Apache NIFI - A Brief Overview of Features in Practice
Introduction
It so happened that at my current place of work I had to get acquainted with this technology. I'll start with a little background. At the next meeting, our team was told that we need to create integration with a well-known system . Integration meant that this well-known system will send us requests via HTTP to a specific endpoint, and we, oddly enough, send back the responses in the form of a SOAP message. Everything seems to be simple and trivial. It follows what is needed ...
A task
Create 3 services. The first one is the Database Update Service. This service, when new data arrives from a third-party system, updates the data in the database and generates a certain file in CSV format for transferring it to the next system. The endpoint of the second service is called - the FTP Transport Service, which receives the transferred file, validates it, and puts it into the file storage via FTP. The third service, the Data Transfer Service to the consumer, works asynchronously with the first two. It receives a request from a third-party external system, to receive the file discussed above, takes the finished response file, modifies it (updates the id, description, linkToFile fields) and sends the response in the form of a SOAP message. That is, the overall picture is as follows: the first two services begin their work only when the data for updating has arrived. The third service works constantly because there are a lot of consumers of information, about 1000 requests for data per minute. Services are constantly available and their instances are located in different environments, such as test, demo, preprod and prod. Below is a diagram of the work of these services. I’ll explain right away that some details are simplified to avoid unnecessary complexity.

Technical deepening
When planning a solution to the problem, we first decided to make java applications using the Spring framework, the Nginx balancer, the Postgres database, and other technical and not very things. Since time to develop a technical solution allowed us to consider other approaches to solving this problem, my eyes fell on the Apache NIFI technology, fashionable in certain circles. I must say right away that this technology allowed us to notice these 3 services. This article will describe the development of a file transfer service and a data transfer service to a consumer, however, if the article comes in, I will write about a data update service in the database.
What it is
