ストレステストを実行して、これらの問題を回避してみませんか?
おそらく、ストレステストは特別な知識を必要とする非常に複雑な問題であるという誤解によって誰かが止められます。 しかし、神が鍋を燃やすわけではありません。 専門的にテストしすぎることを選択しない場合、またはまったくテストしない場合は、最初に選択します。 さらに、基本的なパフォーマンステストの構成は非常に簡単です。 オンラインツールを使用する(たとえば、 負荷テストをすばやく参照する )か、すべてを自分の手でかき混ぜることができます。これはそれほど複雑ではありません。
ネコの下で、 Apache JMeterを使用して、サイトの単純な負荷テストをゼロから整理する方法を説明しています。
説明したアプローチ(Log Replay)は特にサイトでうまく機能し、POSTをアクティブに使用するWebアプリケーションには適していないこと、またその単純さでCookieベースのセッションの存在を無視することをすぐに警告します。 さらに、127.0.0.1でデプロイされたプロジェクトをテストすることは望ましくありません。JMeterとサイトの速度が低下するため、結果はかなりゆがめられます(一方で、サーバーが遠い場合は悪いです-遅延が干渉します)。
必要なもの:
- Jmeter
- マウントされたヒキガエル 、今日ではほとんどすべての車で発見されています
- 当サイトのアクセスログ 。 アクセスログが空の場合、ブラウザを拾い上げてサイトを登るのを少しでも妨げることはありません。 HTTrackやXenuなどのクローラーを使用してサイトを通過できます。 WebサーバーがIISの場合、最初にログ形式をNCSAに切り替える必要があります。これは、JMeterパーサーが認識します。 実行中のサーバーの下でログを取得する価値はありません(彼がそこに書いているとき)、すでに昨日など、既に閉じられているサーバーを取得するか、ログ抽出中はWebサーバーを一時停止することをお勧めします。 ログは、正しいかどうかをテキストエディタで確認する必要があります。
JMeterの場合、サーバーのファイルシステムにアクセスすることなく、ログとして渡すファイルを生成する方法はまだあります。 どこかからサイトURLのリストを取得します。 受け入れ可能なリストは、スキャンレポートでXenuによって作成されます。 このリストをテキストファイルに貼り付けます。 それは次のようなものになります
http://test.local/index.php
http://test.local/news/event-12.php
...
「http://test.local」のグローバルリプレイを「」GET」(引用符とスペース付き)にすると、
"GET /index.php
"GET /news/event-12.php
...
パーサーはこのフォーマットを適切に使用し、額面どおりに受け取ります(行の終わりで引用符を閉じないでください)。
そこで、JMeterをダウンロードしました( http://jakarta.apache.org/site/downloads/downloads_jmeter.cgi 、アーカイブを展開し、 binディレクトリに移動してjmeter.batを実行します (Windowsでサンプルを作成します)。しばらくすると、伝統的なヒキガエルのようなGUIが起動します。
左側には、 TestPlanとWorkbenchの 2つのノードのツリーがあります(2 番目のノードはすぐに忘れてしまいますが、必要ありません)。 テスト計画を右クリックして、「 追加」->「スレッドグループ」と言います(インターフェイスでは、さまざまな有用性のチップが多数表示されますが、気が散ることはありませんが、最短ルートでテストに進みます。必要に応じて、JMeterの広範な機能を詳細に調べます) 。

追加されたスレッドグループ:
ここではまだ何も変更しません。 数字はすべて1で、これは良いことです。 これは、スクリプトを1回実行する1人の仮想ユーザーです(使用するアクセスログサンプラーの場合、ログの最初の行に対応する1つの要求を実行します)。 そして、テストをデバッグするためにこれ以上必要はありません。
テスト計画とスレッドグループの名前も変更しません。これらの名前はテスト内で一意です。
スレッドグループを右クリックして、 アクセスログサンプラーを追加します ( スレッドグループ- >追加->サンプラー->アクセスログサンプラー)

