64ビットアプリケーションの開発に関する記事の読者は、説明されている問題が実証されていないことを非難することがよくあります。 つまり、実際のアプリケーションでのエラーの例は示していません。
インターネットで読んだり、PVS-Studioユーザーが私たちに言った実際のプログラムで発見したさまざまな種類のエラーの例を収集することにしました。 そこで、CおよびC ++での64ビットエラーの30の例のコレクションである記事に注目します。
記事の続き>>
はじめに
当社のOOO「プログラム検証システム」は、C / C ++のアプリケーションコードの64ビットエラーを検出する専用の静的アナライザーViva64を開発しています。 この作業中、64ビットの欠陥の例のコレクションは常に更新されており、この記事の意見で最も興味深いエラーを収集することにしました。 この記事では、実際のアプリケーションのコードから直接取られた例と、実際のコードに基づいて合成的にコンパイルされた例を示します。
この記事では、さまざまなタイプの64ビットエラーについてのみ説明し、それらの検出および防止の方法については説明しません。 以下のリソースに連絡することにより、64ビットプログラムの欠陥を診断および修正する方法について詳しく知ることができます。
- C / C ++での64ビットアプリケーションの開発コース [1]。
- size_tおよびptrdiff_tとは何ですか [2]。
- C ++コードを64ビットプラットフォームに移植する際の20の落とし穴 [3]。
- PVS-Studioのチュートリアル [4];
- カウントできる64ビットの馬 [5]。
例1.バッファーオーバーフロー
struct STRUCT_1
{
int * a;
};
struct STRUCT_2
{
int x;
};
...
STRUCT_1 Abcd;
STRUCT_2 Qwer;
memset(&Abcd、0、sizeof(Abcd));
memset(&Qwer、0、sizeof(Abcd));
タイプSTRUCT_1およびSTRUCT_2の2つのオブジェクトがプログラムで宣言されています。これらは、最初に使用する前にクリアする必要があります(すべてのフィールドをゼロで初期化します)。 初期化を実装する際、プログラマーは同様の行をコピーし、「&Abcd」を「&Qwer」に置き換えました。 しかし同時に、彼は「sizeof(Abcd)」を「sizeof(Qwer)」に置き換えるのを忘れていました。幸いなことに、STRUCT_1構造体とSTRUCT_2構造体のサイズは32ビットシステムで一致し、コードは長い間正しく機能していました。
コードを64ビットシステムに移植すると、Abcd構造のサイズが増加し、その結果、バッファーオーバーフローエラーが発生しました(図1を参照)。
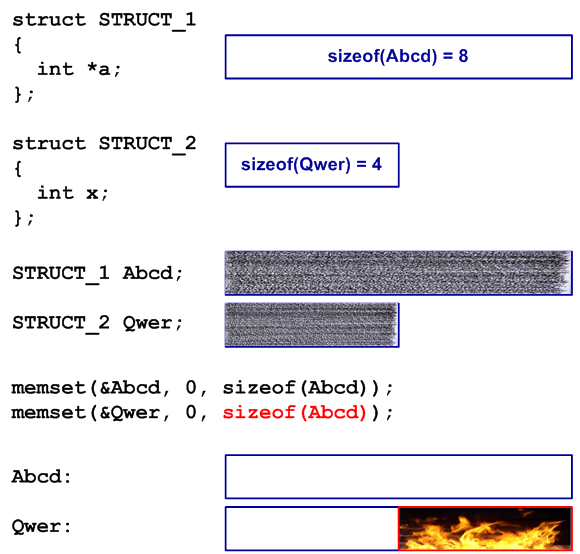
図1-バッファオーバーフローの例の概略説明
そのようなエラーは、後で使用されるデータが劣化した場合、検出が困難になる可能性があります。
例2.余分なキャスト
char * buffer;
char * curr_pos;
int長さ;
...