NIFI is a distributed architecture for fast parallel loading and processing of data, a large number of plug-ins for sources and transformations, versioning configurations and much more. A nice bonus is that it is very easy to use. Trivial processes, such as getFile, sendHttpRequest and others, can be represented as squares. Each square represents a certain process, the interaction of which can be seen in the figure below. More detailed documentation on the interaction of process tuning is written here.
The idea to write an article was born after a long search and structuring of the information received in something conscious, as well as the desire to make life easier for future developers ..
Example
An example of how squares interact with each other is considered. The general scheme is quite simple: We get an HTTP request (In theory, with a file in the body of the request. To demonstrate the capabilities of NIFI, in this example, the request starts the process of receiving the file from the local PF), then we send back the response that the request was received, the process of receiving the file from FH and then the process of moving it through FTP to FH. It is worth explaining that processes interact with each other through the so-called flowFile. This is the basic entity in NIFI that stores attributes and content. Content - data that is represented by the stream file. Roughly speaking, if you received a file from one square and transfer it to another, the content will be your file.
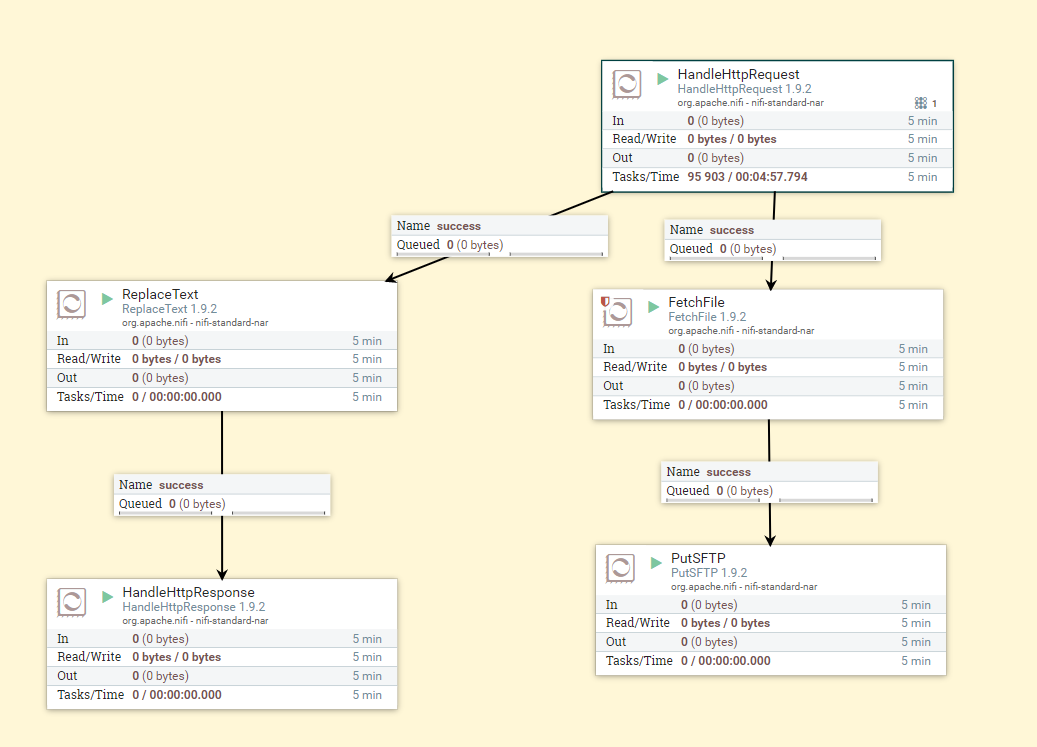
As you can see, this figure depicts the overall process. HandleHttpRequest - accepts requests, ReplaceText - generates a response body, HandleHttpResponse - returns a response. FetchFile - receives a file from the file storage and transfers it to the PutSftp square - puts this file on FTP at the specified address. Now more about this process.
In this case, request is the beginning of everything. Let's see its configuration options.
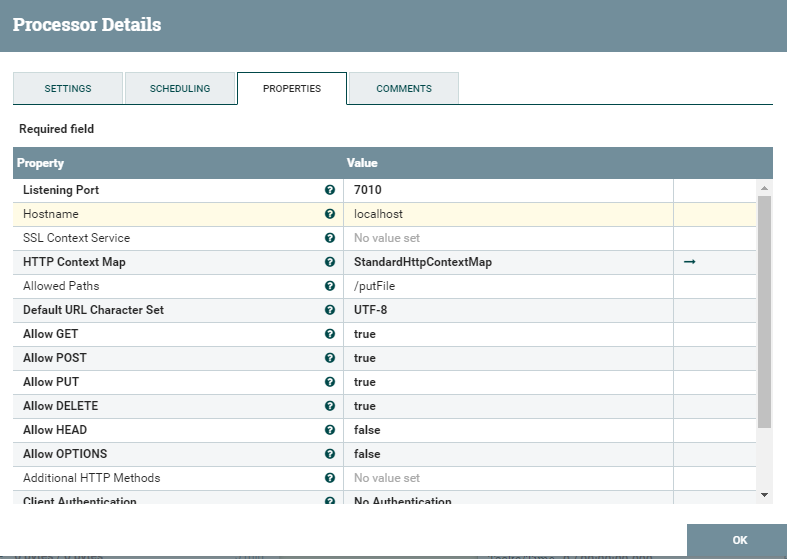
Everything here is pretty trivial with the exception of StandartHttpContextMap - this is some kind of service that allows you to send and receive requests. You can see more details and even examples here
Next, see the ReplaceText square configuration options. It is worth paying attention to ReplacementValue - this is what will return to the user in the form of an answer. In settings you can adjust the level of logging, logs can be viewed {where nifi was unpacked} /nifi-1.9.2/logs there are also failure / success parameters - based on these parameters you can control the whole process. That is, in the case of successful text processing, the process of sending a response to the user is called, and in the other case, we simply pledge the unsuccessful process.
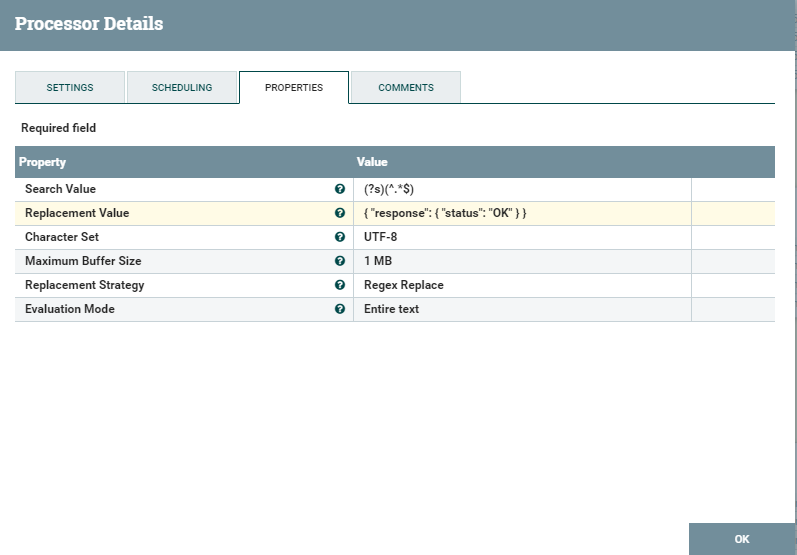
The HandleHttpResponse properties have nothing special except status for successful response creation.
