Helm Security
The essence of the story about the most popular package manager for Kubernetes could be represented with the help of emoji:

In fact, everything will be a little more complicated, and the story is full of technical details on how to make Helm safe .
Everything in this article relates to Helm 2. This version is now in production and most likely it is you who are using it now, and it is in it that there are security risks.
About the speaker: Alexander Khayorov ( allexx ) has been developing for 10 years, helps improve the content of Moscow Python Conf ++ and has joined the Helm Summit committee. Currently working at Chainstack as a development lead - this is a hybrid between the development manager and the person who is responsible for the delivery of the final releases. That is, it is located on the site of hostilities, where everything happens from the creation of the product to its operation.
Chainstack is a small, actively growing, startup whose task is to provide customers with the opportunity to forget about the infrastructure and the difficulties of operating decentralized applications, the development team is located in Singapore. Do not ask Chainstack to sell or buy cryptocurrency, but offer to talk about enterprise blockchain frameworks, and they will be happy to answer you.
This is the package manager (charts) for Kubernetes. The most intuitive and versatile way to bring applications to the Kubernetes cluster.

This, of course, is about a more structural and industrial approach than creating your own YAML manifests and writing small utilities.
Why helm? Primarily because it is supported by CNCF. Cloud Native - a large organization, is the parent company for the projects Kubernetes, etcd, Fluentd and others.
Another important fact, Helm is a very popular project. When in January 2019 I was just planning to talk about how to make Helm safe, the project had a thousand stars on GitHub. By May there were 12 thousand of them.
Many people are interested in Helm, therefore, even if you still do not use it, you will need knowledge of its safety. Safety is important.
The core team of Helm is supported by Microsoft Azure, and therefore this is a fairly stable project unlike many others. The release of Helm 3 Alpha 2 in mid-July indicates that quite a lot of people are working on the project, and they have the desire and strength to develop and improve Helm.
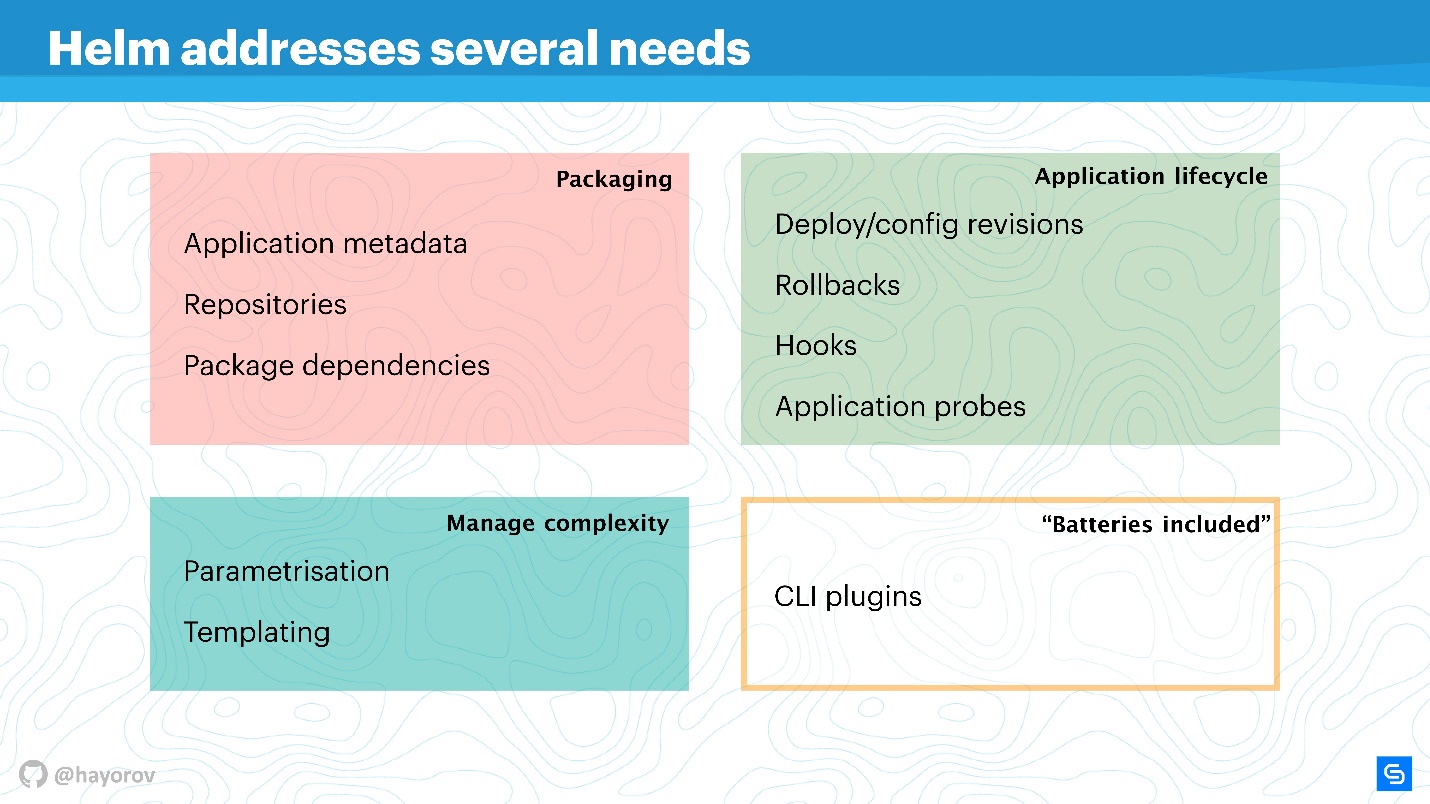
Helm solves several root application management issues in Kubernetes.
Packing is organized in an understandable way: there is metadata in full accordance with the work of the usual package manager for Linux, Windows or MacOS. That is, a repository, depending on various packages, meta-information for applications, settings, configuration features, indexing of information, etc. All this Helm allows you to get and use for applications.
Complexity management . If you have many similar applications, then you need parameterization. Templates follow from this, but in order not to come up with your own way of creating templates, you can use what Helm offers out of the box.
Application lifecycle management - in my opinion, this is the most interesting and unresolved issue. This is why I came to Helm in due time. We needed to monitor the application life cycle, we wanted to transfer our CI / CD and application cycles to this paradigm.
Helm allows you to:
In addition , Helm has "batteries" - a huge number of tasty things that can be included in the form of plug-ins, simplifying your life. Plugins can be written independently, they are quite isolated and do not require a slender architecture. If you want to implement something, I recommend to do it as a plugin, and then it is possible to include it in upstream.
Helm is based on three main concepts:
The diagram conceptually reflects the high-level architecture of Helm.
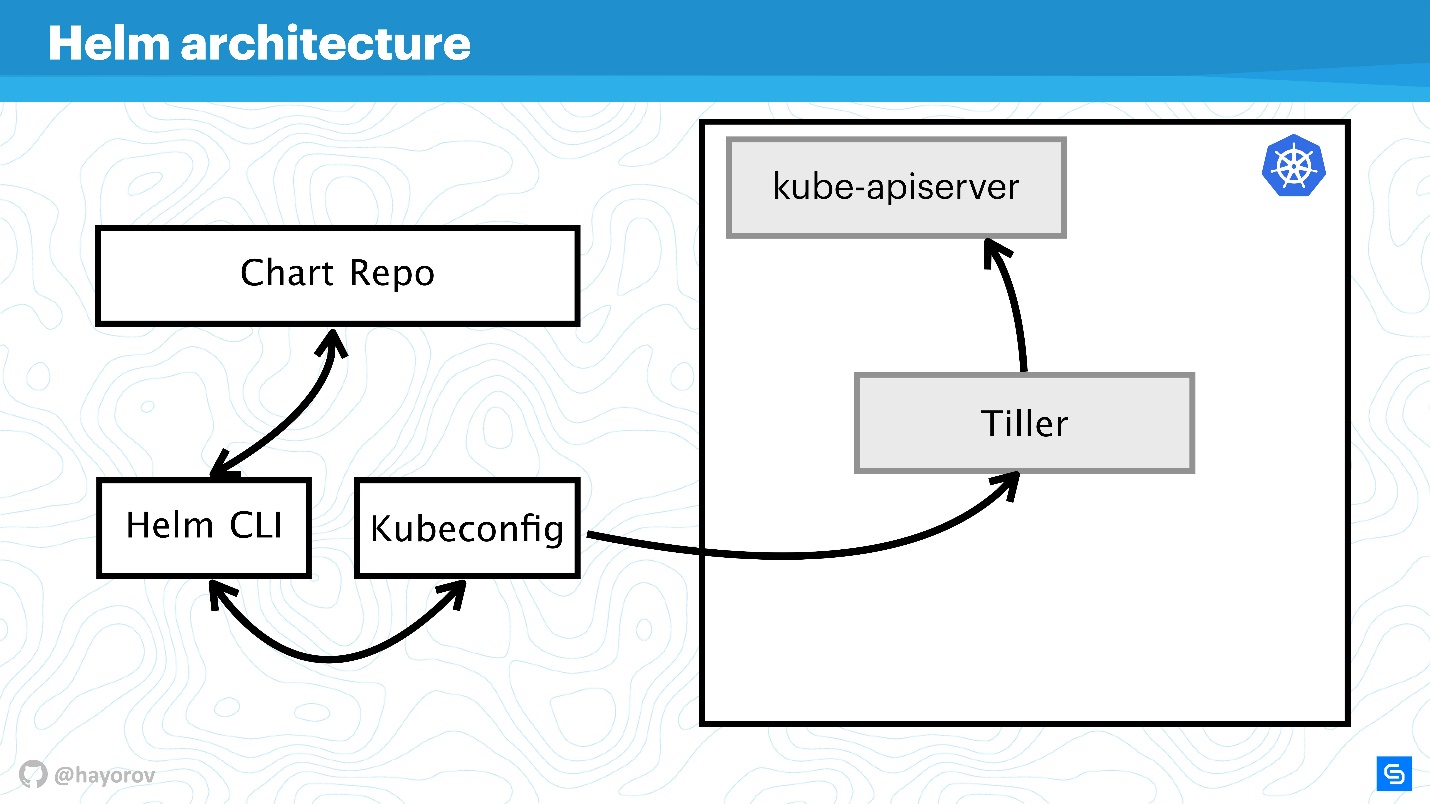
Let me remind you that Helm is something that is connected with Kubernetes. Therefore, we can not do without Kubernetes-cluster (rectangle). The kube-apiserver component is on the wizard. Without Helm, we have Kubeconfig. Helm brings one small binary, so to speak, Helm CLI utility, which is installed on a computer, laptop, mainframe - for anything.
But this is not enough. Helm has a Tiller server component. He represents Helm within a cluster; it is the same application within a Kubernetes cluster as any other.
The next component of Chart Repo is the chart repository. There is an official repository, and there may be a private repository of a company or project.
