 正規表現はアルゴリズムの算術です。 多くのプログラミング言語、エディター、アプリケーション設定で利用できます。 乗算による加算と同様に、それらは使いやすいです。
正規表現はアルゴリズムの算術です。 多くのプログラミング言語、エディター、アプリケーション設定で利用できます。 乗算による加算と同様に、それらは使いやすいです。
しかし、正規表現を適切かつ効率的に使用するには、正規表現がどのように機能するかを理解する必要があります。 正規表現の原理を説明し、どのような場合に問題があり、それらを解決する方法を示します。
一般的なアドバイスの続き。
私は、メタキャラクターや何らかの参照の平凡な説明を書きたくありません。 覚えているレーキを見せたいです。 規則的な構造を通して自己表現へのパスを概説します。 そして、効果的な正規表現を自然に生成する特定の考え方を伝えるようにしてください。
繰り返しますが、あなたはあなた自身の経験からしか学ぶことができません。 したがって、少なくとも1ダースも書いていない場合は、100正規表現を持つ方が良いでしょう。ドキュメントや本を読んで実験するだけの価値があると思います。
区別と利便性のために、テキストで見つかった正規表現にいくらか色を付けました。 青-記号、緑-量指定子、灰色-角かっこおよびその他のサービス文字、栗-メタ文字、赤-ドット(迷子にならないように)および正規表現のスラッシュ。
理論のビット
私は形式主義者ではなく、理論的根拠を簡単な言葉で説明しようとします。 興味のある方はウィキで正確な言葉遣いを見つけることができます 。
アルファベットに加えて、正規表現には3つのプロパティがあります。
凝集性、2つの式aとbが一緒になって式abを形成できる場合
つまり、式aが最初に実行され、次に残りの行で式bが実行されます。 条件としてのそれらの間には、論理的Iと言うことができます。
アプリケーションでは、これは非常にシンプルで基本的な方法を提供します。検索文字列を連続した部分に分割し、それぞれに対して独自の式を作成し、次に「連結」します。
演算子|を使用して、2つの式aおよびbが可能な場合の代替 式a | bを形成する
クラッチとの違いは、条件aとbの間に論理ORがあり、検証に同じ行が使用されることです。
アプリケーションでは、これにより、完成した式に簡単なブランチを簡単に追加できます。
式a *(空)、a、aa、aaa、...などのすべてのオプションがチェックされた場合のクローズ
つまり、式aを適用しながら再帰的に適用しようとします。 現実には、パーサーはまさにそれを実行し、パフォーマンスの問題を引き起こしますが、実際には、量指定子の作業を検討するときに、さらに詳しく説明します。
いいね! ただし、必要なテンプレートに一致する式を作成するのは簡単です。 必要のないものと一致しないように変更することはより困難です 。
この時点で、メンターの説明は次の言葉で終わるはずです:効率は時間とともにあなたにやってくる、若いパダワン...
種類はありません!
神経系の具体化として正規表現が登場したと言われています。 これがどれほど真実かはわかりませんが、正規表現で考えることを学ぶのは簡単です。 これの鍵は階層です。 見つける必要がある線のバリエーションだけでなく、小さな要素で構成される構造を想像してください。 そして、レギュラーはこの構造の単なる説明です。
まず、シンボルについて話す必要があります。 文字は構造の特定の最小限のコンポーネントですが、 リテラル文字で構成される裸のテキストと、たとえばプログラミング言語の文字列を区別する必要があります。文字列を引用符に限定し、エスケープ文字を使用して文字列内の引用符を示しますまたは繰り返し。 また、通常、印刷できない文字(改行またはタブ)を指定することもできます。 これはすべて、リテラル文字を文字列文字に拡張します。 文字列を解析する必要がある場合は、まずこのステップを登る必要があります。アルファベットの記号を記述する必要があります。
