文の解析 (英語の解析 )のような概念から始めましょう。 このプロセスの本質は、「何らかの形で」提案の構造を反映するグラフを作成することです。
「どんな形であれ」と言うのは、今日、グラフが構築される原則の単一の受け入れられたシステムがないからです。 1つの概念の枠組み内であっても、単語間の関係に関する個々の科学者の見解は異なる場合があります(これは、前のセクションで説明した形態現象の解釈の不一致に似ています)。
おそらく、まず第一に、依存関係のグラフ(通常はツリー)を構築する方法をフレーズ構造ベースの解析と依存関係解析に分割する必要があります。
最初の学校の代表者は文を「構成要素」に分割し、次に各構成要素をその構成要素に分割します-そして、単語に到達するまで続きます。 この考えは、ウィキペディアの写真によく示されています。
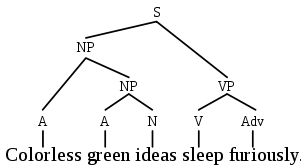
2番目の学校の代表者は、相互に依存する単語を、補助ノードなしで直接相互に接続します。
私の同情は2番目のアプローチ(依存関係解析)の側にあるとすぐに言わなければなりませんが、どちらもより詳細な議論に値します。
チョムスキー学校
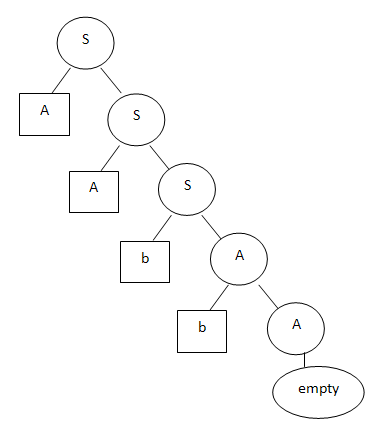
「コンポーネント」の分析は、明らかにチョムスキーの文法から生まれました。 誰も知らない場合、チョムスキーの文法は言語文を記述するルールを定義する方法です。 この文法を使用すると、フレーズを生成して分析することができます。 たとえば、次の文法は、任意の数の文字aと、それに続く任意の数の文字bで構成される「言語」を説明しています。S -> aS | bA | 'empty'
A -> bA | 'empty'
文字Sから始めて、フォームa ... ab ... bの任意の行を生成できます。 このような文法を解析するための汎用アルゴリズムもあります。 入力文字列と一連の文法規則を彼に渡すことで、答えを得ることができます-文字列が与えられた言語内の有効な文字列であるかどうか。 また、文字列が最初の文字Sから派生する方法を示す解析ツリーを取得することもできます。
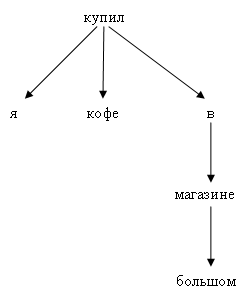
次のツリーがaabb行に対応するとします。
この方法の明らかな利点は、チョムスキーの文法が古くから知られている形式主義であることです。 長く開発された解析アルゴリズムがあります;文法の「形式的特性」は知られています。 表現力、処理の複雑さなど。 さらに、チョムスキーの文法はプログラミング言語のコンパイルに使用されています。
チョムスキー自身は主に言語学者であり、彼はまず自然言語である英語で仕事を試みました。 したがって、英語のコンピューター言語学では、彼の作品の影響は非常に大きいです。 チョムスキーの形式主義は「対面」ですが、私が知る限り、自然言語処理では使用されていません(このために十分に開発されていません)、彼の学校の精神は生き続けています。
このようなツリーを構築するパーサーの良い例は、 スタンフォードパーサーです (オンラインデモがあります)。
単語関係モデル
一般に、このアプローチを特に新鮮と呼ぶことは困難です。 誰もが、50年代のLucien Tesniereの作品を情報源として言及しています。 言及は以前の考えで行われます(ただし、「アイデアの世界」、つまり抽象クラスの概念を作り出したため、PLOプラトンの父と呼ばれるものと同じオペラから)。 ただし、コンピューター言語学では、チョムスキーの文法が積極的に使用されている間に、依存関係の解析が長い間バックグラウンドで行われていました。 おそらく、チョムスキーのアプローチの制限は、言語に(英語よりも)より自由な語順を与えているため、依存関係解析の分野で最も興味深い作業は、依然として英語圏の「外」で行われています。