Let's see how architecture components interact when we want to install an application using Helm.
Further, we will complicate the scheme to see the vector of attacks to which the entire Helm architecture as a whole can be subjected. And then we’ll try to protect her.
The first potentially weak point is the privileged user API . As part of the scheme, this is a hacker who has gained admin access to Helm CLI.
An unprivileged API user can also be dangerous if it is somewhere nearby. Such a user will have a different context, for example, he can be fixed in one namespace of the cluster in the settings of Kubeconfig.
The most interesting attack vector may be the process that is located inside the cluster somewhere near Tiller and can access it. It can be a web server or a microservice that sees the network environment of the cluster.
An exotic, but gaining popularity, attack option is associated with Chart Repo. A chart created by an unscrupulous author may contain an unsafe resource, and you will execute it, taking it on faith. Or it can replace the chart that you download from the official repository, and, for example, create a resource in the form of policies and escalate your access.
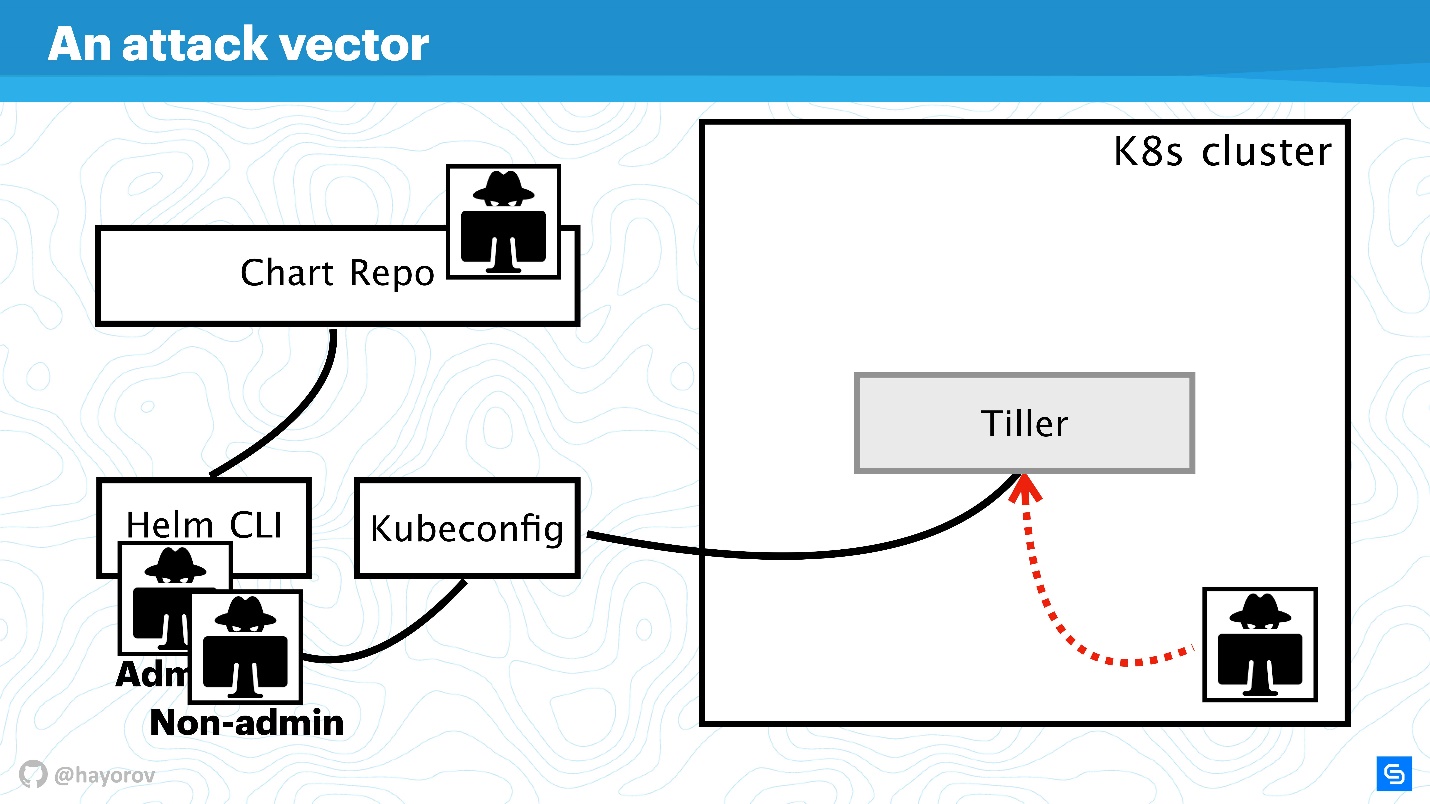
Let's try to fight off attacks from all these four sides and figure out where there are problems in the Helm architecture, and where, possibly, they are not.
Let's enlarge the scheme, add more elements, but keep all the basic components.
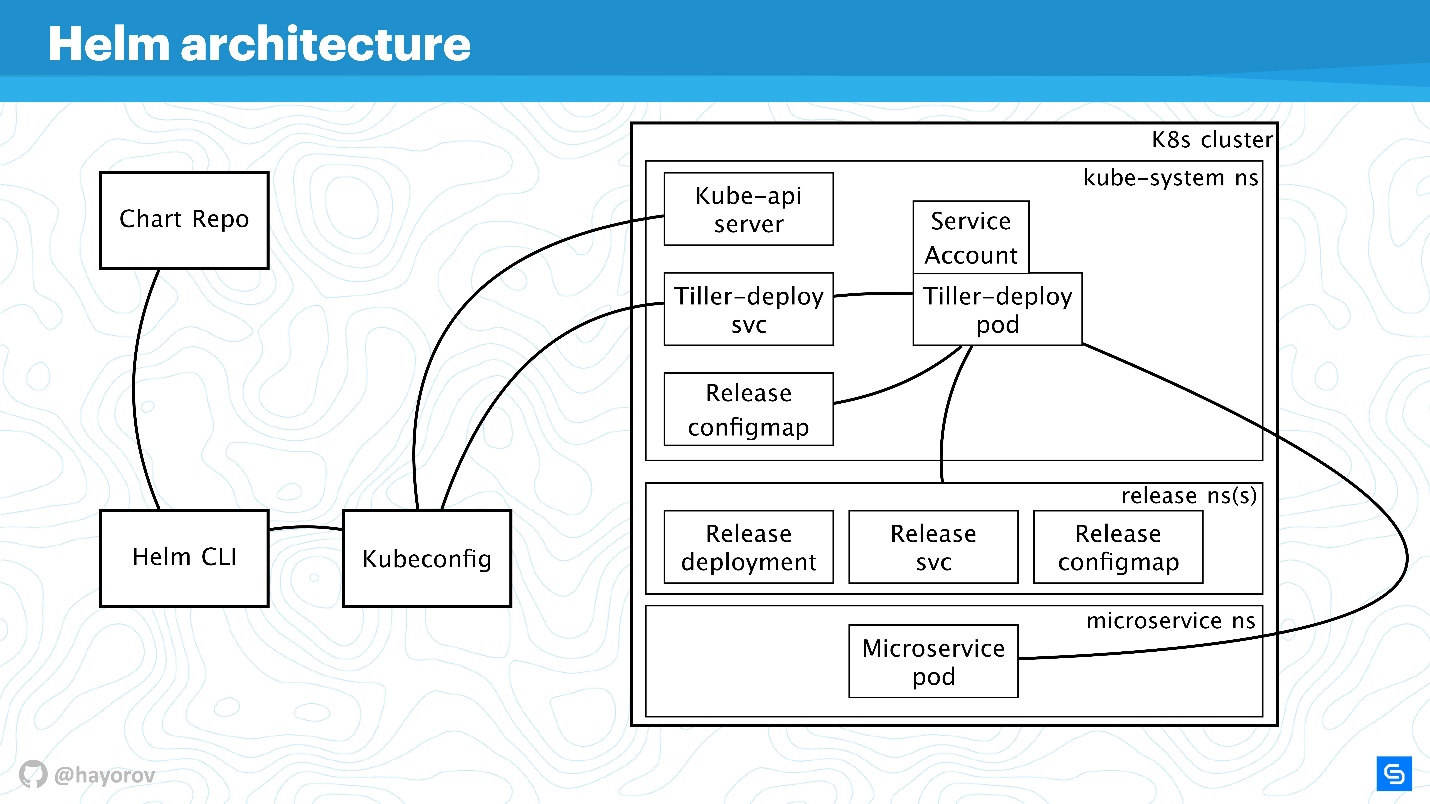
Helm CLI communicates with Chart Repo, interacts with Kubeconfig, work is transferred to the cluster in the Tiller component.
Tiller is represented by two objects:
Different protocols and schemes are used for interaction. From a security point of view, we are most interested in:
We will discuss all these directions in order.
It seems that this is not a fresh recommendation itself, but I am sure that so far many people have not turned on RBAC even in production, because this is a lot of fuss and you need to configure a lot. Nevertheless, I urge this to be done.
https://rbac.dev/ is a lawyer site for RBAC. It collected a huge amount of interesting materials that will help set up RBAC, show why it is good and how to live with it in principle in production.
I’ll try to explain how Tiller and RBAC work. Tiller works inside the cluster under a certain service account. Typically, if RBAC is not configured, this will be the superuser. In the basic configuration, Tiller will be the admin. That is why it is often said that Tiller is an SSH tunnel to your cluster. In fact, this is so, so you can use a separate specialized service account instead of the Default Service Account in the diagram above.
When you initialize Helm, first install it on the server, you can set the service account using
. This will allow you to use the user with the minimum necessary set of rights. True, it is necessary to create such a "garland": Role and RoleBinding.
Unfortunately, Helm will not do this for you. You or your Kubernetes cluster administrator need to prepare a set of Role, RoleBinding for service-account in advance to transfer Helm.
The question is - what is the difference between Role and ClusterRole? The difference is that ClusterRole is valid for all namespaces, unlike regular Role and RoleBinding, which work only for specialized namespace. You can configure policies for the entire cluster and all namespaces, as well as personalized for each namespace separately.
It is worth mentioning that RBAC solves another big problem. Many complain that Helm, unfortunately, is not multitenancy (does not support multi-tenancy). If several teams consume a cluster and use Helm, it is impossible in principle to configure policies and to differentiate their access within this cluster, because there is some service account under which Helm works, and it creates all resources in the cluster from under it, which sometimes very uncomfortable. This is true - as the binary itself, as a process, Helm Tiller does not have a clue about multitenancy .
However, there is a great way that you can run Tiller in a cluster several times. There is no problem with this; Tiller can be run in every namespace. Thus, you can use RBAC, Kubeconfig as a context, and restrict access to the special Helm.
It will look as follows.
For example, there are two Kubeconfig with context for different teams (two namespace): X Team for the development team and admin cluster. The admin cluster has its own wide Tiller, which is located in the Kube-system namespace, respectively an advanced service-account. And a separate namespace for the development team, they will be able to deploy their services in a special namespace.
