ポータブルドキュメント形式では、 前回見たDOCXやODTほど単純ではありませんが、それでも元はバイナリ形式ではなくテキスト形式のままです。 びっくりした? 次に、中身を見てみましょう。 それから本当にたくさんのテキスト。

お気づきかもしれませんが、私たちの前には、バイナリデータが散在した非常に「テキスト」のドキュメントがあります。 もちろん、ノートブックでpdfブックを読むことはできませんが、何が書かれ、何が画面に表示されるかを理解することは非常に可能です。 この記事の目的はデータ形式を説明することではないことを事前にお知らせします。そのため、「テキストはどこで検索できますか?」
PDFデータタイプ
PDFはいくつかの基本的なデータ型(正確には8つ)をサポートしていますが、その一部は文字列、配列、辞書(ディストナリー)、ストリーム、オブジェクトです。 それぞれについて説明しましょう。
行
PostScriptから継承されたPDF文字列。その結果、.pdfの文字列は、括弧で囲まれた8ビット文字のシーケンスを意味します。 文字列はバックスラッシュを使用して次の行に転送できます。バックスラッシュは行の一部ではなく、特に特殊文字をエスケープします。
(最初の行\ 最初の行\ n 2番目の行は角かっこ付き\(\))
その結果、出力に2行が表示されます。
最初の行最初の行 括弧付きの2行目()
PDFの元の8ビット文字のため、たとえば同じUnicodeエンコーディングでテキストデータを挿入する方法がいくつかあります。 独立した2バイトの16進数(
<2B>
)またはそのシーケンス(
<54776F20>
)を使用して、8進文字コード挿入(
\053
)を使用できます。 たとえば、次の行は同等です。
(2 + 2 =4。) (2 \ 053 2 \ 0754。) (2つの<2B> 2つの<3D> 4つ。) (<54776F202B2074776F203D20> 4)。
将来、PDFドキュメントを含む行のテキストデータを検索する方法を学習します。
配列
PDF配列は角括弧で囲まれ、単純にグループ化されたオブジェクトのシーケンスです。 例:
[(Hello,)10(world!)]
。 配列にはテキスト文字列が含まれることがあります。
辞書
これらは<<と>>で囲まれたキーと値のペアです。 多くの場合、辞書は、辞書に記述されているプロパティを含むオブジェクトにそのオブジェクトを付与するために使用されます。 しかし、これらのデータは、たとえばストリームを復号化する方法、その長さを調べる方法、または逆に現在のオブジェクトを関心のないものとして破棄する方法(イメージの場合)を決定するのに役立ちます。 通常のPDF辞書の例を次に示します。
<< /長さ681 /フィルター / FlateDecode >>
読んだ後、私のコードは次のように表示します:
$辞書 = 配列 (ストリーム
"長さ" => "681" 、
「フィルター」 => true 、
"FlateDecode" => true 、
) ;
ストリームは、
stream
endstream
と
endstream
stream
endstream
間の8ビットデータのシーケンスを表します。 バイナリデータは、圧縮テキスト、画像、埋め込みフォントのいずれであっても、ストリームとして表示されます。 ストリームは常にオブジェクトの内部(すぐ下)に配置され、少なくともその長さ(辞書のオプション
/Length N
)と、多くの場合圧縮方法(
/Filter /FlateDecode
)によって特徴付けられます。 PDFは十分な数の圧縮形式(暗号化形式
/CryptDecode
を含む)をサポートしますが、3つだけに関心があります:最も一般的に使用されるFlate(gzip圧縮)およびよりまれなASCII Hex(データを末尾の文字を持つ16進文字列として表します
>
) ASCII 85ベース(ソーステキストの4つの連続した文字が、ASCIIテーブルで
!
