時系列データベース(timeseries db、 wiki )を統計のあるサイトのメインリポジトリとして使用する場合、問題を解決する代わりに多くの頭痛の種を得ることができます。 私はそのようなデータベースが使用されているプロジェクトに取り組んでおり、時には議論されるInfluxDBは、一般的に予期しない驚きを提示しました。
免責事項 :これらの問題はInfluxDB 1.7.4向けです。
なぜ時系列なのか?
プロジェクトは、さまざまなブロックチェーンでトランザクションを追跡し、統計を表示することです。 具体的には、安定したコインの放出と燃焼を調べます( wiki )。 これらのトランザクションに基づいて、グラフを作成し、ピボットテーブルを表示する必要があります。
トランザクションを分析するときに、InfluxDB時系列データベースをメインストレージとして使用するというアイデアが浮上しました。 トランザクションは時点であり、時系列モデルにうまく適合します。
また、集計関数は非常に便利に見えました-長期間のチャートの処理に最適です。 ユーザーにはその年のグラフが必要であり、データベースには5分の時間枠のデータセットが含まれています。 彼に10万ポイントを送ることは無意味です-長い処理を除いて、それらは画面に収まりません。 時間枠を増やす独自の実装を記述するか、Influxに組み込まれた集約関数を使用できます。 彼らの助けを借りて、日ごとにデータをグループ化し、希望の365ポイントを送信できます。
通常、このようなデータベースがメトリックの収集に使用されるのは少し恥ずかしいことでした。 監視サーバー、iot-devices、すべてが「注ぐ」形式の数百万のポイント:[<time>-<metric value>]。 しかし、データベースが大量のデータフローでうまく機能する場合、少量が問題を引き起こすのはなぜですか? これを念頭に置いて、彼らはInfluxDBを機能させました。
InfluxDBで他に便利なもの
上記の集約関数に加えて、 連続クエリ ( doc )という素晴らしいものがあります。 これは、スケジュールに基づいてデータを処理できるデータベースに組み込まれたスケジューラです。 たとえば、24時間ごとに1日のすべてのレコードをグループ化し、平均を計算して、独自の自転車を作成せずに別のテーブルに1つの新しいポイントを記録できます。
保持ポリシー ( doc )もあります -一定期間後のデータ削除のセットアップ。 たとえば、CPUの負荷を1秒間に1回測定してCPUに保存する必要がある場合に便利ですが、数か月の距離ではこの精度は必要ありません。 この状況では、これを行うことができます。
- データを別のテーブルに集約する連続クエリを作成します。
- 最初の表では、その週より古いメトリックを削除するためのポリシーを定義します。
また、Influxは独立してデータのサイズを削減し、不要なデータを削除します。
保存データについて
