Solving a job with pwnable.kr 17 - memcpy. Data alignment

In this article we will deal with data alignment, and also solve the 17th task from the site pwnable.kr .
Organizational Information
Especially for those who want to learn something new and develop in any of the areas of information and computer security, I will write and talk about the following categories:
In addition to this, I will share my experience in computer forensics, analysis of malware and firmware, attacks on wireless networks and local area networks, conducting pentests and writing exploits.
So that you can find out about new articles, software and other information, I created a channel in Telegram and a group to discuss any issues in the field of ICD. Also, I will personally consider your personal requests, questions, suggestions and recommendations personally and will answer everyone .
All information is provided for educational purposes only. The author of this document does not bear any responsibility for any damage caused to anyone as a result of using knowledge and methods obtained as a result of studying this document.
- PWN;
- cryptography (Crypto);
- network technologies (Network);
- reverse (Reverse Engineering);
- steganography (Stegano);
- search and exploitation of WEB vulnerabilities.
In addition to this, I will share my experience in computer forensics, analysis of malware and firmware, attacks on wireless networks and local area networks, conducting pentests and writing exploits.
So that you can find out about new articles, software and other information, I created a channel in Telegram and a group to discuss any issues in the field of ICD. Also, I will personally consider your personal requests, questions, suggestions and recommendations personally and will answer everyone .
All information is provided for educational purposes only. The author of this document does not bear any responsibility for any damage caused to anyone as a result of using knowledge and methods obtained as a result of studying this document.
Data alignment
Alignment of data in the computer's RAM is a special arrangement of data in memory for faster access. When working with memory, processes use the machine word as the main unit. Different types of processors can have different sizes: one, two, four, eight, etc. bytes. When saving objects in memory, it may happen that some field goes beyond these word boundaries. Some processors can work with unaligned data for a longer time than with aligned data. And non-core processors generally cannot work with unaligned data.
In order to better imagine a model of aligned and unaligned data, consider an example on the following object - the Data structure.
struct Data{ int var1; void* mas[4]; };
Since the size of a variable of type int in x32 and x64 processors is not 4 bytes, and the value of a variable of type void * is 4 and 8 bytes, respectively, in memory this structure for processors x32 and x64 will be presented as follows.

X64 processors with such a structure will not work, since the data is not aligned. For data alignment, it is necessary to add another 4 byte field to the structure.
struct Data{ int var1; int addition; void* mas[4]; };
Thus, the data structure data for x64 processors will be aligned in memory.

