注目に値する最初のこと:ILM-万能薬ではなく、技術でも、解決策でも、行動のガイドでもありません。 これは、企業データの最新の見解を反映した概念です。 ビジネスにとっての情報の価値とストレージインフラストラクチャのコストの最適なバランスを達成することを目的とした一連の管理プラクティス。
ILMは、SNIA(ストレージネットワーキング産業協会、 www.snia.org )によると、ビジネスの観点からの情報の価値を最も適切で費用対効果の高いインフラストラクチャと相関させるために使用されるポリシー、プロセス、プラクティス、サービス、およびツールです。情報を作成し、その配置で終わる瞬間から。 情報は、アプリケーション、データ、メタデータに関連付けられた管理ポリシーとサービスレベルを介してビジネス要件にマッピングされます。
簡単に言えば、これは、セキュリティパラメータ、情報の可用性、ビジネス価値、ストレージコストの最小化を考慮したビジネス要件に基づいた、データセンターインフラストラクチャでの自動データ配置の概念です。 ILMはどのようなストレージの問題を解決しますか?
データの海にdrれないでください
企業情報の量が毎年、そして非常に深刻に増加していることは秘密ではありません。 IDCのレポートによると、保存および処理されるデータの量の増加は年間70%以上です。 平均的な現代の企業では、毎日3,000人の従業員がテラバイトのデータをメールで送信しています。 合計で、ガートナーの推定によると、2005年には1日あたり360億件の電子メッセージが送信されました。これは2001年の3倍です。 医学などの特定の分野では、情報量が指数関数的に増加しています。
状況は、特定の種類の情報の長期保存を規定する規範的行為と企業標準の要件により、場合によっては5〜10年間複雑になります。 これは、1 TBの企業データ量が少なく、年間60%の増加を示している企業(最新の基準では最大ではない)が10年間で110 TBの情報を保存することを意味します。 100倍以上増やしてください!
データ量の爆発的な増加の問題は、別の問題と密接に関連しています。データセンターの分散インフラストラクチャを管理するプロセスは常に複雑になっています。 最新のデータセンターは、サーバー、ストレージシステムの要素(論理ユニット、ディスク、コントローラー、制御サーバー、テープドライブなど)、ストレージネットワークの要素、ローカルエリアネットワーク(ルーター、ホストコントローラー、アダプター、など)。 特殊なツールを使用して、複雑なインフラストラクチャを管理し、インフラストラクチャ要素の種類ごとに-独自のツールを使用します。 また、データセンター内の異種コンポーネントが増えるほど、使用を余儀なくされる管理ツールが増えます。 これにより、システムの複雑さがさらに増します。
さらに、特殊なインフラストラクチャ管理ツールを使用しても、雪崩のような成長するデータストリームを管理するという主要な問題は解決されません。 企業は、高価な高性能システムに情報を保存し続けており、機器のコストは削減されていますが、毎年そのストレージにより多くのお金を費やしています。 バックアッププロセスはより複雑になり、より多くの時間が必要になります。 同時に、既存の管理ツールは情報を配置するプロセスを十分に自動化しません。管理者は、情報を保存する場所を仮想的に手動で割り当て、必要なサーバーにバインドを設定し、バックアップスケジュールを作成し、ソースと宛先を決定します。
データストレージの分野における現在の状況は、次のように説明できます。 データの量は劇的に増加しており、利用可能な管理ツールはこれに対処することができません 。
ビジネスには、システムに保存されているすべてのデータが必要ですか?
10年で企業情報の量を100倍に増やした会社の例に戻ると、私たちは自問します。オンラインストレージに保存されたこの110 TBのデータは、そのビジネスに本当に必要なのでしょうか。
明らかにそうではありません。 時間の経過とともに、データの価値とその可用性とセキュリティの要件の両方が変化します。 したがって、金融取引の価値は最初の月に最大になり、その後着実に減少します。 さらに、会社のERPシステムの財務記録と、たとえば従業員の個人的な手紙には、作成時のビジネスに対する異なる値があります。
一方、運用中の高性能データセンターストレージでは、古くなった不要なデータを含むすべてのデータが配置されますが、アクセス性の要件が高いデータのみが保存されます。
エンタープライズストレージグループによる分析は、ビジネスの情報の価値がそのタイプに応じて時間とともにどのように変化するかを示しています。
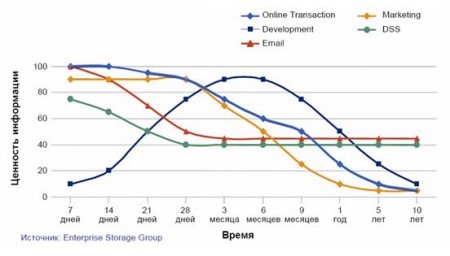
重要な結論を下すことができます。 情報のクラスが異なればビジネス上の価値も異なり、この価値は時間とともに変化します。
企業データの次の重要な特性は、その状態です。 作成されたデータは後続の処理のためにデータセンターに保存され、ビジネスが解決するタスクに応じて変更されます。 データが変更される限り、それらはアクティブ状態にあり、操作可能と呼ばれます。 しかし、時間が経つにつれて、データが「修正」され、変更が行われなくなる時期が来ます。 これらを使用して、新しいドキュメント、要約レポートなどを生成できます。このようなデータは参照と呼ばれます。 参照データを保存する自然な方法は、アーカイブすることです。
現代のデータセンターでは、運用データと参照データは通常同じリポジトリにまとめられ、ストレージのコストが増加するだけでなく、特定の種類の情報のストレージを管理する規制への準拠が困難になります。
最後に、別の条件があります。他の場所で使用されていない古いデータと、規制法で規制されている保存期間が切れています。 このデータはビジネスで不要になり、値はゼロになり、削除できます。 現在、古いデータはほとんど手動で追跡され、システムからのデータの削除は管理者にとって悪夢であり、ストレージはお金の無駄です。
前進して!