サーバーアドレスとアクセスログへのローカルパスを入力します(サーバーからドラッグして、ディスクに保存します)。
次に、テストに表示ツールを追加します。
- スレッドグループ->追加->リスナー->結果を表に表示
- スレッドグループ->追加->リスナー->グラフ結果
- スレッドグループ->追加->リスナー->集計レポート
テスト計画の準備ができたので、テストに進みます:)そしてデバッグ(何も、何も、初めて稼ぐことはできません)。
File-> Saveのように、テスト計画に変更を加えるたびに。 これは重要であり、JMeterは別の時間にハングし、メモリからテストを復元する必要があります。
実行->すべてクリア (初めて実行することはできませんが、それでも必要です)。
実行->開始
そして、表の結果の表示を見に行きましょう。 運が良ければ、1行で、[ステータス]列に緑色のチェックマークが付きます。

何かがうまくいかなかった場合、ステータスにエラーがあります:

この場合は、TestPlan.logをご覧ください。 原則として、そのレポートによると、何が正確に壊れたのかを推測できます。 たとえば、テスト対象のサーバーが応答しない場合、次の呪いがログに表示されます:
rc="Non HTTP response code: java.net.ConnectException" rm="Non HTTP response message: Connection refused: connect"
このようなテキスト
rc="Non HTTP response code: java.net.ProtocolException" rm="Non HTTP response message: Invalid HTTP method: null"
は、アクセスログ行が正しく解析されなかったことを示している可能性があります。
私たちがそれを理解したか、すべてがすぐにきれいになったと仮定します。 スレッドグループのプロパティに移動し、 ループカウントを設定します:永遠に

開始します(ファイル->保存、実行->すべてクリア、実行->開始)。 Tableの結果の表示を見てみましょう。 次のようになります。

エラーの最後の行は、ファイルが終了したためにJMeterが動揺していることです(明らかに、エンドレスファイルの操作に慣れています)。 残念ながら、ファイルの最後でスクリプトが停止し、 Samplerエラー = Continue設定後に実行されるアクションを無視します(これは私にはバグのようで、開発者にはおそらく機能があります)。 これによりテスト結果が歪まないように、かなり長いアクセスログを取得することをお勧めします。 長いファイルは、コマンドラインでコピーするか、テキストエディターでCtrl + C、Ctrl + Vを使用して、短いファイルから簡単に整理できます。 私たちの実験では、ログに1000行を超える行が必要になることはほとんどありません。
テストを開始する前に、スクリプトの開始時に0〜1000ミリ秒のランダムな遅延( Uniform Random Timer )を追加しましょう。通常、グラフを少し滑らかにするのに役立ちます。 結果としてのスクリプトは次のように機能します。ランダムなミリ秒数の間待機し、ログから行を読み取り、HTTP要求を作成し、結果をリスナーに渡し、再び待機し、次の行を読み取ります。
最初の目撃テストを行います。 スレッドグループのプロパティに次のように入力します: スレッド数(ユーザー): 100、 ランプアップ期間(秒) :100。100人の仮想ユーザーをサイトに設定し、100人ずつ、つまりユーザーごとに1つずつ戦闘に導入します。毎秒。 天井のどこかから100と100の数字を取りましたが、どこかから始める必要があります。
繰り返しになりますが、サイトを遅くしたり、埋め尽くしたりする可能性が十分にあることを思い出してください(すでに動作しているプロジェクトについて話している場合は悪いかもしれません)。 OK、私たちの正しい心と地味な記憶にあり、私たちの行動に対する責任を認識して、私たちは始めます。
ファイル->保存、実行->すべてクリア、実行->開始 、そしてグラフ結果を見る。 たとえば、次のような写真が表示されます。
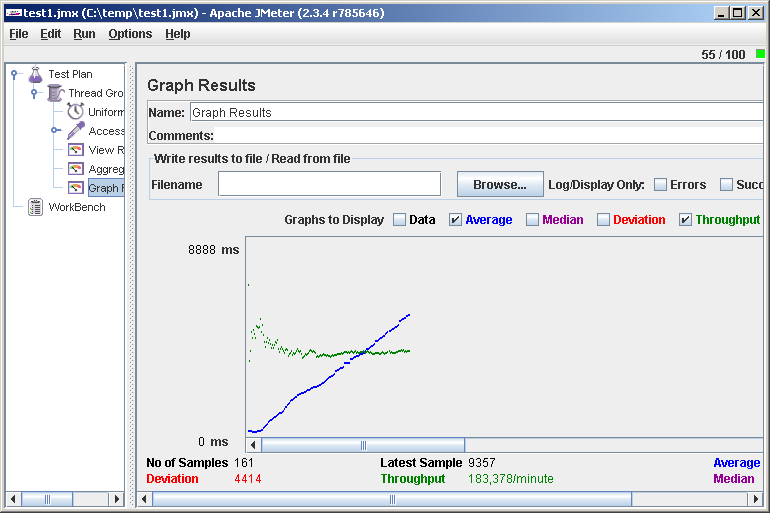
右上隅に、仮想ユーザーの現在の数が表示されます。
このチャートは何を教えてくれますか? 平均応答時間( Average )は増加しており、処理速度( Throughput )は変わりません。 これは、サーバーのどこかで操作がキューに入れられ、すべての要求を処理するのに十分なパフォーマンスがないことを意味します。 ブラウザでサイトを訪問した後、私たちはそれがかろうじて投げたり向きを変えたり、まったく反応しないと確信します。 なぜ不幸な人を無駄に拷問するのですか? 実行->停止 さて、サイトは再び活気づきました。 そのようなテスト中の悪い考えは、しばらく気を散らし、数時間後に(実際に)戻って、サイトが半日横になっていることを見つけることです。
意味のある結果として、最大スループット値(1分あたり183リクエスト)という1つの数値が得られました。 パフォーマンスの制限と考えることができます。 この数値を開始するには、たとえば、1日あたり100,000ホストがサイトをプルしないことは既に明らかです。
応答時間のグラフを注意深く見ると、最初に棚が見えます。 この時点で、負荷は増大していましたが、サーバーの反応は変わりませんでした。つまり、彼は大丈夫でした。 この負荷範囲をさらに詳しく調べてみましょう。 スレッド数を減らし、 ランプアップ期間を増やすことにより、次の図が得られます。