格納されるデータはそれほど多くありません。約7万件の取引と100万ポイントの市場情報が含まれています。 新しいエントリの追加-1日あたり3000ポイント以下。 サイトにはメトリックもありますが、データはほとんどなく、保持ポリシーには1か月以内しか保存されません。
問題
サービスの開発およびその後のテスト中に、InfluxDBの運用中にますます重大な問題が発生しました。
1.データの削除
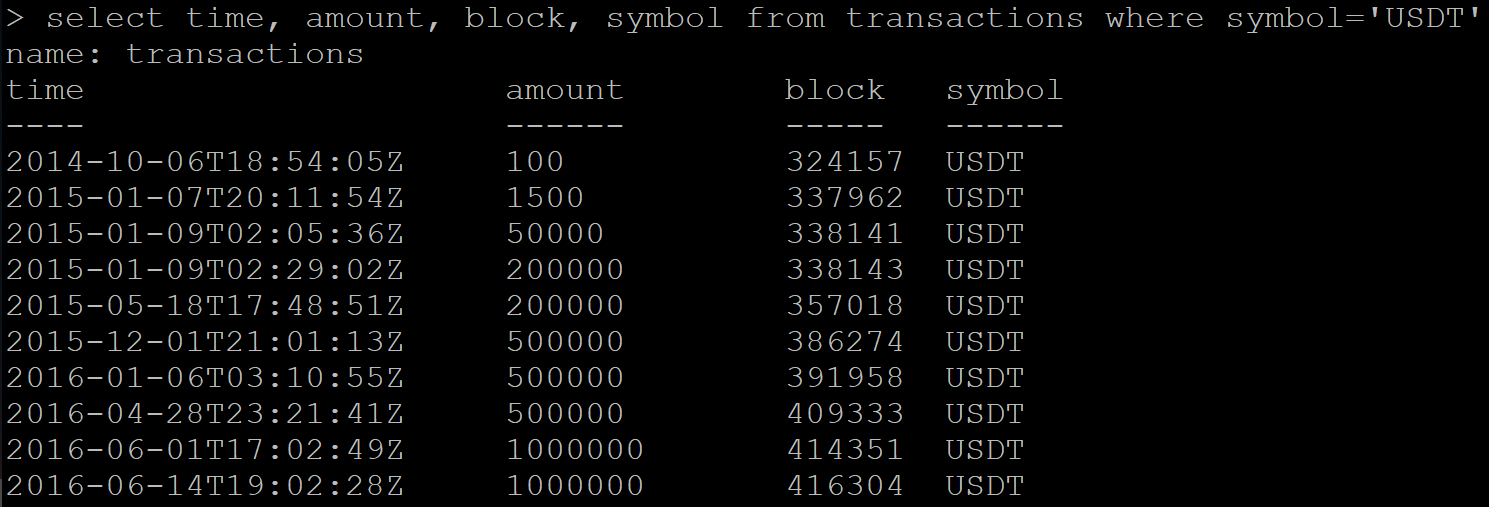
トランザクションに関する一連のデータがあります。
SELECT time, amount, block, symbol FROM transactions WHERE symbol='USDT'
結果:
データを削除するコマンドを送信します。
DELETE FROM transactions WHERE symbol='USDT'
次に、既に削除されたデータの受信をリクエストします。 Influxは、空の回答の代わりに、削除する必要があるデータの一部を返します。
テーブル全体を削除しようとしています:
DROP MEASUREMENT transactions
テーブル削除の確認:
SHOW MEASUREMENTS
リスト内のテーブルは見ていませんが、新しいデータリクエストは同じトランザクションセットを返します。
削除のケースは孤立したケースであるため、問題は1回だけ発生しました。 しかし、データベースのこの動作は明らかに「正しい」作業のフレームワークに適合しません。 後でgithubで、ほぼ1年前にこのトピックに関するオープンチケットを見つけました。
その結果、データベース全体の削除とその後の復元が役立ちました。
2.浮動小数点数
InfluxDBの組み込み関数を使用した数学計算では、精度エラーが発生します。 珍しいことではなく、不快なことです。
私の場合、データには金銭的な要素があり、高精度で処理したいと思います。 このため、継続的なクエリを放棄する計画です。
3.連続クエリを異なるタイムゾーンに適応させることはできません
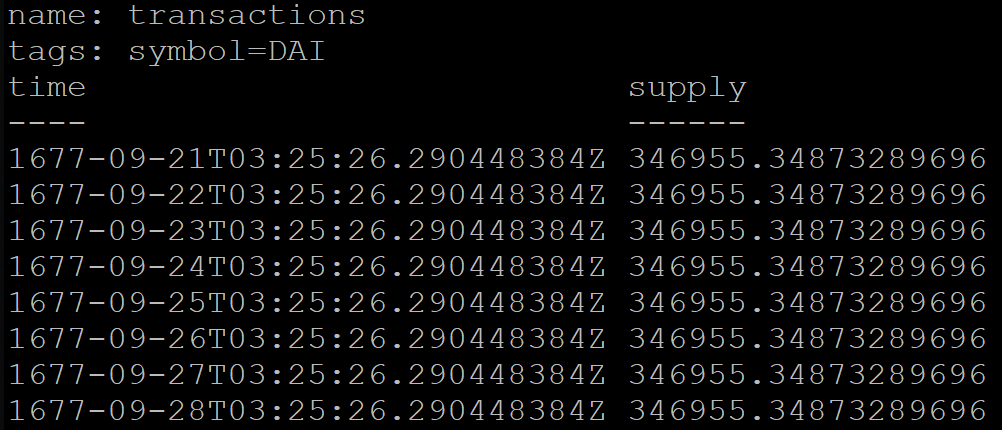
このサービスには、トランザクションに関する毎日の統計を含むテーブルがあります。 毎日、この日のすべてのトランザクションをグループ化する必要があります。 ただし、各ユーザーの日は異なる時間に開始されるため、トランザクションのセットは異なります。 UTCには、データを集計する必要がある37のシフトオプションがあります。
InfluxDBで時間でグループ化する場合、たとえばモスクワ時間(UTC + 3)のように、さらにシフトを指定できます。
SELECT MEAN("supply") FROM transactions GROUP BY symbol, time(1d, 3h) fill(previous)
ただし、クエリ結果は正しくありません。 何らかの理由で、毎日グループ化されたデータは1677年から始まります(InfluxDBは今年からの期間を公式にサポートしています):
この問題を回避するために、サービスは一時的にUTC + 0に転送されました。
