Weight Insensitive Neural Networks (WANN)
Google’s new work offers the architecture of neural networks that can simulate the innate instincts and reflexes of living beings, followed by further training throughout life.
And also significantly reducing the number of connections within the network, thereby increasing their speed.
Artificial neural networks, although similar in principle to biological ones, are still too different from them to be used in their pure form to create a strong AI. For example, now it is impossible to create a model of a person (or a mouse, or even an insect) in a simulator, give him a “brain” in the form of a modern neural network and train it. It just doesn't work.
Even having discarded the differences in the learning mechanism (in the brain there is no exact analogue of the back-propagation algorithm of the error, for example) and the lack of different-scale temporal correlations, on the basis of which the biological brain builds its work, artificial neural networks have several more problems that do not allow them to simulate sufficiently living brain. Probably due to these inherent problems of the mathematical apparatus used now, Reinforcement Learning, designed to imitate the training of living creatures on the basis of the reward, does not work as well as we would like in practice. Although it is based on really good and right ideas. The developers themselves joke that the brain is RNN + A3C (i.e., a recurrent network + actor-critic algorithm for its training).
One of the most noticeable differences between the biological brain and artificial neural networks is that the structure of the living brain is pre-configured by millions of years of evolution. Although the neocortex, which is responsible for the higher nervous activity in mammals, has an approximately uniform structure, the general structure of the brain is clearly defined by genes. Moreover, animals other than mammals (birds, fish) do not have a neocortex at all, but at the same time they exhibit complex behavior that is not achievable by modern neural networks. A person also has physical limitations in the structure of the brain, which are difficult to explain. For example, the resolution of one eye is approximately 100 megapixels (~ 100 million photosensitive rods and cones), which means that from two eyes the video stream should be about 200 megapixels with a frequency of at least 15 frames per second. But in reality, the optic nerve can pass through itself no more than 2-3 megapixels. And its connections are directed not at all to the nearest part of the brain, but to the occipital part to the visual cortex.
Therefore, without detracting from the importance of the neocortex (roughly speaking, it can be considered at birth as an analogue of randomly initiated modern neural networks), the facts suggest that even a person has a huge role to play in a predetermined brain structure. For example, if a baby is only a few minutes old to show its tongue, then thanks to mirror neurons, it will also stick out its tongue. The same thing happens with children's laughter. It is well known that babies from birth have a superlative recognition of human faces. But more importantly, the nervous system of all living things is optimized for their living conditions. The baby will not cry for hours if it is hungry. He will get tired. Or scared of something and shut up. The fox will not reach exhaustion until starvation reach for inaccessible grapes. She will make several attempts, decide that he is bitter (s) and leave. And this is not a learning process, but a behavior predefined by biology. Moreover, different species have different. Some predators immediately rush for prey, while others sit in ambush for a long time. And they learned this not through trial and error, but such is their biology, given by instincts. Likewise, many animals have wired predator avoidance programs from the first minutes of life, although they have not physically been able to learn them.
Theoretically, modern methods of training neural networks are capable of creating a semblance of such a pre-trained brain from a fully connected network, zeroing out unnecessary connections (in fact, cutting them off) and leaving only the necessary ones. But this requires a huge number of examples, it is not known how to train them, and most importantly - at the moment there are no good ways to fix this "initial" structure of the brain. Subsequent training changes these weights and everything goes bad.
Researchers from Google also asked this question. Is it possible to create an initial brain structure similar to the biological one, that is, already well optimized for solving the problem, and then only retrain it? Theoretically, this will dramatically narrow the space of solutions and allow you to quickly train neural networks.
Unfortunately, existing network structure optimization algorithms, such as Neural Architecture Search (NAS), operate on entire blocks. After adding or removing which, the neural network has to be trained anew from scratch. This is a resource-intensive process and does not completely solve the problem.
Therefore, the researchers proposed a simplified version, called the "Weight Agnostic Neural Networks" (WANN). The idea is to replace all the weights of a neural network with one “common” weight. And in the learning process, it’s not to select weights between neurons, as in ordinary neural networks, but to select the structure of the network itself (the number and location of neurons), which with the same weights shows the best results. And after that, optimize it so that the network works well with all possible values of this total weight (common for all connections between neurons!).
As a result, this gives the structure of a neural network, which does not depend on specific values of weights, but works well with everyone. Because it works due to the overall network structure. This is similar to an animal’s brain that has not yet been initialized with specific scales at birth, but already contains embedded instincts due to its general structure. And the subsequent fine-tuning of the scales during training throughout life, makes this neural network even better.
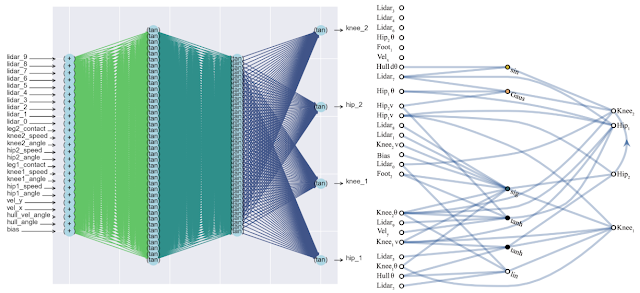
A side positive effect of this approach is a significant reduction in the number of neurons in the network (since only the most important connections remain), which increases its speed. Below is a comparison of the complexity of a classic fully connected neural network (left) and a matched new one (right).
