- ファイルがトレントやそのフラグメントのハッシュを含む他のソースにない場合でも、破損したダウンロードを修復します。
- サーバーでサポートされていない場合でも、履歴書付きのファイルをダウンロードします。
- サーバーが直接リンクを提供せず、異なるアドレスからファイルを提供する場合(ただし、部分コンテンツを提供する場合)に再開します。
今日、「 トレントvs. 64 kbps 」で、1週間前に彼自身が遭遇した問題を見つけました。
かなり長い間、約10日間(断続的に)、100 Kbpsで3.5 GBのISOイメージをダウンロードしました。 そして、この同じ画像はダウンロード時に破損していました。 このことを急流で探し、前述のトピックで説明した方法を使用しようとしました-以前はこのようなファイルを復元していました。 しかし、ファイルはそこにありませんでした(そして、私がそれをダウンロードした場所からのリソースは、ほんの数週間前に取得しました)。 著作権侵害で私を蹴り始めないように、すぐにVisual Studio 2008 Professional SP1 RUS with Dreamsparkをダウンロードしたと言います。
そのため、多くの手動作業を行ったように、さらに10日間待つことを望みませんでした。その結果、この汚いプロセス全体を実行するスクリプトが生まれました。
アイデア
ポンプで送らなければならない情報の量を最小限に抑え、実際に何らかの形でこれらの損傷部分を特定する必要がありました。 ここから、明らかにアクションプランが続きます。
- ダウンロードしたファイルをかなり小さな断片に切り分けました。
- ハッシュを検討してください。
- いくつかの参考文献と比較して、「不良」を特定します。
- 必要なピースと接着剤をダウンロードします。
そして、これと同じ「正しい」ハッシュをどこで入手できますか? すべてを完全に自分にダウンロードしないようにするには、ファイルをはるかに高速でダウンロードできるサードパーティの場所が必要です。 SSHを含む共有ホスティングプラットフォームにアクセスできるようになりました。必要なものだけです。 しかし...そこにあるスペースは3.5 GBではなく、1.5 GBだけでした。 その結果、ファイル全体を一度にプルするのではなく、断片的にプルするようになりました。
コード
これらすべての製作の結果、次のコードが生まれました(ファイルmd5_verify.phpを呼び出しましょう)。
<?php
$md5sum = 'md5sum.txt' ; //
$tmp = 'chunk.tmp' ; //
$out = 'out/' ; //
$offset = 0 ; // ( )
$chunk = 1048576 ; //
$size = 3760066560 ; //
$host = 'http://all.files.dreamspark.com' ;
$path = '/dl/studentdownload/7/6/3/76329869-10C4-4360-9B09-98C813F8EAFA/ru_visual_studio_2008_professional_edition_dvd_x86_x15-25526.iso' ;
$param = '?LCID=1033&__gda__={timestamp}_{hash}' ;
$cookie = '__sdt__={another-hash-or-guid}' ;
$url = $host . $path . $param ;
//
$sums = file ( $md5sum );
for ( $i = 0 , $l = sizeof ( $sums ); $i < $l && $offset + $i * $chunk < $size ; $i ++)
{
//
$start = $offset + $i * $chunk ;
$end = min ( $size , $offset + ( $i + 1 ) * $chunk ) - 1 ;
//
list( $hash , $file ) = explode ( ' ' , $sums [ $i + intval ( $offset / $chunk )]);
$file = trim ( $file , "*\r\n " );
//
$fp = fopen ( $tmp , "w+" );
// CURL
$options = array
(
CURLOPT_URL => $url ,
CURLOPT_HEADER => false ,
CURLOPT_COOKIE => $cookie ,
CURLOPT_RANGE => $start . '-' . $end , //
CURLOPT_FILE => $fp
);
$ch = curl_init (); // CURL
curl_setopt_array ( $ch , $options ); //
curl_exec ( $ch ); //
curl_close ( $ch ); //
fclose ( $fp ); //
//
$broken = ( $hash != md5_file ( $tmp ));
// ,
print $file . ' [' . $start . '-' . $end . ']: ' . ( $broken ? 'BROKEN' : 'OK' ) . "\n" ;
// , ( )
if ( $broken )
copy ( $tmp , $out . $file );
//
unlink ( $tmp );
}
