAME, STEP_NAME, CASE WHEN STEP_NAME='ETL_START' THEN 1 ELSE 0 END AS START_FLAG, CASE WHEN STEP_NAME='ETL_END' THEN 1 ELSE 0 END AS END_FLAG, CASE WHEN STEP_NAME='ETL_ERROR' THEN 1 ELSE 0 END AS ERROR_FLAG, STEP_NAME || ' : ' || STEP_DESCR AS STEP_LOG, SUBSTR( SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), 1, INSTR(SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), '***')-2 ) AS AFFECTED_ROWS FROM UTL_JOB_STATUS WHERE datetime(LOG_D, 'unixepoch') >= date('now', 'start of month', '-3 month') ) SELECT JB.SID, JB.MIN_LOG_DT AS START_DT, strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS LOG_DT, JB.SOURCE, JB.LAYER, JB.JOB_NAME, CASE WHEN JB.ERROR_FLAG = 1 THEN 'ERROR' WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 AND strftime('%s','now') - JB.MIN_LOG_DT > 0.5*60*60 THEN 'HANGS' /* half an hour */ WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 THEN 'RUNNING' ELSE 'OK' END AS STATUS, ERR.STEP_LOG AS STEP_LOG, JB.CNT AS STEP_CNT, JB.AFFECTED_ROWS AS AFFECTED_ROWS, strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS JOB_START_DT, strftime('%d.%m.%Y %H:%M', datetime(JB.MAX_LOG_DT, 'unixepoch')) AS JOB_END_DT, JB.MAX_LOG_DT - JB.MIN_LOG_DT AS JOB_DURATION_SEC FROM ( SELECT SID, SOURCE, LAYER, JOB_NAME, MAX(UTL_JOB_STATUS_ID) AS UTL_JOB_STATUS_ID, MAX(START_FLAG) AS START_FLAG, MAX(END_FLAG) AS END_FLAG, MAX(ERROR_FLAG) AS ERROR_FLAG, MIN(LOG_DT) AS MIN_LOG_DT, MAX(LOG_DT) AS MAX_LOG_DT, SUM(1) AS CNT, SUM(IFNULL(AFFECTED_ROWS, 0)) AS AFFECTED_ROWS FROM SRC GROUP BY SID, SOURCE, LAYER, JOB_NAME ) JB, ( SELECT UTL_JOB_STATUS_ID, SID, JOB_NAME, STEP_LOG FROM SRC WHERE 1 = 1 ) ERR WHERE 1 = 1 AND JB.SID = ERR.SID AND JB.JOB_NAME = ERR.JOB_NAME AND JB.UTL_JOB_STATUS_ID = ERR.UTL_JOB_STATUS_ID ORDER BY JB.MIN_LOG_DT DESC, JB.SID DESC, JB.SOURCE;
SQL Checking the ability to get a new session number
SELECT SUM ( CASE WHEN start_job.JOB_NAME IS NOT NULL AND end_job.JOB_NAME IS NULL /* existed job finished */ AND NOT ( 'y' = 'n' ) /* force restart PARAMETER */ THEN 1 ELSE 0 END ) AS IS_RUNNING FROM ( SELECT 1 AS dummy FROM UTL_JOB_STATUS WHERE sid = -1) d_job LEFT OUTER JOIN ( SELECT JOB_NAME, SID, 1 AS dummy FROM UTL_JOB_STATUS WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */ AND STEP_NAME = 'ETL_START' GROUP BY JOB_NAME, SID ) start_job /* starts */ ON d_job.dummy = start_job.dummy LEFT OUTER JOIN ( SELECT JOB_NAME, SID FROM UTL_JOB_STATUS WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */ AND STEP_NAME in ('ETL_END', 'ETL_ERROR') /* stop status */ GROUP BY JOB_NAME, SID ) end_job /* ends */ ON start_job.JOB_NAME = end_job.JOB_NAME AND start_job.SID = end_job.SID
Features of the table:
- the beginning and end of the data processing procedure must be followed by the steps ETL_START and ETL_END
- in case of an error, ETL_ERROR step must be created with its description
- the amount of processed data must be highlighted, for example, with asterisks
- at the same time, the same procedure can be started with the force_restart = y parameter; without it, the session number is issued only to the completed procedure
- in normal mode, you cannot run the same data processing procedure in parallel
The necessary operations for working with the table are as follows:
- getting the session number of the ETL procedure to start
- insert a log entry into a table
- getting the last successful ETL procedure record
In databases such as Oracle or Postgres, these operations can be implemented with built-in functions. Sqlite needs an external mechanism, and in this case it is prototyped in PHP .
Output
Thus, error messages in data processing tools play a mega-important role. But it is difficult to call them optimal for a quick search for the causes of the problem. When the number of procedures approaches one hundred, the monitoring of processes turns into a complex project.
The article provides an example of a possible solution to the problem in the form of a prototype. The whole prototype of a small repository is available in gitlab SQLite PHP ETL Utilities .
All Articles