Memcpy job solution
We click on the memcpy signature icon and we are told that we need to connect via SSH with the guest password.
They also provide source code.
// compiled with : gcc -o memcpy memcpy.c -m32 -lm #include <stdio.h> #include <string.h> #include <stdlib.h> #include <signal.h> #include <unistd.h> #include <sys/mman.h> #include <math.h> unsigned long long rdtsc(){ asm("rdtsc"); } char* slow_memcpy(char* dest, const char* src, size_t len){ int i; for (i=0; i<len; i++) { dest[i] = src[i]; } return dest; } char* fast_memcpy(char* dest, const char* src, size_t len){ size_t i; // 64-byte block fast copy if(len >= 64){ i = len / 64; len &= (64-1); while(i-- > 0){ __asm__ __volatile__ ( "movdqa (%0), %%xmm0\n" "movdqa 16(%0), %%xmm1\n" "movdqa 32(%0), %%xmm2\n" "movdqa 48(%0), %%xmm3\n" "movntps %%xmm0, (%1)\n" "movntps %%xmm1, 16(%1)\n" "movntps %%xmm2, 32(%1)\n" "movntps %%xmm3, 48(%1)\n" ::"r"(src),"r"(dest):"memory"); dest += 64; src += 64; } } // byte-to-byte slow copy if(len) slow_memcpy(dest, src, len); return dest; } int main(void){ setvbuf(stdout, 0, _IONBF, 0); setvbuf(stdin, 0, _IOLBF, 0); printf("Hey, I have a boring assignment for CS class.. :(\n"); printf("The assignment is simple.\n"); printf("-----------------------------------------------------\n"); printf("- What is the best implementation of memcpy? -\n"); printf("- 1. implement your own slow/fast version of memcpy -\n"); printf("- 2. compare them with various size of data -\n"); printf("- 3. conclude your experiment and submit report -\n"); printf("-----------------------------------------------------\n"); printf("This time, just help me out with my experiment and get flag\n"); printf("No fancy hacking, I promise :D\n"); unsigned long long t1, t2; int e; char* src; char* dest; unsigned int low, high; unsigned int size; // allocate memory char* cache1 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); char* cache2 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); src = mmap(0, 0x2000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); size_t sizes[10]; int i=0; // setup experiment parameters for(e=4; e<14; e++){ // 2^13 = 8K low = pow(2,e-1); high = pow(2,e); printf("specify the memcpy amount between %d ~ %d : ", low, high); scanf("%d", &size); if( size < low || size > high ){ printf("don't mess with the experiment.\n"); exit(0); } sizes[i++] = size; } sleep(1); printf("ok, lets run the experiment with your configuration\n"); sleep(1); // run experiment for(i=0; i<10; i++){ size = sizes[i]; printf("experiment %d : memcpy with buffer size %d\n", i+1, size); dest = malloc( size ); memcpy(cache1, cache2, 0x4000); // to eliminate cache effect t1 = rdtsc(); slow_memcpy(dest, src, size); // byte-to-byte memcpy t2 = rdtsc(); printf("ellapsed CPU cycles for slow_memcpy : %llu\n", t2-t1); memcpy(cache1, cache2, 0x4000); // to eliminate cache effect t1 = rdtsc(); fast_memcpy(dest, src, size); // block-to-block memcpy t2 = rdtsc(); printf("ellapsed CPU cycles for fast_memcpy : %llu\n", t2-t1); printf("\n"); } printf("thanks for helping my experiment!\n"); printf("flag : ----- erased in this source code -----\n"); return 0; }
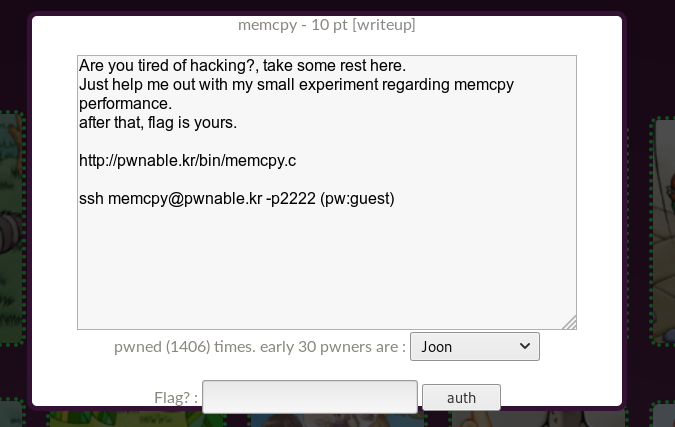
When connected, we see the corresponding banner.
Let's find out what files are on the server, as well as what rights we have.

We have a readme file. After reading it, we learn that the program runs on port 9022.

Connect to port 9022. We are offered an experiment - compare the slow and fast version of memcpy. Next, the program will enter a number in a certain interval and issue a report on the comparison of the slow and fast versions of the function. There is one thing: experiments 10, and reports - 5.
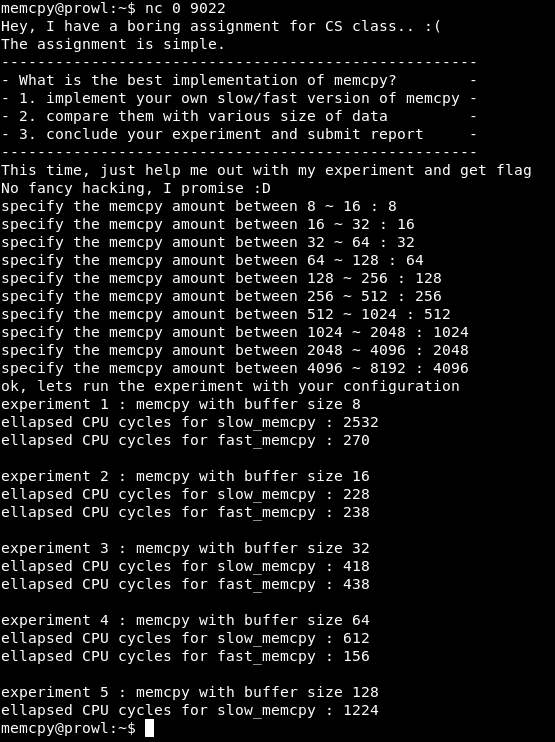
Let's tidy up why. Find the place in the code to compare the results.
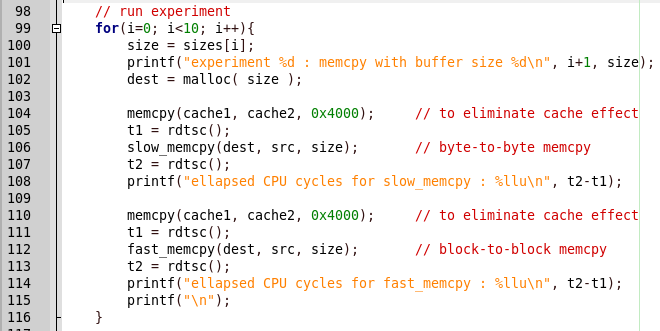
Everything is simple, first slow_memcpy is called, then fast_memcpy. But in the program report there is a conclusion about the slow release of the function, and when the quick implementation is called, the program crashes. Let's see the quick implementation code.
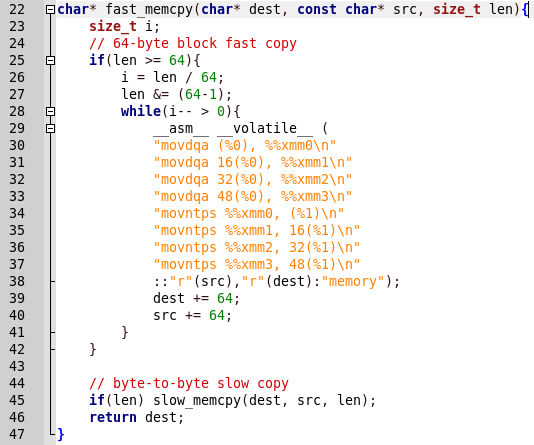
Copying is done using assembler functions. We determine by commands that this is SSE2. As stated here : SSE2 uses eight 128-bit registers (xmm0 to xmm7) included in the x86 architecture with the introduction of the SSE extension, each of which is treated as 2 consecutive double-precision floating-point values. Moreover, this code is working with aligned data.


