Kafkaに関する本の後に、 Kafka Streams APIライブラリに関する同様に興味深い作品をリリースしたことを思い出してください。

これまでのところ、コミュニティはこの強力なツールの限界を理解しているだけです。 そのため、最近、翻訳を紹介する記事が公開されました。 著者自身の経験から、Kafka Streamsから分散データウェアハウスを作成する方法を説明しています。 素敵な読書を!
世界中のApache Kafka Streamsライブラリは、Apache Kafka上での分散ストリーミング処理に企業で使用されています。 このフレームワークの過小評価されている側面の1つは、ストリーミング処理に基づいてローカル状態を保存できることです。
この記事では、クラウドアプリケーションのセキュリティ用の製品を開発する上で、この機会をどのように活用したかを説明します。 Kafka Streamsを使用して、共有サービスマイクロサービスを作成しました。各マイクロサービスは、システム内のオブジェクトの状態に関する信頼性の高い情報のフォールトトレラントでアクセス性の高いソースとして機能します。 私たちにとって、これは信頼性とサポートの容易さの両方の点で前進です。
単一の中央データベースを使用してオブジェクトの正式な状態をサポートできる代替アプローチに興味がある場合は、読んでください...
共有状態で作業するためのアプローチを変更する時だと思った理由
エージェントレポートに基づいて、さまざまなオブジェクトの状態を維持する必要がありました(たとえば、サイトが攻撃された)。 Kafka Streamsに移行する前は、単一の中央データベース(+サービスAPI)に依存して状態を管理していました。 このアプローチには欠点があります。 データ集約型の状況では、一貫性と同期のサポートが大きな課題になります。 データベースがボトルネックになるか、競合状態になり、予測不能になる可能性があります。
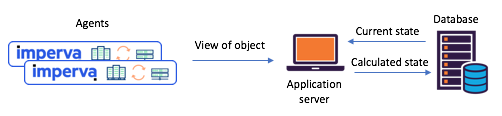
図1:移行前に発生する典型的な分割状態シナリオ
KafkaおよびKafka Streams:エージェントはAPIを介して送信を通信し、更新されたステータスは中央データベースを通じて計算されます
Kafka Streamsの紹介-共有状態のマイクロサービスを簡単に作成できるようになりました
約1年前、このような問題に対処するために、共有状態シナリオを徹底的に確認することにしました。 私たちはすぐにKafka Streamsを試すことにしました-それがどれだけスケーラブルで、可用性が高く、耐障害性があるか、ストリーミング機能がどれほど豊かか(ステートフルなものを含む変換)を知っています。 Kafkaでのメッセージングシステムの成熟度と信頼性は言うまでもなく、必要なものだけです。
作成した各状態保持マイクロサービスは、非常に単純なトポロジのKafka Streamsインスタンスに基づいて構築されました。 それは、1)ソース2)キーと値の永続的なストレージを備えたプロセッサ3)ドレインで構成されていました。

図2:ステートフルマイクロサービスのストリーミングインスタンスのデフォルトトポロジ。 計画メタデータを含むリポジトリもあることに注意してください。
この新しいアプローチでは、エージェントは元のトピックに送信されるメッセージを作成し、消費者(メール通知サービスなど)は、ストック(出力トピック)を通じて計算された共有状態を受け入れます。
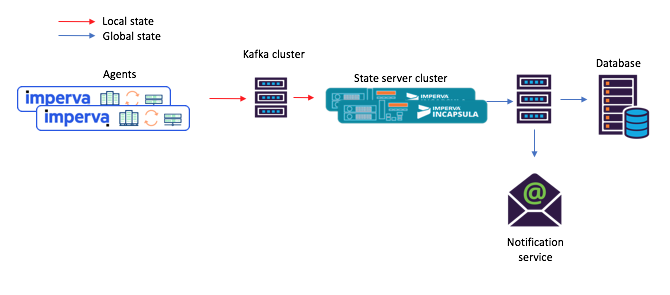
図3:共有マイクロサービスを使用したシナリオのタスクフローの新しい例:1)エージェントは、元のKafkaトピックに到着するメッセージを生成します。 2)共有状態のマイクロサービス(Kafka Streamsを使用)はそれを処理し、計算された状態を最終的なKafkaトピックに書き込みます。 その後3)消費者は新しい状態を受け入れる
ねえ、この組み込みのキーと値のリポジトリは実際には非常に便利です!
