Face recognition at the knee-applied level
In general, face recognition and identification of people according to their results looks like teenage sex for elders - everyone talks a lot about him, but few practice. It is clear that we are no longer surprised that after downloading photos from friendly gatherings, Facebook / VK suggests marking the people found in the picture, but here we intuitively know that social networks have a good help in the form of a graph of person connections. And if there is no such graph? However, let's start in order.

Initially, face recognition and identification of “friend / foe” with us grew out of exclusively domestic needs - drug addicts got into a colleague’s staircase, and constantly monitor the picture from the installed video camera, and even disassemble where the neighbor and where the stranger had no desire no.
Therefore, literally in a week, a prototype consisting of an IP camera, a single-plate device, a motion sensor and the Python face recognition library face_recognition was assembled on the knee. Since the python library was on a single-plate, rather powerful hardware ... let's say it carefully, not very fast, we decided to build the processing process as follows:
The whole process was glued together by our beloved Erlang, and in the process of testing on colleagues he proved his minimal working capacity.
However, the assembled model did not find application in real life - not because of its technical imperfection, which undoubtedly was - as experience shows, collected on a knee in greenhouse office conditions has a very bad tendency to break in the field, and at the time of demonstration to the customer , and because of the organizational ones, the inhabitants of the entrance refused the majority of any video surveillance.
The project went on the shelf and periodically poked with a stick for demonstrations during sales and the urge to reincarnate in the personal household.
Everything has changed since the moment when we had a more specific and quite commercial project on the same topic. Since it would not be possible to cut corners in it using a motion sensor directly from the statement of the problem, I had to delve deeper into the nuances of searching and recognizing faces in three heads (okay, two and a half, if you count mine) directly on the stream. And then a revelation happened.
The trouble is that most of the findings on this issue are purely academic sketches on the topic that “I had to write an article in a magazine on a fashionable topic and get a tick for publishing.” I do not detract from the merits of scientists - among the papers I found there were a lot of useful and interesting, but, alas, I have to admit that the reproducibility of the work of their code posted on Github leaves much to be desired or looks like a dubious undertaking with time wasted in the end.
Numerous frameworks for neural networks and machine learning were often difficult to lift - face recognition was a separate narrow task for them, uninteresting in a wide range of problems that they solved. In other words, to take a ready-made example and run it on the target hardware just to check how it works and whether it works, did not work. That was not an example, then the need to obtain it suggested a sour quest from the assembly of certain libraries of certain versions for strictly defined OS. Those. to take and fly on the move - literally crumbs like the previously mentioned face_recognition, which we used for the previous crafts.
Big companies, as always, saved us. Both Intel and Nvidia have long felt the growing momentum and commercial appeal of this class of tasks, but, being suppliers of equipment in the first place, they distribute their frameworks for solving specific application problems for free.
Our project was more likely not of a research, but of an experimental nature, so we did not analyze and compare the solutions of individual vendors, but simply took the first one with the aim of collecting a ready-made prototype and testing it in battle, while receiving the fastest response. Therefore, the choice very quickly fell on Intel OpenVINO - a library for the practical application of machine learning in applied tasks.
To get started, we put together a stand, which is traditionally a nettop kit with an Intel Core i3 processor and IP cameras from Chinese vendors on the market. The camera was directly connected to the nettop and supplied it with an RTSP stream with a not very large FPS, based on the assumption that people still would not run in front of it like in competitions. The processing speed of one frame (search and recognition of faces) fluctuated in the region of tens to hundreds of milliseconds, which was quite enough to embed the search mechanism for persons using existing samples. In addition, we also had a backup plan - Intel has a special coprocessor to speed up the calculations of Neural Compute Stick 2 neural networks, which we could use if we did not have a general-purpose processor. But - so far nothing has happened.
After completing the assembly and verifying the functionality of the basic examples - a distinctive feature of the Intel SDK was in a step-by-step and very detailed example guide - we started building the software.
The main task facing us was to search for a person in the camera’s field of view, her identification and timely notification of her presence. Accordingly, in addition to recognizing faces and comparing them with patterns (how to do this, at that time, raised no less questions than everything else), we needed to provide secondary things of the interface plan. Namely, we must receive frames with the faces of the necessary persons from the same camera for their subsequent identification. Why, from the same camera, I think it’s also quite obvious - the camera’s installation point on the object and the lens optics introduce certain distortions, which, presumably, can affect the quality of recognition, we use a different source of source data than a tracking tool.