Thus, working with unaligned data, the program may crash. Alignment is performed by 128 bits, that is, 16 bytes each, so the blocks must be equal to 16. We need to find out how many bytes are already in the first block on the heap (let X) then we must each transfer as many bytes to the program (let Y) so that ( X + Y)% 16 was 0.
Since all operations occupy heap blocks that are multiples of two, iterate over X as 2, 4, 8, etc. until 16.
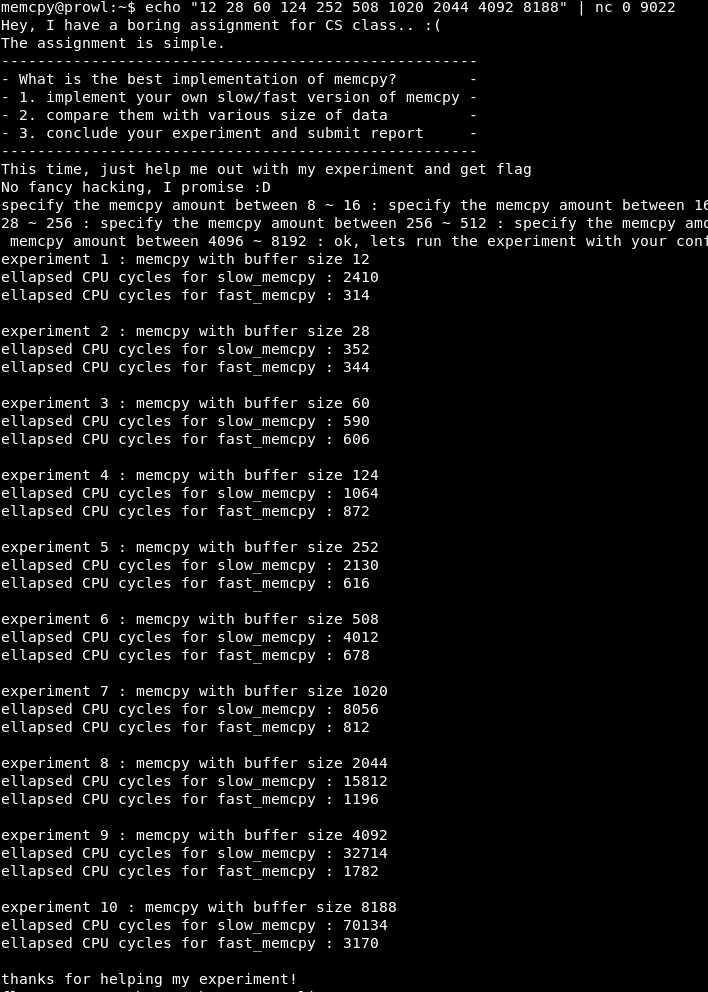
As you can see, with X = 4, the program runs successfully.

We get the shell, read the flag, get 10 points.
You can join us on Telegram . Next time we’ll deal with heap overflow.
All Articles