while((*(curr_pos ++)!= 0x0a)&&
((UINT)curr_pos-(UINT)バッファー<(UINT)長さ));
コードは悪いですが、実際のコードです。 彼の仕事は、0x0Aで示される行の終わりを見つけることです。 可変長はint型であるため、INT_MAX文字より長い行ではコードは機能しません。 ただし、別のエラーに興味があるので、プログラムは小さなバッファーで動作し、int型の使用は正しいと仮定します。
問題は、64ビットシステムでは、バッファーおよびcurr_posポインターがアドレススペースの最初の4ギガバイトの外側にある可能性があることです。 この場合、UINT型へのポインターの明示的なキャストは、重要なビットを破棄し、アルゴリズムに違反します(図2を参照)。
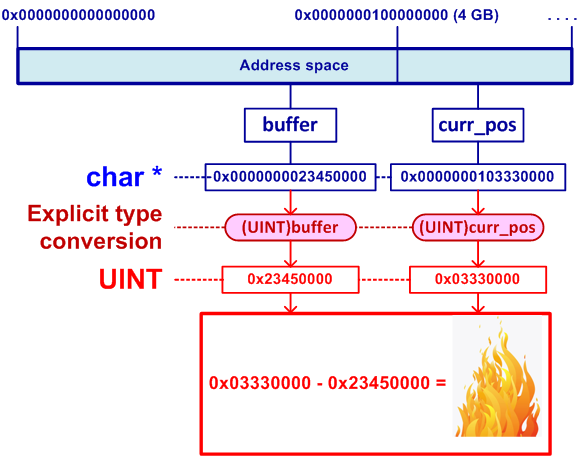
図2-終端記号を検索するときの誤った計算
このエラーは、バッファのメモリがアドレス空間の下位4ギガバイトに割り当てられている間、コードが長時間正常に動作できるという点で不快です。 バグ修正は、完全に不要な明示的な型変換を削除することです:
while(curr_pos-バッファー<length && * curr_pos!= '\ r') curr_pos ++;
例3.無効な#ifdef
多くの場合、長い歴史を持つプログラムでは、#ifdef--#else-#endif構造にラップされたコードのセクションを見つけることができます。 プログラムを新しいアーキテクチャに移植する場合、誤って記述された条件により、過去に開発者が計画した誤ったコードフラグメントがコンパイルされる可能性があります(図3を参照)。 例:
#ifdef _WIN32 // Win32コード cout << "これはWin32です" << endl; #else // win16コード cout << "これはWin16です" << endl; #endif //間違った代替オプション: #ifdef _WIN16 // Win16コード cout << "これはWin16です" << endl; #else // win32コード cout << "これはWin32です" << endl; #endif

図3-2つのオプション-これは少なすぎる
このような状況で#elseオプションを使用するのは危険です。 各ケースの動作を明示的に検討し(図4を参照)、コンパイルエラーメッセージを#elseブランチに配置することをお勧めします。
#if defined _M_X64 // Win64コード(Intel 64) cout << "これはWin64" << endl; #elif defined _WIN32 // Win32コード cout << "これはWin32です" << endl; #elif defined _WIN16 // Win16コード cout << "これはWin16です" << endl; #else static_assert(false、「不明なプラットフォーム」); #endif

図4-すべての可能なコンパイルパスがチェックされます
例4. intおよびintとの混同*
古いプログラム、特にCでは、ポインターがint型に格納されているコードスニペットは珍しくありません。 ただし、これは意図的に行われず、不注意によって行われる場合があります。 型intと型intへのポインターの使用に起因する混乱を含む例を考えてみましょう。
int GlobalInt = 1;
void GetValue(int ** x)
{
* x =&GlobalInt;
}
void SetValue(int * x)
{
GlobalInt = * x;
}
...