4.パフォーマンス
インターネットには、InfluxDBと他のデータベースの比較に関する多くのベンチマークがあります。 最初の知り合いでは、彼らはマーケティング資料のように見えましたが、今では彼らには何らかの真実があると思います。
私の事例を説明します。
このサービスは、前日の統計を返すAPIメソッドを提供します。 計算中、メソッドは次のクエリを使用してデータベースに3回クエリを実行します。
SELECT * FROM coins_info WHERE time <= NOW() GROUP BY symbol ORDER BY time DESC LIMIT 1
SELECT * FROM dominance_info ORDER BY time DESC LIMIT 1
SELECT * FROM transactions WHERE time >= NOW() - 24h ORDER BY time DESC
説明
- 最初のクエリでは、市場データを含む各コインの最後のポイントを取得します。 私の場合、8コインで8ポイント。
- 2番目の要求は、最新のポイントを受け取ります。
- 3番目のものは、最終日のトランザクションのリストを要求します。数百個ある場合があります。
InfluxDBでは、インデックスがタグと時間によって自動的に作成されるため、クエリが高速化されることを明確にします。 最初のクエリでは、 シンボルはタグです。
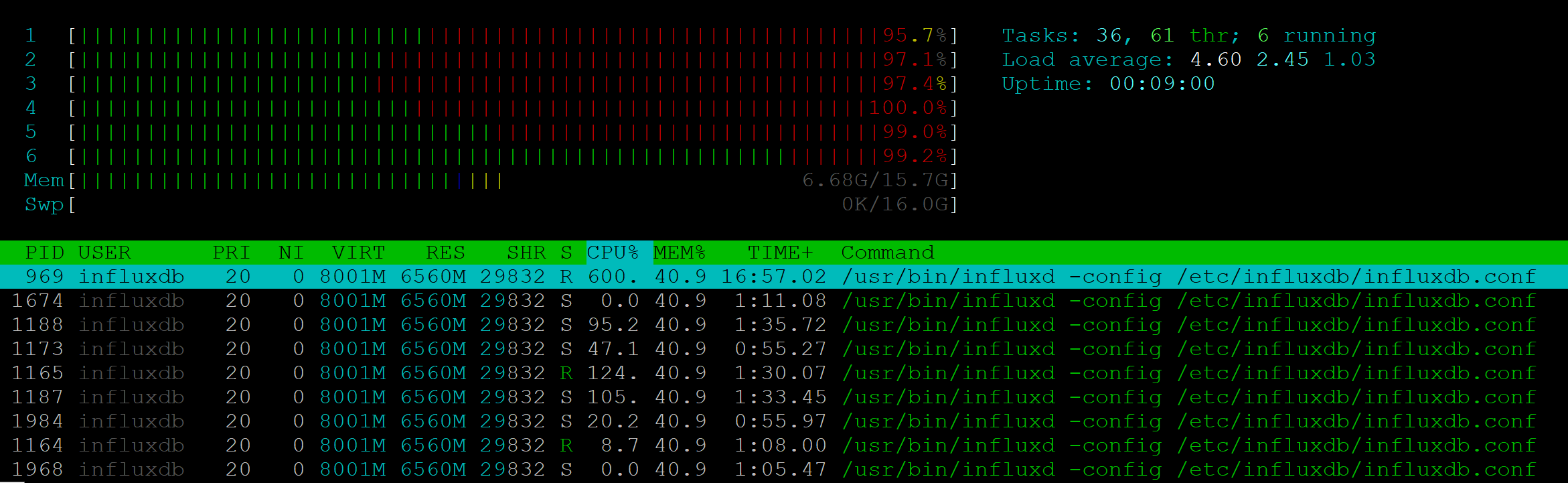
このAPIメソッドのストレステストを行いました。 25 RPSの場合、サーバーは6つのCPUの最大負荷を示しました。
同時に、NodeJsプロセスは負荷をまったく与えませんでした。
実行速度はすでに7〜10 RPS低下しています。1つのクライアントが200ミリ秒で応答を受信できる場合、10クライアントが1秒待機する必要があります。 25 RPS-安定性が損なわれた境界、500エラーがクライアントに返されました。
このようなパフォーマンスでは、Influxをプロジェクトで使用することは不可能です。 さらに、多くのクライアントに対して監視を実証する必要があるプロジェクトでは、同様の問題が発生し、メトリックサーバーが過負荷になる可能性があります。
おわりに
得られた経験から最も重要な結論は、十分な分析なしでは未知の技術をプロジェクトに取り込むことはできないということです。 githubでのオープンチケットの簡単なスクリーニングは、InfluxDBをメインデータウェアハウスとして使用しないための情報を提供できます。
InfluxDBは私のプロジェクトのタスクに適しているはずですが、実践が示しているように、このデータベースはニーズを満たしておらず、めちゃくちゃです。
プロジェクトリポジトリでバージョン2.0.0-betaを既に見つけることができます。2番目のバージョンで大幅な改善が期待されています。 それまでは、TimescaleDBのドキュメントを勉強します。