This is a working approach, Tiller is not so gluttonous that it could greatly affect your budget. This is one of the quick fixes.
Continuing our story, switch from RBAC and talk about ConfigMaps.
Helm uses ConfigMaps as a data warehouse. When we talked about architecture, there was nowhere a database in which information about releases, configurations, rollbacks, etc. was stored. For this, ConfigMaps is used.
The main problem with ConfigMaps is known - they are unsafe in principle, it is impossible to store sensitive data in them. We are talking about everything that should not get beyond the service, for example, passwords. The most native way for Helm now is to move from using ConfigMaps to secrets.
This is done very simply. Redefine the Tiller setting and specify that the storage will be secrets. Then for each deploy you will not receive ConfigMap, but a secret.
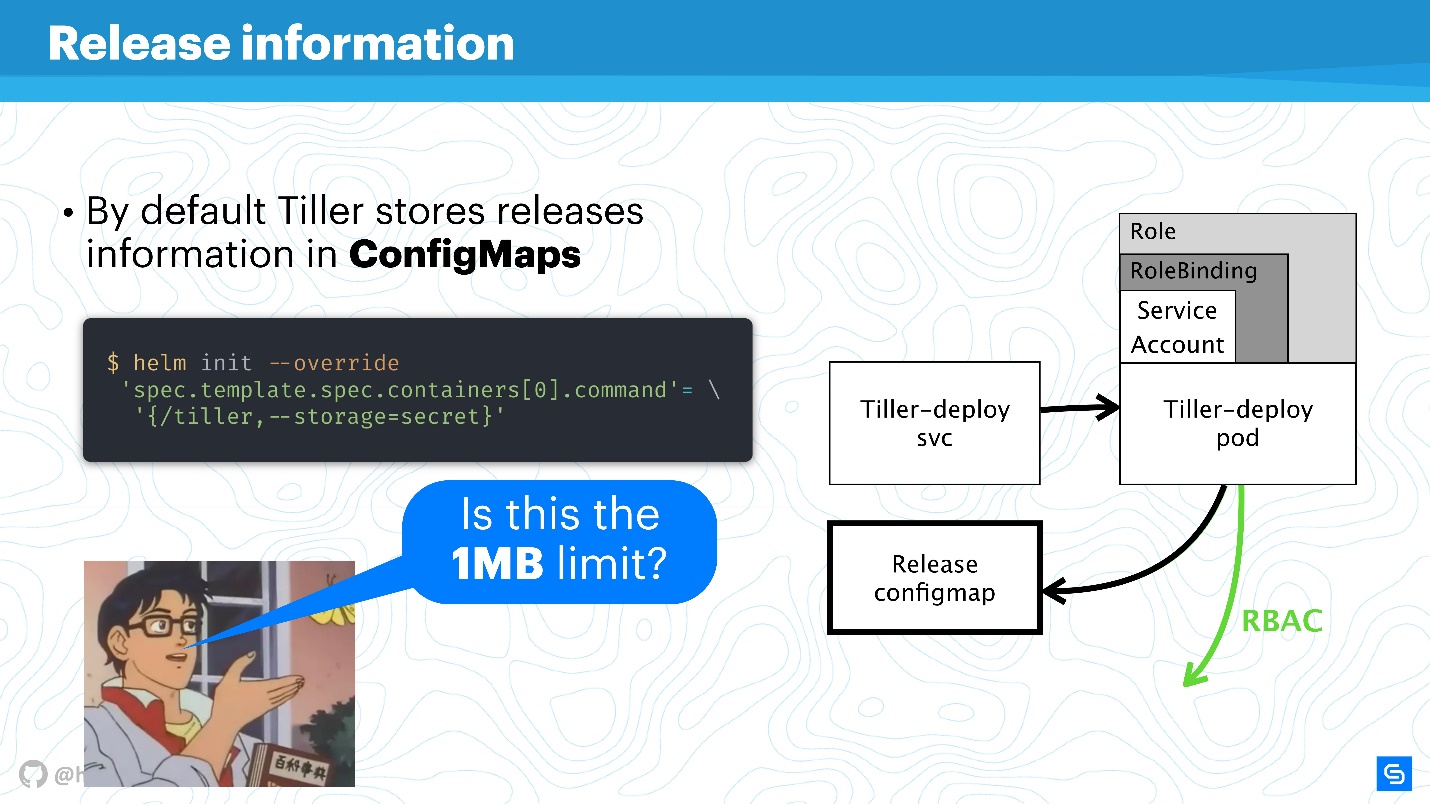
You may argue that the secrets themselves are a strange concept, and it is not very safe. However, it is worth understanding that the developers of Kubernetes are doing this. Starting with version 1.10, i.e. for a long time, there is the possibility, at least in public clouds, to connect the correct storage to store secrets. Now the team is working on even better handing out access to secrets, individual pods or other entities.
Of course, there will be a limit for storing data in 1 MB . Helm here uses etcd as a distributed repository for ConfigMaps. And there they thought it was a suitable data chunk for replications, etc. There is an interesting discussion on Reddit about this, I recommend finding this fun reading matter for the weekend or reading the squeeze here .
Charts are the most socially vulnerable and can become the source of "Man in the middle", especially if you use the stock solution. First of all, we are talking about repositories that are exposed via HTTP.
Pay attention to the mechanism of chart signatures . The technology is simple to disgrace. This is the same thing you use on GitHub, the usual PGP machine with public and private keys. Set up and be sure, having the necessary keys and signing everything, this is really your chart.
In addition, the Helm client supports TLS (not in the sense of HTTP from the server side, but mutual TLS). You can use server and client keys in order to communicate. Frankly, I do not use such a mechanism because of dislike for mutual certificates. In principle, chartmuseum - the main Helm Repo exposure tool for Helm 2 - also supports basic auth. You can use basic auth if it's more convenient and calmer.
There is also a helm-gcs plugin that allows you to host Chart Repos on Google Cloud Storage. It is quite convenient, works great and is quite safe, because all the described mechanisms are utilized.
If you enable HTTPS or TLS, use mTLS, connect basic auth to further reduce risks, you will get a secure communication channel Helm CLI and Chart Repo.
The next step is very responsible - to secure Tiller, which is located in the cluster and is, on the one hand, the server, on the other hand, it accesses other components and tries to introduce itself as someone.
As I said, Tiller is a service that exposes gRPC, a Helm client comes to it via gRPC. By default, of course, TLS is off. Why this is done is a debatable question, it seems to me to simplify the setup at the start.
In my opinion, unlike mTLS for charts, here it is appropriate and is done very simply - generate a PQI infrastructure, create a certificate, launch Tiller, transfer the certificate during initialization. After that, you can execute all Helm commands, appearing to be a generated certificate and private key.
Thus, you will protect yourself from all requests to Tiller from outside the cluster.
So, we secured the connection channel to Tiller, already discussed RBAC and adjusted the rights of Kubernetes apiserver, reduced the domain with which it can interact.
Let's look at the final diagram. This is the same architecture with the same arrows.
All connections can now be safely painted in green:
We markedly secured the cluster, but someone smart said:
There are different ways to manipulate data and find new attack vectors. However, I am confident that these recommendations will enable the implementation of a basic industry safety standard.
This part is not directly related to security, but it will also be useful. I will show you some interesting things that few people know about. For example, how to search for charts - official and unofficial.
The github.com/helm/charts repository now has about 300 charts and two streams: stable and incubator. The contributor knows how difficult it is to get from incubator to stable, and how easy it is to fly out of stable. However, this is not the best tool to search for charts for Prometheus and all that you like for one simple reason is not a portal where it is convenient to search for packages.
But there is a hub.helm.sh service with which it is much more convenient to find charts. Most importantly, there are many more external repositories and almost 800 charots are available. Plus, you can connect your repository if for some reason you do not want to send your charts to stable.
Try hub.helm.sh and let's develop it together. This service is under the Helm project, and you can even contribute in its UI if you are a front-end vendor and want to simply improve the appearance.
I also want to draw your attention to the Open Service Broker API integration . It sounds cumbersome and incomprehensible, but it solves the problems that everyone faces. I will explain with a simple example.
There is a Kubernetes-cluster in which we want to run the classic application - WordPress. As a rule, a database is needed for full functionality. There are many different solutions, for example, you can start your statefull service. This is not very convenient, but many do.
Others, like us at Chainstack, use managed databases, such as MySQL or PostgreSQL, for servers. Therefore, our databases are located somewhere in the cloud.
But a problem arises: you need to connect our service with the database, create a flavor database, pass credential and somehow manage it. All this is usually done manually by the system administrator or developer. And there is no problem when there are few applications. When there are many, you need a combine. There is such a combine - this is Service Broker. It allows you to use a special plug-in to the public cloud cluster and order resources from the provider through Broker, as if it were an API. To do this, you can use the native Kubernetes tools.
It is very simple. You can query, for example, Managed MySQL in Azure with a base tier (this can be configured). Using the Azure API, the base will be created and prepared for use. You do not need to interfere with this, the plugin is responsible for this. For example, OSBA (Azure plugin) will return credential to the service, pass this to Helm. You can use WordPress with cloudy MySQL, do not deal with managed databases at all, and don’t worry about statefull services inside.
You can write your own plugin and use this entire on-premise story. Then you just have your own plugin for the corporate Cloud provider. I advise you to try this approach, especially if you have a large scale and you want to quickly deploy dev, staging or the entire infrastructure for a feature. This will make life easier for your operations or DevOps.
Another find that I have already mentioned is the helm-gcs plugin , which allows you to use Google buckets (object storage) to store Helm charts.

It takes only four commands to start using it:
The beauty is that the native gcp method for authorization will be used. You can use the service account, the developer account - anything. It is very convenient and costs nothing to operate. If you, like me, advocate opsless philosophy, then this will be very convenient, especially for small teams.
Helm is not the only service management solution. There are a lot of questions to him, which is probably why the third version appeared so quickly. Of course there are alternatives.
It can be as specialized solutions, for example, Ksonnet or Metaparticle. You can use your classic infrastructure management tools (Ansible, Terraform, Chef, etc.) for the same purposes that I talked about.
Finally, there is the Operator Framework solution, the popularity of which is growing.
It is more native for CNCF and Kubernetes, but the entry threshold is much higher , you need to program more and describe manifestes less.
There are various addons, such as Draft, Scaffold. They make life much easier, for example, developers simplify the Helm send and launch cycle for deploying a test environment. I would call them extenders of opportunities.
Here is a visual graph of where what is located.
On the x-axis, the level of your personal control over what is happening, on the y-axis, the level of Kubernetes nativeness. Helm version 2 is somewhere in the middle. In version 3, it is not colossal, but both control and level of nativeness are improved. Ksonnet solutions are still inferior even to Helm 2. However, they are worth a look to know what else is in this world. Of course, your configuration manager will be under your control, but absolutely not native to Kubernetes.