int XX;
GetValue((int **)&XX);
SetValue((int *)XX);
この例では、変数XXは、ポインターを保持するバッファーとして使用されます。 このコードは、ポインターのサイズがint型のサイズと一致する32ビットシステムで正しく機能します。 64ビットシステムでは、このコードは正しくなく、呼び出しは
GetValue((int **)&XX);
変数XXの隣の4バイトのメモリが破損します(図5を参照)。

図5-変数XXの隣のメモリ破損
上記のコードは、初心者によってまたは急いで書かれました。 さらに、明示的な型変換は、コンパイラが最後に抵抗したことを示し、ポインターとintが異なるエンティティであることを開発者に示唆します。 しかし、ブルートフォースが勝ちました。
エラー修正は基本的であり、変数XXに適切なタイプを選択することにあります。 この場合、明示的なキャストは必要なくなります。
int * XX; GetValue(&XX); SetValue(XX);
例5.非推奨の機能を使用する
多くのAPI関数は、互換性のために残されていますが、64ビットアプリケーションを開発する際に危険をもたらします。 典型的な例は、SetWindowLongやGetWindowLongなどの関数の使用です。 プログラムでは、次のようなコードを見つけることができます。
SetWindowLong(window、0、(LONG)this); ... Win32Window * this_window =(Win32Window *)GetWindowLong(window、0);
かつてこのコードを書いたプログラマーに責任はありません。 約5〜10年前の開発中、プログラマと経験とMSDNを活用して、32ビットWindowsシステムの観点から完全に正しいコードをコンパイルしました。 これらの関数のプロトタイプは次のとおりです。
LONG WINAPI SetWindowLong(HWND hWnd、int nIndex、LONG dwNewLong); LONG WINAPI GetWindowLong(HWND hWnd、int nIndex);
ポインターのサイズとLONGタイプはWin32システムで同じであるため、ポインターがLONGタイプに明示的にキャストされるという事実も正当化されます。 しかし、64ビットバージョンでプログラムを再コンパイルすると、型キャストのデータによってアプリケーションがクラッシュまたは誤動作する可能性があることは明らかだと思います。
ミスの不愉快さは、その不規則な、または非常にまれな症状にさえあります。 エラーが発生するかどうかは、「this」ポインタが指すオブジェクトが作成されるメモリの領域によって異なります。 オブジェクトが下位4ギガバイトのアドレス空間で作成された場合、64ビットプログラムは正しく機能します。 エラーは、メモリの割り当てにより、オブジェクトが最初の4ギガバイトの外側で作成され始めると、長期間後に予期せずに現れます。
64ビットシステムでは、プログラムが実際にLONG、int、boolなどの値を保存する場合にのみ、SetWindowLong / GetWindowLong関数を使用できます。 ポインターを使用する必要がある場合は、関数の詳細オプションSetWindowLongPtr / GetWindowLongPtrを使用する必要があります。 おそらく、将来新しいエラーを引き起こさないように、どのような場合でも新しい関数を使用することをお勧めします。
SetWindowLongおよびGetWindowLong関数を使用した例は古典的なものであり、64ビットアプリケーションの開発に関するほとんどすべての記事に記載されています。 ただし、ビジネスはこれらの機能に限定されないことに注意してください。 次のことに注意してください:SetClassLong、GetClassLong、GetFileSize、EnumProcessModules、GlobalMemoryStatus(図6を参照)。
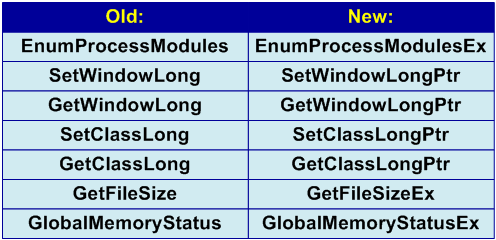
図6-廃止された最新の関数の名前を含む表
例6.暗黙的な型変換による値のトリミング
size_tから符号なしおよび類似のキャストへの暗黙のキャストは、コンパイラーの警告で十分に診断されます。 ただし、大規模なプログラムでは、このような警告は簡単に失われる可能性があります。 警告が無視された実際のコードに似た例を考えてみましょう。これは、短い行を操作しても何も悪いことは起きないように思われるためです。
bool Find(const ArrayOfStrings&arrStr)
{
ArrayOfStrings :: const_iterator it;
for(it = arrStr.begin(); it!= arrStr.end(); ++ it)
{
符号なしn = it-> find( "ABC"); //切り捨て
if(n!= string :: npos)
trueを返します。
}
falseを返します。
};
上記の関数は、文字列の配列でテキスト「ABC」を検索し、少なくとも1つの文字列にシーケンス「ABC」が含まれている場合にtrueを返します。 コードの64ビットバージョンをコンパイルする場合、この関数は常にtrueを返します。
