ArraySortHelper<T>
クラスの
ArraySortHelper<T>
メソッドに出会いました。
ここで興味深い点は、要素の比較です。柔軟性を確保するために、
IComparer<T>
インターフェイスを実装する別のクラスによってレンダリングされます。 さまざまな考えとスタジオを用意して、そのような柔軟性のコストとそれで何ができるかを評価することにしました-カットの下には、QuickSortの操作中に要素を比較するコストの分析があります。
したがって、Hoarのクイックソートの標準実装があります。これは、
IComparer<T>
インターフェイスを実装するオブジェクトの
Compare(T x, T y)
メソッドを使用して、配列要素を比較します。 実験では、リフレクターを使用して、ソート方法のコードを次の形式で取得します。
Copy Source | Copy HTML
- static public void Sort <T、TValue>(T []キー、TValue []値、 int左、 int右、IComparer <T>比較器)
- {
- する
- {
- int index = left;
- int num2 = right;
- T y =キー[インデックス+((num2-インデックス)>> 1 )];
- する
- {
- 試してみる
- {
- / * Cmp 1 * / while (comparer.Compare(keys [index]、y)< 0 )
- {
- インデックス++;
- }
- / * Cmp 2 * / while (comparer.Compare(y、keys [num2])< 0 )
- {
- num2--;
- }
- }
- catch ( IndexOutOfRangeException )
- {
- 新しい ArgumentException ( null 、 "keys" )をスローします。
- }
- catch ( 例外 )
- {
- 新しい InvalidOperationException ()をスローします。
- }
- if (インデックス> num2)
- {
- 休憩 ;
- }
- if (インデックス<num2)
- {
- T local2 =キー[インデックス];
- キー[インデックス] =キー[num2];
- キー[num2] = local2;
- if (値!= null )
- {
- TValue local3 =値[インデックス];
- 値[インデックス] =値[num2];
- 値[num2] = local3;
- }
- }
- インデックス++;
- num2--;
- }
- while (インデックス<= num2);
- if ((num2-left)<=(right-index))
- {
- if (左<num2)
- {
- / * Call 1 * / Sort <T、TValue>(keys、values、left、num2、comparer);
- }
- 左=インデックス。
- }
- 他に
- {
- if (インデックス<右)
- {
- / *呼び出し2 * /ソート<T、TValue>(キー、値、インデックス、右、比較子);
- }
- right = num2;
- }
- }
- while (左<右);
- }
比較操作の呼び出しのみを調査するため、この関数に対するすべての変更は、リストの識別コメントでマークされている行1、12、16、53、および61でのみ行われます。
パート1 数値の配列の実験(int)
まず、ソート処理の期間中に2つの数値を比較する操作を呼び出すオーバーヘッドの寄与を推定します。 これを行うには、上記の関数で、「
comparer.Compare(a, b)
」の呼び出しを「
a - b
」の形式の式に変更します。 両方のバージョンの実行時間を測定し、参照してください...恐ろしい画像が表示されます-時間のほぼ3分の2が、比較番号の述部の呼び出しの編成に費やされています。

何がそんなに遅くなるのでしょうか? 明らかに、ポイントは比較プロセスの過度の複雑さです(これは、演算自体が2つの数値を減算することに削減されるという事実にもかかわらず!):
-
comparer
のnull
チェック - オブジェクト仮想テーブルでの
Compare
メソッドの検索 -
comparer
オブジェクトのCompare
メソッドを呼び出す -
CompareTo
メソッドを呼び出す - 実際に数字の比較
この場合、最初の2つのポイントは、CIL命令
callvirt
と
call
違いです。
null
チェックの存在により
callvirt
は、仮想性に関係なく、 すべての非静的クラスメソッドを呼び出すために生成されることを思い出させてください。
さて、4番目のポイントは、比較器の標準実装によって呼び出されます(
T
代わりに
int
を置換する場合、
null
すべてのチェックはJITコンパイラーによって自然に削除され
null
)。
Copy Source | Copy HTML
- クラス GenericComparer < T >:IComparer < T > ここで、 T : IComparable < T >
- {
- public int Compare( T x、 T y)
- {
- if (x!= null )
- {
- if (y!= null )
- {
- return x.CompareTo(y);
- }
- 1を 返します。
- }
- if (y!= null )
- {
- return - 1 ;
- }
- 0を 返し ます 。
- }
- }
レイヤーを一度に1つずつ削除します。これは、
CompareTo
を呼び出すことから始めます。これは基本的に行われるためです。次の形式の比較
CompareTo
子を作成します。
Copy Source | Copy HTML
- クラス IntComparer : IComparer < int >
- {
- public int Compare( int x、 int y)
- {
- return x-y;
- }
- }
測定では、15%の確率で勝っています。 そして、すべての構造体のすべてのメソッドに関して、整数の配列を検討し、それらに対して
CompareTo
を呼び出すという事実にもかかわらず、これは非仮想的です。 次の層である
callvirt
と
call
ときの
call
違いは、特にソート機能の柔軟性に関する同じ要件の範囲内で、検証がより困難です。 ただし、不可能なことは何もありません。構造体のインスタンスを操作する場合、インターフェイスから継承されたメソッドの実装を含め、
call
操作を使用してすべての構造体のすべてのメソッドが呼び出されます。 これにより、次の最適化を行うことができます。
Copy Source | Copy HTML
- static public void SortNoVirt <T、TValue、TCmp>(T []キー、TValue []値、 int left、 int right、TCmp comparer) ここで、 TCmp: IComparer <T>
- {
- // ...
