Web scraping with R. Comparison of movie ratings on Kinopoisk and IMDB

The World Wide Web is an ocean of data. Here you can see almost any information you are interested in. However, "pulling" this information from the Internet is already more difficult. There are several ways to get data and web-scraping is one of them.
What is web scraping? In short, it is a technology that allows you to extract data from HTML pages. When using scraping, there is no need to copy-paste the necessary information or transfer it from the screen to notepad. Information will appear on your computer in a form convenient for you.
Web-scraping on the example of the site Kinopoisk.ru
It’s a good idea to set yourself a goal in order not to do scraping for scraping. I decided that this would be a comparison of the ratings of films on the sites Kinopoisk.ru and IMDB.com, as well as the average ratings of films by genre . For analysis, films were taken that were released from 2010 to 2018, with a minimum of 500 votes.
To get started, load the libraries we need:
# library(rvest) library(selectr) library(xml2) library(jsonlite) library(tidyverse)
Next, I get the number of films in a year that satisfy the selection condition (more than 500 votes). This is done in order to find out the total number of pages with data and to “generate” links to them, because links are similar in structure.
# 2018 url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
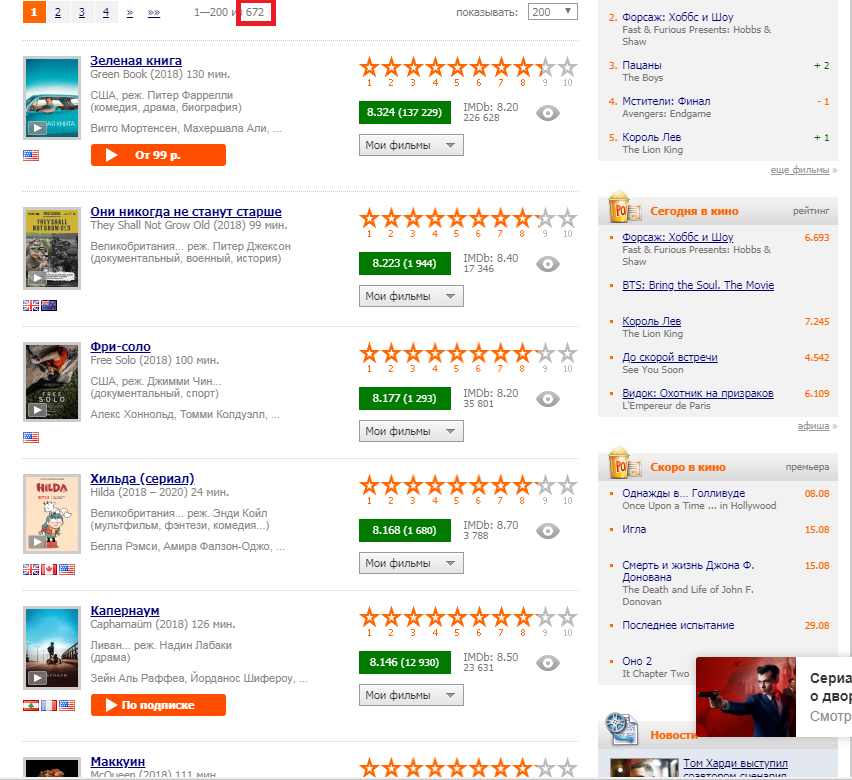
Our task is to "pull out" the number 672, highlighted in the picture by a red rectangle. For this we need web-scraping.
Kinopoisk.ru site web-scraping pages using the rvest
package
First we need to "read" the url we received. To do this, use the read_html()
function of the read_html()
package.