64ビットシステムの定数「string :: npos」の値は、size_t型の0xFFFFFFFFFFFFFFFFFFです。 この値が符号なしタイプの変数「n」に配置されると、0xFFFFFFFFに切り捨てられます。 その結果、0xFFFFFFFFFFFFFFFFFFは0xFFFFFFFFと等しくないため、条件 "n!= String :: npos"は常に真になります(図7を参照)。

図7-値トリミングエラーの概略説明
修正は簡単で、コンパイラの警告を聞いてください:
for(auto it = arrStr.begin(); it!= arrStr.end(); ++ it)
{
auto n = it-> find( "ABC");
if(n!= string :: npos)
trueを返します。
}
falseを返します。
例7. Cで宣言されていない関数
長年にもかかわらず、Cで書かれたプログラムまたはプログラムの一部は、すべての生物よりも生き続けています。 これらのプログラムのコードは、C言語の型制御規則が厳しくないため、64ビットエラーが発生しやすくなっています。
Cでは、最初に宣言せずに関数を使用できます。 これに関連する64ビットエラーの興味深い例を分析してみましょう。 まず、3ギガバイトサイズの配列の割り当てと使用がそれぞれ発生する正しいバージョンのコードを検討します。
#include <stdlib.h>
ボイドテスト()
{
const size_t Gbyte = 1024 * 1024 * 1024;
size_t i;
char *ポインター[3];
//割り当てます
for(i = 0; i!= 3; ++ i)
ポインター[i] =(char *)malloc(Gbyte);
//使用
for(i = 0; i!= 3; ++ i)
ポインター[i] [0] = 1;
//無料
for(i = 0; i!= 3; ++ i)
無料(ポインター[i]);
}
このコードは、メモリを正しく割り当て、各配列の最初の要素に1つずつ書き込み、占有メモリを解放します。 コードは64ビットシステムで正常に動作します。
「#include <stdlib.h>」行を削除またはコメントアウトします。 コードは引き続き収集されますが、プログラムが起動するとクラッシュします。 ヘッダーファイル「stdlib.h」が接続されていない場合、Cコンパイラはmalloc関数がintを返すと見なします。 最初の2つのメモリ割り当ては成功する可能性があります。 3回目の呼び出しで、malloc関数は最初の2ギガバイトを超える配列のアドレスを返します。 コンパイラーは関数の結果がintであると信じているため、結果を誤って解釈し、ポインター配列に誤ったポインター値を格納します。
64ビットデバッグバージョン用にVisual C ++コンパイラーによって生成されたアセンブラーコードを検討してください。 最初に、malloc関数宣言が存在するときに生成される正しいコードが提供されます(ファイル「stdlib.h」が接続されています)。
ポインター[i] =(char *)malloc(Gbyte); mov rcx、qword ptr [Gbyte] qword ptr [__imp_malloc(14000A518h)]を呼び出します mov rcx、qword ptr [i] mov qword ptrポインター[rcx * 8]、rax
ここで、malloc関数の宣言がない場合の不正なコードのバリアントを考えます。
ポインター[i] =(char *)malloc(Gbyte); mov rcx、qword ptr [Gbyte] mallocを呼び出す(1400011A6h) cdqe mov rcx、qword ptr [i] mov qword ptrポインター[rcx * 8]、rax
CDQE(ダブルワードからクワッドワードへの変換)ステートメントの可用性に注意してください。 コンパイラーは、結果がeaxレジスターにあると計算し、それを64ビット値に拡張してPointers配列に書き込みます。 したがって、raxレジスタの上位ビットは失われます。 割り当てられたメモリのアドレスが最初の4ギガバイト内にある場合でも、eaxレジスタの高ビットが1の場合、間違った結果が得られます。 たとえば、アドレス0x81000000は0xFFFFFFFF81000000になります。
例8.大きくて古いプログラムの恐竜の残骸
何十年にもわたって開発されてきた大規模な古いソフトウェアシステムには、さまざまなアタビズムと、長年にわたって一般的なパラダイムとスタイルを使用して記述されたコードの断片が数多くあります。 そのようなシステムでは、最も古い部分がC言語のスタイルで記述されている場合、プログラミング言語の開発の進化を観察できます。最新の部分では、Alexandrescuのスタイルの複雑なテンプレートを見つけることができます。

図8-恐竜の発掘
64ビットに関連するアタビズムがあります。 むしろ、現代の64ビットコードの動作を妨げるアタビズム。 例を考えてみましょう:
//これを超えて、プログラミングエラーを想定
#define MAX_ALLOCATION 0xc0000000
void * malloc_zone_calloc(malloc_zone_t *ゾーン、
size_t num_items、size_tサイズ)
{
void * ptr;
...