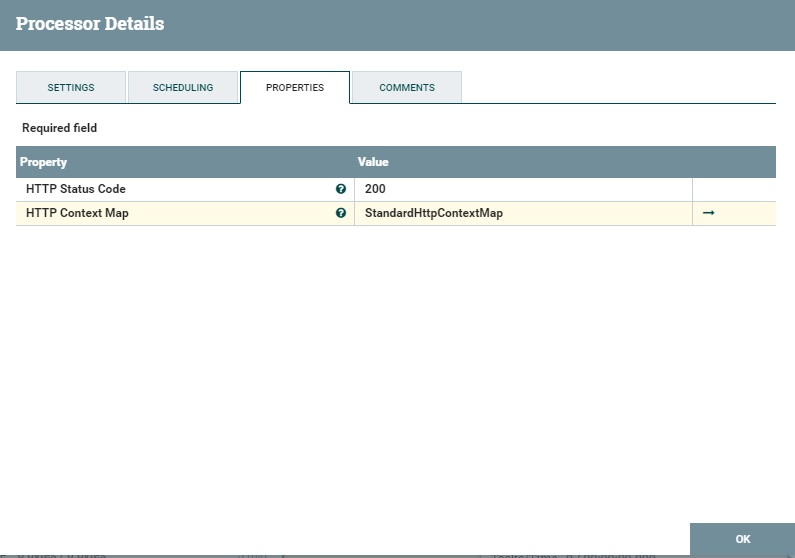
We sorted out the request with the answer - let's move on to receiving the file and placing it on the FTP server. FetchFile - receives the file at the path specified in the settings and transfers it to the next process.
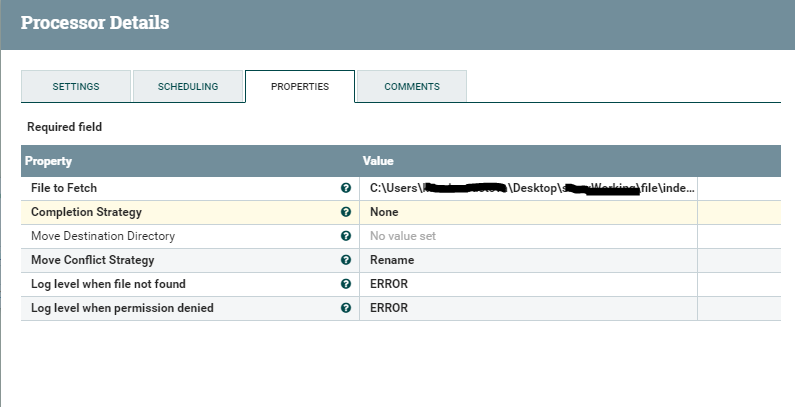
And then the PutSftp square - puts the file in the file storage. Configuration parameters can be seen below.