- }
- struct IntComparerNoVirt : IComparer < int >
- {
- public int Compare( int x、 int y)
- {
- return x-y;
- }
- }
実際の型がソート関数に転送されるため、ジェネリックパラメーターが展開されると、実際の型の比較演算子が考慮され、より効率的な
call
命令が使用されて比較演算が呼び出されます。 時間の測定では、「標準」コールの実行時間の約35%の生産性の向上が示されていますが、引き算による
Compare
コールの後続の置き換えからの増加は18%です。
注: C ++のSTLライブラリでは、すべての述語がこの方法で送信されます-型はテンプレートパラメーターを通過します。 さらに、このトリックのおかげで、C ++コンパイラは型に関する完全な情報を取得し、原則として述語コードのインライン化を実行するため、メソッドを呼び出すコストが完全になくなります。 .Net JITの結果を分解した経験から、すべてのトリックとは異なり、ここでは展開が行われないことが示されました。 どうやら、これはジェネリックに関連するか、静的メソッドに対してのみ機能します。
注#2:空の構造を使用して比較演算子の転送を保存することはできませんでした-C#のフィールドのない構造のサイズ(
sizeof
)は1に等しいことが判明しました(必要に応じてゼロではありません)。 VC ++では、空の構造体のサイズも1に等しくなりますが、標準では、空のクラス(構造体)のサイズは0より大きい必要があるとされています。 これは、配列「
sizeof(array) / sizeof(array[0])
」の長さを計算するための一般的な設計のために行われます。 C#/。Netでは、これは明らかにC ++で書かれたコードとやり取りする際のバイナリ互換性のために行われます。
データを単一のダイアグラムに縮小すると、標準的な方法によるソートの実行時間の次の分布が得られます。
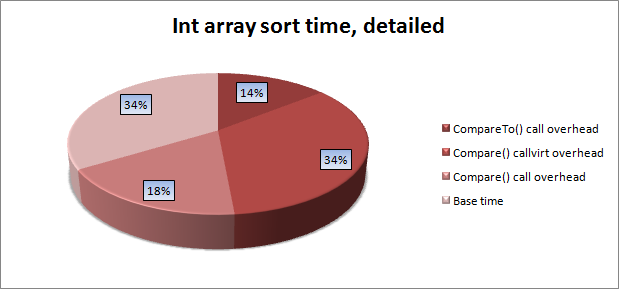
明らかな結論は、計算量の多いライブラリの開発では、頻繁に呼び出される述語構造を作成し、ジェネリックパラメーターを介してその型を転送することが理にかなっているということです。
パート2 そして、オブジェクトはどうですか?