if(((unsigned)num_items> = MAX_ALLOCATION)||
((符号なし)サイズ> = MAX_ALLOCATION)||
((long long)サイズ* num_items> =
(long long)MAX_ALLOCATION))
{
fprintf(stderr、
"*** malloc_zone_calloc [%d]:引数が大きすぎます:%d、%d \ n"、
getpid()、(符号なし)num_items、(符号なし)サイズ);
NULLを返します。
}
ptr = zone-> calloc(zone、num_items、size);
...
return ptr;
}
まず、関数コードには、割り当てられたメモリの許容サイズのチェックが含まれていますが、これは64ビットシステムにとって奇妙なことです。 そして次に、発行される診断メッセージは正しくありません。なぜなら、明示的にunsignedにキャストするために4,400,000,000の要素にメモリを割り当てると、105,032,704の要素にのみメモリを割り当てることができないという奇妙なメッセージが表示されるからです。
例9.仮想関数
64ビットエラーの美しい例の1つは、仮想関数宣言での無効な引数タイプの使用です。 通常、それは誰かのずさんなものではなく、単に「事故」であり、有罪当事者はいませんが、間違いがあります。 次の状況を考慮してください。
太古の昔から、MFCライブラリには、WinHelp関数を持つCWinAppクラスがあります。
クラスCWinApp {
...
仮想void WinHelp(DWORD dwData、UINT nCmd);
};
ユーザーアプリケーションで独自のヘルプを表示するには、この機能をブロックする必要がありました。
クラスCSampleApp:public CWinApp {
...
仮想void WinHelp(DWORD dwData、UINT nCmd);
};
そして、64ビットシステムが登場するまではすべて順調でした。 MFC開発者は、WinHelp関数(および他のいくつかの関数)のインターフェイスを次のように変更する必要がありました。
クラスCWinApp {
...
仮想ボイドWinHelp(DWORD_PTR dwData、UINT nCmd);
};
32ビットモードでは、タイプDWORD_PTRとDWORDは一致していましたが、64ビットモードではいいえです。 当然、ユーザーアプリケーションの開発者も型をDWORD_PTRに変更する必要がありますが、これを行うには、最初にこれについて調べる必要があります。 その結果、ユーザークラスのWinHelp関数が呼び出されないため、64ビットプログラムでエラーが発生します(図9を参照)。

図9-仮想機能に関連するエラー
例10.パラメーターとしてのマジックナンバー
プログラムの本体に含まれるマジックナンバーはスタイルが悪く、エラーを引き起こします。 マジックナンバーの例は1024および768であり、これらは画面解像度のサイズを厳密に示します。 この記事のフレームワークでは、64ビットアプリケーションで問題を引き起こす可能性のあるマジックナンバーに興味があります。 64ビットプログラムにとって危険な最も一般的な数値を図10の表に示します。

図10-64ビットプログラムにとって危険なマジックナンバー
CADシステムの1つで発生したCreateFileMapping関数の使用例を示しましょう。
ハンドルhFileMapping = CreateFileMapping( (ハンドル)0xFFFFFFFF、 NULL PAGE_READWRITE、 dwMaximumSizeHigh、 dwMaximumSizeLow、 名前);
正しい予約済み定数INVALID_HANDLE_VALUEの代わりに、数字0xFFFFFFFFが使用されます。 これは、INVALID_HANDLE_VALUE定数が値0xFFFFFFFFFFFFFFFFをとるWin64プログラムでは正しくありません。 関数を呼び出す正しいオプションは次のとおりです。
ハンドルhFileMapping = CreateFileMapping( INVALID_HANDLE_VALUE、 NULL PAGE_READWRITE、 dwMaximumSizeHigh、 dwMaximumSizeLow、 名前);
ご注意 一部の人は、ポインターに展開されると値0xFFFFFFFFが0xFFFFFFFFFFFFFFFFFFに変わると信じています。 そうではありません。 C / C ++の規則によると、値0xFFFFFFFFは「unsigned int」型です。これは、「int」型では表現できないためです。 したがって、64ビットタイプに拡張すると、値0xFFFFFFFFFFuは0x00000000FFFFFFFFFFuになります。 しかし、このように(size_t)(-1)のように書くと、予想される0xFFFFFFFFFFFFFFFFが得られます。 ここで、「int」は最初に「ptrdiff_t」に展開され、次に「size_t」に変換されます。
