以下はプログラムのソースであり、テキスト内の単語の総数と平均単語長を考慮しています。 プログラムはperlで書かれています。
use strict;
use locale;
use POSIX qw (locale_h);
setlocale(LC_CTYPE, 'ru_RU.CP1251');
setlocale(LC_ALL, 'ru_RU.CP1251');
open (TEXT, "<text.txt");
undef $/;
my $text = <TEXT>;
close(TEXT);
my @words = $text =~ m/[-]+/ig;
open(OUT, ">out.txt");
my ($count, $sum);
foreach(@words){
$count++;
$sum += length($_);
}
print OUT " : $count\n : ".($sum/$count);
close(OUT);
私が使用したほとんどすべてのテキストはモシュコフ図書館から取られました。 それは私が得たものです。
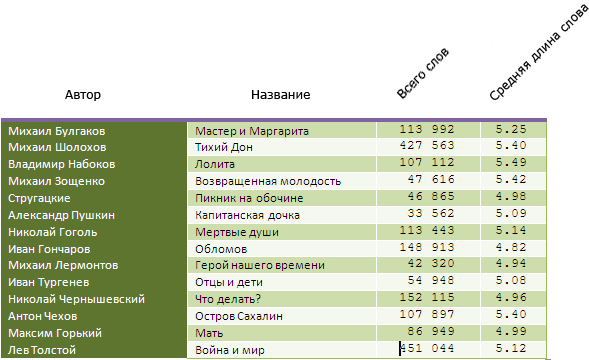
結論は、著者ごとに平均単語長がどれだけ異なるかは自分で調整します。