から
y
までの5文字でエンコードされている場合の圧縮)。
ストリームでは、PDFドキュメントから取得するテキストを探します。 このトピックの冒頭にある画像の後半にストリームの例を見つけることができます: はい、はい、それらの亀裂-これはそれです。
オブジェクト
オブジェクトは、動作する最大の構造です。 オブジェクトは、キーワード
obj
および
endobj
で囲まれた、通常の数値からストリームまでの他のデータ型を内部に含むことができます。 オブジェクトは、ドキュメント内で独自のIDを持ち、これを使用して参照できます。 まず、自分の内部にスレッドを持つオブジェクト(メインサブタスクを忘れないでください)に興味があります。ほとんどの場合、辞書の形で追加のオプションセットが含まれています。 これは、PDFファイル内のオブジェクトの典型的な例です(非圧縮ストリームコンテンツを使用):
2 0 obj << /長さ9 2 R >> ストリーム BT / F1 12 Tf 72,712 Td(短いテキストストリーム。)Tj ET エンドストリーム endobj
さて、データの内部表現の入門部分はこれで終わりました。「ちょっとしたこと」-ストリームからテキストを取得し、内部文字変換の辞書を取得します(これまで見たことのない実装です)。
テキストを探す場所は?
「PDF文書内のテキストオブジェクトをどこで検索できますか?」という問題を定式化します。ここでは、すべてが1回または2回以上の簡単なことをさまざまなフォーラムで説明しています。スレッドがあるオブジェクトを探します。 通常、gzipで圧縮されたストリームを意味しますが、ドキュメントには、圧縮されていないか、逆に、いくつかの圧縮(
/Filter /FlateDecode /ASCIIHexDecode
)が含まれている可能性があります。 さて、有効な例が必要です。 Mikhail Yuryevich Lermontovによる詩「Sail」のPDF形式 (このドキュメントは、前の記事のodtファイルからAcrobat.comで作成されました)。
このドキュメントでオブジェクトを見つけて、解析を開始します。 少しカンニングをして、明らかにテキストデータがあるオブジェクトを取り上げますが、これは単なる例です。スクリプトは何を扱うかを気にしません。
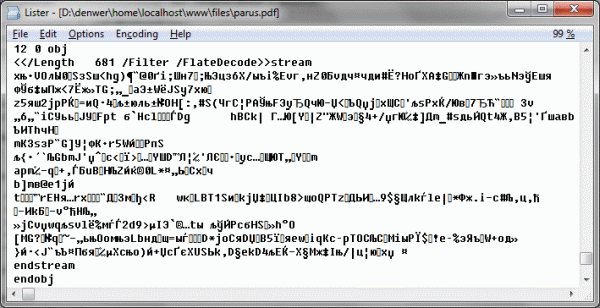
まず、PDFデータ型に関する以前に取得した知識を使用して、目の前にあるものを理解しましょう。 データストリームが681バイト(
/Length 681
)であり、ストリームがgzip(
/FlateDecode
)で圧縮されている(
/Filter
)と言うプロパティのディクショナリを持つオブジェクトの前にあります。 データストリームをアンロードするのに十分な情報が既にあります
gzuncompress
が適切です:
0.1ワット q 0 -0.1 612.1 792.1 re W * n q 0 0 0 RG 0 0 0 rg BT 2 Tr 0.59999ワット 56.8 716.6 Td / F1 18 Tf [<01> 17 <02> 10 <03> 10 <04> 17 <05>] TJ ET Q q 0 0 0 rg BT 56.8 682.5 Td / F1 11 Tf [<06> 9 <07> 11 <08> 6 <07> 11 <07> 11 <09> 13 <0A> 4 <0B> 14 <0C> 11 <0D> 11 <0E > 9 <0F> 9 <0A> 4 <10> 11 <11> 10 <12> 23 <13> 6 <10> 11 <14> 10 <10> 11 <15>] TJ ET ...多くのテキスト...
次に、この例から少し脱線し、PDFでのテキストの表示についてもう少し学習しましょう。 いくつかのことを覚えておく必要があります。
- テキストがストリーム内にある場合、テキスト
BT
(テキストの先頭)の先頭とET
末尾(テキストの末尾)の「マーカー」の間に含まれます。 - PDFは、Tjマーケット(テキストの表示)または
TJ
マーカー(個々の文字の位置に基づいてテキストを表示)があるかどうかによって、テキストを表示する場合としない場合があります。 これらのマーカーは、この場合のように、テキストの行または行の配列の後に表示されます([<01>17<02>10<03>10<04>17<05>]TJ
)。 - 上で書いたように、PDFは個々の文字の配置をサポートします。つまり、文字の各ペア間の距離の任意の個別のサイズを指定できます。 これについては後で
1. <01> 17 <02> 10 <03> 10 <04> 17 <05> 2. <06> 9 <07> 11 <08> 6 <07> 11 <07> 11 <09> 13 <0A> 4 <0B> 14 <0C> 11 <0D> 11 <0E> 9 <0F> 9 <0A> 4 <10> 11 <11> 10 <12> 23 <13> 6 <10> 11 <14> 10 <10> 11 <15>
この例のPDFを注意深く読んだ読者は、見出し( SAIL )と詩の最初の行( 帆だけが白くなる )があることを示唆しているかもしれません。 そして彼は正しいだろうが! ただし、このテキストの非常に奇妙な16進コードは見つかりません。
-
は01 02 03 04 05
としてエンコードされます -
06 07 08 07 07 09
...
