Create a pipeline for streaming data processing. Part 2
Hello. We share the translation of the final part of the article, prepared especially for students of the Data Engineer course. The first part can be found here .
Apache Beam and DataFlow for real-time pipelines

To start the conveyor, we need to delve a little into the settings. For those of you who have not used GCP before, you must complete the following 6 steps on this page .
After that, we will need to upload our scripts to Google Cloud Storage and copy them to our Google Cloud Shel. Uploading to cloud storage is quite trivial (a description can be found here ). To copy our files, we can open the Google Cloud Shel from the toolbar by clicking the first icon on the left in Figure 2 below.

Figure 2
The commands we need to copy files and install the necessary libraries are listed below.
After we have completed all the configuration steps, the next thing we need to do is create a dataset and table in BigQuery. There are several ways to do this, but the easiest is to use the Google Cloud console by first creating a dataset. You can follow the steps in the following link to create a table with a schema. Our table will have 7 columns corresponding to the components of each user log. For convenience, we will define all columns as strings (type string), with the exception of the timelocal variable, and name them according to the variables that we generated earlier. The layout of our table should look like Figure 3.
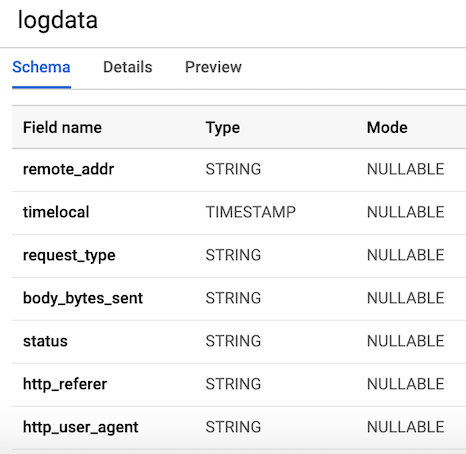
Figure 3. Table layout
Pub / Sub is a critical component of our pipeline because it allows several independent applications to interact with each other. In particular, it works as an intermediary that allows us to send and receive messages between applications. The first thing we need to do is create a topic. Just go to Pub / Sub in the console and press CREATE TOPIC.
The code below calls our script to generate the log data defined above, and then connects and sends the logs to Pub / Sub. The only thing we need to do is create a PublisherClient object, specify the path to the topic using the
method and call the
function with
and data. Please note that we import
from our
script, so make sure that these files are in the same folder, otherwise you will get an import error. Then we can run this through our google console using:
As soon as the file starts, we can observe the output of the log data to the console, as shown in the figure below. This script will work until we use CTRL + C to complete it.

Figure 4. Output of
Now that we’ve prepared everything, we can proceed to the most interesting part - writing the code of our pipeline using Beam and Python. To create a Beam pipeline, we need to create a pipeline object (p). After we create the pipeline object, we can apply several functions one after another using the
operator. In general, the workflow looks like the image below.
In our code, we will create two user-defined functions. The
function, which scans data and retrieves the corresponding row based on the PATTERNS list using the
function. The function returns a comma-separated string. If you are not a regular expression expert, I recommend that you read this tutorial and practice in notepad to check the code. After that, we define a custom ParDo function called Split , which is a variation of the Beam transform for parallel processing. In Python, this is done in a special way - we must create a class that inherits from the DoFn Beam class. The Split function takes a parsed string from the previous function and returns a list of dictionaries with keys corresponding to the column names in our BigQuery table. There is something worth noting about this function: I had to import the
inside the function for it to work. I received an import error at the beginning of the file, which was strange. This list is then passed to the WriteToBigQuery function, which simply adds our data to the table. The code for the Batch DataFlow Job and Streaming DataFlow Job is shown below. The only difference between batch and stream code is that in batch processing we read CSV from
using the
function from Beam.
We can start the pipeline in several different ways. If we wanted to, we could just run it locally from the terminal, remotely logging into GCP.
However, we are going to launch it using DataFlow. We can do this using the command below by setting the following required parameters.
