カットの下で、TFの元の実装との比較、写真を認識するためのデモアプリケーション、よく...結論。 誰も気にしないでください。
ResNetの仕組みについては、たとえばこちらをご覧ください 。
ネットワーク構造を数字で示します。
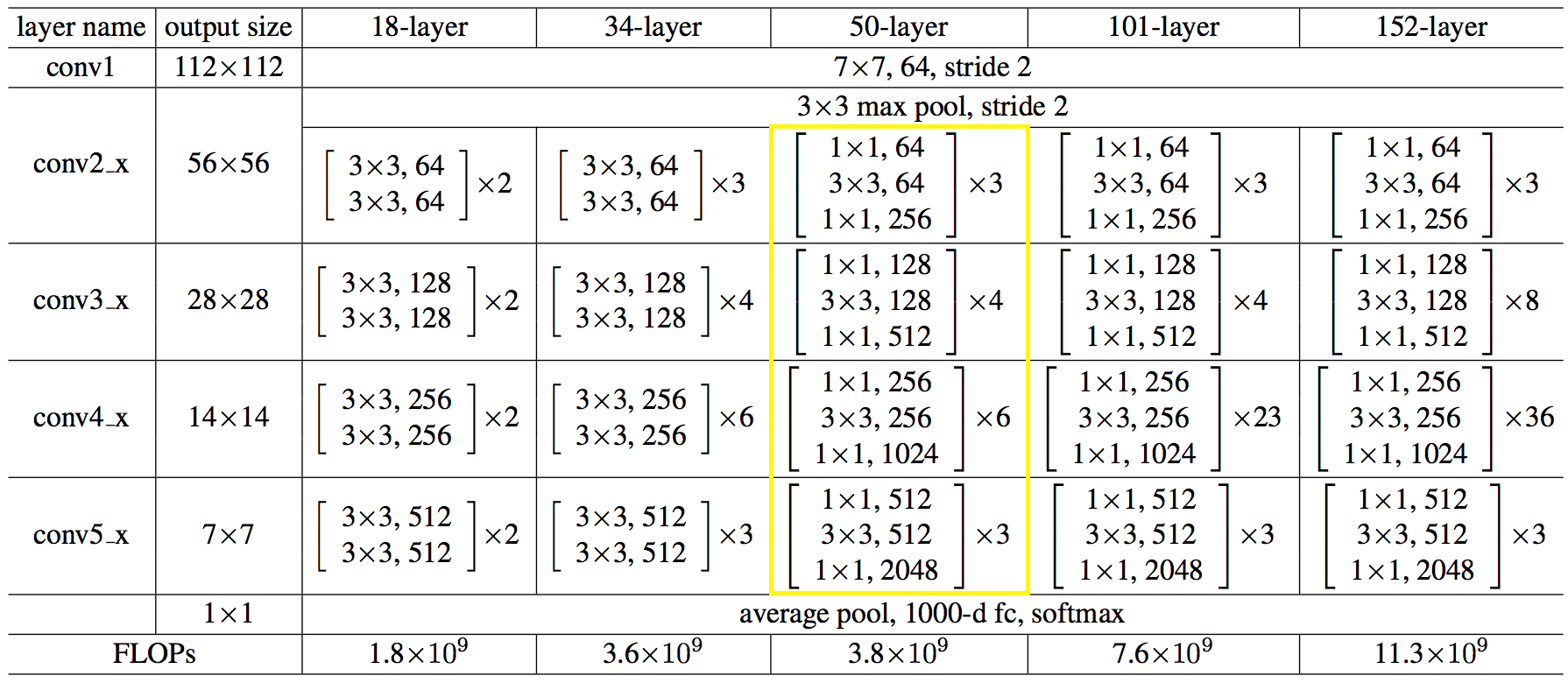
コードはpythonほど単純で複雑ではないことが判明しました。
ネットワークを作成するC ++コード:
auto net = sn::Net(); net.addNode("In", sn::Input(), "conv1") .addNode("conv1", sn::Convolution(64, 7, 3, 2, sn::batchNormType::beforeActive, sn::active::none, mode), "pool1_pad") .addNode("pool1_pad", sn::Pooling(3, 2, sn::poolType::max, mode), "res2a_branch1 res2a_branch2a"); convBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, 1, "res2a_branch", "res2b_branch2a res2b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, "res2b_branch", "res2c_branch2a res2c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256}, 3, "res2c_branch", "res3a_branch1 res3a_branch2a", mode); convBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, 2, "res3a_branch", "res3b_branch2a res3b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3b_branch", "res3c_branch2a res3c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3c_branch", "res3d_branch2a res3d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3d_branch", "res4a_branch1 res4a_branch2a", mode); convBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, 2, "res4a_branch", "res4b_branch2a res4b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4b_branch", "res4c_branch2a res4c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4c_branch", "res4d_branch2a res4d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4d_branch", "res4e_branch2a res4e_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4e_branch", "res4f_branch2a res4f_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4f_branch", "res5a_branch1 res5a_branch2a", mode); convBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, 2, "res5a_branch", "res5b_branch2a res5b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5b_branch", "res5c_branch2a res5c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5c_branch", "avg_pool", mode); net.addNode("avg_pool", sn::Pooling(7, 7, sn::poolType::avg, mode), "fc1000") .addNode("fc1000", sn::FullyConnected(1000, sn::active::none, mode), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