# XML HTML webpage <- read_html(url)
And then, using the functions of the rvest
package rvest
we first “extract” the part of the HTML document that we need (the html_nodes()
function), and then from this part we extract the information we need in a form convenient for us (the html_text()
, html_table()
functions, html_attr()
other)
But how do we understand which element we need to extract? To do this, we must hover over the information that interests us, click LMB and select "view code". In our case, we get the following picture:
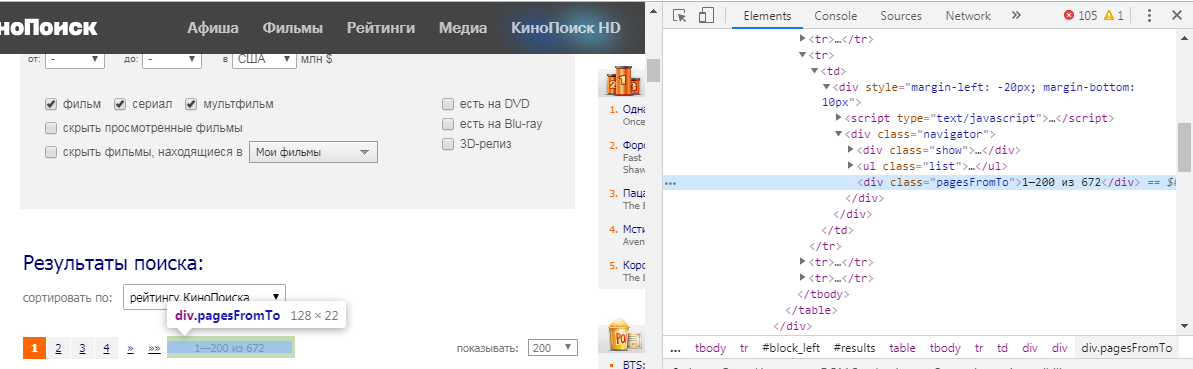
The html_nodes()
function has the form html_nodes(x, css)
. x is the webpage defined earlier, but in css we write the id or element class. In our case, it is:
number_html <- html_nodes(webpage, ".pagesFromTo")
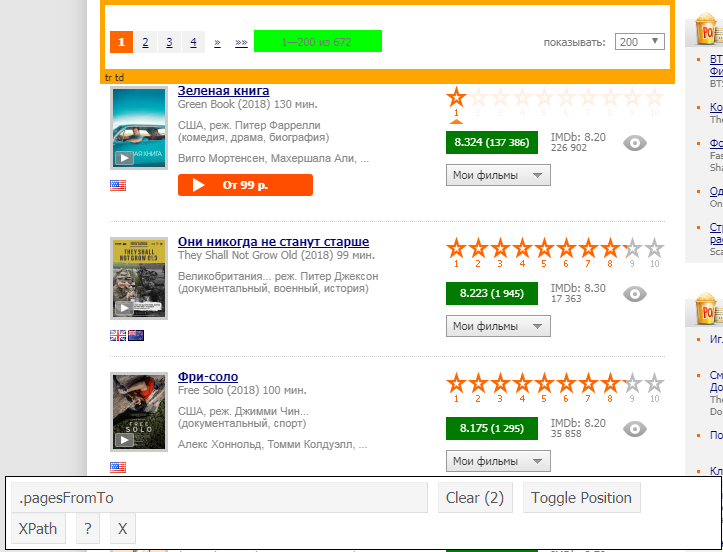
Also, to "detect" the desired element, you can use the selectorGadget extension, which shows what we need to enter explicitly:
Next, with the html_text function, we extract the text part from the selected element:
number <- html_text(number_html) [1] "1—50 672" "1—50 672"
We got the number we needed from Kinopoisk's HTML page, but now we need to "clear it". This is a standard procedure for scraping, because very rarely we need the element we need in the form we need.
We got 2 identical elements due to the fact that the total number of films is indicated at the top and bottom of the page and their css selector is exactly the same. Therefore, for starters, we remove the excess element:
number <- number[1] [1] "1—50 672"
Next, we need to get rid of the part of the vector that goes up to the number 672. You can do this in different ways, but the basis of all the methods is writing a regular expression. In this case, I “replace” the “1-50 of” part with a void (you can use str_remove
instead of str_replace
), then remove the extra spaces ( str_trim
function) and finally translate the vector from character to numeric type. At the output I get the number 672. Exactly so many films of 2018 have more than 500 user votes on Kinopoisk.
number <- str_replace(number, ".{2,}", "") number <- as.numeric(str_trim(number)) [1] 672
What do we do next? If you look through the pages on Kinopoisk you will see that the addresses of the search pages have the same structure and differ only in number. Therefore, in order not to enter the page address manually each time, we will calculate the number of pages and “generate” the required number of addresses. It is done like this:
# page_number <- ceiling(number/50) # page <- sapply(seq(1:page_number), function(n){ list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results") })
The output is 14 addresses. The ceiling
function in this example rounds a number to a BIG integer.