While this command is running, we can go to the DataFlow tab in the google console and view our pipeline. By clicking on the pipeline, we should see something similar to Figure 4. For debugging purposes, it can be very useful to go to the logs and then to Stackdriver to view detailed logs. This helped me resolve problems with the pipeline in a number of cases.
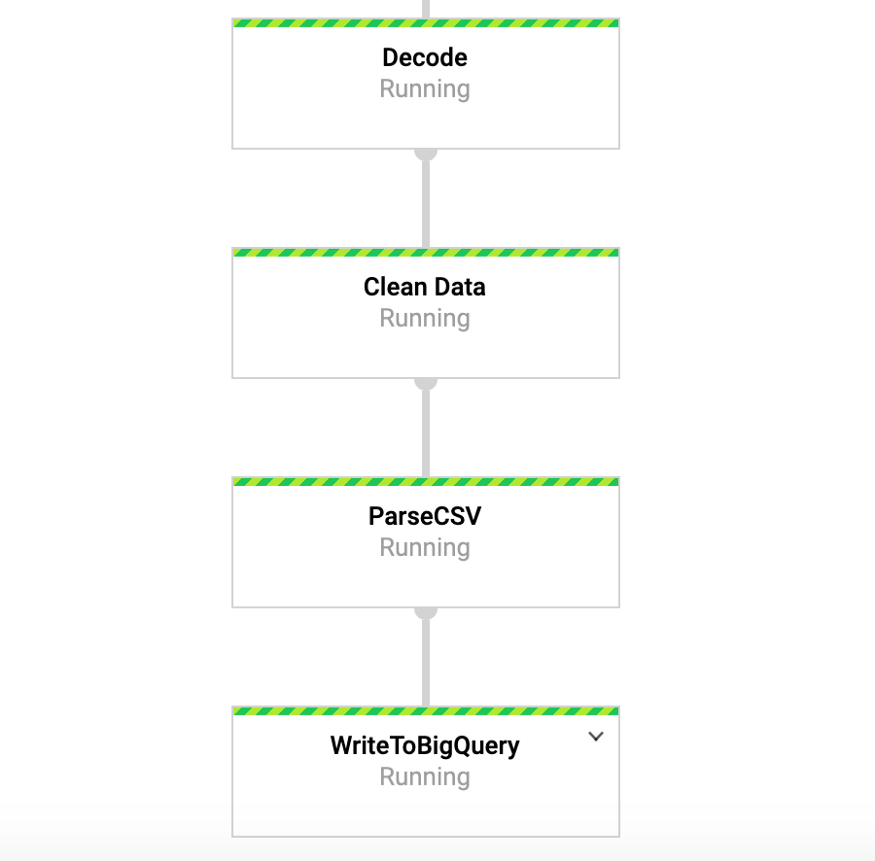
Figure 4: Beam Conveyor
So, we should already have started the pipeline with the data coming into our table. To test this, we can go to BigQuery and view the data. After using the command below, you should see the first few rows of the data set. Now that we have the data stored in BigQuery, we can conduct further analysis, as well as share data with colleagues and begin to answer business questions.

Figure 5: BigQuery
We hope that this post will serve as a useful example of creating a streaming data pipeline, as well as finding ways to make data more accessible. Storing data in this format gives us many advantages. Now we can begin to answer important questions, for example, how many people use our product? Is the user base growing over time? What aspects of the product do people interact with the most? And are there any errors where they should not be? These are questions that will be of interest to the organization. Based on the ideas stemming from the answers to these questions, we can improve the product and increase user interest.
Beam is really useful for this type of exercise, and also has a number of other interesting use cases. For example, you can analyze the data on exchange ticks in real time and make transactions based on the analysis, perhaps you have sensor data coming from vehicles and you want to calculate the calculation of the traffic level. You can also, for example, be a gaming company that collects user data and uses it to create dashboards to track key metrics. Okay, gentlemen, this topic is already for another post, thanks for reading, and for those who want to see the full code, below is a link to my GitHub.
https://github.com/DFoly/User_log_pipeline
That's all. Read the first part .