→完全なコードはこちらから入手できます
それを簡単に行うことができ、ネットワークアーキテクチャとファイルからの重みを読み込み、
このように:
string archPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Struct.json", weightPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Weights.dat"; std::ifstream ifs; ifs.open(archPath, std::ifstream::in); if (!ifs.good()){ cout << "error open file : " + archPath << endl; system("pause"); return false; } ifs.seekg(0, ifs.end); size_t length = ifs.tellg(); ifs.seekg(0, ifs.beg); string jnArch; jnArch.resize(length); ifs.read((char*)jnArch.data(), length); // Create net sn::Net snet(jnArch, weightPath);
興味のあるアプリケーションを作成しました。 こちらからダウンロードできます。 ネットワークの重みにより、ボリュームが大きくなっています。 ソースがあります。例として使用できます。
アプリケーションは記事専用に作成されたため、サポートされないため、プロジェクトリポジトリには含まれていません。

さて、TFと比較して何が起こったのか。
平均100個の画像を実行した後の兆候。 マシン:i5-2400、GF1050、Win7、MSVC12。
認識結果の値は、3文字目まで一致します。
→ テストコード
| CPU:時間/画像、ミリ秒 | GPU:時間/画像、ミリ秒 | CPU:RAM、Mb | GPU:RAM、Mb | |
|---|---|---|---|---|
| スカイネット | 410 | 120 | 600 | 1200 |
| テンソルフロー | 250 | 25 | 400 | 1400 |
実際、すべてがもちろん嘆かわしいです。
CPUについては、MKL-DNNを使用しないことにしました。私はそれを終了することを考えました。シーケンシャル読み取りのためにメモリを再分散し、ベクトルレジスタを最大限にロードしました。 おそらく、行列の乗算、および/または他のいくつかのハッキングにつながる必要がありました。 ここで休むと、最初はもっと悪かったのですが、MKLをすべて同じように使用する方が正しいでしょう。
GPUでは、ビデオカードのメモリからメモリへのメモリのコピーに時間がかかり、すべての操作がGPUで実行されるわけではありません。
このすべての騒ぎからどのような結論を引き出すことができますか:
-誇示するのではなく、よく知られた実績のあるソリューションを使用するために、すでに多かれ少なかれ気になっています。 彼は一度mxnetに座って、ネイティブ使用に苦労しました。
-MLフレームワークのネイティブCインターフェイスを使用しようとしないでください。 そして、開発者が焦点を当てた言語、つまりpythonでそれらを使用します。
あなたの言語からML機能を使用する簡単な方法は、Pythonでサービスプロセスを作成し、ソケットで画像を送信することです。責任の分担と重いコードの欠如が発生します。
おそらくすべて。 この記事は短いものでしたが、結論は価値があり、MLだけに当てはまるとは思いません。
ありがとう
PS:
まだTFに追いつくことを試みたいという欲求と強さを持っている人がいれば、 歓迎 !)
PS2:
早く手を下げました 彼は煙の休憩を取って、再びそれを取り、すべてがうまくいった。
CPUについては、私が考えたように、行列乗算へのキャストが役立ちました。
GPUの場合、すべての操作を個別のlibで選択したため、CPUにコピーすることなく、その逆もありませんが、このアプローチの唯一のマイナス点は、いくつかの事が一致したものの、すべての演算子を書き直さなければならないことでしたが、それらを接続しませんでした。
一般的には、次のようになります。
| CPU:時間/画像、ミリ秒 | GPU:時間/画像、ミリ秒 | CPU:RAM、Mb | GPU:RAM、Mb | |
|---|---|---|---|---|
| スカイネット | 195 | 15 | 600 | 800 |
| テンソルフロー | 250 | 25 | 400 | 1400 |
つまり、少なくともTFの場合よりも推論がさらに速くなりました。
テストコードは変更されていません。