1分あたり3人の仮想ユーザーと150のリクエストの後、サイトが病気になったことがわかります。
確かに、今では静的負荷でテストを行うのが理にかなっています。 スレッド数 = 3、 ランプアップ期間 = 0(すぐにスレッドを入力)を設定し、何が起こったかを確認します。 すべてがうまくいっているようで、サイトは鮮やかに反応します。 必要に応じて、そのようなポイントをいくつか削除し、紙の上にグラフを作成します。 これらの数値は、動的負荷を伴うグラフでの観測よりもはるかに信頼性があります。
それでは、 集計レポートを見てみましょう。 そこで、URLに関する統計を準備しました。
(テスト後は、静的負荷が大きすぎても過度ではないことを確認することをお勧めします)。 主に関心があるのは、平均、平均応答時間の列です。 多くの場合、最初にシステムに負荷をかける重いページがいくつかあることが判明し、それらを調整すると、全体的なパフォーマンスが何度も向上します(統計によって頻繁に呼び出され、長時間動作するページから最適化を開始することをお勧めします)。 公平を期すために、最長再生ページが常に負荷に最大の貢献をするわけではないことに注意する必要がありますが、より頻繁にそうなります。
受け取った数字の解釈に関するいくつかの言葉:仮想ユーザー3人、1分あたり150リクエスト。 これらの値は、実際のユーザー、たとえば1日あたりのページリクエストとどのように関連していますか? 実質的には何もせず、実際のユーザーをシミュレートするという目標を設定しませんでした。 私たちが持っているのは、チューニングの過程で導くことができる相対的な値です。 この場合、テスト中にサイトのURLリストに従って3人のユーザーが取得され、「ログ」には写真、CSS、およびその他のリソースが含まれていません。 したがって、1分あたり150は、実際の1分あたりのページリクエストと一致します。 実際のログを使用した場合は、 集計レポートを取得してcsvにエクスポートし(下部に[ テーブルデータの保存 ]ボタンがあります )、そこからリソースへのすべてのアクセスを破棄し、残りのヒットを計算し、テスト期間で割ることができます。
結論として、説明した方法の1つの欠点について警告したいと思います。 すべての仮想ユーザーが同じ順序でクエリを実行するため、すべてのレベルでのキャッシュ効率が非常に高くなります。 実際には、効率は低くなり、これにより、研究結果にほとんど推定誤差が生じません(ちなみに、手が届く場合、ログから行をランダムな順序で引き出すサンプラーを記述する必要があります)。
しかし、その後、そのようなテストは迅速かつ簡単に実行され、良好なパフォーマンスを発揮します。