Those. In addition to the stream handler itself, we need at least a video archive and a video file analyzer that will isolate all detected faces from the recording and save the most suitable ones as reference ones.
As always, we took the familiar Erlang and PostgreSQL as glue between ffmpeg, applications on OpenVINO and Telegram Bot API for notification. In addition, we needed a web-UI to provide the minimum set of procedures for managing the complex, which our colleague-front-ender had uploaded to VueJS.
The logic of work was as follows:
It looks something like this:
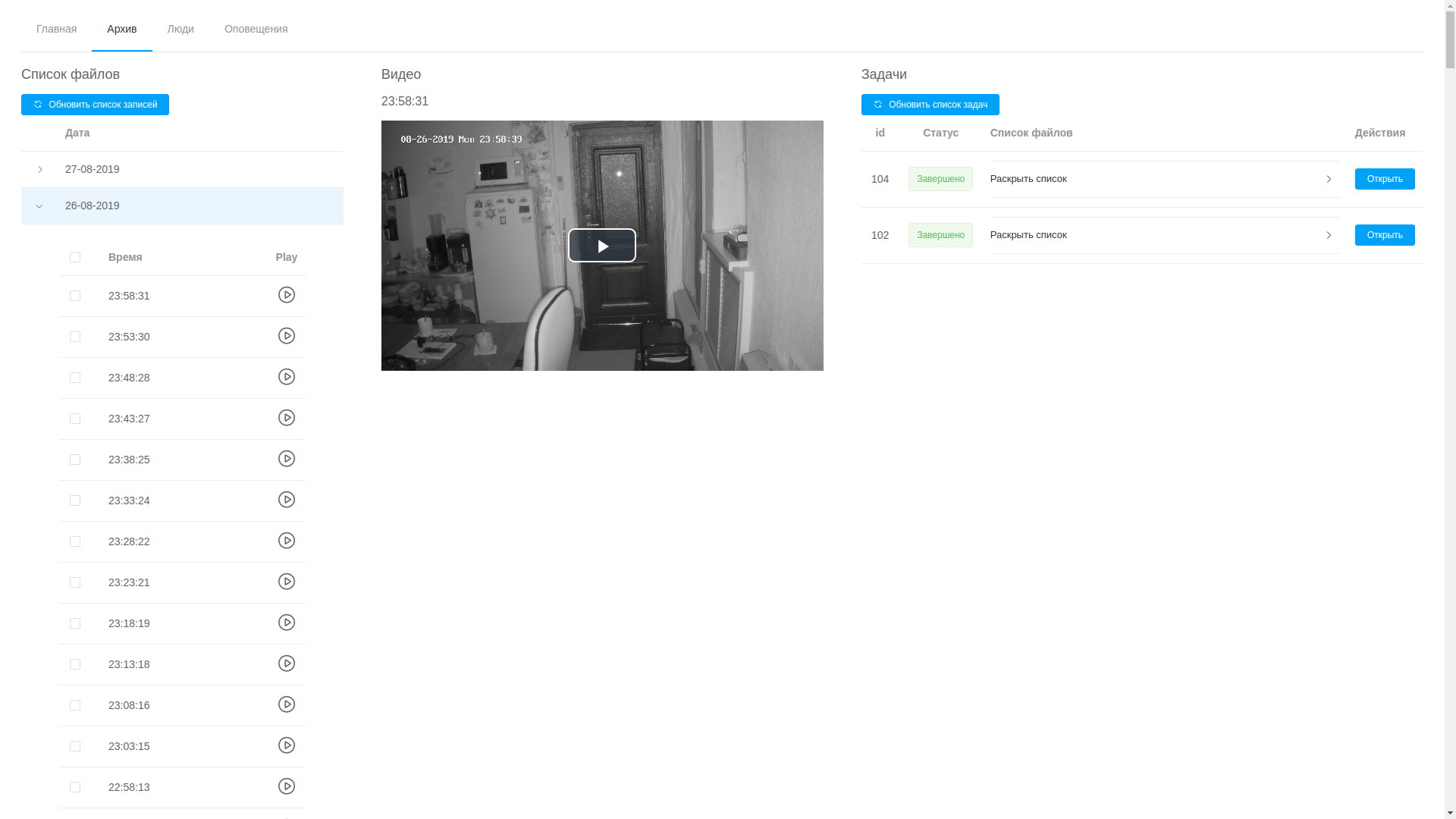
View archive
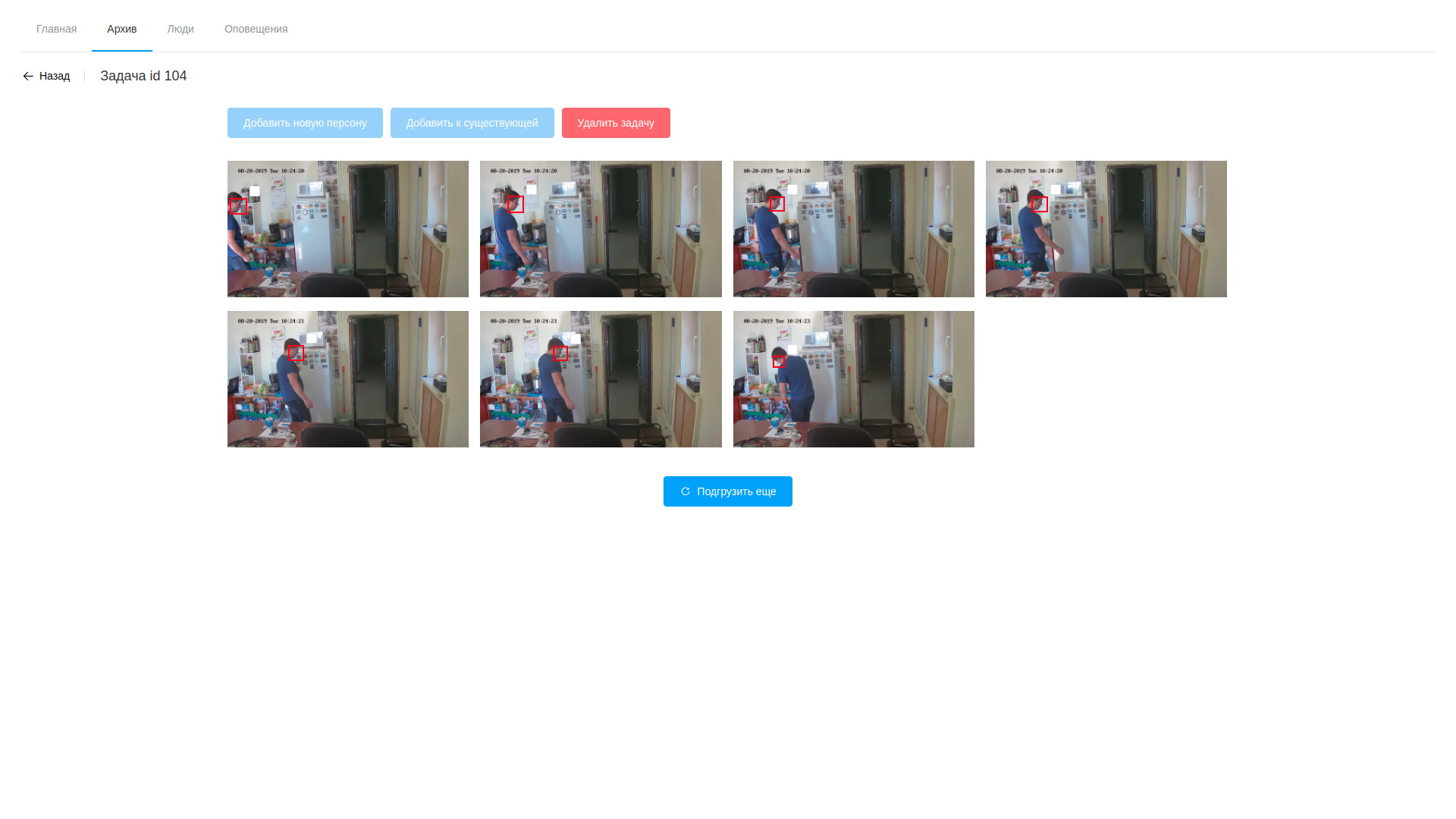
Video Analysis Results
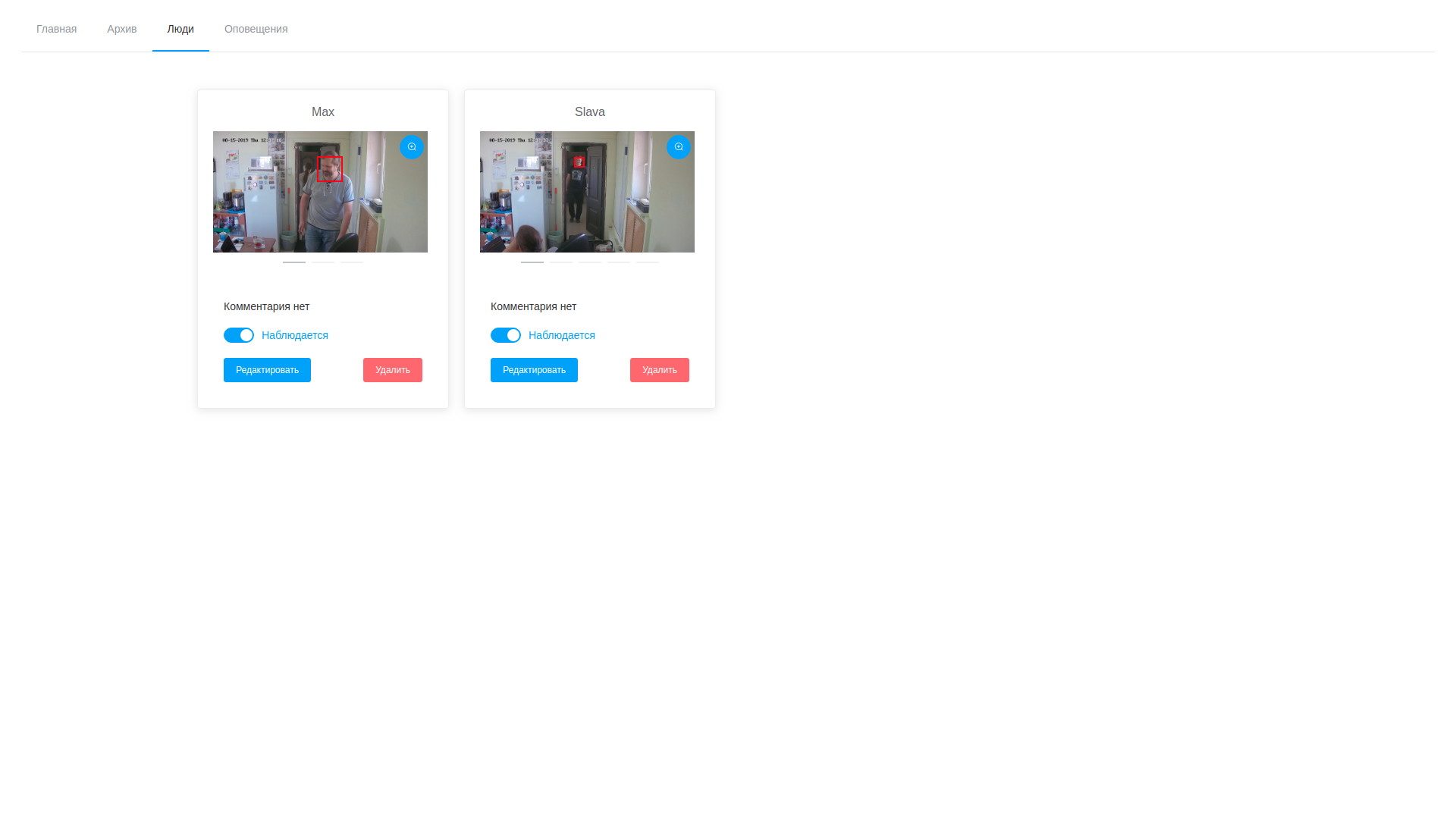
List of observed personalities
The resulting solution is in many ways controversial and sometimes even not optimal both in terms of productivity and in terms of reducing reaction time. But, I repeat, we did not have a goal to get an effective system right away, but simply to go this route and fill the maximum number of cones, identify narrow paths and potential non-obvious problems.
The assembled system was tested in greenhouse office conditions for a week. During this time, the following observations were noted:
What is ahead? Checking the system in battle, optimizing the detection processing cycle, simplifying the procedure for searching for events in the video archive, adding more data to the analysis (age, gender, emotions) and another 100,500 small and not-so tasks that still need to be done. But the first step in the path of a thousand steps we have already taken. If anyone shares their experience in solving such problems or gives interesting links on this issue - I will be very grateful.