And then we use the lapply
function to the input of which the addresses of the pages are fed, and the function "extracts" information from the Kinopoisk pages about the name, rating, number of votes and main genres (maximum 3) of the film. Function code can be found in the repository on Github .
As a result, we get a table with 8111 films.
| NAME | Rating | VOTES | GENRE | Year |
|---|---|---|---|---|
| sherlock | 8.884 | 235316 | thriller, drama, crime | 2010 |
| running Man | 8.812 | 1917 | game, real tv, comedy | 2010 |
| Great War | 8.792 | 5690 | documentary, military, history | 2010 |
| discovery how the universe works | 8.740 | 3033 | documentary | 2010 |
| Start | 8.664 | 533715 | fiction, action, thriller | 2010 |
| discovery into the universe with steven hawking | 8.520 | 4373 | documentary | 2010 |
It is worth noting about the use of the Sys.sleep function. Using it, you can set the delay time between expressions. Why is this needed? If you want to receive information on one year, then there is no need. But if you are interested in a large number of films / years, then after a certain number of requests, Kinopoisk will consider you a robot and you will receive an empty list for your request. To avoid this, you need to enter the delay time.
Similarly, "scrap" the site IMDB.com.
Data Analysis
We have two tables, in one information about films with IMDB, in the other from Kinopoisk. Now we need to combine them. We will unite according to the columns NAME and YEAR. In order to reduce the number of discrepancies in the names, even at the stage of scraping, I removed all punctuation marks and converted the letters to lower case. As a result, after all connections and deletions, we get 3450 films that have the information we need from both sites.
I'm interested in the difference in the ratings of films on two sites, so we will create the DELTA variable, which is the difference between the estimates of IMDB and Kinopoisk. If DELTA is positive, then the IMDB score is higher; if negative, then lower.
First, construct a histogram for the DELTA indicator:
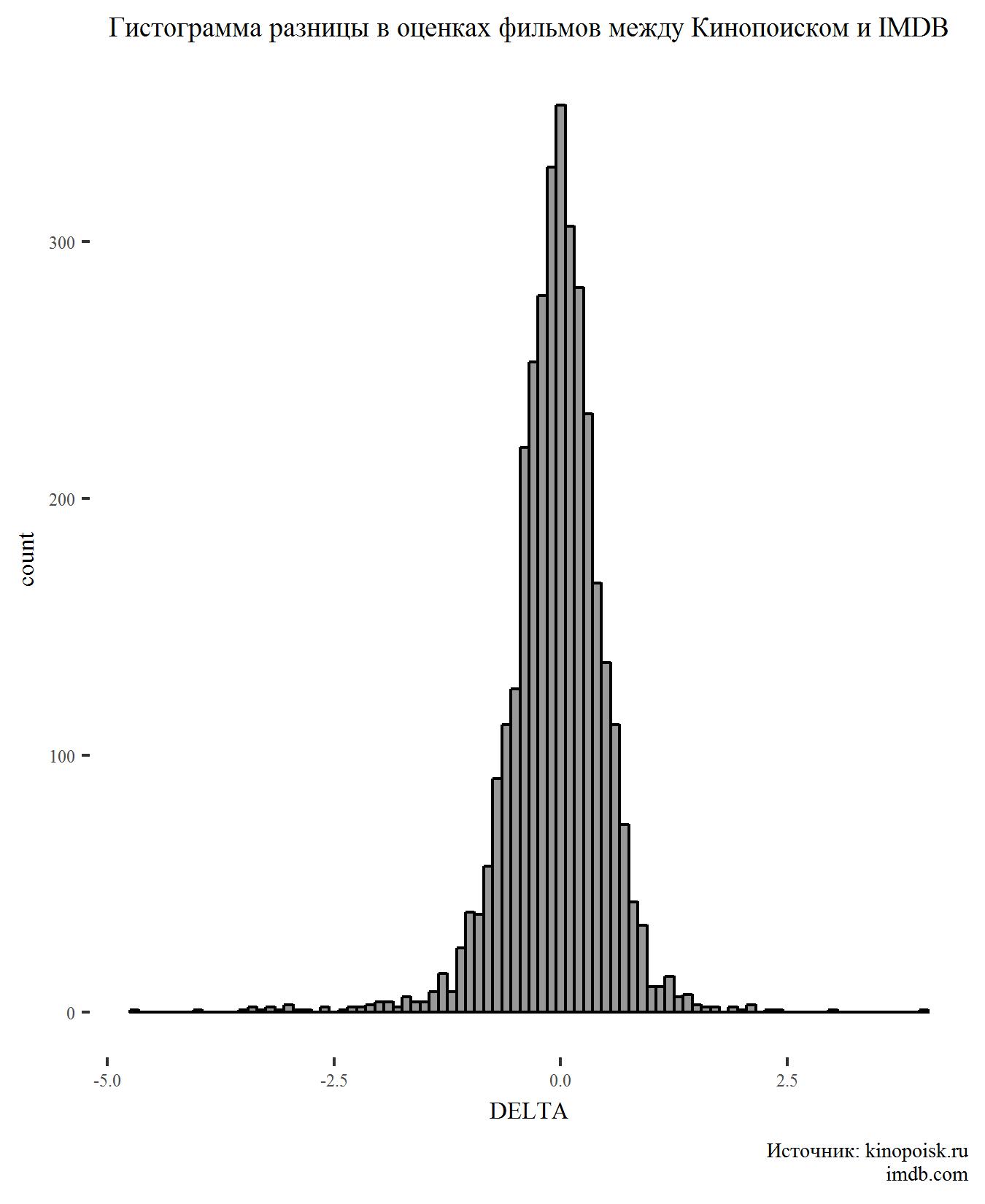
