以下は、GAEおよび受信負荷に関するグラフの2番目の部分で統計を操作する機能の説明です:自分自身とgoogleによって生成されたもの。 私は、GAEにまったく遭遇しなかった人々にとって理解しやすい方法で書き込もうとしました。
パート1:統計
もちろん、GAEは独自のグラフを表示しますが、いくつかの質問があります。
- しばらくするとそれらを見ることができなくなり、スケジュールは最終日のみ利用可能になります。
- データ表示は固定されており、カスタマイズできません。
- その条件のいずれかのスケジュールを作成する方法はありません。bullshitbingoの場合、異なるゲームを個別に見るのは面白いでしょう。
問題: GAEは基本的に1000を超えるレコードを返すことができません 。 これは非リレーショナルデータモデルによるものであり、おそらくこれはだれにもわずらわしくないかもしれませんが、統計を強く妨害します。 別の考慮事項:いくつかの複雑なクエリを構築し、GAE側で何かを直接計算することは非常に高価になる可能性があるため、プロセッサ時間と大量のデータの保存に費用がかかります。 統計は、一般に、機能するために必要ではない「死んだ」データであるため、GAEサーバーから自分のどこかにそれを取得し、すでに処理することはかなり可能です。 さらに便利です。 そのため、統計をcsvファイルの形式でアップロードし、ローカルで既に何らかの方法で作業することが決定されました。
データのアップロード
GAEはオフセットのあるレコードを選択する方法を知らないため、データのアップロードは別のタスクです。 むしろ、可能ですが、実際にはクライアント側で実装されます(もちろん、httpクライアントではなく、アプリケーション)。 つまり、100番目から10個のレコードを取得したい場合、それを行うことができます。これには、fetch()呼び出しに対応するパラメーターもありますが、実際には110個のレコードすべてがデータベースから抽出され、最初の100個のAPIだけが残ります。 つまり、1000番目から100個のレコードを取得することは不可能です。 これはドキュメントにも書かれていますが、どういうわけか霧がかかっています。
リレーショナルデータベースで使用していたように、オフセットとして行番号ではなく、日付/時刻を使用すると、状況から抜け出すことができます。 GAEの時間は小数点以下6桁まで保存されるため、まったく同じ時間で複数のエントリを作成する確率は非常に小さくなります。 厳密に言えば、単調に増加する値を持つ人工のユニークなフィールドを作成することは可能ですが、私はそのような必要性は見ていません。
すべての統計は、日付ごとに並べ替えて、1000個ごとに選択できます。そのたびに、到達可能な日付を記憶し、次回からすでに退却することができます。 統計のアンロードが保証されたら、削除できます。 さらに、これらの1000エントリページのフラグメントを呼び出します。 別の数を選択することもできますが、1000が悪くないことが判明しました。たとえば100なので、1000で停止しました。
統計をパラメーターとしてアップロードするスクリプトは、データの出力が必要になる前に、最大日付(つまり、時間のない日付)を取ります。 これには2つの理由があります。
1)統計は継続的に受信されますが、「昨日以前の」データは変更されません。
2)大量のデータと実行時間の制限により、すべての統計を一度にアップロードするだけではうまくいかない場合があります。少なくとも1日はアップロードできます。
したがって、大ストロークのアルゴリズムでは次のことが判明しました。
- このクエリのようなものを使用して、最も古い1000レコードを選択します。SELECT * FROM request where date <$ date order by date limit 1000;
- 各行のcsvレコードを生成します。
- $ last_date-最大受信日を覚えておいてください。
- リクエストを実行し、$ last_dateを条件に追加します:SELECT * FROM request where date <$ date and date > = $ last_date order by date limit 1000;
- クエリ結果は空ではないgoto 2です。
理論的には、2つの異なるリクエスト間で時刻が正確に一致する可能性がまだ存在するため、$ last_dateと比較する場合、「lax more」が使用されます。 ページのジャンクションで行が重複しないようにするには、一意のキーを確認し(データベースに保存されているオブジェクトに対してそのようなキーを生成します)、既にアンロードされている場合はその行を省略します。
bullshitbingoの場合、ハブに投稿を公開した日のデータは、20秒を超えて、つまりファウルの寸前でアンロードされました。 もう少しデータがある場合は、ダウンロードを数日ではなく、数時間に分割する必要があります。
統計を削除します。 もちろん、これもまた問題です。 ドキュメントは、一度に1つではなく、データベースからレコードを一括で削除する方が効率的であることを保証します。 指定した日付よりも短いものをすべて削除しようとすると、常にタイムアウトが発生します。 さらに、この手順を同等のボリュームでローカルに確認したところ、動作はゆっくりでしたがゆっくりでした。 削除手順を一度に1レコードずつ書き換える必要がありました。 スクリプトの実行時間に割り当てられた30秒の場合、400〜600レコードが削除されました。 私は手順を再度書き直し、100個のレコードを削除し始めました。プロセスが加速し、そこで何が起こったのかを正確に把握する力がなかったようです。 削除して大丈夫、10のトリックがすべてうまくいきました。
パート2:「Habraeffect?」
このテーマについてはすでにいくつかの記事があります。たとえば、 ここには GAEに関する記事がありますが、javaにはその写真があり、完全に機能するプロジェクトがあります。
一般に、このビジネスを特別な効果とも呼びません。ピーク時には、負荷は1秒あたり4リクエストでした。 1時間以内に、負荷は1秒あたり約2リクエストでしたが、その後は着実に低下しました。これはすべてグラフから明らかです。
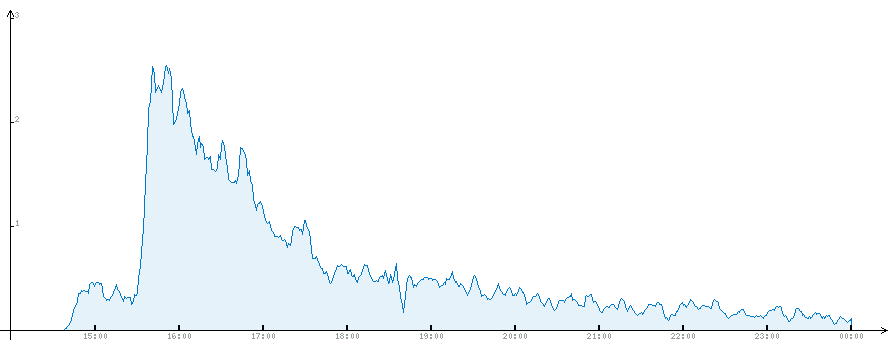
完全な統計。 4つのクエリのピーク負荷は、平均化のためにここでは表示されません。
時はモスクワで、投稿は14:40に公開されました。明らかに約1時間後に彼はメインページに行きました。 GAEはGMTで時間を節約しますが、csvファイルを読み込むときにおそらく可能ですが、グラフを描画する段階で既に変換を実行しました。

