LuaVela: Lua 5.1 implementation based on LuaJIT 2.0
Some time ago, we announced a public release and opened under the MIT license the source code of LuaVela - an implementation of Lua 5.1, based on LuaJIT 2.0. We started working on it in 2015, and by the beginning of 2017 it was used in more than 95% of the company's projects. Now I want to look back on the path traveled. What circumstances prompted us to develop our own implementation of a programming language? What problems did we encounter and how did we solve them? How is LuaVela different from other LuaJIT forks?
This section is based on our report on HighLoad ++. We began to actively use Lua to write the business logic of our products in 2008. At first it was vanilla Lua, and since 2009 - LuaJIT. The RTB protocol has a tight framework for processing the request, so switching to a faster implementation of the language was a logical and necessary decision from some point on.
Over time, we realized that there were certain limitations to the LuaJIT architecture. The most important thing for us was that LuaJIT 2.0 uses strictly 32-bit pointers. This led us to a situation where running on 64-bit Linux limited the size of the virtual address space of the process memory to one gigabyte (in later versions of the Linux kernel, this limit was raised to two gigabytes):
This limitation became a big problem - by 2015, 1-2 gigabytes of memory ceased to be enough for many projects to load the data that the logic worked with. It is worth noting that each instance of the Lua virtual machine is single-threaded and does not know how to share data with other instances - this means that in practice, each virtual machine could claim a memory size not exceeding 2GB / n, where n is the number of worker threads of our server applications.
We went over several solutions to the problem: we reduced the number of threads in our application server, tried to organize access to data through LuaJIT FFI, tested the transition to LuaJIT 2.1. Unfortunately, all of these options were either economically disadvantageous or did not scale well in the long run. The only thing left for us was to take a chance and fork LuaJIT. At this point, we made decisions that largely determined the fate of the project.
First, we immediately decided not to make changes to the syntax and semantics of the language, focusing on removing the architectural limitations of LuaJIT, which turned out to be a problem for the company. Of course, as the project developed, we began to add extensions (we will discuss this below) - but we isolated all the new APIs from the standard language library.
In addition, we abandoned cross-platform in favor of supporting only Linux x86-64, our only production platform. Unfortunately, we did not have enough resources to adequately test the gigantic amount of changes that we were going to make to the platform.
Let's see where the restriction on the size of pointers comes from. To begin with, the number type in Lua 5.1 is (with some minor caveats) the C type double, which in turn corresponds to the double precision type defined by the IEEE 754 standard. In the encoding of this 64-bit type, the range of values is highlighted for presentation NaN. In particular, how NaN interprets any value in the range [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Thus, we can pack into a single 64-bit value either a “real” double precision number or some entity, which from the point of view of double type will be interpreted as NaN, and from the point of view of our platform it will be something more meaningful - for example, object type (high 32 bits) and a pointer to its contents (low 32 bits):
This technique is sometimes called NaN tagging (or NaN boxing), and TValue basically describes how LuaJIT represents variable values in Lua. TValue also has a third hypostasis used to store a function pointer and information for unwinding a Lua stack, that is, in the final analysis, the data structure looks like this:
The frame.link field in the definition above is of type uintptr_t, because in some cases it stores a pointer, and in others it is an integer. The result is a very compact representation of the virtual machine stack - in fact, it is a TValue array, and each element of the array is situationally interpreted as a number, then as a typed pointer to an object, or as data about the frame of a Lua-stack.