しかし、私たちのアプリケーションは数字で生きているわけではありません:)影響の問題は、オブジェクトの配列を操作するコンテキストで発生しました。 簡単! このような単純なクラスをプロトタイプとして使用します。
Copy Source | Copy HTML
- クラス IntObj : IComparable < IntObj >
- {
- パブリックint値 。
- public int CompareTo( IntObjその他)
- {
- 戻り値 -その他。 値 ;
- }
- }
そして、同様の単純な実験を行いますが、オブジェクトの配列を使用すると、結果としてわずかに異なる状況になります。

また、比較プロセスの各部分の比率が変わらない場合、合計時間への寄与は著しく減少します。 非常に幸運な質問が発生します。問題は何ですか、何が遅くなっていますか? ソート関数のコードをひと目見れば、理解するのに十分です。コードの唯一の異なる部分の処理が遅くなりました-配列要素間の値の交換。 しかし、私たちは参照型を使用しており、ポインタのみが再配置され、それらは数字の「中心」にあります! おもしろいので、そこで速度が低下し、CILを読んでもあまりメリットがないことが
*.ref
ます。交換コードは、数字には
*.i4
命令を、オブジェクトには
*.i4
使用する以外はまったく同じです。
CILは役に立たなかったので、JIT出口を意味するので、アセンブラーを見てみましょう:)ここで私たちは多くの問題に直面しています-構成(デバッグ/リリース)に関係なく、JITコンパイラーはその環境を見て、プロセスに接続されたデバッガーの存在に応じて別のコードを生成します。 したがって、[逆アセンブリ]ウィンドウから実際のコードにアクセスするには、デバッグせずにアプリケーションを起動し、
Debugger.Break();
の呼び出しの形式でブレークポイントを設定します
Debugger.Break();
。 以下は、配列の2つのセルの値を交換するために生成されるコードのリストです。
リストでは、オブジェクトの配列に書き込む関数の呼び出しにすぐに気付き、CILを監視している間はこの呼び出しはありませんでした。 明らかに、この関数は単にアドレスをコピーするだけではなく、この呼び出しを整理するコストに加えて、何か他のものを取得します。つまり、詳細はCLRの実装にあります。 実際、パブリックバージョンのCLR 2.0(SSCLI 2.0パッケージ)のソースを読んだ後、次のコードが見つかりました。
Copy Source | Copy HTML
- / **************************************************** **************************** /
- / *適切なチェックをすべて行った後、配列[idx]に「val」を割り当てます* /
- HCIMPL3( void 、JIT_Stelem_Ref_Portable、PtrArray *配列、符号なしidx、 Object * val)
- {
- if (!配列)
- {
- FCThrowVoid(kNullReferenceException);
- }
- if (idx> = array-> GetNumComponents())
- {
- FCThrowVoid(kIndexOutOfRangeException);
- }
- if (val)
- {
- MethodTable * valMT = val-> GetMethodTable();
- TypeHandle arrayElemTH = array-> GetArrayElementTypeHandle();
- if (arrayElemTH!= TypeHandle(valMT)&& arrayElemTH!= TypeHandle(g_pObjectClass))
- {
- TypeHandle :: CastResult result = ObjIsInstanceOfNoGC(val、arrayElemTH);
- if (result!= TypeHandle :: CanCast)
- {
- HELPER_METHOD_FRAME_BEGIN_2(val、配列);
- //これはArrayStoreCheck(&val、&array);と同等です。
- #ifdef STRESS_HEAP
- //ストレスレベルが十分に高い場合、すべてのjitでGCを強制します
- if (g_pConfig-> GetGCStressLevel()!= 0
- #ifdef _DEBUG
- &&!g_pConfig-> FastGCStressLevel()
- #endif
- )
- GCHeap :: GetGCHeap()-> StressHeap();
- #endif
- #if CHECK_APP_DOMAIN_LEAKS
- //インスタンスがアジャイルの場合、またはアジャイルをチェックする
- if (!arrayElemTH.IsAppDomainAgile()&&!arrayElemTH.IsCheckAppDomainAgile()&& g_pConfig-> AppDomainLeaks())
- {
- val-> AssignAppDomain(array-> GetAppDomain());
- }
- #endif
- if (!ObjIsInstanceOf(val、arrayElemTH))
- {
- COMPlusThrow(kArrayTypeMismatchException);
- }
- HELPER_METHOD_FRAME_END();
- }
- }
- //最適化されたJIT_Stelem_Refのパフォーマンスゲイン
- // jitinterfacex86.cppは、主にJIT_WriteBarrierReg_Bufの呼び出しが原因です。
- //ここで直接書き込みバリアを呼び出すことにより、
- //インラインアセンブリをMSVCからgccに変換することを回避できます
- //ほとんどのパフォーマンス向上を維持しながら。
- HCCALL2(JIT_WriteBarrier、( Object **)&array-> m_Array [idx]、val);
- }
- 他に
- {
- // NULLの書き込みバリアを通過する必要はありません
- ClearObjectReference(&array-> m_Array [idx]);
- }
- }
- HCIMPLEND
これからわかるように、オブジェクトの配列に要素を書き込む場合、配列の境界の標準チェックに加えて、型の互換性もチェックされ、必要に応じて適切な変換が実行されます。 文字列型であり、C#自体にも型制御が含まれていることに注意する価値がありますが、情報は
System.Object
の形式でCIL命令にすでに含まれているため、CLRは信頼性を再確認します。
パート3。 結論の類似性
このすべてからどのような結論を引き出すことができますか? 筋金入りの最適化は提供しませんが、特にミニチュアの述語関数では、大きなループ内での仮想呼び出しを避けることは理にかなっています。 実際には、これはたとえば次のとおりです。
- クラスではなく構造の形式で述語を実装し、その後にジェネリックパラメーターを介して型情報を予測する
- 小さな実用的なクラスメソッドを静的拡張メソッドに置き換えます。静的拡張メソッドは、静的な性質のため、仮想テーブルをバイパスするために呼び出されます
もちろん、これらは唯一の可能な結論ではありませんが、読者は思考のために部屋を離れる必要があります:)