例11.サイズを示すマジック定数
もう1つのよくある間違いは、マジックナンバーを使用してオブジェクトのサイズを設定することです。 バッファの割り当てとゼロ化の例を考えてみましょう。
size_tカウント= 500; size_t *値=新しいsize_t [count]; //バッファの一部のみが埋められます memset(値、0、カウント* 4);
この場合、64ビットシステムでは、ゼロ値で満たされるよりも多くのメモリが割り当てられます(図11を参照)。 エラーは、size_tのサイズが常に4バイトであると想定することです。

図11-配列の一部のみを埋める
正しいオプション:
size_tカウント= 500; size_t *値=新しいsize_t [count]; memset(値、0、カウント* sizeof(値[0]));
割り当てられたメモリまたはデータのシリアル化のサイズを計算するときに、同様のエラーが発生する可能性があります。
例12.スタックオーバーフロー
多くの場合、64ビットプログラムはより多くのメモリとスタックを消費します。 ヒープ上により多くのメモリを割り当てることは危険ではありません。このタイプのメモリは64ビットプログラムで32ビットよりも何倍も利用できるためです。 ただし、使用されるスタックメモリを増やすと、予期しないオーバーフロー(スタックオーバーフロー)が発生する可能性があります。
スタックを使用するメカニズムは、オペレーティングシステムとコンパイラによって異なります。 Visual C ++コンパイラーによってビルドされたアプリケーションのWin64コードでスタックを使用することの特殊性を検討します。
Win64システムで呼び出し規約を開発する際、関数を呼び出すためのさまざまなオプションの存在に終止符を打つことにしました。 Win32には、stdcall、cdecl、fastcall、thiscallなどの多くの呼び出し規則がありました。 Win64では、「ネイティブ」呼び出し規約は1つだけです。 __cdeclコンパイラーなどの修飾子は無視されます。
x86-64呼び出し規約は、x86のfastcall規約に似ています。 x64規則では、最初の4つの整数引数(左から右へ)は、この目的のために特別に選択された64ビットレジスタで渡されます。
RCX:最初の整数引数
RDX:2番目の整数引数
R8:3番目の整数引数
R9:4番目の整数引数
残りの整数引数はスタックを介して渡されます。 thisポインターは整数引数と見なされるため、常にRCXレジスターに配置されます。 浮動小数点値が渡されると、最初の4つの値がXMM0〜XMM3レジスタで送信され、後続の値がスタックを介して送信されます。
引数をレジスターに渡すことはできますが、コンパイラーはスタック上の引数用にスペースを予約し、RSPレジスター(スタックポインター)の値を減らします。 少なくとも、各関数はスタック上に32バイトを予約する必要があります(RCX、RDX、R8、R9レジスタに対応する4つの64ビット値)。 スタック上のこのスペースにより、スタック上の関数に渡されるレジスタの内容を簡単に保存できます。 呼び出される関数は、レジスタを介してスタックに渡された入力パラメーターをダンプする必要はありませんが、必要に応じて、スタック上の場所を予約することでこれが可能になります。 4つを超える整数パラメーターが渡された場合、対応する追加スペースがスタック上に予約されます。
説明された特徴は、スタックの吸収速度の実質的な増加をもたらす。 関数にパラメータがない場合でも、32バイトはスタックから「噛み付いた」ままになり、その後は使用されません。 このような不経済なメカニズムを使用する意味は、デバッグの統合と簡素化に関連しています。
もう1つの瞬間に注目しましょう。 RSPスタックポインターは、次の関数呼び出しの前に16バイト境界で整列する必要があります。 したがって、64ビットコードでパラメーターなしで関数を呼び出すときに使用されるスタックの合計サイズは48バイトです: 8(戻りアドレス)+ 8(アライメント)+ 32(引数用に予約)。
本当にそんなに悪いの? いや 64ビットコンパイラで使用できるレジスタの数が多いため、より効率的なコードを構築でき、一部のローカル関数変数用にスタック上のメモリを予約しないことを忘れないでください。 したがって、場合によっては、64ビットバージョンの関数は32ビットバージョンよりも少ないスタックを使用します。 この問題とさまざまな例については、記事「 64ビットプログラムがより多くのスタックメモリを必要とする理由 」で詳しく説明されています 。