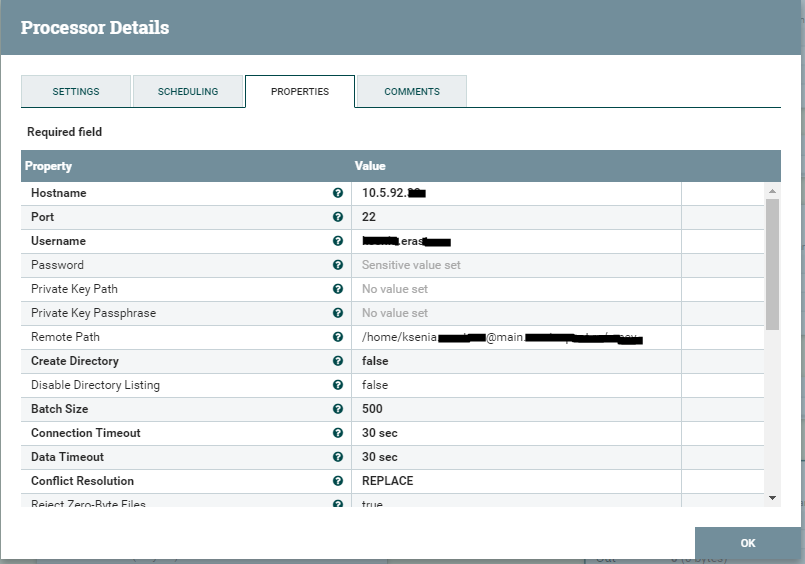
It is worth paying attention to the fact that each square is a separate process that must be started. We examined the simplest example that does not require any complicated customization. Next, we consider the process a little more complicated, where we write a little bit on the grooves.
More complex example
The data transfer service to the consumer turned out to be a little more complicated due to the process of modifying the SOAP message. The overall process is presented in the figure below.

Here, the idea is also not very complicated: we received a request from the consumer that they needed data, sent a response that they received a message, started the process of receiving a response file, then edited it with certain logic, and then transferred the file to the consumer in the form of a SOAP message to the server.
I think it’s not worth describing again the squares that we saw above - we will go straight to the new ones. If you need to edit a file and regular squares like ReplaceText are not suitable, you will have to write your own script. This can be done using the ExecuteGroogyScript square. Its settings are presented below.
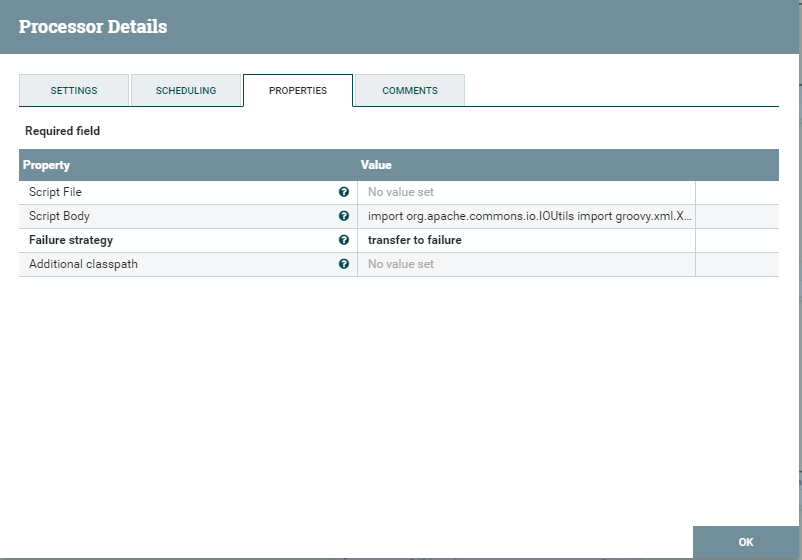
There are two options for loading the script into this square. The first is by loading the script file. The second is by inserting a script into scriptBody. As far as I know, the executeScript square supports several PLs - one of them is groovy. I will disappoint developers java - you cannot write scripts in such squares in java. For those who really want to - you need to create your own custom square and throw it into the NIFI system. This whole operation is accompanied by rather lengthy dances with a tambourine, which we will not deal with in the framework of this article. I chose groovy language. Below is a test script that simply incrementally updates the id in the SOAP message. It is important to note. You take the file from flowFile, update it, do not forget that you need it, updated, put it back there. It is also worth noting that not all libraries are connected. It may happen that you still have to import one of the libs. The downside is that the script in this square is quite difficult to debut. There is a way to connect to the JVM NIFI and start the debugging process. Personally, I ran a local application and simulated getting a file from a session. Debugging was also done locally. Errors that come out when loading a script are pretty easy to google and are written by NIFI to the log.