The Operator Framework is absolutely native to Kubernetes and allows you to manage it much more elegantly and meticulously (but remember the level of entry). Rather, it is suitable for a specialized application and creating management for it, rather than a mass harvester for packing a huge number of applications using Helm.
Extenders simply improve control a bit, complement workflow or cut corners of CI / CD pipelines.
The good news is that Helm 3 is appearing. The alpha version of Helm 3.0.0-alpha.2 has already been released, you can try. It is quite stable, but functionality is still limited.
Why do you need Helm 3? First of all, this is the story of the disappearance of Tiller , as a component. This, as you already understand, is a huge step forward, because everything is simplified from the point of view of architectural security.
When Helm 2 was created, which was during Kubernetes 1.8 or even earlier, many concepts were immature. For example, the concept of CRD is being actively implemented, and Helm will use CRD to store structures. It will be possible to use only the client and not keep the server side. Accordingly, use native Kubernetes commands to work with structures and resources. This is a huge step forward.
Support for native OCI repositories (Open Container Initiative) will appear. This is a huge initiative, and Helm is interesting primarily for posting its charts. It comes to the point that, for example, the Docker Hub supports many OCI standards. I don’t think, but perhaps the classic providers of Docker repositories will start to give you the opportunity to place their Helm charts for you.
A controversial story for me is Lua's support as a templating engine for writing scripts. I'm not a big fan of Lua, but it will be a completely optional feature. I checked it 3 times - using Lua will not be necessary. Therefore, anyone who wants to be able to use Lua, someone who likes Go, join our huge camp and use go-tmpl for this.
, — . int string, . JSONS-, values.
event-driven model . . Helm 3, , , , , .
Helm 3 , , Helm 2, Kubernetes . , Helm Kubernetes Kubernetes.
- the box is Helm (this is the most suitable that is in the latest release of Emoji);
- lock - security;
- man is the solution to the problem.
In fact, everything will be a little more complicated, and the story is full of technical details on how to make Helm safe .
- Briefly, what is Helm if you did not know or forget. What problems does it solve and where is it located in the ecosystem.
- Consider the architecture of Helm. Not a single conversation about security and how to make a tool or solution more secure can do without understanding the architecture of the component.
- Let's discuss Helm components.
- The most burning issue is the future - the new version of Helm 3.
Everything in this article relates to Helm 2. This version is now in production and most likely it is you who are using it now, and it is in it that there are security risks.
About the speaker: Alexander Khayorov ( allexx ) has been developing for 10 years, helps improve the content of Moscow Python Conf ++ and has joined the Helm Summit committee. Currently working at Chainstack as a development lead - this is a hybrid between the development manager and the person who is responsible for the delivery of the final releases. That is, it is located on the site of hostilities, where everything happens from the creation of the product to its operation.
Chainstack is a small, actively growing, startup whose task is to provide customers with the opportunity to forget about the infrastructure and the difficulties of operating decentralized applications, the development team is located in Singapore. Do not ask Chainstack to sell or buy cryptocurrency, but offer to talk about enterprise blockchain frameworks, and they will be happy to answer you.
Helm
This is the package manager (charts) for Kubernetes. The most intuitive and versatile way to bring applications to the Kubernetes cluster.
This, of course, is about a more structural and industrial approach than creating your own YAML manifests and writing small utilities.
Helm is the best that is now available and popular.
Why helm? Primarily because it is supported by CNCF. Cloud Native - a large organization, is the parent company for the projects Kubernetes, etcd, Fluentd and others.
Another important fact, Helm is a very popular project. When in January 2019 I was just planning to talk about how to make Helm safe, the project had a thousand stars on GitHub. By May there were 12 thousand of them.
Many people are interested in Helm, therefore, even if you still do not use it, you will need knowledge of its safety. Safety is important.
The core team of Helm is supported by Microsoft Azure, and therefore this is a fairly stable project unlike many others. The release of Helm 3 Alpha 2 in mid-July indicates that quite a lot of people are working on the project, and they have the desire and strength to develop and improve Helm.
Helm solves several root application management issues in Kubernetes.
- Application packaging. Even an application like “Hello, World” on WordPress already consists of several services, and I want to pack them together.
- Management of the complexity that arises with the management of these applications.
- A life cycle that does not end after installation or deployment of the application. It continues to live, it needs to be updated, and Helm helps in this and is trying to bring the right measures and policies for this.
Packing is organized in an understandable way: there is metadata in full accordance with the work of the usual package manager for Linux, Windows or MacOS. That is, a repository, depending on various packages, meta-information for applications, settings, configuration features, indexing of information, etc. All this Helm allows you to get and use for applications.
Complexity management . If you have many similar applications, then you need parameterization. Templates follow from this, but in order not to come up with your own way of creating templates, you can use what Helm offers out of the box.
Application lifecycle management - in my opinion, this is the most interesting and unresolved issue. This is why I came to Helm in due time. We needed to monitor the application life cycle, we wanted to transfer our CI / CD and application cycles to this paradigm.
Helm allows you to:
- manage deployment; introduces the concept of configuration and revision;
- successfully rollback;
- use hooks for different events;
- Add additional application checks and respond to their results.
In addition , Helm has "batteries" - a huge number of tasty things that can be included in the form of plug-ins, simplifying your life. Plugins can be written independently, they are quite isolated and do not require a slender architecture. If you want to implement something, I recommend to do it as a plugin, and then it is possible to include it in upstream.
Helm is based on three main concepts:
- Chart Repo - description and array of parameterization possible for your manifest.
- Config — that is, the values that will be applied (text, numerical values, etc.).
- Release brings together the top two components, and together they turn into Release. Releases can be versioned, thereby achieving the organization of the life cycle: small at the time of installation and large at the time of upgrade, downgrade or rollback.
Helm Architecture
The diagram conceptually reflects the high-level architecture of Helm.
Let me remind you that Helm is something that is connected with Kubernetes. Therefore, we can not do without Kubernetes-cluster (rectangle). The kube-apiserver component is on the wizard. Without Helm, we have Kubeconfig. Helm brings one small binary, so to speak, Helm CLI utility, which is installed on a computer, laptop, mainframe - for anything.
But this is not enough. Helm has a Tiller server component. He represents Helm within a cluster; it is the same application within a Kubernetes cluster as any other.
The next component of Chart Repo is the chart repository. There is an official repository, and there may be a private repository of a company or project.
Interaction
Let's see how architecture components interact when we want to install an application using Helm.
- We say
Helm install
, go to the repository (Chart Repo) and get a Helm chart.
- The Helm Utility (Helm CLI) interacts with Kubeconfig to figure out which cluster to contact.
- Having received this information, the utility turns to Tiller, which is located in our cluster, already as an application.
- Tiller turns to Kube-apiserver to perform actions in Kubernetes, to create some objects (services, pods, replicas, secrets, etc.).
Further, we will complicate the scheme to see the vector of attacks to which the entire Helm architecture as a whole can be subjected. And then we’ll try to protect her.
Attack Vector
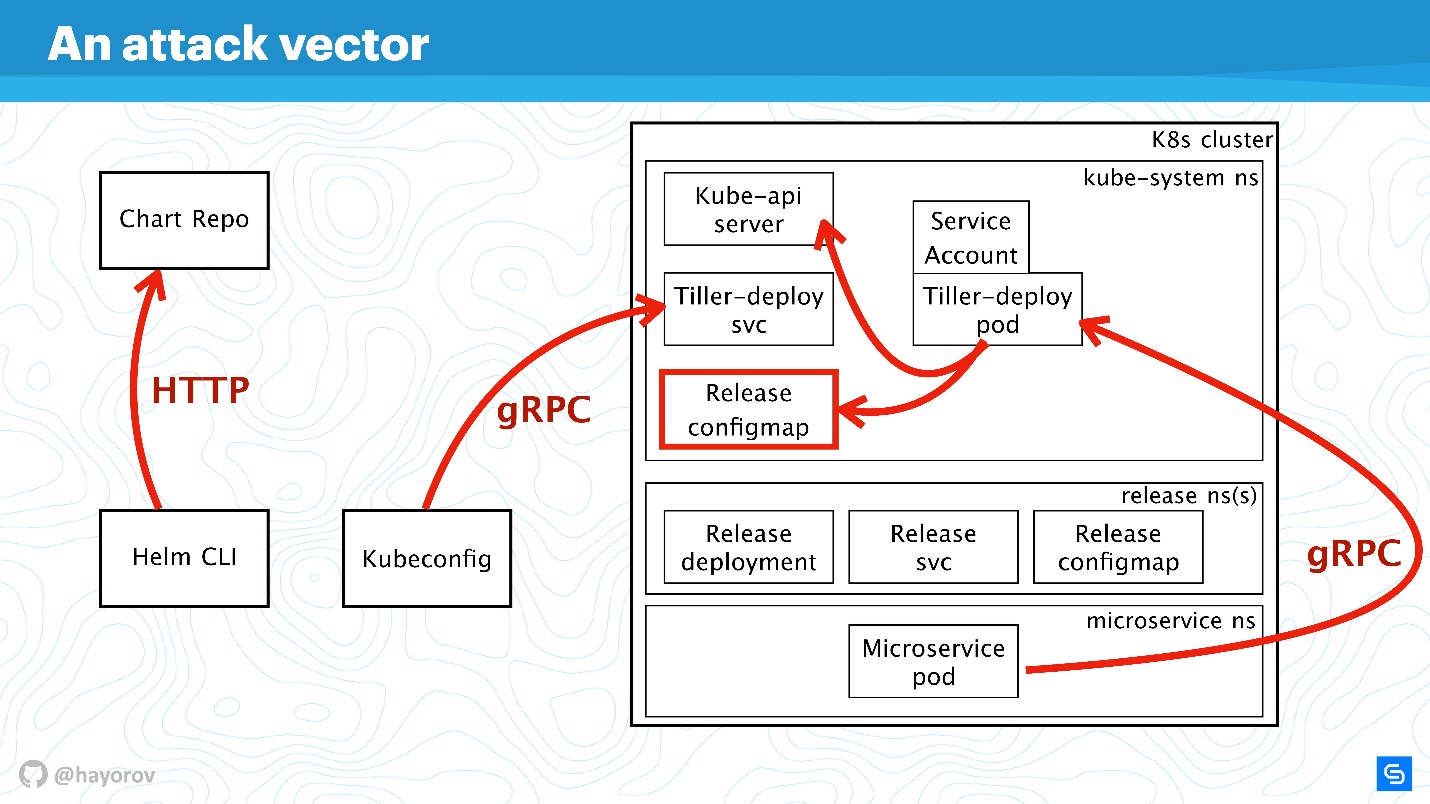
The first potentially weak point is the privileged user API . As part of the scheme, this is a hacker who has gained admin access to Helm CLI.
An unprivileged API user can also be dangerous if it is somewhere nearby. Such a user will have a different context, for example, he can be fixed in one namespace of the cluster in the settings of Kubeconfig.