依存関係解析の主なアイデアは、依存する単語を相互接続することです。 ほとんどすべてのフレーズの中心は動詞です(明示的または暗示的)。 さらに、動詞(アクション)から質問をすることができます:誰が何をするのか、どこでするのかなど。 添付されたエンティティについては、質問をすることもできます(まず、質問「何」)。 たとえば、上の「大きな店でコーヒーを買った」というツリーでは、この一連の質問を再現できます。 ルート-購入(フレーズアクション)。 誰が買ったの? -I.何を買ったの? -コーヒー。 どこで買いましたか? -店内。 どの店で? -大きなもので。
ここでも、多くの技術的な微妙さとあいまいさがあります。 動詞の欠如は別の方法で扱うことができます。 通常、「to be」という動詞は、「I [am] a student。」という意味です。 述語文では、状況はより複雑です。路上では湿っています。 路上で湿っているとは言えません:)何が何をどのように解釈するかにかかっているかは必ずしも明確ではありません。 たとえば、「今日は仕事に行きません。」 「not」パーティクルは他の単語とどのように関係していますか? オプションとして、ここでは動詞「non-action」が使用されていると想定できます:「私は行かない」(ロシア語ではないが、意味がある)。 ユニオンで結合された同種のメンバーをどのようにスカルプトするかは完全には明らかではありません。 「コーヒーとパンを買った。」 たとえば、「and」という単語を「bought」にスカルプトし、「coffee」と「bun」を「and」に添付できます。 しかし、他のアプローチもあります。 「私は仕事に行きます」という特定の結束を形成する言葉の相互作用から、かなり繊細な瞬間が生じます。 「歩く」が本質的に未来時制の唯一の動詞(つまり、行動)であり、2つの単語で作成されただけであることは明らかです。
このようなアナライザーの動作を確認したい場合は、 ConnexorのWebサイトをお勧めします 。
なぜ依存解析は魅力的ですか? さまざまな引数を与えます。 たとえば、単語を相互に結合しても、追加のエンティティは作成されないため、さらなる分析が簡単になると言われています。 結局、解析はテキスト処理の次のステップに過ぎず、結果のツリーをどう処理するかを想像する必要があります。 ある意味で、依存関係ツリーは、文の要素間の明示的なセマンティックな関係を示すため、「よりクリーン」です。 さらに、依存性解析は、自由な語順を持つ言語により適しているとしばしば主張されます。 チョムスキーでは、すべての従属ブロックがどういうわけか互いに隣り合っていることが判明しました。 ここでは、理論的には、文の異なる端にある単語を結び付けることができます(技術的にはここではそれほど単純ではありませんが、後で詳しく説明します)。 原則として、これらの議論は私がテニエのキャンプに参加するのに十分です:)
結果のツリーが近接しているという正式な証拠があると言わなければなりません。 どこかで、ある種の木を別の種類の木に、またはその逆に変換できるという定理が外れました。 しかし、実際にはこれは機能しません。 少なくとも私の記憶では、スタンフォードパーサーの出力を変換して依存関係ツリーを取得しようとした人はいませんでした。 どうやら、すべてがそれほど単純ではなく、エラーが増えます...最初にスタンフォードパーサーが間違いを犯し、次に変換アルゴリズムが間違いを犯します...そして最終的に何が起こるのでしょうか? エラー時のエラー。
(UPD:前述のスタンフォードの人たちは、パーサーの出力を依存関係構造に変換する方法をまだテストしました 。しかし、この変換では射影木だけが議論されていることに注意する必要があります。
おそらく今日はこれで十分でしょう。 次の部分に進みます。