There is nothing surprising on the chart. The difference in ratings has a normal distribution and a peak in the region of zero, which suggests that users of the two sites usually agree in the assessment of films.
Converge, but not quite. The t-test of two independent samples allows us to say that the ratings on Kinopoisk are higher and this difference is statistically significant (p-value <0.05).
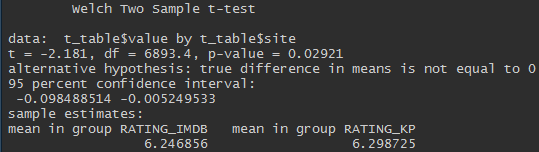
Although the difference is significant, it is very small.
Next, let's see how the difference in ratings depends on the number of votes.
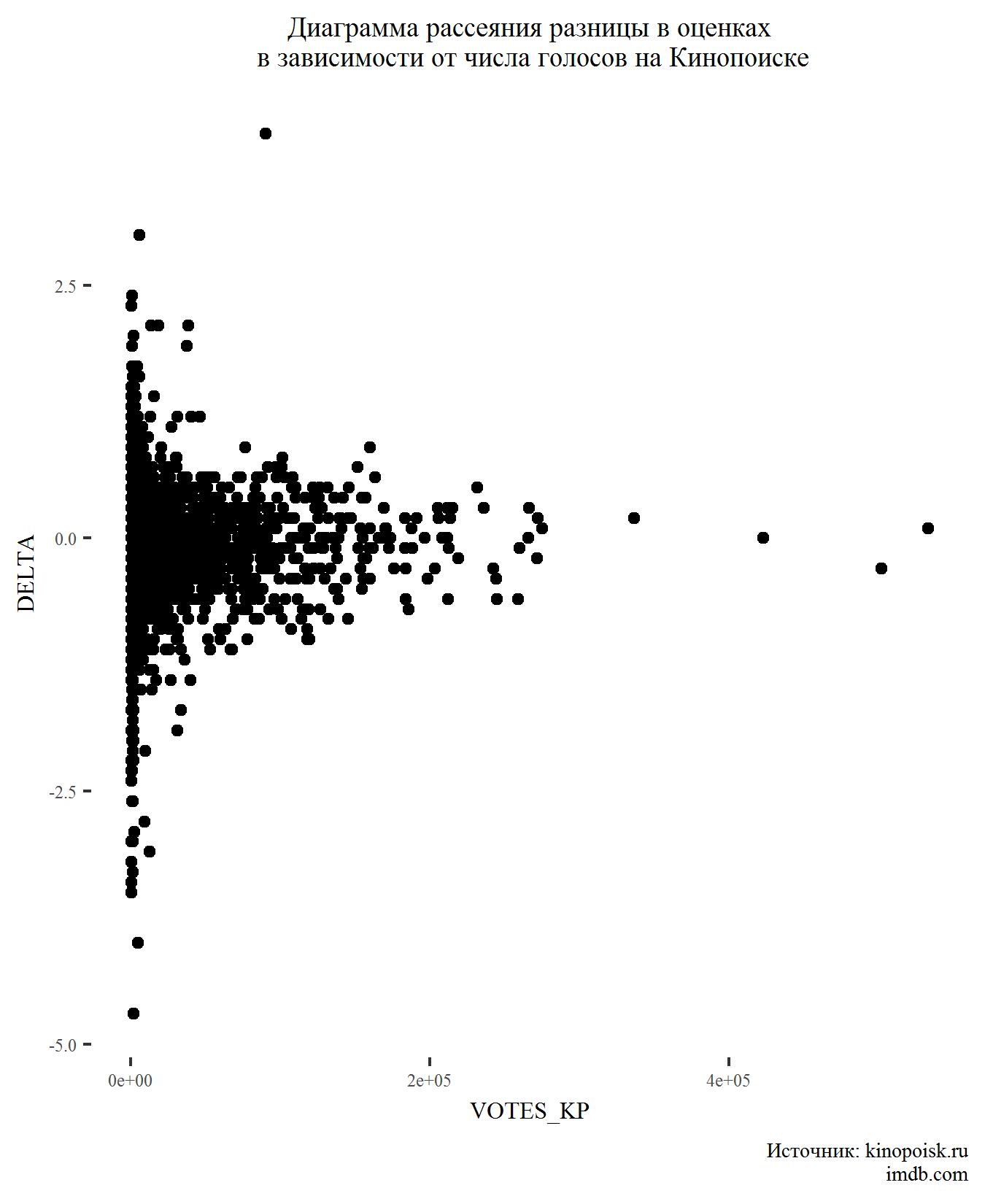
Nothing unexpected here either. Films with a large number of votes usually have very little difference in ratings.
Now let's move on to evaluating films by genre. It is worth noting right away that one film can have up to three genres, but only one rating, so one film can go "into the test" and comedy, and melodrama.
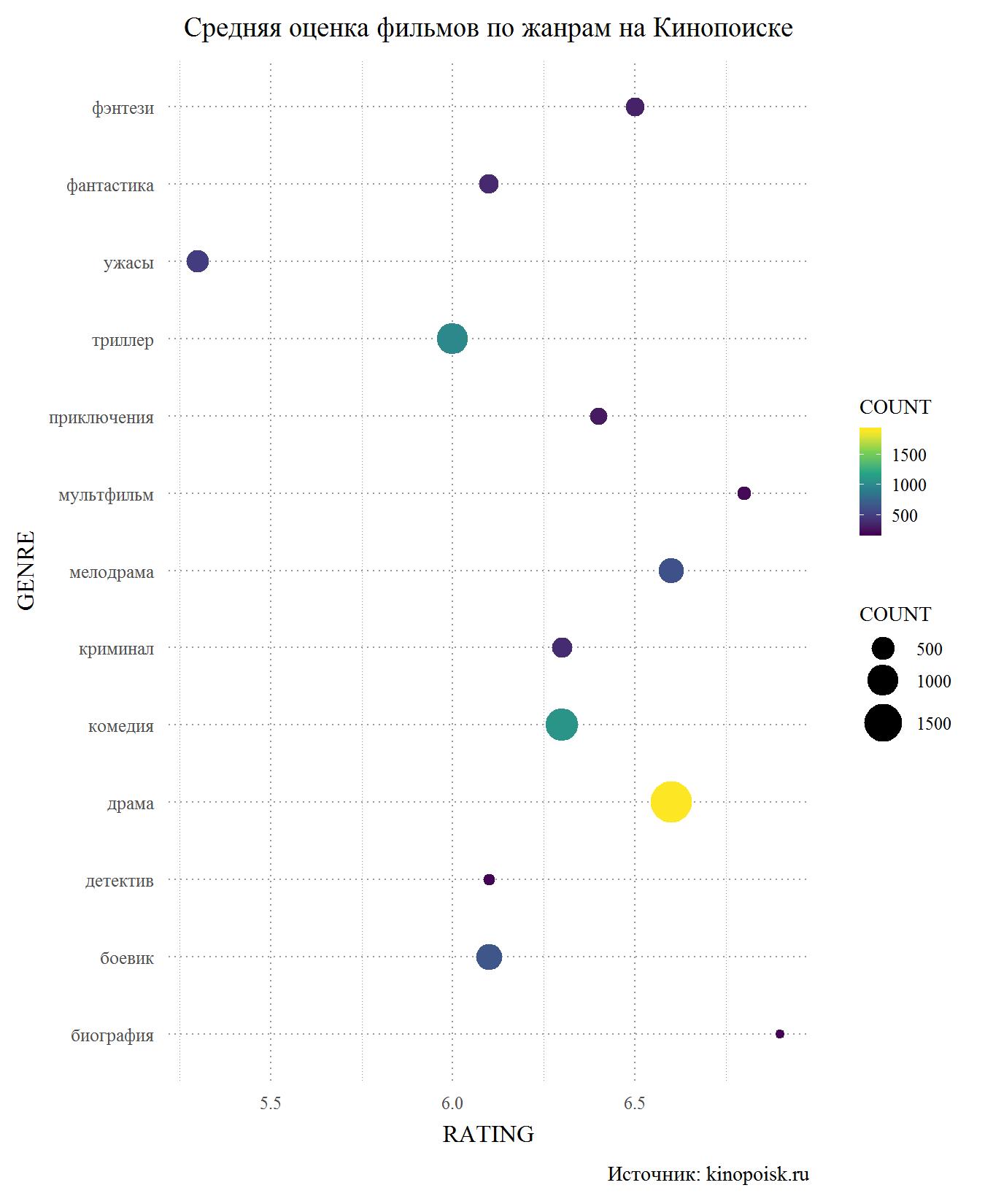
Let's start with Kinopoisk. Among genres with at least 150 appearances in the database, horror is an obvious outsider. Also low users rate thrillers, action detectives and, what was surprising to me, science fiction. On the other