The most interesting attack vector may be the process that is located inside the cluster somewhere near Tiller and can access it. It can be a web server or a microservice that sees the network environment of the cluster.
An exotic, but gaining popularity, attack option is associated with Chart Repo. A chart created by an unscrupulous author may contain an unsafe resource, and you will execute it, taking it on faith. Or it can replace the chart that you download from the official repository, and, for example, create a resource in the form of policies and escalate your access.
Let's try to fight off attacks from all these four sides and figure out where there are problems in the Helm architecture, and where, possibly, they are not.
Let's enlarge the scheme, add more elements, but keep all the basic components.
Helm CLI communicates with Chart Repo, interacts with Kubeconfig, work is transferred to the cluster in the Tiller component.
Tiller is represented by two objects:
- Tiller-deploy svc, which exposes a certain service;
- Tiller-deploy pod (on the diagram in a single copy in one replica), which runs the entire load that accesses the cluster.
Different protocols and schemes are used for interaction. From a security point of view, we are most interested in:
- The mechanism by which Helm CLI refers to chart repo: what protocol, whether there is authentication and what can be done about it.
- The protocol by which Helm CLI, using kubectl, communicates with Tiller. This is an RPC server installed inside the cluster.
- Tiller itself is available for microservices that are in a cluster and interacts with Kube-apiserver.
We will discuss all these directions in order.
RBAC
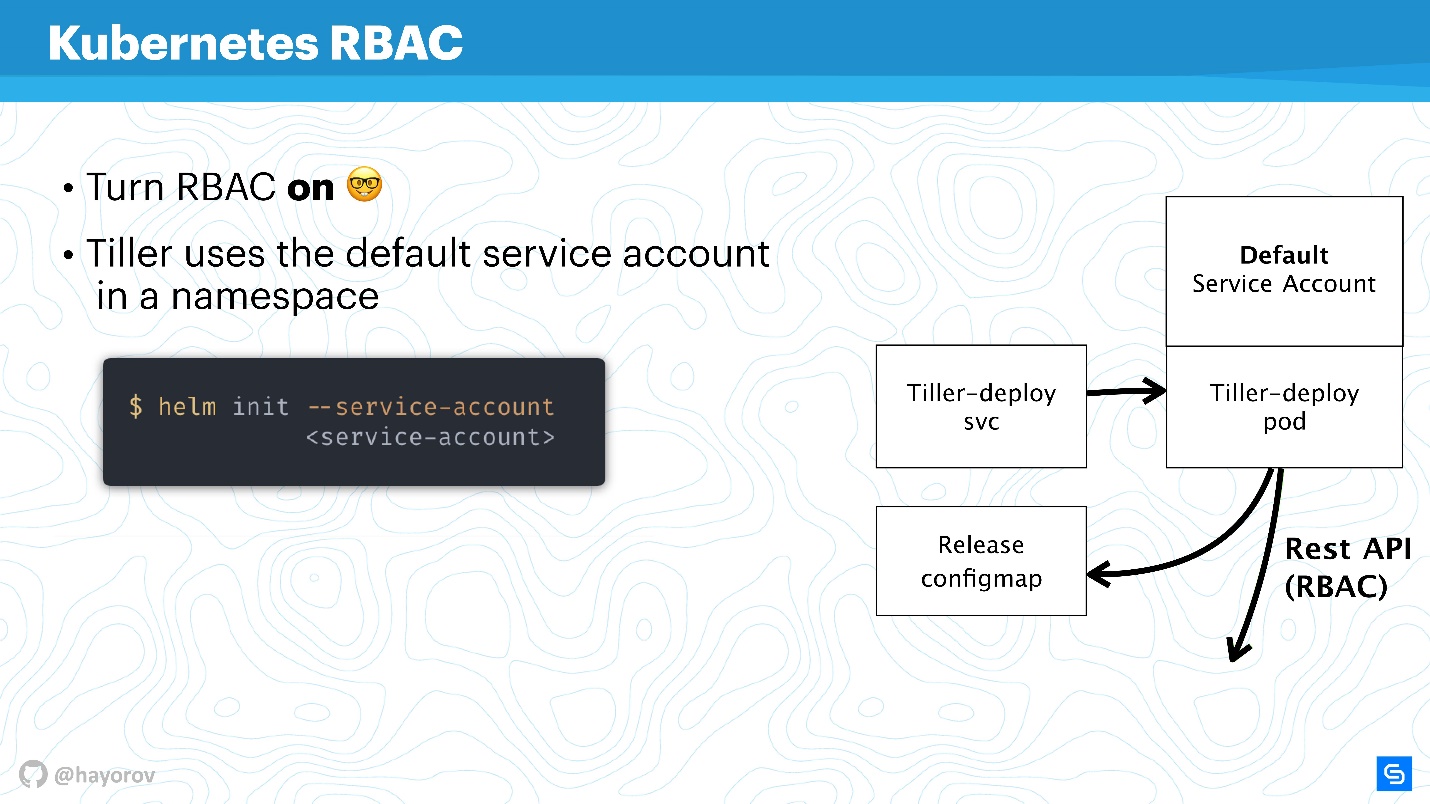
It is useless to talk about any security of Helm or another service within the cluster if RBAC is not enabled.
It seems that this is not a fresh recommendation itself, but I am sure that so far many people have not turned on RBAC even in production, because this is a lot of fuss and you need to configure a lot. Nevertheless, I urge this to be done.
https://rbac.dev/ is a lawyer site for RBAC. It collected a huge amount of interesting materials that will help set up RBAC, show why it is good and how to live with it in principle in production.
I’ll try to explain how Tiller and RBAC work. Tiller works inside the cluster under a certain service account. Typically, if RBAC is not configured, this will be the superuser. In the basic configuration, Tiller will be the admin. That is why it is often said that Tiller is an SSH tunnel to your cluster. In fact, this is so, so you can use a separate specialized service account instead of the Default Service Account in the diagram above.
When you initialize Helm, first install it on the server, you can set the service account using
--service-account
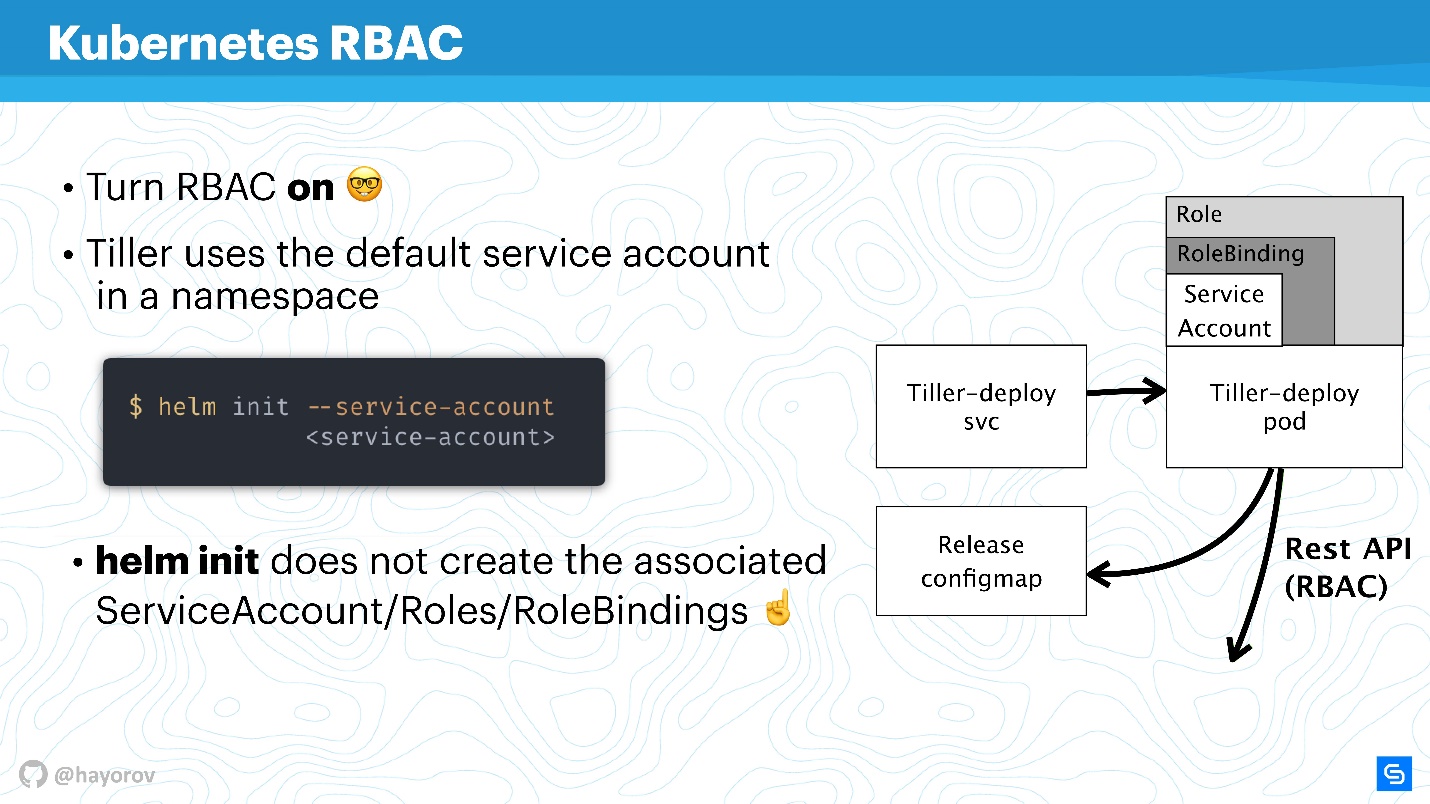
. This will allow you to use the user with the minimum necessary set of rights. True, it is necessary to create such a "garland": Role and RoleBinding.
Unfortunately, Helm will not do this for you. You or your Kubernetes cluster administrator need to prepare a set of Role, RoleBinding for service-account in advance to transfer Helm.
The question is - what is the difference between Role and ClusterRole? The difference is that ClusterRole is valid for all namespaces, unlike regular Role and RoleBinding, which work only for specialized namespace. You can configure policies for the entire cluster and all namespaces, as well as personalized for each namespace separately.