To search for such an architecture, researchers used the Topology search algorithm (NEAT). First, a set of simple neural networks is created, and then one of three actions is done: a new neuron is added to the existing connection between two neurons, a new connection with random ones is added to another neuron, or the activation function in the neuron changes (see the figures below). And then, unlike classical NAS, where optimal weights between neurons are searched, here all weights are initialized with one single number. And optimization is carried out to search for a network structure that works best in a wide range of values of this one total weight. Thus, a network is obtained that does not depend on the specific weight between neurons, but works well in the entire range (but all weights are still initiated by one number, and not different as in normal networks). Moreover, as an additional goal for optimization, they try to minimize the number of neurons in the network.
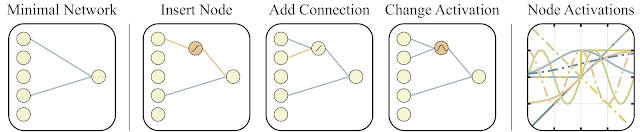
Below is a general outline of the algorithm.
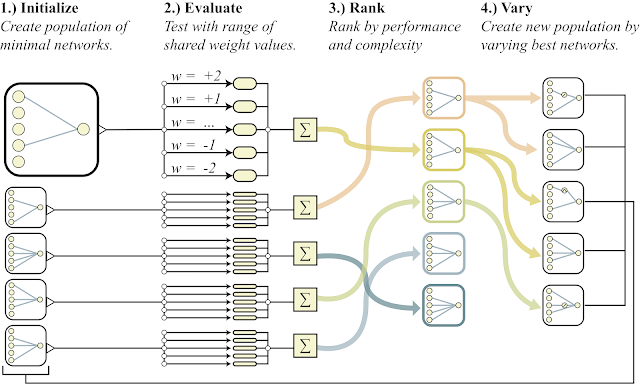
- creates a population of simple neural networks
- each network initializes all its weights with one number, and for a wide range of numbers: w = -2 ... + 2
- the resulting networks are sorted by the quality of the solution to the problem and by the number of neurons (down)
- in the part of the best representatives, one neuron is added, one connection or the activation function in one neuron changes
- these modified networks are used as initial in point 1)
All this is good, but hundreds, if not thousands of different ideas have been proposed for neural networks. Does this work in practice? Yes it works. Below is an example of the search result for such a network architecture for the classical pendulum trolley problem. As can be seen from the figure, the neural network works well with all variants of the total weight (better with +1.0, but also tries to raise the pendulum from -1.5). And after optimizing this single weight, it starts to work perfectly perfectly (Fine-Tuned Weights option in the figure).
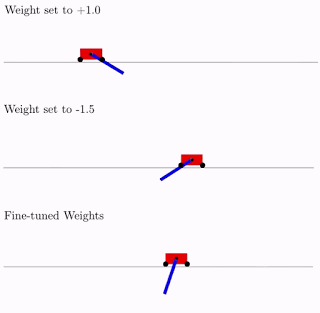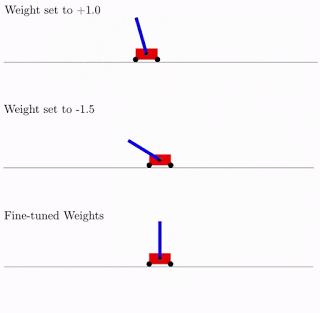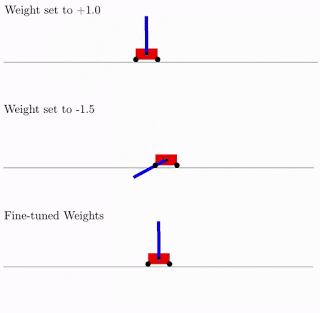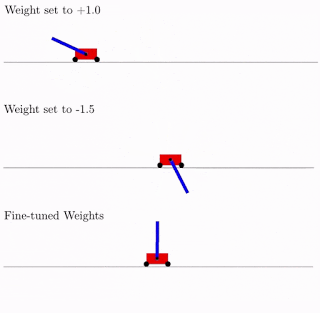
What is characteristic, you can retrain as this single total weight, since the selection of architecture is done on a limited discrete number of parameters (in the example above -2, -1,1,2). And you can get a more accurate optimal parameter, say, 1.5. And you can use the best total weight as a starting point for the retraining of all weights, as in the classical training of neural networks.
This is similar to how animals are trained. Having instincts that are close to optimal at birth, and using this brain structure given by the genes as the initial one, during the course of their life the animals train their brain under specific external conditions. More details in a recent article in the journal Nature .
Below is an example of a network found by WANN for a pixel-based machine control task. Please note that this is a ride on the "bare instincts", with the same total weight in all joints, without the classic fine-tuning of all weights. At the same time, the neural network is extremely simple in structure.
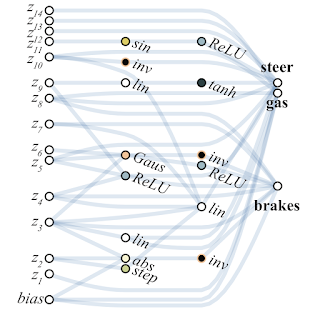

Researchers suggest creating ensembles from WANN networks as another use case for WANN. So, the usual randomly initialized neural network on MNIST shows an accuracy of about 10%. A selected single WANN neural network produces about 80%, but an ensemble from WANN with different total weights shows already> 90%.
As a result, the method proposed by Google researchers to search for the initial architecture of an optimal neural network not only imitates animal learning (birth with built-in optimal instincts and retraining during life), but also avoids the simulation of the entire animal life with full-fledged learning of the entire network in classical evolutionary algorithms, creating Simple and fast networks at once. Which is enough just to slightly train to get a fully optimal neural network.
References
All Articles