変換表
前の例では、PDFからテキストを取得するためのほとんどの関数が保存されます。これは、インターネット上のパブリックドメインで見つけることができます。 何が何であるかを理解してみましょう。 したがって、 ToUnicode CMapsに関心があります 。これについては、AdobeからPDF形式の説明のテキストを取得することに関するサブセクションで説明します。 ファイルでそれらを検索しましょう。 私は再びカンニングし、読者に「意図的に正しい作品」を提供します。
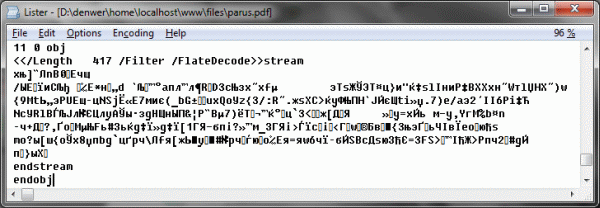
解読する:
/ CIDInit / ProcSet findresource begin 12 dict開始 begincmap / CIDSystemInfo << /レジストリ(Adobe) /注文(UCS) /サプリメント0 >> def / CMapName / Adobe-Identity-UCS def / CMapType 2 def 1 begincodespacerange <00> endcodespacerange 45 beginbfchar <01> <041F> <02> <0410> <03> <0420> <04> <0423> <05> <0421> <06> <0411> <07> <0435> <08> <043B> <09> <0442> ...変換の多くの行... endbfchar endcmap CMapName currentdict / CMap defineresource pop 終わり 終わり
おなじみの数字
<01>
、
<02>
など? まあ-テキスト行で少し前に見ました。
01
を
041F
に置き換える必要があると仮定し、この数字が何を隠しているのか見てみましょう。 やった!
#x041F
=
! あるキャラクターから別のキャラクターへの変換が見つかったので、今度はドキュメントを参照して、もう少し学びます。
bfchar
beginbfchar
と
endbfchar
の間の変換が最も簡単です。 最初のコードを別のコードに一致させます。 たとえば、上記の例では、
01
が文字コード
隠すことがわかりました
しかし、これはこの変換の操作の特別な場合にすぎません-最大512文字(Unicodeでは最大128文字)の文字列全体に単一のコードを一致させることが可能です。
bfrange
beginbfrange
と
endbfrange
囲まれた別のより複雑な変換があります。 個々のキャラクターではなく、その範囲で動作します。 変換は、作業のために2つのオプションをサポートします。
-
<0000> <005E> <0020>
-0000から005Eの範囲で作業します。各値は、間隔0020および007Eの値に変換されます。 原理に気づきましたか? 0000は0020、0001から0021、0002から0022などに変換されます。 -
<005F> <0061> [<00660066> <00660069> <00660066006C>]
-005Fと0061の間隔(つまり、別の0060)の各値は、角括弧内の配列の対応するシーケンスに置き換えられます。005Fは0066 00に置き換えられます。 66(つまりff
)、0060でfi
、そして0061でffl
。
アルゴリズムとコード
私たちの知識を使用して、帆に関する「不運な」詩を読むことができます。 さて、最も興味深いコードと完全なソースへのリンクを提示する時間です:
GitHubにコメントを付けてコードを取得できます 。
- 関数 pdf2text ( $ filename ) {
- // pdfファイルのデータを行に読み込み、ファイルに含まれる可能性があることを考慮
- //バイナリストリーム。
- $ infile = @ file_get_contents ( $ filename 、 FILE_BINARY ) ;
- if ( empty ( $ infile ) )
- return "" ;
- //最初のパス。 ファイルからすべてのテキストデータを取得する必要があります。
- //最初のパスでは、位置付けされた「ダーティ」データのみを取得します。
- // 16進挿入など。
- $変換 = 配列 ( ) ;
- $ texts = array ( ) ;
- //まず、pdfファイルからすべてのオブジェクトのリストを取得します。
- preg_match_all ( "#obj(。*)endobj#ismU" 、 $ infile 、 $ objects ) ;
- $オブジェクト = @ $オブジェクト [ 1 ] ;
- //見つけたものを見てみましょう-テキストに加えて、捕まることができます