64ビットプログラムが1スタック以上を消費するかどうかを予測することは不可能です。 Win64プログラムは2〜3倍のスタックメモリを使用できるため、安全に再生し、プロジェクト設定を変更する必要があります。プロジェクト設定は予約済みスタックのサイズに影響します。 プロジェクト設定でパラメーターStack Reserve Size(key / STACK:reserve)を選択し、予約済みスタックのサイズを3倍にします。 デフォルトでは、このサイズは1メガバイトです。
例13.可変数の引数とバッファーオーバーフローを持つ関数
printfなどの可変数の引数を持つ関数を使用する場合、scanfはC ++では不適切なスタイルと見なされますが、依然として広く使用されています。 これらの関数は、64ビットシステムを含む他のシステムにアプリケーションを転送するときに多くの問題を引き起こします。 例を考えてみましょう:
int x; char buf [9];
sprintf(buf、 "%p"、&x);
コードの作成者は、将来のポインターのサイズが32ビットを超える可能性があることを考慮していません。 その結果、64ビットアーキテクチャでは、このコードによりバッファオーバーフローが発生します(図12を参照)。 このエラーは、マジックナンバー「9」の使用に起因する可能性がありますが、実際のアプリケーションでは、マジックナンバーなしでバッファオーバーフローが発生する可能性があります。

図12-sprintf関数を使用する場合のバッファーオーバーフロー
このコードを修正するためのオプションは異なります。 最も効率的な方法は、危険な関数の使用を取り除くためにコードをリファクタリングすることです。 たとえば、printfをcoutに、sprintfをboost :: formatまたはstd :: stringstreamに置き換えることができます。
ご注意 Linux開発者はしばしばこの推奨事項を批判し、gccは、たとえばprintf関数に渡される実際のパラメーターとフォーマット文字列が一致することをチェックすると主張します。 したがって、printfの使用は安全です。 ただし、リソースからロードされたプログラムの別の部分からフォーマット文字列を転送できることを忘れています。 つまり、実際のプログラムでは、フォーマット文字列がコード内に明示的に存在することはめったにないため、コンパイラはそれをチェックできません。 開発者がVisual Studio 2005/2008/2010を使用する場合、次の形式のコードに関する警告を受け取ることはできません。void * p = 0; printf( "%x"、p); / W4および/ Wallキーを使用しても。
例14.可変数の引数と無効な形式を持つ関数
多くの場合、printf関数やその他の同様の関数を使用すると、プログラムで誤った書式設定文字列が見つかる場合があります。 このため、不正な値が表示されます。これは、プログラムの異常終了にはつながりませんが、もちろんエラーです。
const char * invalidFormat = "%u"; size_t値= SIZE_MAX; //間違った値が出力されます printf(invalidFormat、値);
その他の場合、フォーマット文字列のエラーが重要になります。 プログラムの1つでのUNDO / REDOサブシステムの実装に基づく例を考えてみましょう。
//ここで、ポインタは文字列として保存されました
int * p1、* p2;
....
char str [128];
sprintf(str、 "%X%X"、p1、p2);
//別の関数では、この行
//次のように処理されます:
void foo(char * str)
{
int * p1、* p2;
sscanf(str、 "%X%X"、&p1、&p2);
//結果-ポインターp1およびp2の値が正しくありません。
...
}
"%X"という形式は、ポインターを操作するためのものではないため、そのようなコードは64ビットシステムの観点からは正しくありません。 32ビットシステムでは、美しくはありませんが、非常に機能的です。
例15. doubleでの整数値の保存
私たちは自分でそのような間違いに遭遇する必要はありませんでした。 おそらく、この間違いはまれですが、非常に現実的です。
double型で、サイズは64ビットで、32ビットおよび64ビットシステムのIEEE-754標準と互換性があります。 一部のプログラマは、double型を使用して整数型を格納および操作します。
size_t a = size_t(-1);
double b = a;
--a;
--b;
size_t c = b; // x86:a == c
// x64:a!= c
double型には52ビットの有効ビットがあり、32ビット整数値を損失なく格納できるため、32ビットシステムでこの例を正当化することを試みることができます。 しかし、64ビット整数をdoubleに保存しようとすると、正確な値が失われる可能性があります(図13を参照)。

図13-size_t型とdouble型の有効ビット数
記事の2番目の部分。