Let's look at an example. Imagine that we started with LuaJIT this Lua code and set a break point inside the print function:
The Lua stack at this point will look like this:

And everything would be fine, but this technique starts to fail as soon as we try to start on x86-64. If we run in compatibility mode for 32-bit applications, we run into the mmap restriction already mentioned above. And 64-bit pointers will not work out of the box at all. What to do? To fix the problem I had to:
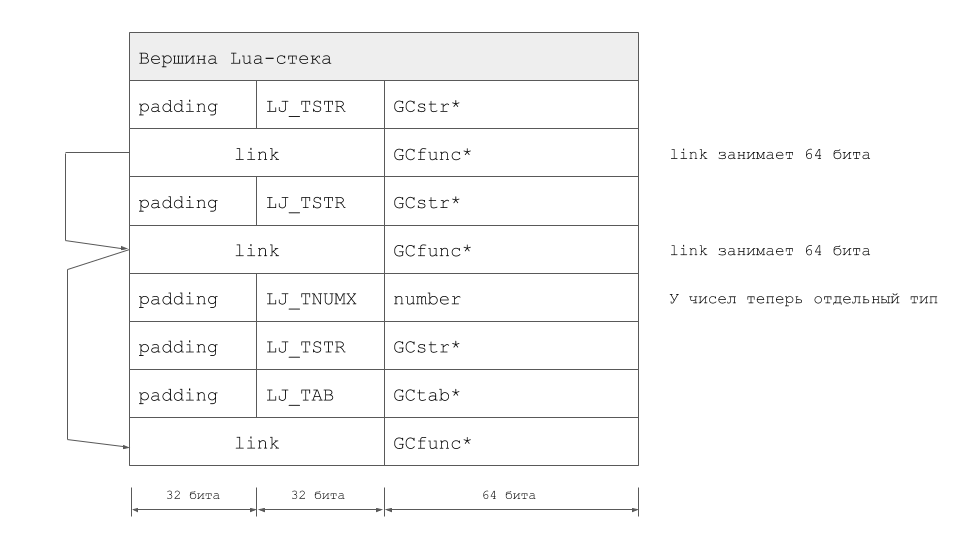
The total volume of changes turned out to be very significant and quite alienated us from the original LuaJIT. It is worth noting that the TValue extension is not the only way to solve the problem. In LuaJIT 2.1, they went the other way by implementing the LJ_GC64 mode. Peter Cawley, who made a huge contribution to the development of this mode of operation, read about it at a meeting in London. Well, in the case of LuaVela, the stack for the same example looks like this:
After months of active development, it's time to try out LuaVela in battle. As the experimental subjects, we selected the most problematic projects in terms of memory consumption: the amount of data with which they had to work, obviously exceeded 1 gigabyte, so they were forced to use various workarounds. The first results were encouraging: LuaVela was stable and showed better performance compared to the LuaJIT configuration used in these same projects.
At the same time, the question of testing arose. Fortunately, we did not have to start from scratch, since from the first day of development, in addition to staging servers, we had at our disposal:
As practice has shown, these resources were quite enough for debugging and bringing the project to a minimum stable state (they did a dev assembly - rolled out to staging - it works and does not crash). On the other hand, such testing through other projects was completely unsuitable in the long term: a project of such a level of complexity as the implementation of a programming language cannot have its own tests. In addition, the lack of tests directly in the project purely technically complicated the search and correction of errors.
In an ideal world, we wanted to test not only our implementation, but also have a set of tests that would allow us to validate it against the semantics of the language . Unfortunately, some disappointment awaited us in this matter. Despite the fact that the Lua community willingly creates forks of existing implementations, until recently, a similar set of validation tests was missing. The situation changed for the better when, at the end of 2018, François Perrad announced the lua-Harness project.
In the end, we closed the testing problem by integrating the most complete and representative test suites in the Lua ecosystem into our repository:
The introduction of each batch of tests allowed us to detect and correct 2-3 critical errors - so it is obvious that our efforts paid off. Although the topic of testing language runtimes and compilers (both static and dynamic) is truly limitless, we believe that we have laid a rather solid basis for stable development of the project. We talked about the problems of testing our own implementation of Lua (including topics such as working with test benches and postmortem debugging) twice, at Lua in Moscow 2017 and at HighLoad ++ 2018 - everyone who is interested in details is welcome to watch a video of these reports. Well, look at the tests directory in our repository, of course.
Thus, we had at our disposal a stable implementation of Lua 5.1 for Linux x86-64, developed by the forces of a small team that gradually “mastered” the LuaJIT heritage and accumulated expertise. In such conditions, the desire to expand the platform and add features that are neither in vanilla Lua nor in LuaJIT, but which would help us solve other pressing problems, became quite natural.