Initially, face recognition and identification of “friend / foe” with us grew out of exclusively domestic needs - drug addicts got into a colleague’s staircase, and constantly monitor the picture from the installed video camera, and even disassemble where the neighbor and where the stranger had no desire no.
Therefore, literally in a week, a prototype consisting of an IP camera, a single-plate device, a motion sensor and the Python face recognition library face_recognition was assembled on the knee. Since the python library was on a single-plate, rather powerful hardware ... let's say it carefully, not very fast, we decided to build the processing process as follows:
- the motion sensor determines whether there is movement in the area of space entrusted to it and signals its presence;
- a written service based on gstreamer, which constantly receives a stream from an IP camera, cuts off 5 seconds before and 10 seconds after detection and feeds it to an analysis recognition library;
- she, in turn, watches the video, finds faces there, compares them with known samples, and if unknown is found, gives the video to the Telegram channel, later it was supposed to be controlled in the same place to immediately cut off false positives - for example, when a neighbor turned to the camera on the wrong side on the samples.
The whole process was glued together by our beloved Erlang, and in the process of testing on colleagues he proved his minimal working capacity.
However, the assembled model did not find application in real life - not because of its technical imperfection, which undoubtedly was - as experience shows, collected on a knee in greenhouse office conditions has a very bad tendency to break in the field, and at the time of demonstration to the customer , and because of the organizational ones, the inhabitants of the entrance refused the majority of any video surveillance.
The project went on the shelf and periodically poked with a stick for demonstrations during sales and the urge to reincarnate in the personal household.
Everything has changed since the moment when we had a more specific and quite commercial project on the same topic. Since it would not be possible to cut corners in it using a motion sensor directly from the statement of the problem, I had to delve deeper into the nuances of searching and recognizing faces in three heads (okay, two and a half, if you count mine) directly on the stream. And then a revelation happened.
The trouble is that most of the findings on this issue are purely academic sketches on the topic that “I had to write an article in a magazine on a fashionable topic and get a tick for publishing.” I do not detract from the merits of scientists - among the papers I found there were a lot of useful and interesting, but, alas, I have to admit that the reproducibility of the work of their code posted on Github leaves much to be desired or looks like a dubious undertaking with time wasted in the end.
Numerous frameworks for neural networks and machine learning were often difficult to lift - face recognition was a separate narrow task for them, uninteresting in a wide range of problems that they solved. In other words, to take a ready-made example and run it on the target hardware just to check how it works and whether it works, did not work. That was not an example, then the need to obtain it suggested a sour quest from the assembly of certain libraries of certain versions for strictly defined OS. Those. to take and fly on the move - literally crumbs like the previously mentioned face_recognition, which we used for the previous crafts.
Big companies, as always, saved us. Both Intel and Nvidia have long felt the growing momentum and commercial appeal of this class of tasks, but, being suppliers of equipment in the first place, they distribute their frameworks for solving specific application problems for free.
Our project was more likely not of a research, but of an experimental nature, so we did not analyze and compare the solutions of individual vendors, but simply took the first one with the aim of collecting a ready-made prototype and testing it in battle, while receiving the fastest response. Therefore, the choice very quickly fell on Intel OpenVINO - a library for the practical application of machine learning in applied tasks.
To get started, we put together a stand, which is traditionally a nettop kit with an Intel Core i3 processor and IP cameras from Chinese vendors on the market. The camera was directly connected to the nettop and supplied it with an RTSP stream with a not very large FPS, based on the assumption that people still would not run in front of it like in competitions. The processing speed of one frame (search and recognition of faces) fluctuated in the region of tens to hundreds of milliseconds, which was quite enough to embed the search mechanism for persons using existing samples. In addition, we also had a backup plan - Intel has a special coprocessor to speed up the calculations of Neural Compute Stick 2 neural networks, which we could use if we did not have a general-purpose processor. But - so far nothing has happened.
After completing the assembly and verifying the functionality of the basic examples - a distinctive feature of the Intel SDK was in a step-by-step and very detailed example guide - we started building the software.
The main task facing us was to search for a person in the camera’s field of view, her identification and timely notification of her presence. Accordingly, in addition to recognizing faces and comparing them with patterns (how to do this, at that time, raised no less questions than everything else), we needed to provide secondary things of the interface plan. Namely, we must receive frames with the faces of the necessary persons from the same camera for their subsequent identification. Why, from the same camera, I think it’s also quite obvious - the camera’s installation point on the object and the lens optics introduce certain distortions, which, presumably, can affect the quality of recognition, we use a different source of source data than a tracking tool.