Apache Beam and DataFlow for real-time pipelines
Google Cloud Setup
Note: I used Google Cloud Shell to start the pipeline and publish the user log data, because I had problems running the pipeline in Python 3. Google Cloud Shell uses Python 2, which is better compatible with Apache Beam.
To start the conveyor, we need to delve a little into the settings. For those of you who have not used GCP before, you must complete the following 6 steps on this page .
After that, we will need to upload our scripts to Google Cloud Storage and copy them to our Google Cloud Shel. Uploading to cloud storage is quite trivial (a description can be found here ). To copy our files, we can open the Google Cloud Shel from the toolbar by clicking the first icon on the left in Figure 2 below.
Figure 2
The commands we need to copy files and install the necessary libraries are listed below.
# Copy file from cloud storage gsutil cp gs://<YOUR-BUCKET>/ * . sudo pip install apache-beam[gcp] oauth2client==3.0.0 sudo pip install -U pip sudo pip install Faker==1.0.2 # Environment variables BUCKET=<YOUR-BUCKET> PROJECT=<YOUR-PROJECT>
Creating our database and table
After we have completed all the configuration steps, the next thing we need to do is create a dataset and table in BigQuery. There are several ways to do this, but the easiest is to use the Google Cloud console by first creating a dataset. You can follow the steps in the following link to create a table with a schema. Our table will have 7 columns corresponding to the components of each user log. For convenience, we will define all columns as strings (type string), with the exception of the timelocal variable, and name them according to the variables that we generated earlier. The layout of our table should look like Figure 3.
Figure 3. Table layout
Publish user log data
Pub / Sub is a critical component of our pipeline because it allows several independent applications to interact with each other. In particular, it works as an intermediary that allows us to send and receive messages between applications. The first thing we need to do is create a topic. Just go to Pub / Sub in the console and press CREATE TOPIC.
The code below calls our script to generate the log data defined above, and then connects and sends the logs to Pub / Sub. The only thing we need to do is create a PublisherClient object, specify the path to the topic using the
topic_path
method and call the
publish
function with
topic_path
and data. Please note that we import
generate_log_line
from our
stream_logs
script, so make sure that these files are in the same folder, otherwise you will get an import error. Then we can run this through our google console using:
python publish.py
from stream_logs import generate_log_line import logging from google.cloud import pubsub_v1 import random import time PROJECT_ID="user-logs-237110" TOPIC = "userlogs" publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(PROJECT_ID, TOPIC) def publish(publisher, topic, message): data = message.encode('utf-8') return publisher.publish(topic_path, data = data) def callback(message_future): # When timeout is unspecified, the exception method waits indefinitely. if message_future.exception(timeout=30): print('Publishing message on {} threw an Exception {}.'.format( topic_name, message_future.exception())) else: print(message_future.result()) if __name__ == '__main__': while True: line = generate_log_line() print(line) message_future = publish(publisher, topic_path, line) message_future.add_done_callback(callback) sleep_time = random.choice(range(1, 3, 1)) time.sleep(sleep_time)
As soon as the file starts, we can observe the output of the log data to the console, as shown in the figure below. This script will work until we use CTRL + C to complete it.
Figure 4. Output of
publish_logs.py
Writing code for our pipeline
Now that we’ve prepared everything, we can proceed to the most interesting part - writing the code of our pipeline using Beam and Python. To create a Beam pipeline, we need to create a pipeline object (p). After we create the pipeline object, we can apply several functions one after another using the
pipe (|)
operator. In general, the workflow looks like the image below.
