
こんにちは、Habr!
プロセッサで使用するすべてのデバイスは、フォンノイマンマシンの原理またはその修正に従って構築されています。 簡単な例:x86を使用する私たちはすべて、フォンノイマンアーキテクチャとハーバードアーキテクチャのハイブリッドです。
しかし、habrasocietyはNOT von Neumannマシンの存在(少なくとも概念、計画、図面、作業サンプル)について知っていますか?
現在は放棄されている(静かに復活している)が、データ駆動型プロセッサアーキテクチャについて、その重要性と独創性を損なうことのない、プロセッサエンジニアリングの概念的な方向についてお話したいと思います。
このコンセプトは、70年代にMITのモンスターによって開発され、その後、世界中の他のプロセッサビルダーによって取り上げられました。
さあ、行こう!
フォン・ノイマンによるとではありませんが、どうやって? o_0
要するに(誰が忘れたのか)、 フォンノイマンアーキテクチャのキーポイントは次のとおりです。
- コマンドは順番に実行されます
- コマンドとデータの区別がつかない
- メモリのアドレス指定可能性
そして、これらすべてから離れるとどうなりますか? そして、これはこれです:
- オペランドの準備が整ったときにコマンドが実行されます
- しかし、それも必要ですか? 通常の意味で、チームとデータの両方を拒否できます。
- ポインターは忘れられない悪夢です...ムーンフェイズの影響もそうです。
データ駆動型アプローチ
そこで、フォンノイマンモデルを放棄しました。 しかし、見返りに何を提供しますか?
答えは簡単です-パッケージング。 はい、はい、ネットワーク上のパケットのように、より小規模ではるかに高速です。
パッケージには、オペレーションコード(>、<、+、-など)、オペランド(またはこれらのオペランドを提供する他のパッケージへのリンク)、および各オペランドの準備マークが含まれます。 データとコマンドの分離はありません。プロセッサは、必要なすべての既製の「スープ」セットで動作します。
原則として、メモリアドレス自体はそうではありません。 すべてがすでに並べ替えられています。 パッケージインデックスのみが既知であり、他に何も知る必要はありません。
1つのパケットのオペランドが処理され、結果が他のパケットに送信されてアクティブになります。 つまり、実際には、初期条件と分岐に応じて、プログラムはそれ自体を収集します。
この概念の開発は、クエリ駆動型のプロセッサです。 これは同じことですが、プロセスは上から下へではなく、下から上へ、つまり 操作は、以前のパッケージからの要求に応じてのみ実行されます。これにより、操作の数が減り、パフォーマンスが向上します。
(X + Y)*(XY):
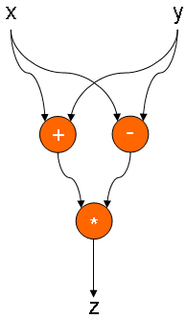
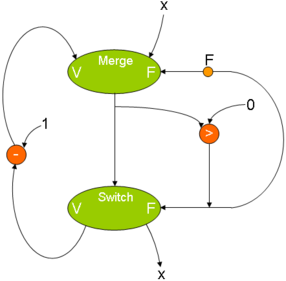
X> 0 DO X-1の場合:
そして、二次方程式の解は次のようになります。
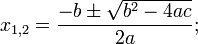
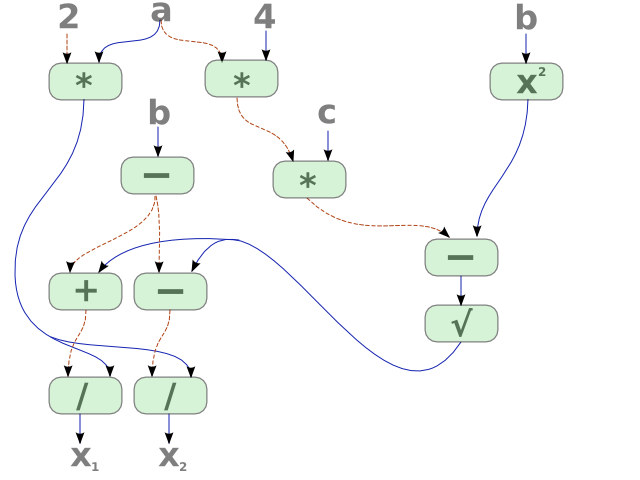
メリット
- 並列化を必要とする計算の高効率。 スレッドを忘れて、タスクはブロックに分割することにより、可能なすべてのプロセッサとコアに自動的に分散されます。
- アルゴリズムに関係なく、コア/プロセッサ間の均一な負荷分散。
- 同期には問題ありません。 スレッドなし。
- 実行に必要なデータがない場合、計算されません-パフォーマンスの向上。
欠点
- 基本的なシングルタスク。 マルチタスクのシミュレーションは可能ですが、メモリ内のパケットにタグを付けるだけです。
- パラグラフ1の結果は、そのようなプロセッサーの例外的な希少性です。
- 私が知る限り、単一の商業的に実行可能なモデルは構築されていません。
- フォンノイマンマシンと比較してより複雑な実装。
アプリケーション:信号処理、ネットワークルーティング、グラフィックコンピューティング。 最近、データベースの分野での応用が検討されています。
奇妙なことですが、数日間のグーグルの後でも、そのようなプロセッサの使用の実際の例は見つかりませんでした。
この概念に最も適したプロセッサは、日本の沖電気DDDPです。