Those. In addition to the stream handler itself, we need at least a video archive and a video file analyzer that will isolate all detected faces from the recording and save the most suitable ones as reference ones.
As always, we took the familiar Erlang and PostgreSQL as glue between ffmpeg, applications on OpenVINO and Telegram Bot API for notification. In addition, we needed a web-UI to provide the minimum set of procedures for managing the complex, which our colleague-front-ender had uploaded to VueJS.
The logic of work was as follows:
- under control of a control plane (in Erlang) ffmpeg writes a stream from the camera to the video in five-minute sections, a separate process ensures that the records are stored in a strictly specified volume and cleans the oldest when this threshold is reached;
- through the web-UI you can view any record, they are arranged in chronological order, which, although not without difficulty, allows you to isolate the desired fragment and send it for processing;
- the processing consists in analyzing the video and extracting frames with detected faces, it just does the OpenVINO-based software (I must say, here we managed to cut the angle a bit - the software for analyzing the stream and analyzing files is almost identical, which is why most of it went to shared library, and the utilities themselves differ only in the processing chain a la modular gstreamer). Processing takes place by video, isolating the found faces using a specially trained neural network. The resulting fragments of the frame containing faces fall into another neural network, which forms a 256-element vector, which is, in fact, the coordinates of the reference points of a person’s face. This vector, the detected frame, and the coordinates of the rectangle of the found face are stored in the database;
- further, after the processing is completed, the operator opens the variety of drawn frames, is horrified by their number and proceeds to search for target people. Selected samples can be added to an existing person or create a new one. After the processing of the task is completed, the analysis results are deleted, with the exception of saved vectors mapped to observational records;
- accordingly, we can look at both frames and detection vectors at any time and edit, deleting unsuccessful samples;
- parallel to the detection cycle in the background, the stream analysis service always works, which does the same thing, but with the stream from the camera. He selects faces in the observed flow and compares them with samples from the database, which is based on the simple assumption that the vectors of one person will be closer to each other than to all other vectors. A pairwise calculation of the distance between the vectors takes place, upon reaching the threshold of operation, a record of detection and a frame are put in the database. In addition, a person is added to the stop list in the near future, which avoids multiple notifications about the same person;
- the control plane periodically checks the detection log and, in the event of new entries, notifies with a message with the attached photo and highlighting the face through the bot to those who are allowed according to the settings.
It looks something like this:
View archive
Video Analysis Results
List of observed personalities
The resulting solution is in many ways controversial and sometimes even not optimal both in terms of productivity and in terms of reducing reaction time. But, I repeat, we did not have a goal to get an effective system right away, but simply to go this route and fill the maximum number of cones, identify narrow paths and potential non-obvious problems.
The assembled system was tested in greenhouse office conditions for a week. During this time, the following observations were noted:
- there is a clear dependence of the quality of recognition on the quality of the original samples. If the observed person passes through the observation zone too quickly, then with a high degree of probability he will not leave data for sampling and will not be recognized. However, I think this is a matter of fine-tuning the system, including lighting and video stream parameters;
- since the system operates with recognition of face elements (eyes, nose, mouth, eyebrows, etc.), it is easy to deceive by putting a visual obstacle between the face and the camera (hair, dark glasses, wearing a hood, etc.) - the face, most likely, it will be found, but the comparison with the samples will not work due to the strong discrepancy between the detection vectors and the samples;
- ordinary glasses do not affect too much - we had examples of positive responses in people with glasses and false-negative responses in people who put on glasses for testing;
- if the beard was on the original samples, and then it was gone, then the number of operations is reduced (the author of these lines trimmed his beard to 2 mm and the number of operations on it was halved);
- false positives also took place, this is an occasion for further immersion in mathematics of the issue and, possibly, a solution to the problem of partial correspondence of vectors and the optimal method for calculating the distance between them. However, field testing should reveal even more problems in this regard.
What is ahead? Checking the system in battle, optimizing the detection processing cycle, simplifying the procedure for searching for events in the video archive, adding more data to the analysis (age, gender, emotions) and another 100,500 small and not-so tasks that still need to be done. But the first step in the path of a thousand steps we have already taken. If anyone shares their experience in solving such problems or gives interesting links on this issue - I will be very grateful.
All Articles