エスケープ文字「\」を使用します。 その場合、文字列の文字は通常の文字「。」の代替です。 シールドされた「\。」。 ここで、表現の交代においては等しくないが、順番に優先順位があると言わなければならない。 つまり、を記述すると、 | \。 、その後、任意の文字が常にそうであるように、ポイントを最後に置きます: \。 | 。 。 これをすべて量指定子*で閉じ、最初と最後に引用符で連結すると、文字列を記述する式が得られます。 しかし、別の落とし穴があります-シンボルの部分表現のポイント。 優先順位が指定されている場合、ポイントは最後であり、オプションを確認するたびにパーサーがいわゆるリターンポイントを配置します。 後続の式が失敗した場合に返される先。 一部のテキストでは、引用符がペアになっていない場合があり、最後の引用符が見つからない場合、パーサーは戻り点まで式のねじを戻します。 シールドされた引用符に遭遇すると、パーサーはそれを2文字に分解し、この誤った結果に満足して、引き続き機能します。 これから、すべてのレギュラーに当てはまる単純な結論を導き出すことができます。 不確実性を排除する必要があります 。 私たちの場合、これは単純です-ピリオドの代わりに、文字クラス[ ^ \ " ]を置き、すべてのあいまいさを取り除きます。
コンパイラーまたはインタープリターに渡す行では、一部の文字もエスケープする必要があるため、プログラムテキストでは次のようになります。
/ " ( \\ . | [ ^ \\ " ] ) * " /
表現する
キャラクターを理解して説明することにより、クラッチまたはクロージャーを使用して、必要に応じて交互に階層を登ることができます。
たとえば、URLを説明するには、まずプロトコルに分割する必要があります。プロトコル、場合によってはユーザーとパスワード、サーバー名、ファイルパスなどです。 次に、パーツを基本的な部分に分割する必要があります。たとえば、サーバー名はドットで区切られた単語ですが、これらの単語には許可された文字があり、右端はtldである必要があります。 基本部分ごとに、文字のアルファベットを慎重に登録し、それらを次のレベルの構造の式に連結する必要があります。
たとえば、名前は[ -a - z0-9 ] +で構成され、ドット[ -a - z0-9 ] + \で区切られます。 [ a - z ] {2,4} (より厳密な場合、許可されたtldは右側に記述できます: c o m | n e t | o r g | r u | i n f o )ドット( [ -a - z0-9 ] + \。 ) + [ a - z ] {2,4}を介したいくつかのレベルの名前があります。
プロトコルはh t t p s ? : / /またはf t p : / / 、その後に名前\ w +およびパスワードが続きます。 +?
一緒に
などなど.../ ( h t t p s ? : \/ \/ | f t p : \/ \/ ( \w + ( : . +? ) ? @ ) ? ) ( [ - a - z0 - 9 ] + \. ) + [ a - z ] {2,4} /
一般に、すべての作業は既にフィールド、セパレーターを示しており、可変性を備えているため、正式な構造を記述するのは簡単です。 主なことは、正しいキャラクターを作ることではありません:)
私はハッキングされた真実を繰り返したいと思います。 時期尚早な最適化は有害です。 少し異なるオプションが必要な場合は、怠けてブロックを交互に繰り返さないでください。 オプション部分または繰り返し部分には「アンカー」が必要です-リテラル文字は先頭または末尾にあります。 何かを追加する場合-遅延しないでください-構造を再度分解し、必要なものを追加してから組み立て直してください。 式内の不可解なハッシュは間違いを犯す確実な方法です。 必要に応じてカバレッジをチェックし、不要なオプションを無視します。 そして、その後のみ最適化します。 ベターではありません-表現の構造は優れていて、すぐに動作しますが、一見すると怖くて混乱しているように見えることもあります。
貪欲な量指定子
現代の正規表現にはいくつかの種類のクロージャーがあります。 この概念を紹介したStephen Cole Kleeneは、次の2つについて説明しました。*と+。 上記のように、彼らの行動は「貪欲」です-彼らは可能なすべてをカバーしようとします-行の終わりまで。 しかし、式のさらに次の演算子または記号があり、すでに行の終わりにいます。 次に、パーサーは、後続の部分式の条件が満たされるまで、量指定子を戻り点に戻します。
明らかに、この動作はパフォーマンスの問題を簡単に引き起こします。 以下は、いくつかのオプションのランタイムです。
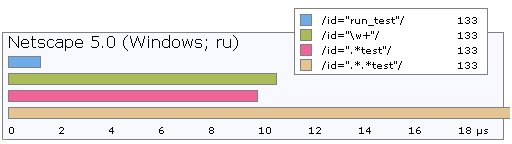
2つのアスタリスクを使用した最後のケースは、実際には1桁遅くなります。 これは、パーサーの特性によるものです。 前述したように、「任意のシンボルを何度も」という表現は逐語的に実行され、実際、パーサーは最初にこの表現で文字列全体をカバーし、各シンボルのリターンポイントを保存します。 式が終了していないことがわかると、パーサーは一致が見つかるまで戻ります。 2つの星が存在すると、リターンポイントの数が1桁、3桁、さらに1桁増えます。 このようなパスにより、「単純な式」が著しく遅くなることが簡単にわかります。
しかし、効率を改善するにはいくつかの方法があります。
停止記号付きの間隔
たとえば、「<」から「>」までのタグを探している場合、任意の文字の代わりに間隔を指定できます。
パーサーは、範囲外の文字を検出すると停止し、すぐに後続のリテラル文字「>」をトリガーします。/ < [ ^ > ] + > /
繰り返し間隔{min、max}を使用します
たとえば、uidまたはmd5署名の最初の検証中に、何文字にする必要があるかがわかっている場合、うまく機能します。
非欲張りまたは遅延量指定子
Perlはやがてこの概念を導入しました。 このような量指定子は逆の働きをします-文字の最小セットをカバーし、後続の連結された式が実行されない場合、それを拡張します。
パフォーマンスの観点からは、ネストされたオプション式では非常にうまく機能しますが、貪欲な量指定子のように、大幅なスローダウンを引き起こす可能性があります。それが明らかな終わりに達するまで量指定子。 これを避けるために、カバーされた文字を間隔でできるだけ狭くし、単純な式を入れた直後に、たとえば固定文字を絞り込むことが望ましいです。
先ほど言ったように、遅延量指定子を使用した式は、可能な限り小さい部分文字列をカバーします。 これにより、たとえば、過剰なカバレッジの問題を簡単に回避できます。
テキスト内の最初のかっこから最後のかっこまでのすべてを取得します。 同時に/ \( . + \) /
最初の閉じ括弧で停止します。/ \( . +? \) /
なぜ停止記号ではないのですか? 常に適用できるわけではないからです。 次の文字は複雑であるか、列挙型の部分式の一部であるか、境界をまったく明確に記述できません。 また、文字数が少ないことがわかっている場合は、遅延量指定子が効果的です。 任意の文字に対応するポイントの後に遅延+と*を置くことを強くお勧めします。そうしないと、パーサーは行末まで歩きます。 ただし、パーサーは滞在場所を指定する必要があることに注意してください。
速度を比較します。
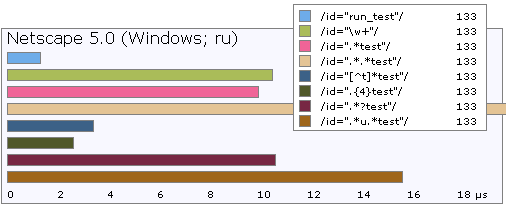
怠zyな「星」と「プラス」には別の欠点があります-境界が後続の部分式で示されていない場合、カバーする文字が少なすぎることがあります。 たとえば、次のような単語を解析する場合:
\w +?
後続のリテラル文字(大きな式の最後)がなければ、この組み合わせは1文字のみをカバーし、この場合は欲張りオプションがより効果的であることがわかります。 また、次の文字が\ w +になることが明確にわかっている場合、貪欲はより効果的であるため、単語またはパラメータを記述できますが、ここでの遅延は単純に効果が低くなります。
怠zyで貪欲なことに加えて、まだあります
超貪欲またはjeの数量詞
それらの重要な違いは、ロールバックしないことです。 このプロパティは、あいまいさが存在する場合に使用できます。 繰り返しますが、あいまいさは効果的な正規表現の敵です。 私は個人的にはそれらを使用しませんでしたが、貪欲な表現の代わりに良い表現で、あなたは冷静にje深いものを置くことができるという意見があります。 非常に重要ではありませんが、goodの数量詞を使用する良い例をここで詳しく説明します 。
結論として
コードからいくつかの悪いケースを示します。
( \ w * ) * -外部の貪欲な星は、単に機能しません。
素晴らしいことは、一部のパーサーはこの式を単純に無視することです。ループバック保護が機能します。
( [ ^ > ] + ) * -ほとんど同じ。
意味に関しては、これらは名前の後にあるタグの内部であり、オプションです。 したがって、+を*に変更し、外部を単に削除します
。 * ; ? 。 *? \ r ? -欲張りの後に*いくつかのオプションの文字があります。
パーサーのオプションの式は、貪欲な量指定子の範囲を返して減らす理由ではないため、これらは重要ではありません。 ほとんどの場合、変更の犠牲者です。 最初の星の後、残りは簡単に削除できます。
\。 ( [ a - z \。 ] {2,6} )は、構造内の区切り文字です。
意図したとおり、たとえばtldの代わりにいくつかのポイントをカバーすると言うだけです。
続けて
- メタキャラクター\ s \ d \ w \ bおよびUnicode
- マルチラインの微妙さ
- 配置とプレビュー
- ...およびその他