hand, melodramatic films on Kinopoisk come up with a bang, having an average rating above 6.5 and second only to cartoons and biopic, which are much smaller in the database
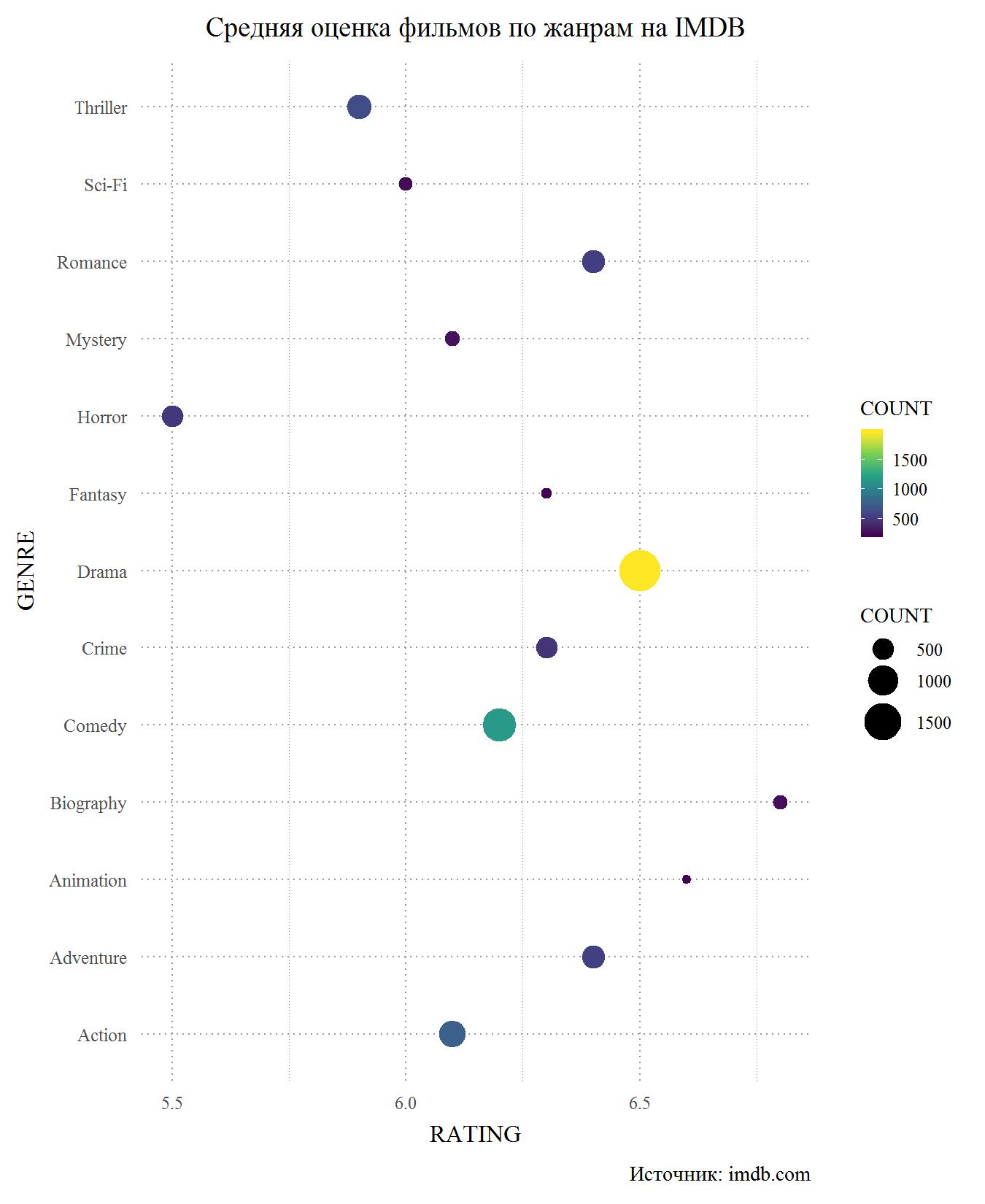
Now consider the same chart, but for IMDB. In principle, he again confirms that the difference in ratings between the sites is insignificant. This is not surprising, because many users have accounts on both sites and are unlikely to give different ratings on different sites. Again, the main loser is the horrors and we can say that they are the lowest rated genre of films. It’s hard for me to evaluate why this happens, because the only horror movie that I watched in my life is Gremlins. Perhaps it is the horrors that are the lowest budget genre, where the weak play of cheap actors and frankly bad scenarios come from. Thrillers with science fiction and on IMDB are among the laggards, but the militants are doing better. Among the leaders are again biographical films and cartoons. The drama holds third place, but the score for melodramas fell below 6.5, to the level of adventure films. Also on IMDB below comedies.
Conclusion and a little about the "external factors"
Although there is a difference in the estimates (on Kinopoisk they are slightly higher), but it’s that a little. According to various genres, the big difference is also imperceptible. Blockbusters that have dozens or even hundreds of thousands of votes, if they have differences, then within 0.5 points.
Movies with a small (especially on Kinopoisk) number of votes, up to 10 thousand, usually have a big difference in ratings. However, the biggest difference in the rating in favor of IMDB is the film with 30,000 votes on a foreign site and more than 90,000 on Kinopoisk. This is the creation of Alexei Pimanov "Crimea". Is the movie so liked by foreign viewers? Hardly. Most likely, the filmmakers used the same "marketing policy" with respect to IMDB as in Kinopoisk. It’s just that if Kinopoisk “cleaned up” such estimates, then they remained on IMDB. I think that’s why there “Crimea” is a “good little kinchik”.
I would be grateful for any comments, suggestions, complaints
Link to the Github repository
My Circle Profile
All Articles