前述のように、共有状態トポロジにはキーと値のストアが含まれています。 その使用にはいくつかのオプションが見つかりましたが、そのうちの2つを以下に説明します。
オプション#1:計算にキーストアと値ストアを使用する
キーと値の最初のリポジトリには、計算に必要な補助データが含まれていました。 たとえば、場合によっては、共有状態は「多数決」の原則に基づいて決定されました。 リポジトリでは、特定のオブジェクトの状態に関する最新のエージェントレポートをすべて保持できます。 次に、1つまたは別のエージェントから新しいレポートを受信し、それを保存し、リポジトリから同じオブジェクトの状態に関する他のすべてのエージェントからレポートを抽出し、計算を繰り返します。
下の図4は、新しいメッセージを処理できるように、プロセッサの処理メソッドへのキーおよび値ストアへのアクセスを開いた方法を示しています。
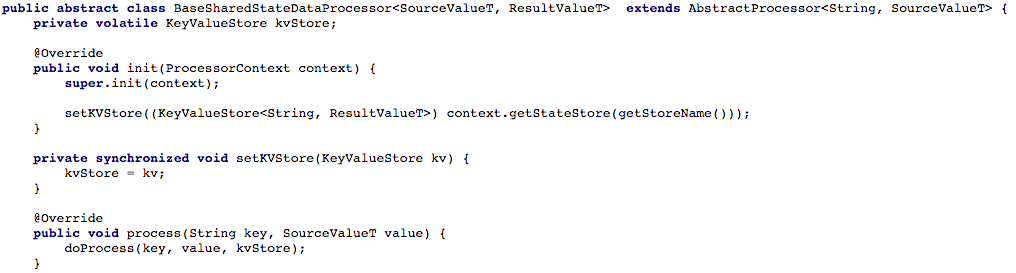
図4:プロセッサの処理メソッドのキーと値のストレージへのアクセスを開きます(その後、共有状態で動作する各スクリプトで、
doProcess
メソッドを実装する必要があります)
オプション#2:Kafka Streamsの上にCRUD APIを作成する
タスクの基本フローを調整した後、共有サービスマイクロサービス用のRESTful CRUD APIの記述を開始しました。 一部またはすべてのオブジェクトの状態を取得し、オブジェクトの状態を設定または削除できるようにしたかった(これはサーバー側のサポートで有用です)。
すべてのGet State APIをサポートするために、処理中に状態を再計算する必要があるときはいつでも、キーと値の組み込みリポジトリに長い間それを置きました。 この場合、以下のリストに示すように、Kafka Streamsの単一インスタンスを使用してこのようなAPIを実装するのは非常に簡単になります。
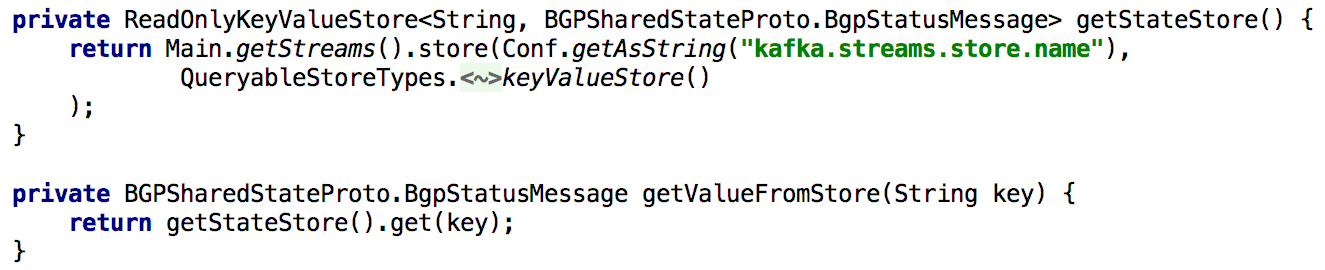
図5:事前に計算されたオブジェクトの状態を取得するためのキーと値の組み込みストレージの使用
APIを介してオブジェクトの状態を更新することも簡単に実装できます。 原則として、このためにはプロデューサーKafkaを作成するだけでよく、その助けを借りて、新しい状態が作成されるレコードを作成します。 これにより、APIを介して生成されたすべてのメッセージが、他のプロデューサー(エージェントなど)から受信したのと同じ方法で処理されることが保証されます。

図6:Kafkaプロデューサーを使用してオブジェクトの状態を設定できます
ちょっとした複雑さ:Kafkaには多くのパーティションがあります。