要するに、スクリプトはファイルを部分的にダウンロードし、連続する各部分のハッシュを比較して、マシンで計算できるようにします。 それが一致しない場合、私たちの作品は壊れており、サーバー上のものは良好です。将来のダウンロードのために延期します。
演技
まず最初に、ダウンロードしたものを細かく分割する必要があります。
C:\ISO>mkdir out && cd out && split -a 3 -b 1048576 ..\ru_visual_studio_2008_professional_edition_dvd_x86_x15-25526.iso
-aパラメーターはサフィックスの長さを指定します。これはアルファベット(26文字の小文字)であるため、3で十分です:26³=17576。これは、3.5 GB / 1 Mb≈3584のスライス数より明らかに大きいです。
このすべてが切断されると、xaaa、xaab、xaacなどの名前のファイルが取得されます。
ハッシュを考えてみましょう:
C:\ISO\out>md5sum x* > ..\md5sum.txt
このプロセスも非常に時間がかかるため、フォームの内容を含むファイルが取得されます。
26c379b3718d8a22466aeadd02d734ec *xaaa
2671dc8915abd026010f3d02a5655163 *xaab
6f539fcb0d5336dfd28df48bbe14dd20 *xaac
69f670a2d9f8cf843cdc023b746c3b8c *xaad
…
次に、md5_verify.phpとmd5sum.txtをサーバーにアップロードし、同じ場所にoutフォルダーを作成します。このフォルダーに、ポンピングする必要があるピースが追加されます。 SSH経由で接続し、PHPインタープリターをスクリプトに突っ込んでいます。 これで、House MDをスリープ状態にしたり、歩いたり、見たりすることができます。
サイトで提供されるチャネルの幅に応じて、数時間でスクリプトが終了し、outフォルダーにダウンロードする必要のあるすべてのピースがあります。
アーカイブ内で非表示にします。
tar - jcvf "chunks.tar.bz2" ./out/x*
最後に、作成したアーカイブをダウンロード可能なパパに転送し、お気に入りのwgetを設定するか、カールするか、好きなものを設定するだけです。
破損したピースをダウンロードしたアーカイブから削除されたものに置き換えると、患者を接着することができます。
cat out\x* > fixed.iso
好きなものをカット、グルー、ハッシュできますが、Windowsをしぶしぶ使わなければならない人は誰でも、cat、split、md5sum(Linuxの標準、Windows用に移植)( GnuWin32プロジェクト)のような小さなユーティリティをすべて手に入れています。
履歴書について
はい、ところで、これと一緒に、サーバーが部分的なコンテンツを提供できない場合でも、ダウンロードして再開する素晴らしい方法を見つけました:シェルを介してホスティングサイトにファイルをプルし、そこから適切な人々のようにダウンロードします。
もちろん、多くのサービスは、RefererやCookieを必要とし、ファイルをただ渡すことに同意しません。 それらを入手できます。Firefoxとその拡張機能であるLive HTTP Headersが必要です。
アドオンウィンドウを開き、ウェブサイト上の「ダウンロード」リンク/ボタンをクリックすると、ファイルを保存するための提案がポップアップ表示されます。 [キャンセル]をクリックしてファイルのダウンロードを拒否し、必要なデータをヘッダーからコピーします。
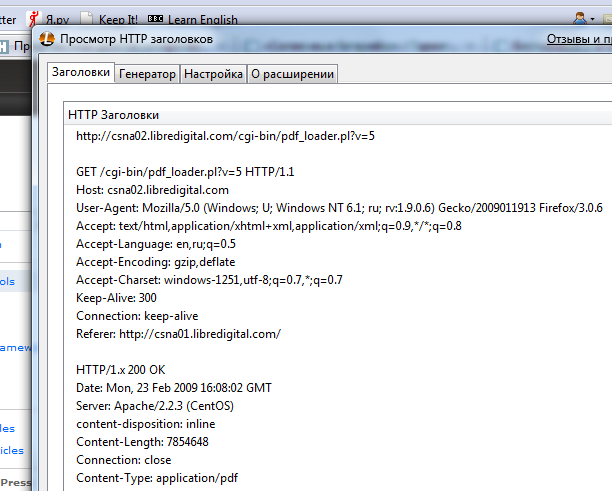
それでは、このデータをお気に入りのロッキングチェアに押し込みます(スクリーンショットではすべてローカルで行われますが、リモートサーバーのSSHを介してこれを行う必要があることは明らかです)。
wget --header "Referer: http://csna01.libredigital.com/" -O "output.pdf" http://csna02.libredigital.com/cgi-bin/pdf_loader.pl?v=5
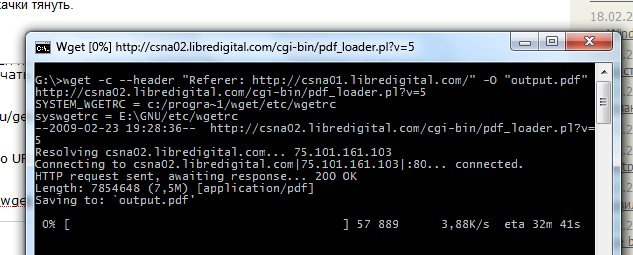
curl -v -e "http://csna01.libredigital.com/" -o "output.pdf" http://csna02.libredigital.com/cgi-bin/pdf_loader.pl?v=5
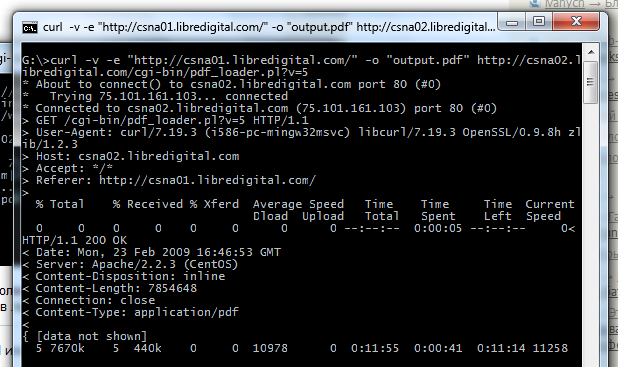
スクリーンショットでは、wgetの-cスイッチの使用を見ることができます( -Cは curlに使用されます)。ダウンロードできますが、例のサーバーではダウンロードできないため、ここではデモ用にのみ提供されます。
最後に
ただし、レスキューでwgetとcurlを直接マシンで使用するのは理にかなっています:出力ファイル名( -Oキー)を同じままにしておくと、いつでも1つのファイルを部分的にダウンロードして、毎回新しいリンクを使用できますcookie)。
これは、トピックの最初の約束から3番目の「方法を学ぶ」です。
PSストーリー全体は、患者が約500個の損傷部品を示して終了しました。 ハッシュの作成、デバッグ、切り取り、計算に数時間、サーバーでスクリプトを実行するのに数時間、これらの部分をダウンロードするのに約12時間かかり、合計で約1日かかりました。 それでも、数十日間部品を再びポンプで送るよりもはるかに少ないです(また、何かが再び損傷しなければなりません)。