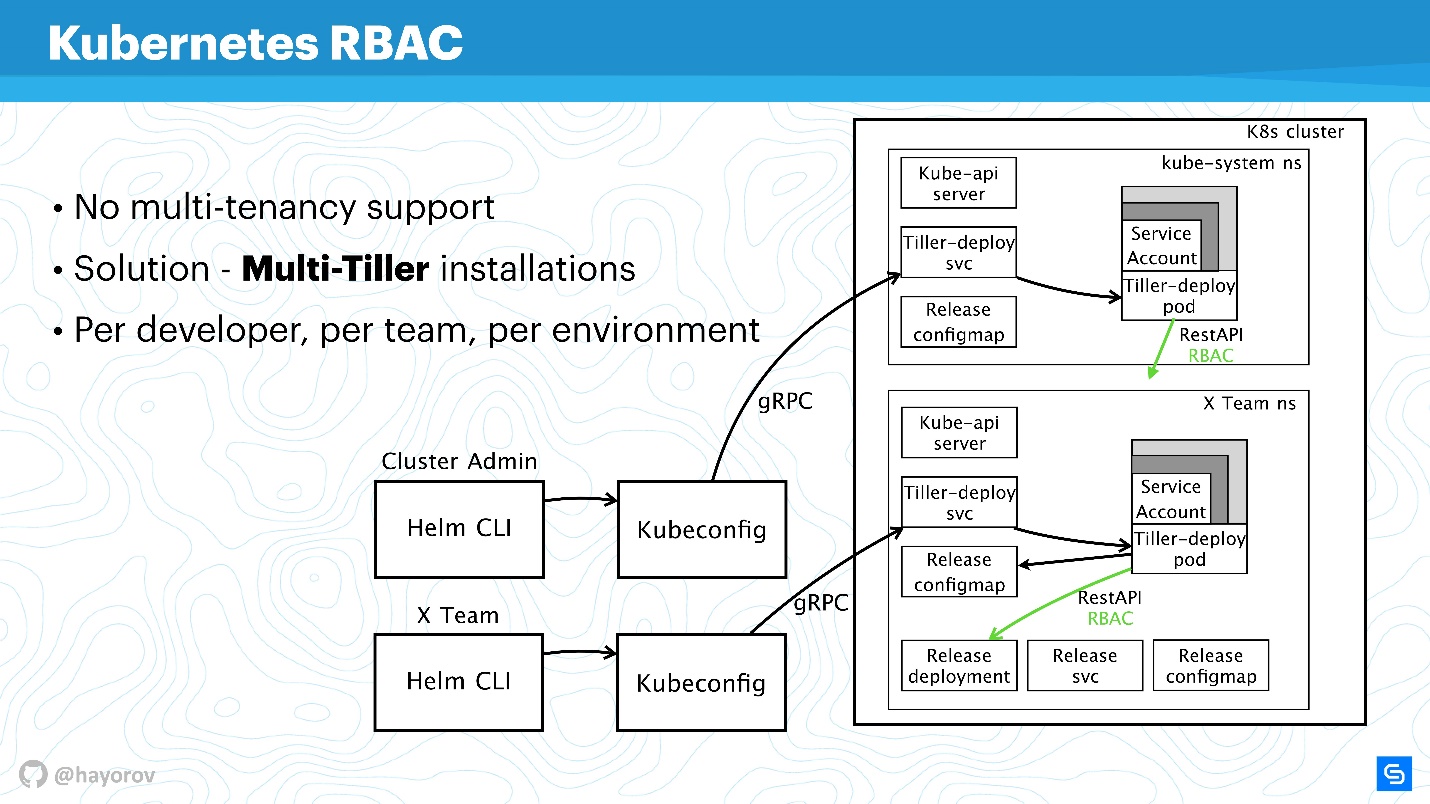
It is worth mentioning that RBAC solves another big problem. Many complain that Helm, unfortunately, is not multitenancy (does not support multi-tenancy). If several teams consume a cluster and use Helm, it is impossible in principle to configure policies and to differentiate their access within this cluster, because there is some service account under which Helm works, and it creates all resources in the cluster from under it, which sometimes very uncomfortable. This is true - as the binary itself, as a process, Helm Tiller does not have a clue about multitenancy .
However, there is a great way that you can run Tiller in a cluster several times. There is no problem with this; Tiller can be run in every namespace. Thus, you can use RBAC, Kubeconfig as a context, and restrict access to the special Helm.
It will look as follows.
For example, there are two Kubeconfig with context for different teams (two namespace): X Team for the development team and admin cluster. The admin cluster has its own wide Tiller, which is located in the Kube-system namespace, respectively an advanced service-account. And a separate namespace for the development team, they will be able to deploy their services in a special namespace.
This is a working approach, Tiller is not so gluttonous that it could greatly affect your budget. This is one of the quick fixes.
Feel free to configure Tiller separately and provide Kubeconfig with context for the team, for a specific developer or for the environment: Dev, Staging, Production (it is doubtful that everything will be on the same cluster, however, it can be done).
Continuing our story, switch from RBAC and talk about ConfigMaps.
Configmaps
Helm uses ConfigMaps as a data warehouse. When we talked about architecture, there was nowhere a database in which information about releases, configurations, rollbacks, etc. was stored. For this, ConfigMaps is used.
The main problem with ConfigMaps is known - they are unsafe in principle, it is impossible to store sensitive data in them. We are talking about everything that should not get beyond the service, for example, passwords. The most native way for Helm now is to move from using ConfigMaps to secrets.
This is done very simply. Redefine the Tiller setting and specify that the storage will be secrets. Then for each deploy you will not receive ConfigMap, but a secret.
You may argue that the secrets themselves are a strange concept, and it is not very safe. However, it is worth understanding that the developers of Kubernetes are doing this. Starting with version 1.10, i.e. for a long time, there is the possibility, at least in public clouds, to connect the correct storage to store secrets. Now the team is working on even better handing out access to secrets, individual pods or other entities.
Storage Helm is better to translate into secrets, and they, in turn, secure centrally.
Of course, there will be a limit for storing data in 1 MB . Helm here uses etcd as a distributed repository for ConfigMaps. And there they thought it was a suitable data chunk for replications, etc. There is an interesting discussion on Reddit about this, I recommend finding this fun reading matter for the weekend or reading the squeeze here .
Chart rep
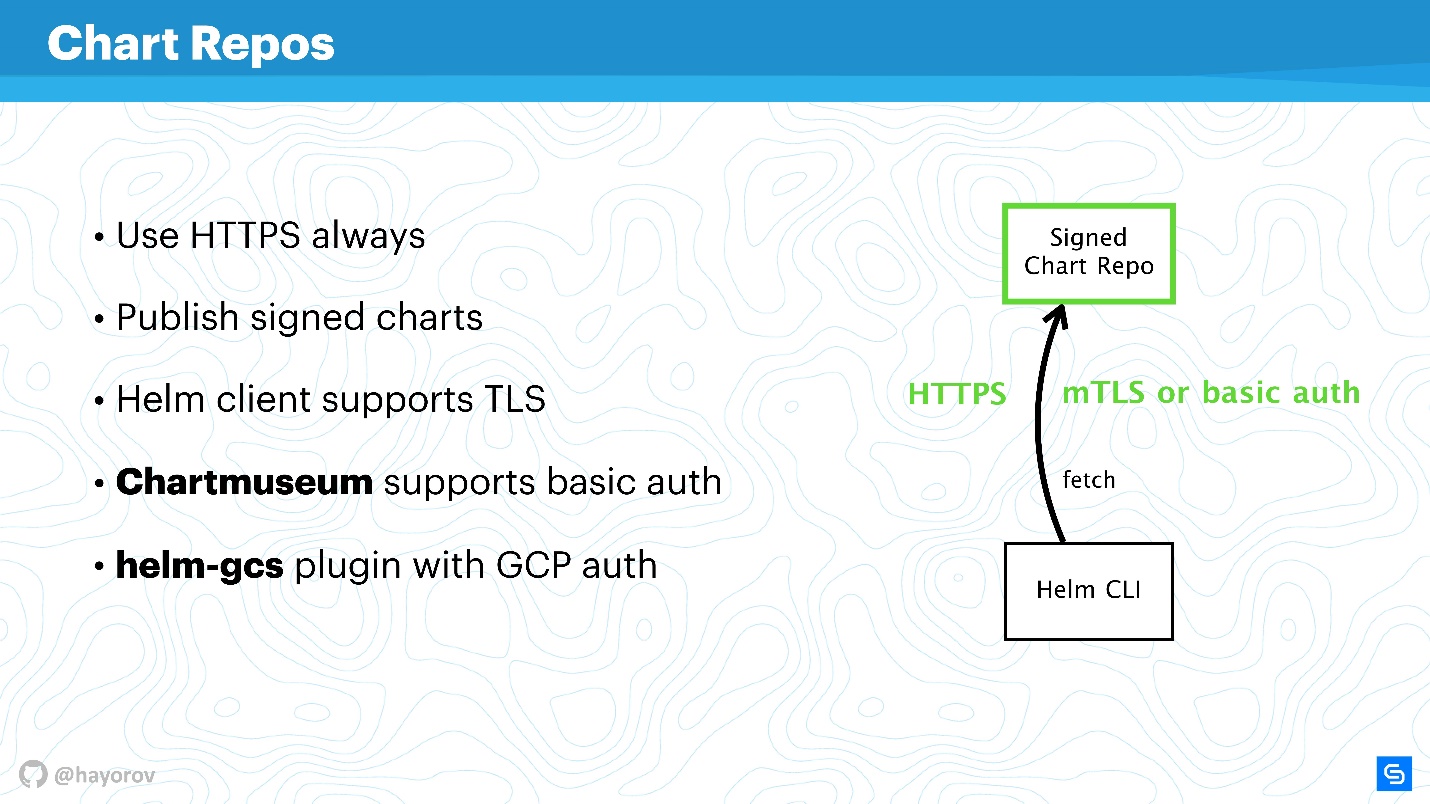
Charts are the most socially vulnerable and can become the source of "Man in the middle", especially if you use the stock solution. First of all, we are talking about repositories that are exposed via HTTP.
Definitely, you need to expose Helm Repo via HTTPS - this is the best option and is inexpensive.
Pay attention to the mechanism of chart signatures . The technology is simple to disgrace. This is the same thing you use on GitHub, the usual PGP machine with public and private keys. Set up and be sure, having the necessary keys and signing everything, this is really your chart.
In addition, the Helm client supports TLS (not in the sense of HTTP from the server side, but mutual TLS). You can use server and client keys in order to communicate. Frankly, I do not use such a mechanism because of dislike for mutual certificates. In principle, chartmuseum - the main Helm Repo exposure tool for Helm 2 - also supports basic auth. You can use basic auth if it's more convenient and calmer.
There is also a helm-gcs plugin that allows you to host Chart Repos on Google Cloud Storage. It is quite convenient, works great and is quite safe, because all the described mechanisms are utilized.