A detailed description of all extensions is provided in the documentation in RST format (use cmake. && make docs to build a local copy in HTML format). A full description of the Lua API extensions can be found at this link , and the C API at this . Unfortunately, in a review article it is impossible to talk about everything, so here is a list of the most significant functions:
Each of these features deserves a separate article - write in the comments which one you would like to read more about.
Here I want to talk a little more about how we reduced the load on the garbage collector. Sealing allows you to make an object inaccessible to the garbage collector. In our typical project, most of the data (up to 80%) inside the Lua virtual machine is already business rules, which are a complex Lua table. The lifetime of this table (minutes) is much longer than the lifetime of the processed requests (tens of milliseconds), and the data in it does not change during query processing. In such a situation, it makes no sense to force the garbage collector to recurse around this huge data structure again and again. To do this, we recursively "seal" the object and reorder the data in such a way that the garbage collector never reaches either the "sealed" object or its contents. In vanilla Lua 5.4, this problem will be resolved by supporting generations of objects in the generational garbage collection.
It is important to keep in mind that “sealed” objects must not be writable. Non-observance of this invariant leads to the appearance of dangling pointers: for example, a “sealed” object refers to a regular one, and a garbage collector, skipping a “sealed” object when passing a heap, skips a regular one - with the difference that a “sealed” object cannot be released, and the usual one can. Having implemented support for this invariant, we essentially get free immunity support for objects, the absence of which is often lamented in Lua. I emphasize that immutable and “sealed” objects are not the same thing. The second property implies the first, but not vice versa.
I also note that in Lua 5.1 immunity can be implemented using metatables - the solution is quite working, but not the most profitable in terms of performance. More information on “sealing,” immunity, and how we use them in everyday life can be found in this report.
At the moment, we are satisfied with the stability and the set of opportunities for our implementation. And although due to the initial limitations, our implementation is significantly inferior to vanilla Lua and LuaJIT in terms of portability, it solves many of our problems - we hope these solutions are useful to someone else.
In addition, even if LuaVela is not suitable for production, we invite you to use it as an entry point to understand how LuaJIT or its fork works. In addition to solving problems and expanding functionality, over the years we have refactored a significant part of the code base and wrote training articles on the internal structure of the project - many of them are applicable not only to LuaVela, but also to LuaJIT.
Thank you for your attention, we are waiting for pull requests!
Background
This section is based on our report on HighLoad ++. We began to actively use Lua to write the business logic of our products in 2008. At first it was vanilla Lua, and since 2009 - LuaJIT. The RTB protocol has a tight framework for processing the request, so switching to a faster implementation of the language was a logical and necessary decision from some point on.
Over time, we realized that there were certain limitations to the LuaJIT architecture. The most important thing for us was that LuaJIT 2.0 uses strictly 32-bit pointers. This led us to a situation where running on 64-bit Linux limited the size of the virtual address space of the process memory to one gigabyte (in later versions of the Linux kernel, this limit was raised to two gigabytes):
/* MAP_32BIT 4 x86-64: */ void *ptr = mmap((void *)MMAP_REGION_START, size, MMAP_PROT, MAP_32BIT | MMAP_FLAGS, -1, 0);
This limitation became a big problem - by 2015, 1-2 gigabytes of memory ceased to be enough for many projects to load the data that the logic worked with. It is worth noting that each instance of the Lua virtual machine is single-threaded and does not know how to share data with other instances - this means that in practice, each virtual machine could claim a memory size not exceeding 2GB / n, where n is the number of worker threads of our server applications.
We went over several solutions to the problem: we reduced the number of threads in our application server, tried to organize access to data through LuaJIT FFI, tested the transition to LuaJIT 2.1. Unfortunately, all of these options were either economically disadvantageous or did not scale well in the long run. The only thing left for us was to take a chance and fork LuaJIT. At this point, we made decisions that largely determined the fate of the project.
First, we immediately decided not to make changes to the syntax and semantics of the language, focusing on removing the architectural limitations of LuaJIT, which turned out to be a problem for the company. Of course, as the project developed, we began to add extensions (we will discuss this below) - but we isolated all the new APIs from the standard language library.
In addition, we abandoned cross-platform in favor of supporting only Linux x86-64, our only production platform. Unfortunately, we did not have enough resources to adequately test the gigantic amount of changes that we were going to make to the platform.
A quick look under the platform hood
Let's see where the restriction on the size of pointers comes from. To begin with, the number type in Lua 5.1 is (with some minor caveats) the C type double, which in turn corresponds to the double precision type defined by the IEEE 754 standard. In the encoding of this 64-bit type, the range of values is highlighted for presentation NaN. In particular, how NaN interprets any value in the range [0xFFF8000000000000; 0xFFFFFFFFFFFFFFFF].
Thus, we can pack into a single 64-bit value either a “real” double precision number or some entity, which from the point of view of double type will be interpreted as NaN, and from the point of view of our platform it will be something more meaningful - for example, object type (high 32 bits) and a pointer to its contents (low 32 bits):
union TValue { double n; struct object { void *payload; uint32_t type; } o; };
This technique is sometimes called NaN tagging (or NaN boxing), and TValue basically describes how LuaJIT represents variable values in Lua. TValue also has a third hypostasis used to store a function pointer and information for unwinding a Lua stack, that is, in the final analysis, the data structure looks like this:
union TValue { double n; struct object { void *payload; uint32_t type; } o; struct frame { void *func; uintptr_t link; } f; };
The frame.link field in the definition above is of type uintptr_t, because in some cases it stores a pointer, and in others it is an integer. The result is a very compact representation of the virtual machine stack - in fact, it is a TValue array, and each element of the array is situationally interpreted as a number, then as a typed pointer to an object, or as data about the frame of a Lua-stack.
Let's look at an example. Imagine that we started with LuaJIT this Lua code and set a break point inside the print function:
local function foo(x) print("Hello, " .. x) end local function bar(a, b) local n = math.pi foo(b) end bar({}, "Lua")
The Lua stack at this point will look like this:
And everything would be fine, but this technique starts to fail as soon as we try to start on x86-64. If we run in compatibility mode for 32-bit applications, we run into the mmap restriction already mentioned above. And 64-bit pointers will not work out of the box at all. What to do? To fix the problem I had to:
- Extend TValue from 64 to 128 bits: this way we get an “honest” void * on a 64-bit platform.
- Correct the virtual machine code accordingly.
- Make changes to the JIT compiler.
The total volume of changes turned out to be very significant and quite alienated us from the original LuaJIT. It is worth noting that the TValue extension is not the only way to solve the problem. In LuaJIT 2.1, they went the other way by implementing the LJ_GC64 mode. Peter Cawley, who made a huge contribution to the development of this mode of operation, read about it at a meeting in London. Well, in the case of LuaVela, the stack for the same example looks like this:
First successes and stabilization of the project
After months of active development, it's time to try out LuaVela in battle. As the experimental subjects, we selected the most problematic projects in terms of memory consumption: the amount of data with which they had to work, obviously exceeded 1 gigabyte, so they were forced to use various workarounds. The first results were encouraging: LuaVela was stable and showed better performance compared to the LuaJIT configuration used in these same projects.
At the same time, the question of testing arose. Fortunately, we did not have to start from scratch, since from the first day of development, in addition to staging servers, we had at our disposal:
- Functional and integration tests of an application server that executes the business logic of all company projects.
- Tests of individual projects.
As practice has shown, these resources were quite enough for debugging and bringing the project to a minimum stable state (they did a dev assembly - rolled out to staging - it works and does not crash). On the other hand, such testing through other projects was completely unsuitable in the long term: a project of such a level of complexity as the implementation of a programming language cannot have its own tests. In addition, the lack of tests directly in the project purely technically complicated the search and correction of errors.
In an ideal world, we wanted to test not only our implementation, but also have a set of tests that would allow us to validate it against the semantics of the language . Unfortunately, some disappointment awaited us in this matter. Despite the fact that the Lua community willingly creates forks of existing implementations, until recently, a similar set of validation tests was missing. The situation changed for the better when, at the end of 2018, François Perrad announced the lua-Harness project.
In the end, we closed the testing problem by integrating the most complete and representative test suites in the Lua ecosystem into our repository:
- Tests written by the creators of the language for their implementation of Lua 5.1.