- //たとえば、同じフォントなど、多くの興味深いもので常に「おいしい」ものではありません。
- for ( $ i = 0 ; $ i < count ( $ objects ) ; $ i ++ ) {
- $ currentObject = $ objects [ $ i ] ;
- //現在のオブジェクトにデータストリームがあるかどうかを確認します(ほとんどの場合)
- // gzipを使用して圧縮します。
- if ( preg_match ( "#stream(。*)endstream#ismU" 、 $ currentObject 、 $ stream ) ) {
- $ストリーム = ltrim ( $ストリーム [ 1 ] ) ;
- //このオブジェクトのパラメータを読み取ります。テキストのみに関心があります
- //データなので、最小限のクリッピングを行って速度を上げます
- //実行する
- $ options = getObjectOptions ( $ currentObject ) ;
- if ( ! ( empty ( $ options [ "Length1" ] ) && empty ( $ options [ "Type" ] ) && empty ( $ options [ "サブタイプ" ] ) ) )
- 続ける ;
- //したがって、「おそらく」テキストになる前に、バイナリから復号化する
- //ビュー。 このアクションの後、プレーンテキストのみを処理します。
- $ data = getDecodedStream ( $ stream 、 $ options ) ;
- if ( strlen ( $ data ) ) {
- //したがって、現在のストリームでテキストコンテナを見つける必要があります。
- //成功した場合、見つかったダーティテキストは残りに移動します
- //前に見つかった
- if ( preg_match_all ( "#BT(。*)ET#ismU" 、 $ data 、 $ textContainers ) ) {
- $ textContainers = @ $ textContainers [ 1 ] ;
- getDirtyTexts ( $ texts 、 $ textContainers ) ;
- //それ以外の場合、シンボリック変換を見つけようとし、
- // 2番目のステップで使用します。
- } その他
- getCharTransformations ( $変換 、 $データ ) ;
- }
- }
- }
- // pdfドキュメントの初期解析の終わりに、受信したドキュメントの分析を開始します
- //シンボリック変換を考慮したテキストブロック。 最後に、戻ります
- //結果が取得されました。
- getTextUsingTransformations ( $ texts 、 $ transformations )を 返し ます。
- }
おわりに
さて、このコードは作成の冠ではありません。提供されるすべてのpdfファイルを解析するわけではありません。 たとえば、ロシア語のフォントが実装され、英語の文字からロシア語の文字の表示に変換されるドキュメントがあります。
このコードは、個々の文字の配置では機能しません。 タスクは実行可能であり、難しくはありません。私はその解決策を読者の肩に置いています。
このコードは、情報を提示するための内部標準に従ってPDFファイルを読むのには理想的ではありません:ページを検索せず、ドキュメントのバージョンで動作しません(PDFは変更の履歴をサポートします)、処理できる情報を完全に読み取らない可能性さえあります。
誰も
$content = shell_exec('/usr/local/bin/pdftotext '.$filename.' -');
をキャンセルしていないことに注意してください
$content = shell_exec('/usr/local/bin/pdftotext '.$filename.' -');
。 しかし、この場合、タスクは、任意のプラットフォームおよび任意のプラットフォームでPDFを読み取ることでした。
この記事に興味を持っていただければ幸いです。その目的は、コミュニティをPDFデバイスに慣れさせ、PHPでそれを読む能力を持ち、複雑なケースでデータを取得するための出発点を見つけることです。
アクティビティと問題への関心に応じて、PDF(ドキュメントの内部構造、ポジショニング、フォント、内部リンク)に関するストーリーを続けるか、RTFを例としてトピック「すべてのコストでテキスト」に戻ります。 ご清聴ありがとうございました!
参照: