これは、Webドキュメントを比較するためのシングル、スーパーシングル、メガシングルのアルゴリズムの原理をアクセシブルな言語で説明しようとする3つの理論的な記事のシリーズの始まりです。
ほとんど重複する検索アルゴリズムに関する出版物では、84個のランダムな帯状疱疹のランダムサンプルを使用したシングルアルゴリズムのバージョンが提案されています。
なぜ正確に84ですか? ランダムに選択された84xのチェックサム値を使用すると、アルゴリズムをスーパーシングルおよびメガシングルのアルゴリズムに簡単に変更できます。 すぐに説明します。
ペンと紙で自分を武装し、以下に説明する各ステップを図の形で比fig的に提示することをお勧めします。
そのため、Webドキュメントの帯状疱疹アルゴリズム
テキストが比較される段階を分析してみましょう。
- テキストの正規化;
- 帯状疱疹への分割;
- 84x静的関数を使用して帯状疱疹のハッシュを計算。
- 84個のチェックサム値のランダムサンプル。
- 比較、結果の決定。
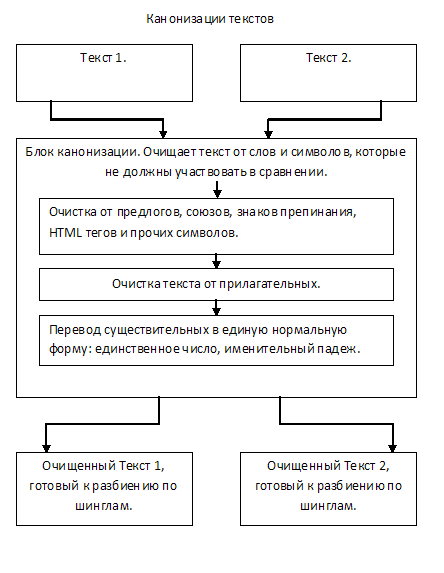
1.テキストの正規化
帯状疱疹のアルゴリズムに関する前回の記事で説明したテキストの正規化とは何ですか。 しかし、簡単に言えば繰り返します。 テキストの正規化により、元のテキストが単一の標準形式になります。
テキストには、前置詞、接続詞、句読点、HTMLタグ、および比較に関与してはならないその他の不要な「ガベージ」がクリアされています。 ほとんどの場合、セマンティックの負荷がないため、テキストから形容詞を削除することも提案されています。
また、テキストの正規化の段階で、名詞を主格の場合、単数形に減らすことも、根だけを残すこともできます。
あなたが実験して実験することができるテキストの標準化により、ここでの行動の範囲は広いです。
出力では、「ごみ」をクリアしたテキストがあり、比較の準備ができています。
2.帯状疱疹への分割
帯状疱疹(英語)-単語のサブシーケンスの記事から分離されたフレーク。
比較されたテキストから、10ピース(鉄片の長さ)で連続する単語のサブシーケンスを選択する必要があります。 サンプリングはオーバーラップで発生しますが、バットでは発生しません。
したがって、テキストをサブシーケンスに分割すると、単語数からシングルの長さ+ 1(単語数-シングルの長さ+ 1)を引いた数の帯状疱疹が得られます。
各項目のアクションは、比較された各テキストに対して実行されることを思い出させてください。

3. 84x静的関数を使用した帯状疱疹のハッシュの計算
この段階は最も興味深いです。 帯状疱疹アルゴリズムの原理は、2つのテキストの帯状疱疹(サブシーケンス)のチェックサムのランダムサンプルを互いに比較することです。
アルゴリズムの問題は、パフォーマンスに直接影響するため、比較の回数です。 比較のための帯状疱疹の数の増加は、生産性に重大な影響を及ぼす操作の指数関数的な増加によって特徴付けられます。
84xの一意の静的ハッシュ関数を介して計算されたチェックサムのセットの形式でテキストを提示することが提案されています。
説明してみましょう。各シングルについて、84個のチェックサム値が異なる関数(たとえば、SHA1、MD5、CRC32など、合計84個の関数)によって計算されます。 したがって、各テキストは、84行の2次元配列の形式で表示されます。各行は、84個のチェックサムの機能に対応しています。
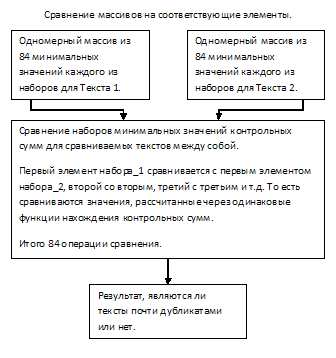
得られたセットから、各テキストの84個の値がランダムに選択され、各テキストが計算されたチェックサム関数に従って互いに比較されます。 したがって、比較のために、合計84の操作を実行する必要があります。

4. 84個のチェックサム値のランダムサンプリング
上で説明したように、84個の配列のそれぞれの要素を互いに比較することは、リソースを大量に消費します。 生産性を高めるために、2次元配列の84行のそれぞれに対して、両方のテキストに対してチェックサムのランダムな選択を実行します。 たとえば、各行から最小値を選択します。
そのため、出力には、各ハッシュ関数のシングルのチェックサムの最小値のセットがあります。

5.比較、結果の決定
そして最後のステップは比較です。 最初の配列の84個の要素と2番目の配列の対応する84個の要素を比較し、同じ値の比率を考慮して、結果を取得します。
おわりに
Yu。G. ZelenkovとI.V. Segalovichの出版物に記載されているWebドキュメントのほとんど重複を見つける理論を、アクセス可能な方法で説明できたことを願っています。 特定のプログラミング言語での実装の詳細に入ることなく。
シリーズの2番目の記事では、Web文書用の超単一アルゴリズムについて説明します。
面白くて、幸運だったと思います。
私たちのブログのオリジナル記事 : パート1。WebドキュメントのShinglesアルゴリズム 。 しばらくお待ちください。続編があります。