シングルスレッドJavaアプリケーションのデバッグは簡単です。 マルチスレッドJavaアプリケーションのデバッグはもう少し複雑ですが、それでも簡単です。 マルチプロセスJavaアプリケーションをデバッグしますか? プロセスが異なるマシンで実行されていますか? これは間違いなく難しいです。 すべてのHadoopマニュアルでは、他のオプション(読み取り:ロギング)が使い果たされて助けにならなかった場合にのみ、デバッグを推奨しています。 大規模なクラスターでは、特定のマップ/削減ノードにアクセスできない可能性があるため、状況はしばしば複雑になります(このオプションに出くわしました)。 しかし、パーツの問題を解決しましょう。 だから...
シナリオ1:ローカルHadoop
すべての最も簡単なオプション。 Hadoopのローカルインストール-すべてが同じマシン上で実行され、さらに同じプロセスで異なるスレッドで実行されます。 デバッグは、通常のマルチスレッドJavaアプリケーションのデバッグと同等です-もっと簡単なことは何ですか?
これを達成する方法は? ローカルのHadoopを展開したディレクトリに移動します(これを実行できるか、適切な指示を読んで今すぐ処理できると思います)。
$ cd〜/ dev / hadoop
$ cp bin / hadoop bin / hdebug
$ vim bin / hdebug
私たちのタスクは、スクリプトが
$HADOOP_OPTS
生成を完了した直後に、別のJVMオプションを追加します(バージョンによって異なりますが、バージョンによって異なります)。
HADOOP_OPTS = "$ HADOOP_OPTS -Xdebug -Xrunjdwp:transport = dt_socket、address = 1044、server = y、suspend = y"
この呪文で何と言いましたか? ポート1044に接続する必要があるリモートデバッガーのサポートを使用してJavaマシンを起動し、接続するまで(開始後すぐに)プログラムが中断されると言いました。 簡単ですね。 Eclipse(または他のJava IDE)に移動して、そこにリモートデバッグセッションを追加します。 さて、例えば、このように:
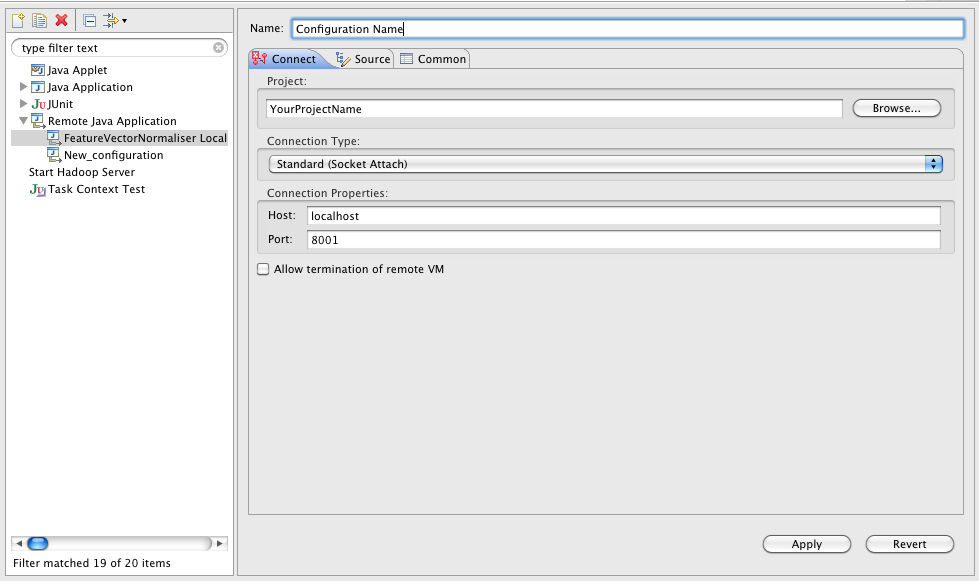
ローカルマシンではなく一部のサーバーでデバッグを実行する場合(これは非常に普通であり、通常これを行います-多くのメモリと多くのプロセッサを備えた特別な開発サーバーがある場合、ラップトップにそのようなものをロードする必要がありますか? )、
localhost
を必要なホストに変更します。 次に、プログラムコードにブレークポイントを入れて(スターター用、本体、いわゆるゲートウェイコード)、Hadoopを開始します。
bin / hadoop jar myApplication.jar com.company.project.Application param1 param2 param3
Khadupは起動し、何もしません。JVMは接続を待機していると報告します。
アドレス1044でトランスポートdt_socketをリッスンしています
これで、Eclipseをデバッグセッションに接続し、ブレークポイントが「ポップアップ」するまで待ちます。 map / reduceクラスのデバッグは、ゲートウェイコードのデバッグと同じです(このシナリオの場合)。
シナリオ2:疑似分散モード
擬似分散モードでは、Hadoopは本番環境で動作する状態に近くなります(したがって、何かが壊れたときに頭痛になります)。 違いは、map / reduceタスクが個別のプロセスで実行され、HDFSが既に「実際」であり(ローカルファイルシステムによってシミュレートされていない-1つのノードにのみ存在する)、デバッグがより難しいことです。 つまり、もちろん、上記のアプローチを新しいプロセスの開始に適用できますが、私はこれをしようとしませんでした。Hadoop自体のコードを変更しないと、単に機能しないという疑いがあります。
このモードでデバッグタスクを解決するには、主に2つのアプローチがあります。1つはローカルタスクトラッカーを使用する方法で、もう1つは
IsolationRunner
です。 ノードが異なり、すべてのコードが1つのプロセスで実行されるため(前のバージョンと同様)、最初のオプションでは非常に近似した結果しか得られないことをすぐに言う必要があります。 2番目のオプションは実際の作業を非常に正確に近似しますが、特定のタスクノードにアクセスできない場合は不可能です(大規模な運用クラスターの場合は非常に可能性が高い)。
したがって、 IsolationRunnerは、特定のタスク(タスク)の実行プロセスを実際に最も正確にシミュレートし、実際に実行を繰り返すことができるヘルパークラスです。 それを使用するには、いくつかのジェスチャーを行う必要があります。
- ジョブ構成で
keep.failed.tasks.files
をtrue
に設定します。 タスクの定式化に応じて、XMLファイルまたはプログラムテキストを編集することでこれを行うことができますが、いずれにしても、難しくはありません。 これにより、タスクがエラーで完了した場合、その構成とデータを削除する必要がないことをタスクトラッカーに指示します。 - さらに、公式ガイドでは、エラーが発生してタスクが完了したノードに移動することを推奨しています。 私たちの場合、それはまだローカル(または非常にローカルではないが、それでも唯一のホスト)です。 taskTrackerが配置されているディレクトリは設定によって異なりますが、「デフォルト」モードでは、ほとんどの場合
hadoop/bin
ます。 マニュアルから例をそのままコピーします。
$ cd <ローカルパス> / taskTracker / $ {taskid} / work $ bin / hadoop org.apache.hadoop.mapred.IsolationRunner ../job.xml
この場合、bin/hdebug
を上記で作成したbin/hdebug
ことができます(相対パスが何らかの形で異なることは明らかです;-))。 その結果、倒れたタスクをデバッグし、倒れたデータを正確に処理します。 シンプルで美しい、快適。 - デバッガーで接続し、行動し、エラーを見つけ、喜ぶ
前述したように、このメソッドは擬似分散モードでの動作が保証されますが、map / reduceノードにアクセスできる場合も正常に動作します(これはほぼ理想的な状況です)。 しかし、3番目のシナリオ、最も難しいシナリオもあります...
シナリオ3:実稼働クラスター
あなたは実際の「戦闘」クラスター上にいて、そこには1000台の車があり、そのために特別に設計されたゲートウェイを除いて、誰もあなたにそれらの1つにログインする権利を与えることはありません-ゲートウェイマシン) すべてが大人の方法で、あなたはまだ半テラバイトのテスト「小さな」データセットに取り組んでいますが、デバッグに伴う頭痛の種はすでに最大の高さまで上がっています。 ここでは、おそらく、ロギングに関するアドバイスを繰り返すのが適切でしょう。まだ実行していない場合は、実行してください。 これにより、少なくとも問題を部分的に特定することができます。おそらく、上記の2つの方法のいずれかを使用して、問題を特定して解決できるでしょう。 予測可能な結果を提供する簡単なデバッグ方法はありません。 厳密に言えば、できることは、ゲートウェイ上でローカルにタスクを実行することだけです。この場合、実際の本番HDFSで作業しますが、特定のノードで動作を正確に再現することはできません。
ローカルでタスクを実行するために必要なことは、
mapred.job.tracker
を
local
設定すること
mapred.job.tracker
(タスク構成で)。 幸運にも、デバッガー(おそらく、お気に入りのEclipseではなく、同じネットワークで実行されているコンソールを使用するか、SSHトンネルを使用できる場合)に接続して、ゲートウェイでコードを実行できます。 長所から-実際のHDFSで実際のデータを操作します。 マイナスの点-エラーが浮遊して再現する場合、神は禁止します。クラスターの1つまたは2つのノードでのみ、2つの行で見つけることができます。 一番下の行は、クラスターサポートチームと話をせずに、特定のノードへの一時的なアクセスを要求せずに達成できる最善の方法です。
おわりに
そのため、マップのデバッグ/アプリケーションの削減がどれほど難しいかを考えるための情報を以下に示します。 上記のすべてを否定することなく、次の戦略をお勧めします。
- タスクコード全体にデバッグメッセージを配置します-最初はめったに(おおよそ)まれではなく、タスクが100行から350行の間に収まることが明らかになった場合はより頻繁に
- 地元のHadoupで問題を再現してみてください。非常に頻繁に成功し、問題を把握できます
- 特定のマップ/ノードの削減にアクセスできるかどうかを確認してください。 それを受け取ることが現実的であるかどうかを確認します(少なくとも一時的であり、すべてではありません)
- 注視デバッグを使用してください! 真剣に、これは機能します-見た目があなたのものでない場合にのみより良いです:多くの場合、部外者は3秒でバグを見ることができます。
- 他のすべてが失敗した場合、上記の手法の異なる組み合わせを使用します。 少なくとも1つは必ず機能します。
良いデバッグ!
PSは、私の古い投稿と、それをサポートするhadoop-application、Java-library、およびJNIの毎週のデバッグに基づいて書かれています。 さらに、RTの第179号とmap / reduceの話でUmputunとBobukへの挨拶は、私が理解し、それらについて話すことができる(多くはありませんが)ものがあることを思い出させました;-)