メインページの統計は別途。

Habraゲームの統計。

翌日の統計:午前11時までに、大部分の人がハラランの2ページ目まで読み上げました。

GAE管理インターフェイス。 ここでは、消費されたリソースも確認できます。スクリーンショットは、投稿の公開から10時間後に撮影されました。 絵が好きです。
2日間の統計もあり、スケールを推定できます。
最適化をまったく行っていないことに注意してください。 つまり、リクエストごとに、データベースから可能なすべてのもの(すべての署名、見出し、名前と説明、ゲームのすべての単語)が選択されましたが、人工的な空のサイクルは手配しませんでした。 これはまず怠のために行われ、次に何が起こるかを見るために行われます。 その結果、GAEが無料で提供するリソースの約70%が消費されます。 CPUがボトルネックであることが判明し、他のすべてのリソースの1〜2%が使い果たされました。 さらに、データベースへのアクセス時にいくつかのタイムアウトエラーが発生したため、データベースに関するほとんどの作業は後でmemcachに転送されました。
いくつかの統計
投稿後、約150人が管理インターフェイスを見ようとし、90のゲームが作成され、そのうちの30が空ではなく、15が意味のあるコンテンツで完全に想像されていました。
ログインした合計人数(IPアドレス別):6814
複数のページをロード:3573または52%
2ページを超える読み込み:2334、34%
10以上:215、3%
結論
GAEで大量のデータを操作することはあまり便利ではありませんが、可能です。 実際の作業では、スケジュールに従って統計情報をダウンロードするスクリプトを作成し、正確性を自動的に確認してから、ダウンロードしたGAEのクリーニングを初期化する必要があります。 つまり、これはすべて非常に顕著なオーバーヘッドコストにつながり、非常に明確ではあるが克服できない困難を生み出します。