そのため、彼らのプロジェクトの1つでは、データベースから主題情報をすばやく検索する必要がありました。 現在、このような問題を解決するために、投稿のタグと見出しが使用されています。 しかし、私の場合、これはオプションではありませんでした。 問題のステートメントは次のとおりです。入力された2つまたは3つの単語に基づいて、これらの単語を含むレコードを取得する必要があります。
データベースの簡略化された形式の構造を図に示します。
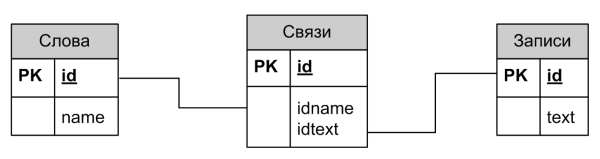
「単語」テーブルには、既存のレコードに表示されるすべての単語、「レコード」テーブル、レコードのテキストがそれぞれ含まれ、「リンク」テーブルには、対応する単語のレコードによる使用へのリンクが含まれます。
この単純化された検索エンジンのすべての作業には、多くのステップが含まれています。 最初のステップは、新しいレコードを追加することです。 したがって、レコードのテキスト全体が単語の配列に分割されます。 その後、データベースに対するいくつかのクエリが実行されます。これらの単語が既に「単語」テーブルにあるかどうかがチェックされ、そうでない場合は、必要なすべてのエントリが追加されます。 各単語の識別子が決定されます。 最後の手順は、単語とレコードの識別子のペアをリンクテーブルに追加することです。
編集は、基本的にエントリの追加と同じですが、最初に「リンク」テーブルから編集中のテキストに関連するすべてのエントリを削除する必要があります。 削除しても問題はないと思います。
さて、レコード検索自体について。 ユーザーが検索フィールドに単語を入力するとします。 検索フィールド自体は、自己入力型の入力フィールドです。
ステップ1:

ステップ2:
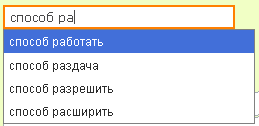
ステップ3:
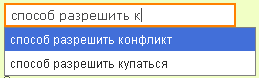
つまり、次の単語を入力すると、使用可能な単語のうち、最初のケースでは文字「c」が「Records」テーブルのレコードにあるかどうかがチェックされます。 2番目のステップでは、「ra」で始まる単語が、「method」という単語が含まれているエントリにあるかどうかがチェックされます。 3番目のステップでは、単語「method」と「allow」がすでに存在するエントリで単語「k」が検索されます。 多数のエントリの間でも、検索用の3つの単語で十分だと思います。
単語のセットが形成された後、検索に進みます。 ここではすべてが簡単です。 入力フィールドに入力された単語の識別子が決定され、「リンク」テーブルのエントリがフィルタリングされます。そこには単語の識別子があります。 結果の配列から、すべての検索語が存在する「レコード」テーブルのエントリの識別子が決定されます。
最終的に何になりますか?
最終的に、ユーザーは要求に応じて必要なレコードをすばやく検索することができます。さらに、システム自体がこの要求を作成するのに役立ちます。 さらに、タグシステムについて話すと、その必要性は完全になくなります。 しかし、それはむしろ好みの問題です。