次に、各シナリオに共有サービスマイクロサービスクラスターを提供することで、処理負荷を分散し、可用性を向上させたいと考えました。 セットアップは可能な限り簡単に行われました。同じアプリケーションID(および同じブートサーバー)で動作するようにすべてのインスタンスを構成した後、他のほとんどすべてが自動的に行われました。 また、各ソーストピックが複数のパーティションで構成されるように設定し、各インスタンスにそのようなパーティションのサブセットを割り当てることができるようにします。
また、状態ストアのバックアップコピーを作成して、たとえば、障害が発生した後の回復の場合に、このコピーを別のインスタンスに転送するのが普通であることにも触れます。 Kafka Streamsの各状態ストアに対して、変更ログ(ローカル更新が追跡される)を使用して複製されたトピックが作成されます。 したがって、カフカは常に州の店舗をヘッジしています。 したがって、1つまたは別のKafka Streamsインスタンスに障害が発生した場合、対応するパーティションが配置される別のインスタンスに状態ストアをすばやく復元できます。 私たちのテストでは、リポジトリに何百万ものレコードがある場合でも、これは数秒で実行できることが示されました。
1つの共有サービスマイクロサービスからマイクロサービスのクラスターに移行すると、Get State APIを実装するのは簡単ではなくなります。 新しい状況では、各マイクロサービスの状態リポジトリには全体像の一部のみが含まれています(キーが特定のパーティションにマップされたオブジェクト)。 必要なオブジェクトの状態がどのインスタンスに含まれているかを判断する必要があり、以下に示すように、フローメタデータに基づいてこれを行いました。
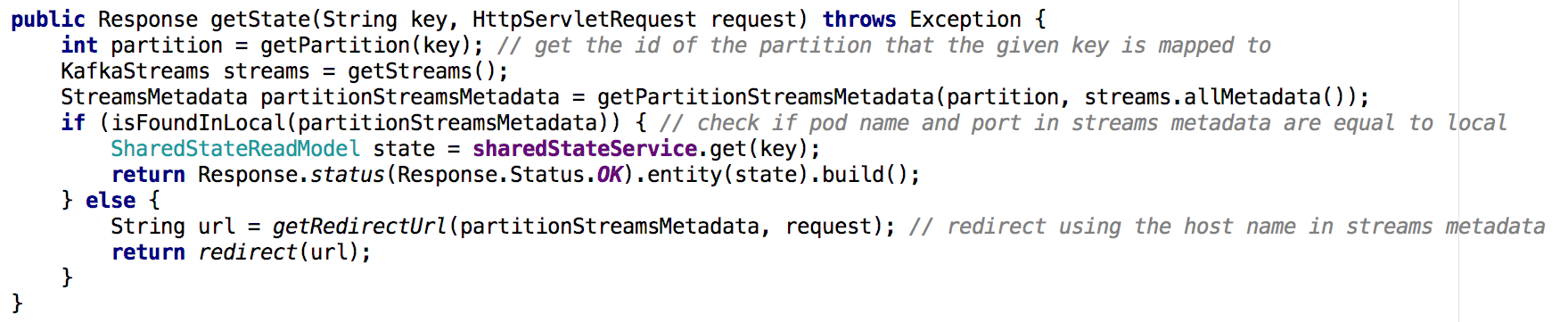
図7:スレッドメタデータを使用して、目的のオブジェクトの状態を要求するインスタンスを決定します。 GET ALL APIでも同様のアプローチが使用されました
主な調査結果
Kafka Streamsのステートストアは、事実上、分散データベースとして機能し、
- カフカで継続的に複製
- そのようなシステムの上に簡単にCRUD APIを構築します
- 複数のパーティションの処理はもう少し複雑です
- 補助データを保存するために、1つ以上の状態ストアをストリームトポロジに追加することもできます。 このオプションは次の場合に使用できます。
- ストリーミング処理の計算に必要なデータの長期保存
- ストリームインスタンスが次に初期化されるときに役立つデータの長期保存
- はるかに...
これらおよびその他の利点のおかげで、Kafka Streamsは、当社のような分散システムでグローバルステータスをサポートするのに最適です。 Kafka Streamsは本番環境で非常に信頼性が高いことが判明しました(展開の瞬間から、私たちは実質的にメッセージを失いませんでした)。これはその機能に限定されないことを確信しています。