データストレージの現在の状況を説明するために、データと情報の違いに焦点を当てませんでした。 同様に、これらの違いは、プロセスとストレージインフラストラクチャを編成する現在のプラクティスでは考慮されていません。 ただし、この側面は、ILMの概念で最も重要なものの1つです。 データ≠情報
データは単なるバイトの集まりであり、ストレージインフラストラクチャにビジネス情報を反映する方法です。 この観点から、それらのセマンティクスは定義されていないため、それらはすべて同じ値であり、ここではストレージの信頼性、セキュリティ、可用性などのパラメータが重要です。 最新のデータストレージシステムとインフラストラクチャ管理ツールが動作するのは、これらの特性です。
情報は、ビジネスにとって特定の意味を表すデータです。 ストレージシステムに均等に配置された構造が類似したデータは、完全に異なる意味を持つ可能性があり、そのため、会社にとって異なる値を持つ可能性があります。 たとえば、電子メールで送信された従業員の個人的な手紙と、機密の顧客情報を含む同じ従業員の手紙。
ILMは、データ管理から離れ、情報管理に焦点を当てることを提案します。 これを行うには、まずストレージへのアプローチを変更する必要があります。 ILMの一部として、企業のビジネス情報をストレージインフラストラクチャに入る前に分類することが提案されています。 分類は、効果的な情報ライフサイクル管理に必要なプロセスであり、保存されたデータに適切なセマンティクスを提供します。
このプロセスでは、サービスレベル目標(SLO)と「ポリシー」の概念が導入され、それに基づいて情報ストレージが管理されます。 SLOは、このクラスの情報のためにストレージインフラストラクチャによって提供されるべき重要なパフォーマンスインジケータ(信頼性、可用性など)を決定します。 「ポリシー」は、特定の条件(たとえば、情報の寿命の終わり)が発生した場合に、特定のクラスの情報で必要なアクションを決定します。 SLOとポリシーの形成の基礎は、企業のビジネス要件とビジネスプロセス、およびさまざまな規制です。
したがって、データセンターのデータストレージへのアプローチは情報中心になります。
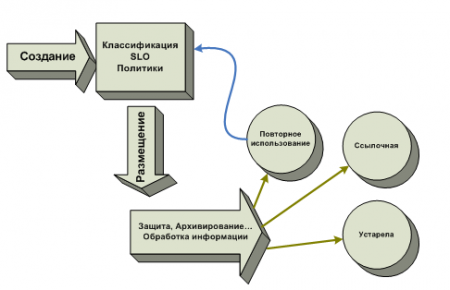
生成された情報は分類され、特定のSLOが関連付けられます。これに基づいて、インフラストラクチャに統合された管理メカニズムが、指定されたポリシーに従ってこの情報を配置します。 つまり、高可用性を必要とする情報は高性能のストレージシステムに格納され、ビジネスにとって重要ではない情報は低コストのストレージに格納されます。
同時に、データアプリケーションを操作するメカニズムは変更されませんが、管理ツールは情報の価値とその状態を常に監視し、ポリシーとSLOに従って適切なストレージシステムに移動します。 ライフサイクルの特定の時点で、情報が参照されたり、古くなったり、再利用されたりする可能性があります。 次に、最初のケースの制御メカニズムはアーカイブに転送し、2番目のケースでは単純に削除し、3番目のケースでは再分類して別のSLOにリンクします。
したがって、ILMに従って構築されたデータセンターには、次の主な利点があります。
- 情報ストレージのコストの削減(低コストのストレージシステムへのデータのタイムリーな転送と古い情報の破壊による);
ポリシーを自動的に適用することにより、データストレージを管理する規制を厳守します。
ストレージ特性(信頼性、セキュリティ、可用性など)のさまざまなクラスの情報への準拠の達成。
情報の重複の除去(参照データの管理による)。
同時に、情報は常に適切な場所で適切なタイミングで最適な価格で提供されます。