If you enable HTTPS or TLS, use mTLS, connect basic auth to further reduce risks, you will get a secure communication channel Helm CLI and Chart Repo.
gRPC API
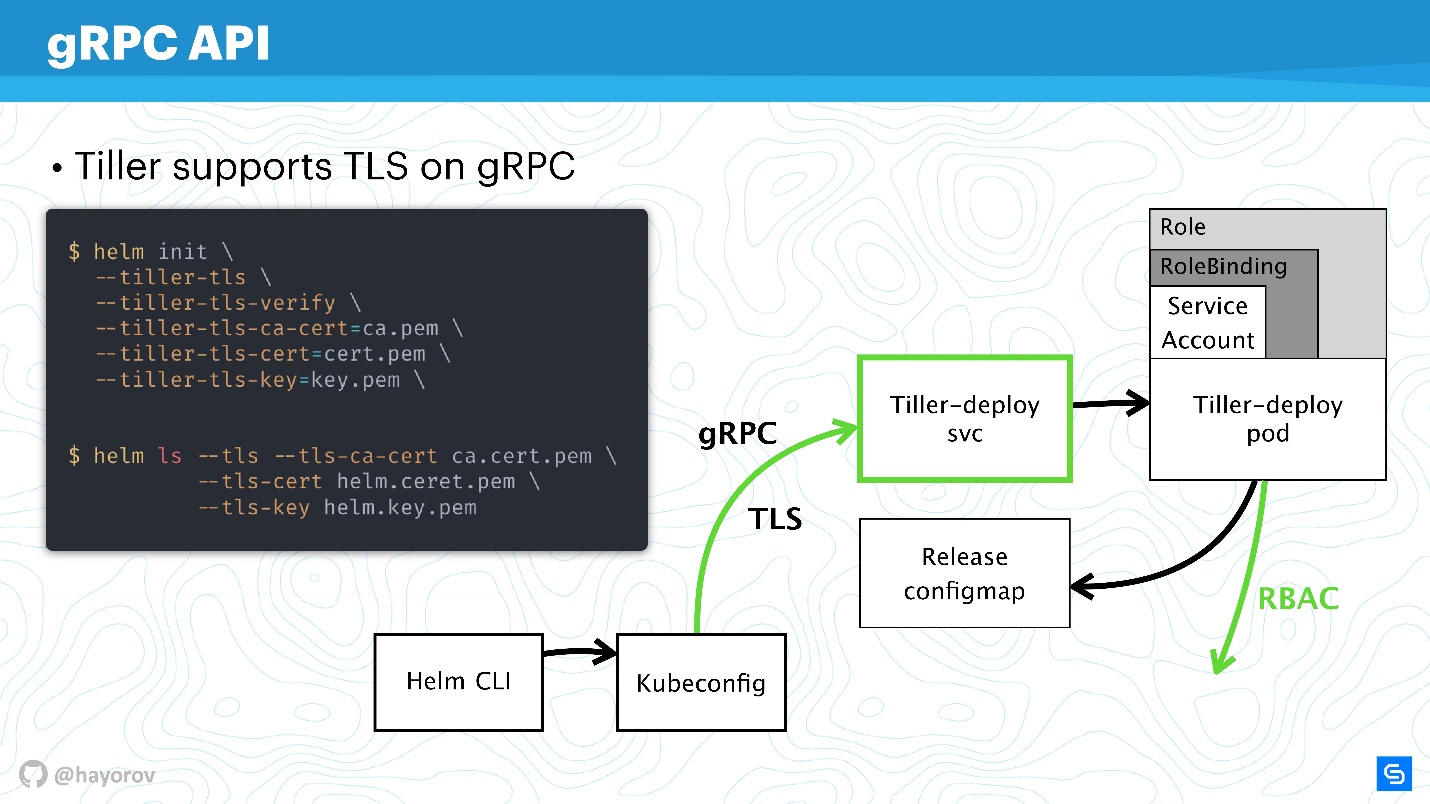
The next step is very responsible - to secure Tiller, which is located in the cluster and is, on the one hand, the server, on the other hand, it accesses other components and tries to introduce itself as someone.
As I said, Tiller is a service that exposes gRPC, a Helm client comes to it via gRPC. By default, of course, TLS is off. Why this is done is a debatable question, it seems to me to simplify the setup at the start.
For production and even for staging, I recommend enabling TLS on gRPC.
In my opinion, unlike mTLS for charts, here it is appropriate and is done very simply - generate a PQI infrastructure, create a certificate, launch Tiller, transfer the certificate during initialization. After that, you can execute all Helm commands, appearing to be a generated certificate and private key.
Thus, you will protect yourself from all requests to Tiller from outside the cluster.
So, we secured the connection channel to Tiller, already discussed RBAC and adjusted the rights of Kubernetes apiserver, reduced the domain with which it can interact.
Protected Helm
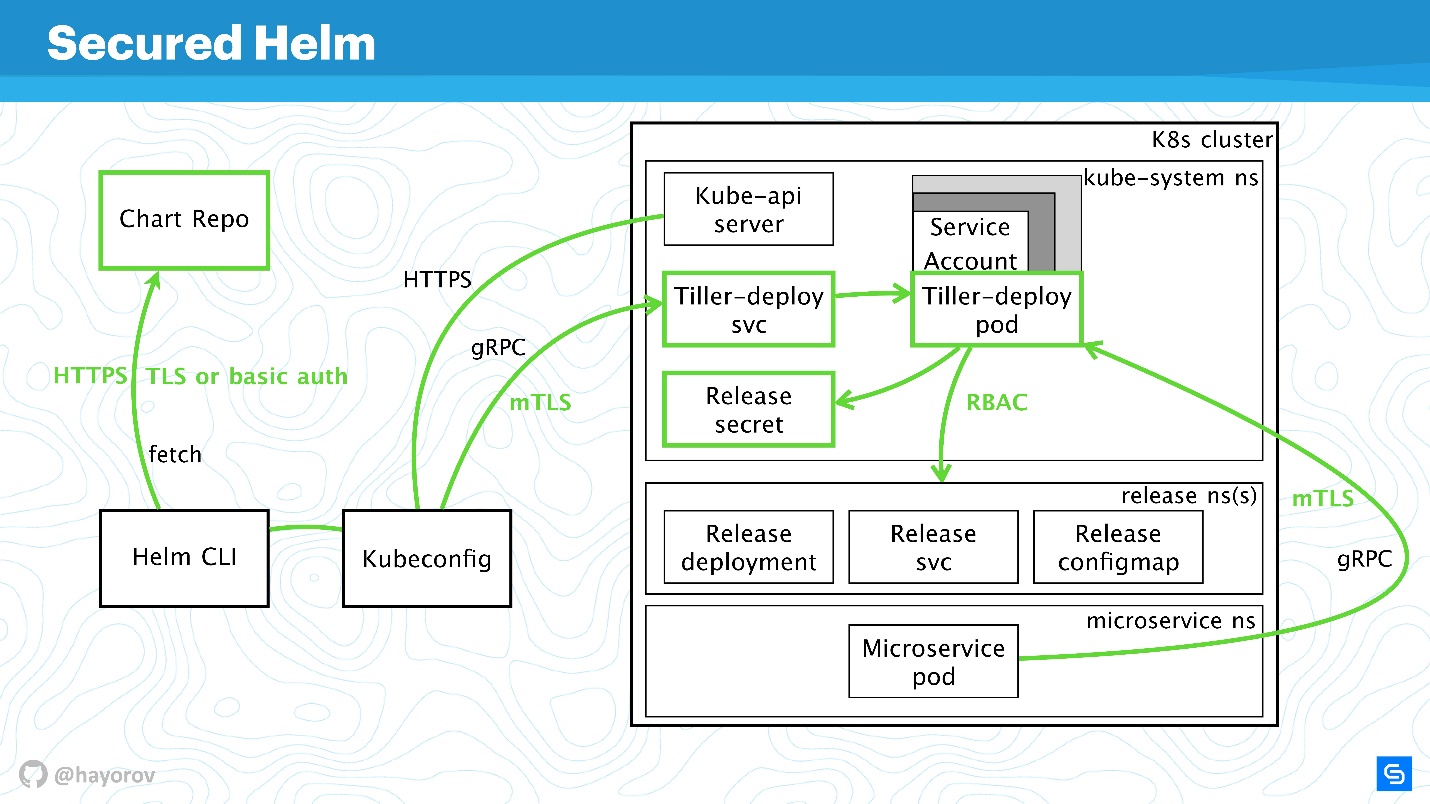
Let's look at the final diagram. This is the same architecture with the same arrows.
All connections can now be safely painted in green:
- for Chart Repo we use TLS or mTLS and basic auth;
- mTLS for Tiller, and it is exposed as a gRPC service with TLS, we use certificates;
- the cluster uses a special service account with Role and RoleBinding.
We markedly secured the cluster, but someone smart said:
“There can only be one absolutely safe solution - the computer is turned off, which is located in a concrete box and it is guarded by soldiers.”
There are different ways to manipulate data and find new attack vectors. However, I am confident that these recommendations will enable the implementation of a basic industry safety standard.
Bonus
This part is not directly related to security, but it will also be useful. I will show you some interesting things that few people know about. For example, how to search for charts - official and unofficial.
The github.com/helm/charts repository now has about 300 charts and two streams: stable and incubator. The contributor knows how difficult it is to get from incubator to stable, and how easy it is to fly out of stable. However, this is not the best tool to search for charts for Prometheus and all that you like for one simple reason is not a portal where it is convenient to search for packages.
But there is a hub.helm.sh service with which it is much more convenient to find charts. Most importantly, there are many more external repositories and almost 800 charots are available. Plus, you can connect your repository if for some reason you do not want to send your charts to stable.
Try hub.helm.sh and let's develop it together. This service is under the Helm project, and you can even contribute in its UI if you are a front-end vendor and want to simply improve the appearance.