- Tests provided by the community by LuaJIT author Mike Pall.
- lua harness
- A subset of the tests of the MAD project being developed by CERN.
- Two test suites that we have created in IPONWEB and continue to be replenished so far: one for functional testing of the platform, the other using the cmocka framework for testing the C API and all that lacks testing at the Lua code level.
The introduction of each batch of tests allowed us to detect and correct 2-3 critical errors - so it is obvious that our efforts paid off. Although the topic of testing language runtimes and compilers (both static and dynamic) is truly limitless, we believe that we have laid a rather solid basis for stable development of the project. We talked about the problems of testing our own implementation of Lua (including topics such as working with test benches and postmortem debugging) twice, at Lua in Moscow 2017 and at HighLoad ++ 2018 - everyone who is interested in details is welcome to watch a video of these reports. Well, look at the tests directory in our repository, of course.
New features
Thus, we had at our disposal a stable implementation of Lua 5.1 for Linux x86-64, developed by the forces of a small team that gradually “mastered” the LuaJIT heritage and accumulated expertise. In such conditions, the desire to expand the platform and add features that are neither in vanilla Lua nor in LuaJIT, but which would help us solve other pressing problems, became quite natural.
A detailed description of all extensions is provided in the documentation in RST format (use cmake. && make docs to build a local copy in HTML format). A full description of the Lua API extensions can be found at this link , and the C API at this . Unfortunately, in a review article it is impossible to talk about everything, so here is a list of the most significant functions:
- DataState - the ability to share an object from multiple independent instances of Lua virtual machines.
- The ability to set a timeout for coroutine and interrupt the execution of those that run longer than it.
- A set of JIT compiler optimizations designed to combat the exponential increase in the number of traces when copying data between objects - we talked about this at HighLoad ++ 2017, but just a couple of months ago we had new working ideas that have yet to be documented.
- New Toolkit: Sampling Profiler. dumpanalyze compiler debug output analyzer, etc.
Each of these features deserves a separate article - write in the comments which one you would like to read more about.
Here I want to talk a little more about how we reduced the load on the garbage collector. Sealing allows you to make an object inaccessible to the garbage collector. In our typical project, most of the data (up to 80%) inside the Lua virtual machine is already business rules, which are a complex Lua table. The lifetime of this table (minutes) is much longer than the lifetime of the processed requests (tens of milliseconds), and the data in it does not change during query processing. In such a situation, it makes no sense to force the garbage collector to recurse around this huge data structure again and again. To do this, we recursively "seal" the object and reorder the data in such a way that the garbage collector never reaches either the "sealed" object or its contents. In vanilla Lua 5.4, this problem will be resolved by supporting generations of objects in the generational garbage collection.
It is important to keep in mind that “sealed” objects must not be writable. Non-observance of this invariant leads to the appearance of dangling pointers: for example, a “sealed” object refers to a regular one, and a garbage collector, skipping a “sealed” object when passing a heap, skips a regular one - with the difference that a “sealed” object cannot be released, and the usual one can. Having implemented support for this invariant, we essentially get free immunity support for objects, the absence of which is often lamented in Lua. I emphasize that immutable and “sealed” objects are not the same thing. The second property implies the first, but not vice versa.
I also note that in Lua 5.1 immunity can be implemented using metatables - the solution is quite working, but not the most profitable in terms of performance. More information on “sealing,” immunity, and how we use them in everyday life can be found in this report.
findings
At the moment, we are satisfied with the stability and the set of opportunities for our implementation. And although due to the initial limitations, our implementation is significantly inferior to vanilla Lua and LuaJIT in terms of portability, it solves many of our problems - we hope these solutions are useful to someone else.
In addition, even if LuaVela is not suitable for production, we invite you to use it as an entry point to understand how LuaJIT or its fork works. In addition to solving problems and expanding functionality, over the years we have refactored a significant part of the code base and wrote training articles on the internal structure of the project - many of them are applicable not only to LuaVela, but also to LuaJIT.
Thank you for your attention, we are waiting for pull requests!
All Articles