import org.apache.commons.io.IOUtils import groovy.xml.XmlUtil import java.nio.charset.* import groovy.xml.StreamingMarkupBuilder def flowFile = session.get() if (!flowFile) return try { flowFile = session.write(flowFile, { inputStream, outputStream -> String result = IOUtils.toString(inputStream, "UTF-8"); def recordIn = new XmlSlurper().parseText(result) def element = recordIn.depthFirst().find { it.name() == 'id' } def newId = Integer.parseInt(element.toString()) + 1 def recordOut = new XmlSlurper().parseText(result) recordOut.Body.ClientMessage.RequestMessage.RequestContent.content.MessagePrimaryContent.ResponseBody.id = newId def res = new StreamingMarkupBuilder().bind { mkp.yield recordOut }.toString() outputStream.write(res.getBytes(StandardCharsets.UTF_8)) } as StreamCallback) session.transfer(flowFile, REL_SUCCESS) } catch(Exception e) { log.error("Error during processing of validate.groovy", e) session.transfer(flowFile, REL_FAILURE) }
Actually on this the customization of the square ends. Next, the updated file is transferred to the square, which is engaged in sending the file to the server. Below are the settings for this square.
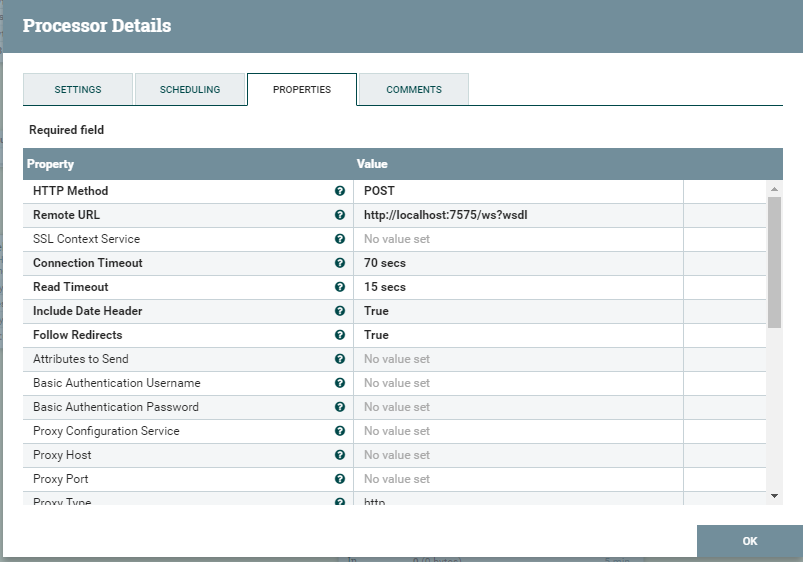
We describe the method by which the SOAP message will be transmitted. We write to where. Next, you need to indicate that this is exactly SOAP.
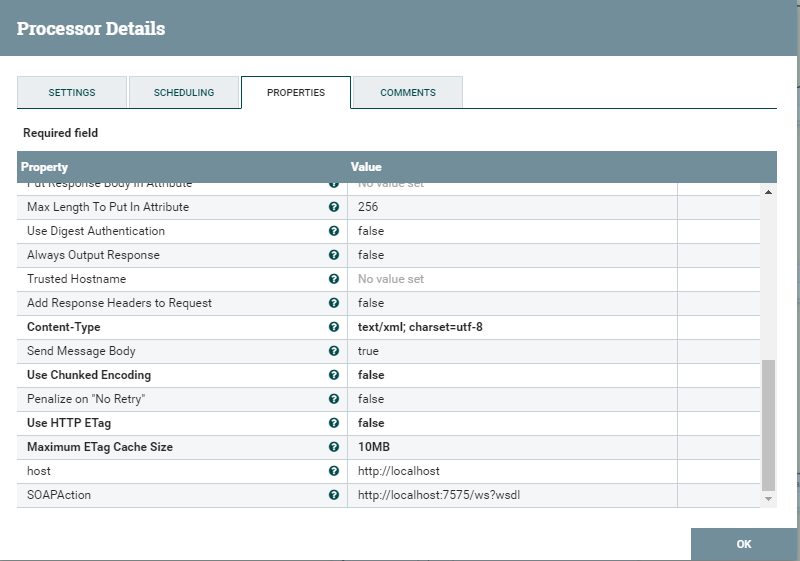
We add some properties such as host and action (soapAction). Save, check. More details on how to send SOAP requests can be found here.
We looked at several uses of NIFI processes. How they interact and what real benefit they have. The examples considered are test ones and are slightly different from what is real in battle. I hope this article will be a little useful for developers. Thanks for your attention. If you have any questions - write. I will try to answer.
All Articles