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform] | [Second Transform] | [Third Transform])
In our code, we will create two user-defined functions. The
regex_clean
function, which scans data and retrieves the corresponding row based on the PATTERNS list using the
re.search
function. The function returns a comma-separated string. If you are not a regular expression expert, I recommend that you read this tutorial and practice in notepad to check the code. After that, we define a custom ParDo function called Split , which is a variation of the Beam transform for parallel processing. In Python, this is done in a special way - we must create a class that inherits from the DoFn Beam class. The Split function takes a parsed string from the previous function and returns a list of dictionaries with keys corresponding to the column names in our BigQuery table. There is something worth noting about this function: I had to import the
datetime
inside the function for it to work. I received an import error at the beginning of the file, which was strange. This list is then passed to the WriteToBigQuery function, which simply adds our data to the table. The code for the Batch DataFlow Job and Streaming DataFlow Job is shown below. The only difference between batch and stream code is that in batch processing we read CSV from
src_path
using the
ReadFromText
function from Beam.
Batch DataFlow Job (packet processing)
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import bigquery import re import logging import sys PROJECT='user-logs-237110' schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' src_path = "user_log_fileC.txt" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'status': element[3], 'body_bytes_sent': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(): p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.textio.ReadFromText(src_path) | "clean address" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) p.run() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Streaming DataFlow Job
from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import pubsub_v1 from google.cloud import bigquery import apache_beam as beam import logging import argparse import sys import re PROJECT="user-logs-237110" schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' TOPIC = "projects/user-logs-237110/topics/userlogs" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'body_bytes_sent': element[3], 'status': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(argv=None): parser = argparse.ArgumentParser() parser.add_argument("--input_topic") parser.add_argument("--output") known_args = parser.parse_known_args(argv) p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes) | "Decode" >> beam.Map(lambda x: x.decode('utf-8')) | "Clean Data" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) result = p.run() result.wait_until_finish() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Conveyor start
We can start the pipeline in several different ways. If we wanted to, we could just run it locally from the terminal, remotely logging into GCP.
python -m main_pipeline_stream.py \ --input_topic "projects/user-logs-237110/topics/userlogs" \ --streaming
However, we are going to launch it using DataFlow. We can do this using the command below by setting the following required parameters.
-
project
- The ID of your GCP project. -
runner
is a pipelinerunner
that will analyze your program and construct your pipeline. To run in the cloud, you must specify a DataflowRunner. -
staging_location
- The path to the Cloud Dataflow cloud storage for indexing the code packets needed by the process handlers. -
temp_location
- the path to the Cloud Dataflow cloud storage to host temporary job files created during the operation of the pipeline. -
streaming
python main_pipeline_stream.py \ --runner DataFlow \ --project $PROJECT \ --temp_location $BUCKET/tmp \ --staging_location $BUCKET/staging --streaming
While this command is running, we can go to the DataFlow tab in the google console and view our pipeline. By clicking on the pipeline, we should see something similar to Figure 4. For debugging purposes, it can be very useful to go to the logs and then to Stackdriver to view detailed logs. This helped me resolve problems with the pipeline in a number of cases.
Figure 4: Beam Conveyor
Access our data in BigQuery
So, we should already have started the pipeline with the data coming into our table. To test this, we can go to BigQuery and view the data. After using the command below, you should see the first few rows of the data set. Now that we have the data stored in BigQuery, we can conduct further analysis, as well as share data with colleagues and begin to answer business questions.
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;
Figure 5: BigQuery
Conclusion
We hope that this post will serve as a useful example of creating a streaming data pipeline, as well as finding ways to make data more accessible. Storing data in this format gives us many advantages. Now we can begin to answer important questions, for example, how many people use our product? Is the user base growing over time? What aspects of the product do people interact with the most? And are there any errors where they should not be? These are questions that will be of interest to the organization. Based on the ideas stemming from the answers to these questions, we can improve the product and increase user interest.
Beam is really useful for this type of exercise, and also has a number of other interesting use cases. For example, you can analyze the data on exchange ticks in real time and make transactions based on the analysis, perhaps you have sensor data coming from vehicles and you want to calculate the calculation of the traffic level. You can also, for example, be a gaming company that collects user data and uses it to create dashboards to track key metrics. Okay, gentlemen, this topic is already for another post, thanks for reading, and for those who want to see the full code, below is a link to my GitHub.
https://github.com/DFoly/User_log_pipeline
That's all. Read the first part .
All Articles