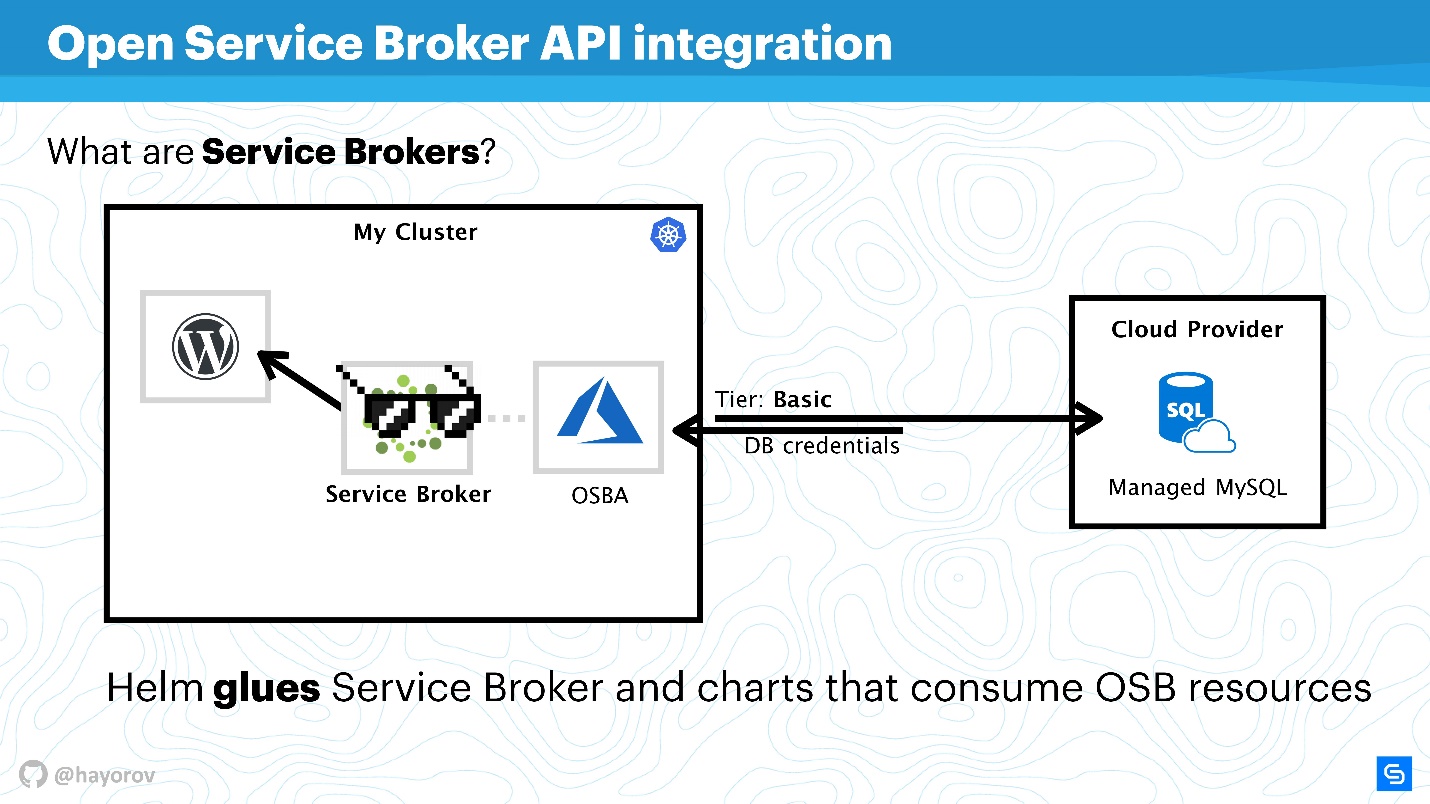
I also want to draw your attention to the Open Service Broker API integration . It sounds cumbersome and incomprehensible, but it solves the problems that everyone faces. I will explain with a simple example.
There is a Kubernetes-cluster in which we want to run the classic application - WordPress. As a rule, a database is needed for full functionality. There are many different solutions, for example, you can start your statefull service. This is not very convenient, but many do.
Others, like us at Chainstack, use managed databases, such as MySQL or PostgreSQL, for servers. Therefore, our databases are located somewhere in the cloud.
But a problem arises: you need to connect our service with the database, create a flavor database, pass credential and somehow manage it. All this is usually done manually by the system administrator or developer. And there is no problem when there are few applications. When there are many, you need a combine. There is such a combine - this is Service Broker. It allows you to use a special plug-in to the public cloud cluster and order resources from the provider through Broker, as if it were an API. To do this, you can use the native Kubernetes tools.
It is very simple. You can query, for example, Managed MySQL in Azure with a base tier (this can be configured). Using the Azure API, the base will be created and prepared for use. You do not need to interfere with this, the plugin is responsible for this. For example, OSBA (Azure plugin) will return credential to the service, pass this to Helm. You can use WordPress with cloudy MySQL, do not deal with managed databases at all, and don’t worry about statefull services inside.
We can say that Helm acts as a glue, which, on the one hand, allows you to deploy services, and on the other hand, it consumes the resources of cloud providers.
You can write your own plugin and use this entire on-premise story. Then you just have your own plugin for the corporate Cloud provider. I advise you to try this approach, especially if you have a large scale and you want to quickly deploy dev, staging or the entire infrastructure for a feature. This will make life easier for your operations or DevOps.
Another find that I have already mentioned is the helm-gcs plugin , which allows you to use Google buckets (object storage) to store Helm charts.
It takes only four commands to start using it:
- install the plugin;
- initiate it;
- set the path to bucket, which is located in gcp;
- publish charts in a standard way.
The beauty is that the native gcp method for authorization will be used. You can use the service account, the developer account - anything. It is very convenient and costs nothing to operate. If you, like me, advocate opsless philosophy, then this will be very convenient, especially for small teams.
Alternatives
Helm is not the only service management solution. There are a lot of questions to him, which is probably why the third version appeared so quickly. Of course there are alternatives.
It can be as specialized solutions, for example, Ksonnet or Metaparticle. You can use your classic infrastructure management tools (Ansible, Terraform, Chef, etc.) for the same purposes that I talked about.
Finally, there is the Operator Framework solution, the popularity of which is growing.
The Operator Framework is the main Helm alternative that you should pay attention to.
It is more native for CNCF and Kubernetes, but the entry threshold is much higher , you need to program more and describe manifestes less.
There are various addons, such as Draft, Scaffold. They make life much easier, for example, developers simplify the Helm send and launch cycle for deploying a test environment. I would call them extenders of opportunities.
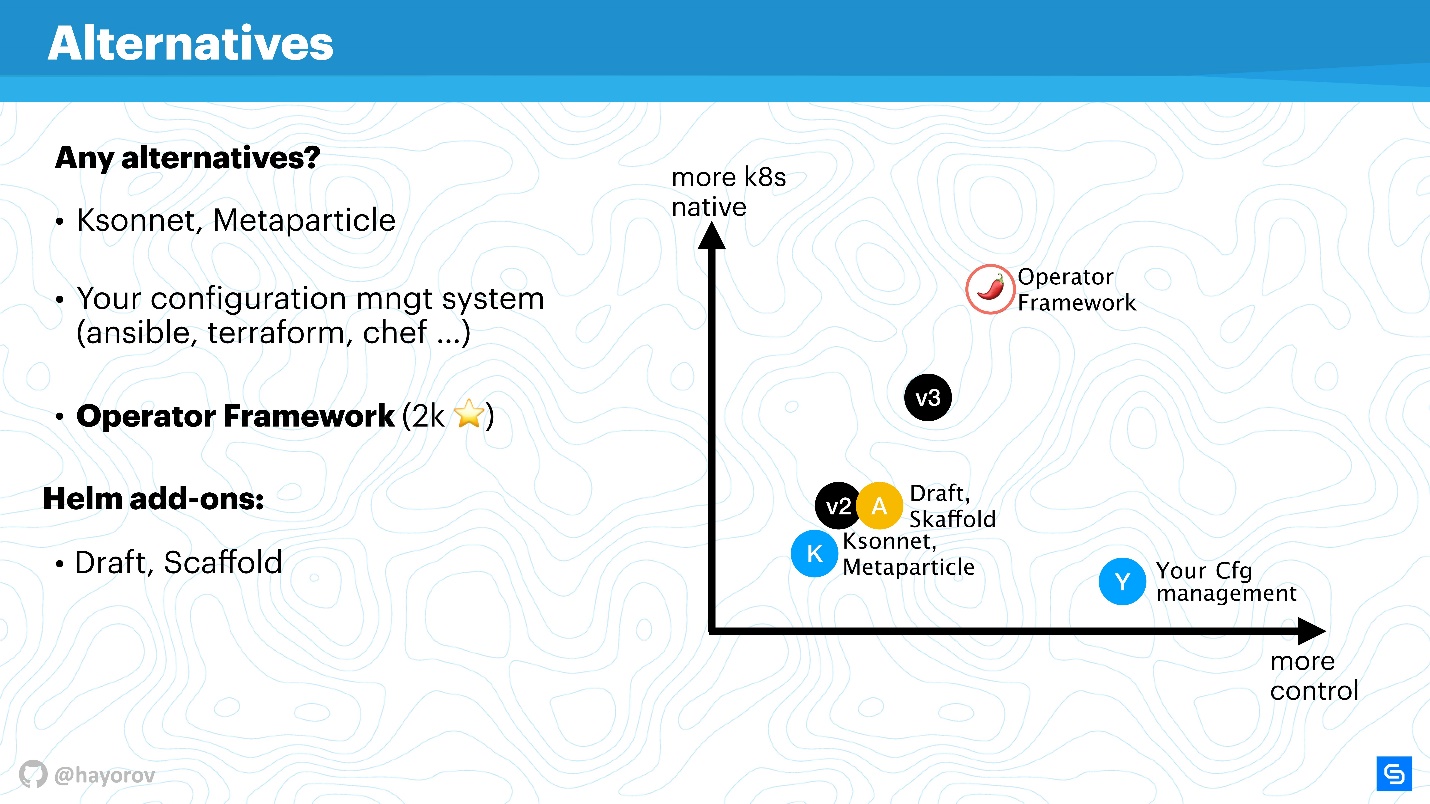
Here is a visual graph of where what is located.
On the x-axis, the level of your personal control over what is happening, on the y-axis, the level of Kubernetes nativeness. Helm version 2 is somewhere in the middle. In version 3, it is not colossal, but both control and level of nativeness are improved. Ksonnet solutions are still inferior even to Helm 2. However, they are worth a look to know what else is in this world. Of course, your configuration manager will be under your control, but absolutely not native to Kubernetes.
The Operator Framework is absolutely native to Kubernetes and allows you to manage it much more elegantly and meticulously (but remember the level of entry). Rather, it is suitable for a specialized application and creating management for it, rather than a mass harvester for packing a huge number of applications using Helm.
Extenders simply improve control a bit, complement workflow or cut corners of CI / CD pipelines.
The future of Helm
The good news is that Helm 3 is appearing. The alpha version of Helm 3.0.0-alpha.2 has already been released, you can try. It is quite stable, but functionality is still limited.
Why do you need Helm 3? First of all, this is the story of the disappearance of Tiller , as a component. This, as you already understand, is a huge step forward, because everything is simplified from the point of view of architectural security.
When Helm 2 was created, which was during Kubernetes 1.8 or even earlier, many concepts were immature. For example, the concept of CRD is being actively implemented, and Helm will use CRD to store structures. It will be possible to use only the client and not keep the server side. Accordingly, use native Kubernetes commands to work with structures and resources. This is a huge step forward.
Support for native OCI repositories (Open Container Initiative) will appear. This is a huge initiative, and Helm is interesting primarily for posting its charts. It comes to the point that, for example, the Docker Hub supports many OCI standards. I don’t think, but perhaps the classic providers of Docker repositories will start to give you the opportunity to place their Helm charts for you.
A controversial story for me is Lua's support as a templating engine for writing scripts. I'm not a big fan of Lua, but it will be a completely optional feature. I checked it 3 times - using Lua will not be necessary. Therefore, anyone who wants to be able to use Lua, someone who likes Go, join our huge camp and use go-tmpl for this.
, — . int string, . JSONS-, values.
event-driven model . . Helm 3, , , , , .
Helm 3 , , Helm 2, Kubernetes . , Helm Kubernetes Kubernetes.
, DevOpsConf , ? , , 30 1 . 20 DevOps-.
telegram- .
All Articles