- 車からのヒント
-コールドスタート
- ハイブリッドシステムの概要
- 人工免疫システムとイディオタイプの効果
推奨システムの実装を成功させるには、大量の参照データを用意することが重要です。 しかし、必要なデータがまったくない、または十分でない場合はどうでしょうか? この状態はコールドスタートと呼ばれます。 たとえば、新しいユーザーがサイトに登録され、システムはまだ彼について何も知りません。 または、誰も購入または評価したことのない新製品がストアに登場しました。 または本当に悪いのは、システムが動作を開始したばかりで、データがまったくないことです。 そのような状況で何ができるかを見てみましょう。
ユーザーをそらす
推奨システムがサービスの機能の1つに過ぎない場合、システムが必要なデータを収集するまで、ユーザーを他の機能で楽しませることができます。 これに必要な時間は、ユーザーのアクティビティに直接依存します。 正確に計算できるとは考えにくいが、それがどの程度のフレームワークにあるかを想像することが重要である。
データをオープンに収集するシステムでは、場合によってはこのプロセスを高速化して、ユーザーがシステムを積極的に「トレーニング」できるようにすることができます。 システムの原理とシステムが使用するデータを部分的に発見できます。これにより、より機敏なユーザーがシステムを自分用にすばやく構成するのに役立ちます。
サードパーティのリソースを使用する
ユーザーに関する一部の情報は、サイトの外部で取得できます。 他のサイトへの訪問履歴を分析し、検索クエリに特に注意を払って何かを見つけることができます( 履歴分析の良い例として、記事「 ナビゲーション履歴の性別の決定 」を読むと役立ちます)。 ユーザーに関するいくつかの個人情報、たとえば彼の電子メールがある場合、彼のブログやソーシャルネットワークで彼に関する情報を見つけることができます。 幸いなことに、多くのサービスはAPIを介して情報へのオープンアクセスを提供します。 結果として得られたデータは、個別に使用するか、ある種のステレオタイプに起因し、他の品質について仮定を立てることができます。
システムを作成するとき、どのような追加の情報源が利用可能になるかを考えてください。おそらくそれらのいくつかを使用すべきです。 これらの方法は非常に時間がかかる可能性があり、ビット単位でデータを収集する必要がある可能性がありますが、システムがユーザーについてできるだけ多く、できるだけ早く知ることが重要な場合は、それらが役立ちます。
統計
次の2つの方法は、より客観的な結果をもたらします。 彼らの本質は、彼が他のオブジェクトをどのように評価し、他のユーザーが新しいオブジェクトをどのように評価したかに基づいて、新しいオブジェクトに対するユーザーの態度を予測できることです。
たとえば、集合フィルタリングアルゴリズムの1つであるSlope Oneを使用します。 評価を予測するために、彼は、システムが評価を決定しようとしているオブジェクトと評価がすでにわかっているオブジェクトとの間の平均差を使用します。
製品の評価者に関する情報があるとします。
| 製品A | 製品B | 製品B | |
| サーシャ | 4 | 評価しませんでした | 8 |
| カティア | 6 | 2 | 4 |
| アーサー | 5 | 3 | 評価しませんでした |
商品Aと商品Bの評価の平均差が何であるかがわかっているので、商品Bのサーシャの評価を計算できます。
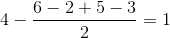
この方法は非常に粗雑ですが、機能します。
ベクトルパターン
2番目のかなり単純ですが、非常にエレガントで効果的な方法は、比較されるオブジェクトを多次元ベクトルの形式で表すことです。この場合、そのプロパティの一部の数値表現が座標として使用されます。 これらのオブジェクトの類似性を特徴付ける大きさは、ベクトル間の角度の余弦になります。 ベクトルAとBを示し、それらの間の角度のコサインが等しい( スカラー積の定義により):

ここで、A * Bはベクトルのスカラー積であり、| A || B | - モジュールの製品。
明らかに、結果として、-1から1までの数値(両方のベクトルが正の場合は0から1)を取得します。 番号1は、ベクトルが同じ方向に向けられ、オブジェクトが同一であることを意味します。 0は、ベクトルが直交(垂直)であり、オブジェクトに共通点がないことを意味します。 -1-ベクトルが反対方向に向けられ、オブジェクトも反対であること。
ベクトルの座標として、2つのオブジェクトを比較し、数値形式で表すことができる任意のパラメーターを使用できます。 たとえば、2つのテキストを比較する必要がある場合、測定のために、それらで発生する単語、および座標-テキストでのそれらの使用回数を取得できます(ただし、 TD-IDFメソッドを使用して、取得したテキストに対する単語の関連性を使用する方が適切です)。 ベクトル形式のテキストでのテキストの表示についての詳細は、「 ベクトル空間モデル 」の記事をご覧ください。 スロープワンに関する記事では、バイナリ値でベクトルを使用する例があります。
例に戻り、アーサーの製品Bの評価を、彼の意見とカティアの類似性に基づいて判断してみましょう。 ベクトルの形でアーサーとカティアを提示し、商品を測定値として使用し、それらの推定値を座標として使用します。 次に:

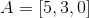

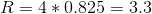
明らかに、そのような評価のためには、意見が一致する訪問者を連れて行く方が良いです。
moismi.ruプロジェクトでは、このアルゴリズムを使用して類似のタグを検索しました。 ベクターモデルの有効性の良い例を次に示します(サイトの右側のタグクラウドに注意):「 Microsoft 」、「 browser 」、「 Google 」。 やや悪いことに、まれなタグで機能します。
私のブログのオリジナル